手机AI芯片量化技术应用进展
2020-04-21
1 引言
近年来,迅速兴起的人工智能技术越来越多地应用和部署到包括手机在内的终端侧。然而,在云端部署追求精度而设计的DNN模型因其具有层数较深、参数较多、计算量较大的特点,在移植到终端侧的过程中出现了时延、算力、存储和功耗等方面的问题,业界纷纷从硬件、软件等多方面来解决此类问题,推动人工智能技术在终端侧的快速有效应用。
2 端侧AI加速方案
2.1 硬件加速
AI技术开始赋能移动智能终端,AI应用不断丰富,为高效执行AI计算,获得更好的应用体验,主流芯片公司均提供了终端侧的AI算力支撑,即在端侧高效执行神经网络的算力支撑。从表1可得,现阶段手机行业AI算力的硬件解决方案现阶段大致分为两种技术路线。第一类,芯片内置专用的神经网络运算单元,对神经网络中大量的矩阵运算进行加速,以华为海思麒麟810、970[1],苹果A11、A12为代表。第二类,通过SDK、API等调度传统硬件单元(CPU、GPU、DSP)及其他通用计算单元联动赋予芯片机器学习能力,以高通(骁龙855[2]、660AIE等)和联发科(P60、P90[3])的部分芯片为代表。随着技术进步、应用场景的丰富以及端侧AI高效算力的要求,两种技术路线有融合发展的趋势[4],如表1所示。对于芯片厂商,支持量化技术,可以在移动设备端进行神经网络推断时获得较好的运行速度收益,满足现阶段终端侧以神经网络推断为主的AI算力需求。
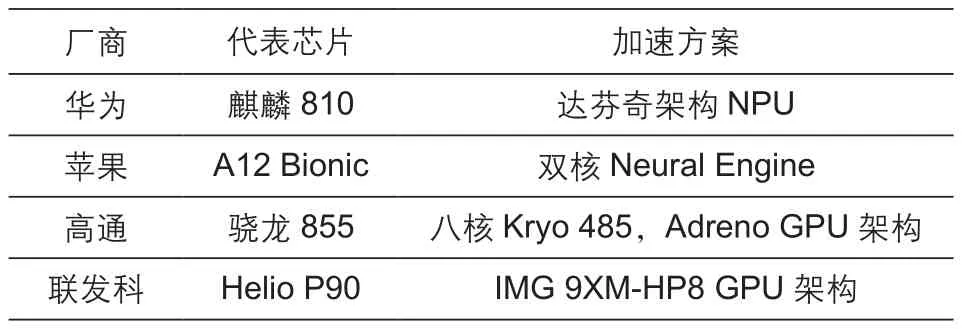
表1 主流手机芯片厂商AI芯片硬件加速方案
2.2 降低模型大小
现阶段的CNN模型并不适用于移动终端,如AlexNet、VGG、ResNet等模型大小动辄超过百兆,对移动设备的内存和运算时延都提出了较高挑战。为了削减模型的大小,并有效控制精度损失,使之适合在移动设备上部署,业界逐渐形成两类方法:
(1)轻量化网络模型的设计。以MobileNet、SqueezeNet、ShuffleNet与DenseNet[5]等为代表。通过传统的卷积方式重新进行网络设计优化,以达到存储、计算量和时延等都得到优化的轻量化网络。轻量化网络模型设计相对于在已训练好的模型上进行处理,设计更为高效的新网络结构,通过减少网络参数,虽然获得较好的模型精度,但这类方法相对门槛较高,目前在终端侧获得较多应用轻量化网络模型是MobileNet[6]。
(2)模型压缩。常用的模型压缩有网络剪枝、量化等方法。两种压缩方法各有其特点,比较如下:
① 网络剪枝方法:传统的网络压缩方法,其核心思想是通过移除神经网络中的部分连接,从而降低网络的存储以及计算量。由于剪枝后的模型迁移性较差,需要对模型进行重新训练,然后再部署到移动设备侧,过程相对复杂,且模型压缩的比例相比量化没有优势。
② 量化方法:将深度神经网络的权重和/或激活函数的参数从32位浮点数转换成低比特位的表达。相比之下,低bit位操作处理逻辑相对简单,能够达到更高的执行效率。其次,通过量化方法可以较好地降低模型大小,在精度损失可控的前提下直接用于移动设备的模型推断。
目前,移动端主要的模型压缩方法是对训练好的标准模型进行量化。因此,本文重点研究通过量化方法对模型进行压缩,以提高端侧AI加速。
