基于SATLSTM的Web系统老化趋势预测
2020-04-19谭宇宁党伟超潘理虎白尚旺
谭宇宁 党伟超 潘理虎 白尚旺
(太原科技大学计算机科学与技术学院 山西 太原 030024)
0 引 言
随着互联网技术的日益成熟,当前软件数量不断增多,功能结构日趋复杂,对其更便利、更可靠的需求使得软件维护的难度也在不断增强。然而长时间持续运行的软件系统因老化现象的存在,可靠