3 手机芯片的量化技术进展
深度神经网络拥有复杂的神经网络结构,它们大量的权重参数会却消耗相当大的存储空间、内存带宽以及计算资源,难以满足移动端的需求,严重阻止了深度神经网络在移动应用上的运行。目前,各终端厂商及芯片厂商均研发了相应的AI框架平台,为开发者提供了开放的SDK、配套的神经网络运行环境(NN runtime)及模型优化和转换工具,以提高在终端上更快更好地运行神经网络模型。当前,移动端模型量化技术大部分采用定点量化方法来对神经网络进行量化。相比较用32位单精度浮点数表示网络,其占用资源多,执行速度慢,而定点数操作处理逻辑相对简单,能够达到更高的执行效率。
3.1 高通SNPE
SNPE(Snapdragon Neural Processing Engine)[8]是用于执行深度神经网络的高通骁龙加速runtime平台,具有广泛的异构计算能力,可以帮助开发人员在内置骁龙芯片的移动终端上运行经过训练的一个或多个神经网络模型,而无须连接到云端。它提供了模型转换和执行的工具及核心的API文件,用以优化经过训练的神经网络在移动终端的运行性能。目前,SNPE平台只支持在x86 Ubuntu Linux上调式网络模型。
为了提高开发的效率,开发人员可以采用常见的深度学习框架(SNPE支持Caffe/Caffe2,ONNX和TensorFlow模型)自主设计和训练网络。如图1所示,经过训练后的模型文件被转换可以加载到SNPE runtime的“DLC”(Deep Learning Container)文件。然后,可调用Snapdragon加速计算单元(CPU、GPU、DSP或AIP)将DLC文件用于执行模型推理过程。
基本的SNPE工作流程包含如下步骤:
(1)将网络模型转换为由SNPE加载的DLC文件。
(2)可选择量化的DLC文件运行在DSP。

图1 高通设备运行SNPE SDK平台流程图
(3)准备模型的输入数据。
(4)使用SNPE runtime加载和执行模型。
在开发过程中,根据实际的应用程序需要会采用量化模型文件,在保证精度影响较小的前提下,可以减少runtime的网络初始化时间和初始化期间的峰值内存使用量,提高模型推断的效率。SNPE支持多种量化模式,所有模式都是将浮点数据参数量化到8位定点值,差别在于量化参数的选择。平台默认的量化模式是使用要量化数据的真实最小值/最大值,然后调整范围以确保最小范围,并保证浮点数0.0能够精确地量化到0-255中的一个整数。针对该量化模式,下面详细阐述下其过程:
(1)计算输入浮点数据的真实范围
在输入数据中查找最小和最大的值,确定编码范围,其中最低限值必须至少为0.01。如输入[-1.8,-1.0,0,0.5],最小值是-1.8,最大值是0.5,编码范围为2.3。
(2)计算最小编码值和最大编码值
最小编码值是指以定点值0表示的最小浮点值。最大编码值是指以定点值255表示的最大浮点值。其中步长大小可表示为:

按量化8 bit(范围为0-255)对应其关系,最小值-1.8对应0,最大值0.5对应255。那么步长等于0.009 020(保留6位小数)。此处编码最小值是设置为-1.8,编码最大值设置为0.5。
(3)量化输入的浮点值
使用上一步设置的编码-min和编码-max参数将所有输入的浮点值量化为8位定点表示,限制在0到255以内。量化公式如下:

(4)按照公式2,检查浮点数0.0量化值

由于0.0没有精确对应一个整数,四舍五入为200,故调整编码的最小值和最大值,以便0.0能够精确到对应200。把0.0的量化后的值固定为200,步长保持不变为0.009 020,反推调整后的编码最小和最大值如下,

(5)输出量化的定点值
量化后的值为[0,89,200,255],图2展示了浮点量化过程,可明显看出经过调整后0.0的准确定点到200的位置。

图2 浮点数量化过程图
通过采用SNPE SDK工具箱对VGG16进行量化对比,表2可以看出在保证精度前提下,量化后的VGG16模型大小变得极小,提高了移动端模型推断效率。本文引用的数据均来自中国电信公开的2019年AI芯片评测报告,具有可靠性[7]。
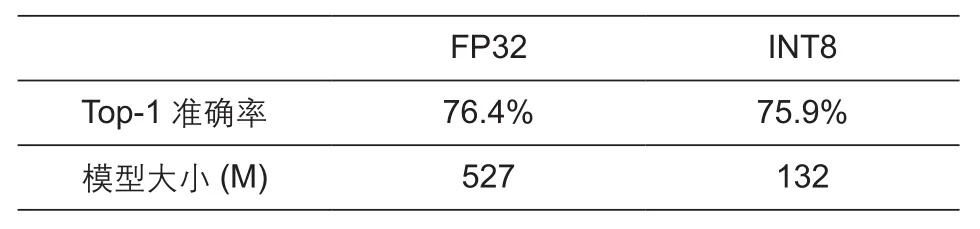
表2 高通SNPE平台VGG16网络量化先后对比
3.2 华为HiAI
华为HiAI是面向智能移动终端的AI计算平台,构建三层AI架构。如图3所示,芯片能力开放、应用能力开放和服务能力开放等架构组成垂直分布,从底层到服务全方面的布局。端芯云结合构筑全面开放的智慧生态,让开发者能够快速地利用华为强大的AI处理能力,为用户提供更好的智慧应用体验[9]。

图3 华为HiAI平台AI框架图
HiAI DDK(Device Development Kit)是海思发布的用于人工智能计算的SDK,该SDK面向AI应用程序开发人员和机器学习算法人员,通过使用HiAI DDK,可以更好的提升移动端机器学习模型运行速度。其中,HiAI Foundation API是移动计算平台中的人工智能计算库,其主要作用是通过HiAI异构计算平台来加速神经网络的计算,支持模型编译、模型加载、模型运行、模型销毁等模型管理接口及基本的算子计算接口。目前HiAI DDK版本的对应关系如表3所示。

表3 HiAI DDK版本对应
目前,API仅支持在麒麟Kirin SoC(System on a Chip)上运行,为开发者提供基于移动设备的运行环境和调试工具,开发者可以在移动设备中运行神经网络模型,调用HiAI Foundation API进行加速计算。HiAI Foundation API无需安装,使用移动设备默认镜像即可支持相关集成、开发和验证。
图4主要介绍了APP使用HiAI DDK的主要集成步骤:
(1) 原始模型:HiAI Foundation支持多种智能平台框架,包括Caffe、Tensor flow等,使用不同的智能平台框架,第三方需要在接口中指出本次计算需要使用的具体的智能平台框架,其他接口和参数无需修改。
(2)INT8量化:是一种可以把FP32模型直接转化为INT8模型的操作,以节约网络存储空间、降低传输时延以及提高运算执行效率。与上述高通SNPE平台描述的量化原理相同。
(3)离线模型转换:完成模型构建或INT8量化后,需要将Caffe或者Tensor flow模型转换为HiAI平台支持的模型格式。通过编译工具生成可以在HiAI Foundation上高效执行的离线模型,并保存为二进制“.om”(Offline Model)文件。将标准的神经网络模型(Caffe等)编译转换为离线模型,编译的主要目的是对模型配置进行优化,生成优化后的目标文件,即离线模型,离线模型是序列化的存储在磁盘上,这样,神经网络前向计算时,可以直接使用优化后的目标文件进行计算,速度更快。目前,离线模型转换需在Ubuntu下执行转换。
(4)APP集成:APP集成流程包含模型预处理、加载模型、运行模型、模型后处理。
通过采用HiAI 2.0 SDK对ResNet50进行量化对比,表4可以看出在保证精度前提下,HiAI SDK量化后的ResNet50模型大小变得极小,提高了移动端模型推断效率。
3.3 联发科NeuroPilot
NeuroPilot是以CPU、GPU和APU(AI Processor Unit)[10]等异构运算为基础的、整合软硬件、完整、开放的人工智能平台,致力将终端人工智能(Edge AI)带入各种跨平台设备,更快地进行深度学习与智慧决策,部署从端到云的强大AI运算方案。其中,APU是人工智能处理单元,专为智能手机移动设备所设计的,可提供高能效的人工智能操作处理。
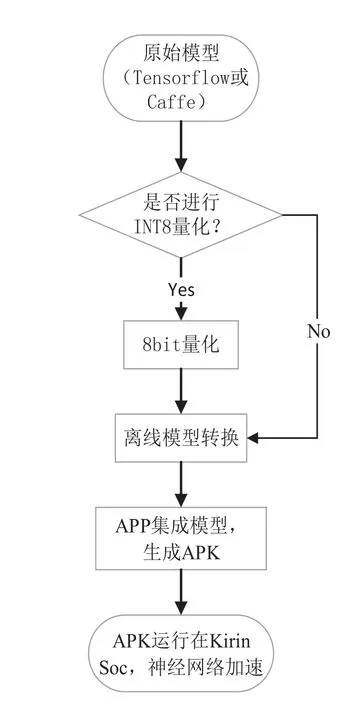
图4 HiAI平台模型集成流程图
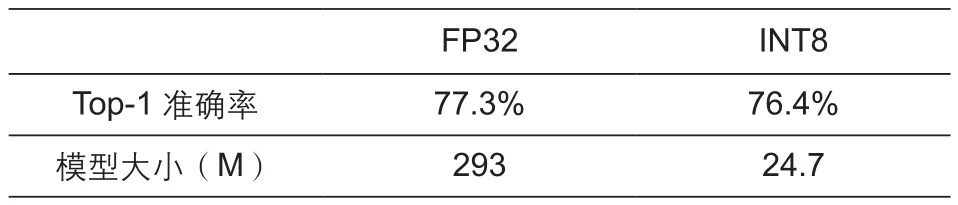
表4 华为HiAI平台对ResNet50量化先后对比
NeuroPilot支持市场上现有的AI架构包括Google的 TensorFlow、Caffe、Amazon的 MXNet、Sony的NNabla等第3方通用架构来构建应用程序。在操作系统方面,联发科技同时支持Android与Linux系统。NeuroPilot SDK不仅兼容谷歌安卓神经网络API(Android NN API)还提供完整的开发工具及NeuroPilot扩充组件,从而让开发人员和设备制造商能以更加贴近硬件的方式编码以提高性能和功效。
从图5可看出,NeuroPilot平台大致可分为3个层级,最顶层是各种应用程序(APP),中间层用于程序编写和异构运算,最底层是各种硬件处理器。软件层主要由算法软件构成,包括API、神经网络runtime、异构runtime,NeuroPilot除了把通用AI应用的运算嵌入,还提供了一些客制化接口,以满足厂商的客制化需求。
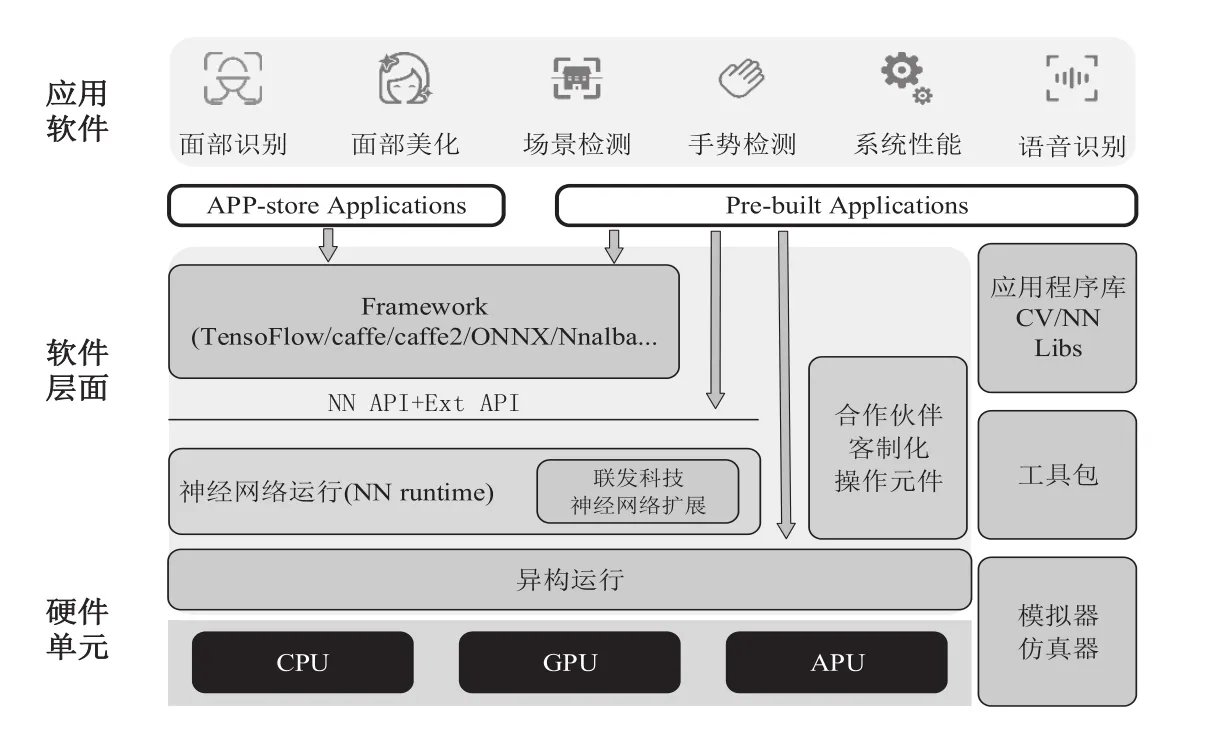
图5 NeuroPilot平台框架
联发科在NeuroPilot 2.0平台上提供了ML Kit工具包,可以对神经网络进行剪枝和量化。通过表5可以得出,经过量化后的模型,可以节省35%的运算量,同样准确度并不会下降。
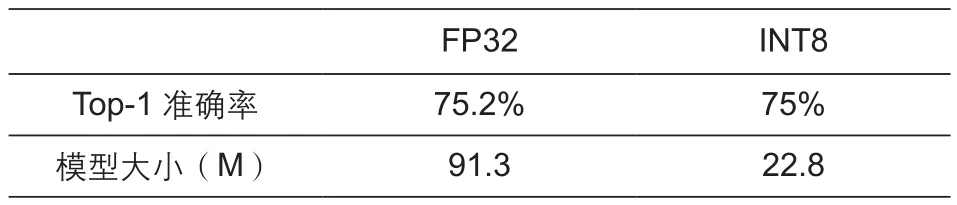
表5 联发科NeuroPilot平台对InceptionV3量化后对比
当前,联发科NeuroPilot SDK虽更新到2.0版本,但并未向开发人员公开,仅对其合作伙伴开放共享。针对NeuroPilot SDK这种能提供软、硬件解决方案的AI平台,若能够对市场开源,相信开发人员可以更方便的开发出实际应用中的人工智能产品,提高内置NeuroPilot技术的智能移动设备的运行效率。
4 量化技术发展判断
深度神经网络普遍使用32位单精度浮点数表示,然而浮点数计算往往占用资源多,执行速度慢。相比之下,定点数操作处理逻辑相对简单,能够达到更高的执行效率。基于此,目前神经网络定点量化技术获得了越来越多的关注。针对移动端模型量化技术的现状,对以后的量化技术发展进行如下判断:
(1)多种低比特量化
随着人工智能应用场景越来越多,因自身字节限制的INT8量化无法满足所有应用场景的需要,故出现了多种低比特量化方法,如INT16、二值量化和三值量化等技术。例如,针对复杂的应用场景如超分网络,相比较采用INT8定点量化网络,16bit量化可以表示更高字节的参数,使得量化后的网络精度更高。同时,近期网络二值量化(-1,+1)和三值量化(-1,0,+1)等方法亦受到了越来越多的研究者的关注。相对于32位浮点数网络,采用权值二值化可以节约32倍存储,同时由于所有权值都量化到+1或者-1,整个网络的浮点数乘加运算可以转换成浮点数加减法。该类型量化方法适用于单一的二类场景,在保证精度前提下,可提高终端的运行效率。未来的量化技术发展应根据实际应用场景分析,在保证精度前提下,采用相对应的低比特量化方法来量化网络参数。
(2)网络激活量化
如今大部分定点量化方法主要是对模型网络权值进行量化,很少会对网络激活进行低比特量化。研发表明,网络激活进行低比特量化可以有效地减少模型量化的精度损失。例如,Hubara等人[11]在中对BinaryConnect网络进行了扩展,二值化神经网络(Binarized Neural Networks,BNN),直接使用符号函数(sign)同时对网络权值和激活进行二值化,在CIFAR-10等小型数据集上,BNN能够达到甚至超过全精度网络的性能。
目前,虽然深度神经在网络权值和网络激活低比特量化方面获得了非常大的进展,但是相比于浮点网络,依然存在较大的性能损失。随着当前的量化技术发展趋势,未来针对如何进行网络非常低比特的压缩、改进量化及训练方法以提升低比特网络性能,依然需要非常多的探索。
5 结束语
当前,越来越多的深度神经网络被部署到手机及其他移动设备上,移动端的AI应用受到广大用户的青睐。目前,主流的终端及芯片厂商纷纷构建了人工智能平台,加速神经网络在移动端的模型推断。本文主要研究分析了高通SNPE、华为HiAI、联发科NeuroPilot等平台对手机AI芯片量化技术方面的研究现状,发现目前常用的量化方法是定点量化。它操作处理逻辑相对简单,在保证精度的前提下,能够达到更高的执行效率。
未来,随着量化技术的不断发展和完善,手机AI芯片量化技术应根据实际应用场景,采用相对应的低比特量化方法来量化网络参数,不再局限于定点INT8量化方法。同时,不能仅对网络权重量化,还要对网络激活进行低比特量化,最大化地量化神经网络,保证其精度前提下,提高手机的运行效率。针对网络的量化技术发展,仍然存在很多的探索,应多方面的完善和改进量化方法,提升网络性能。
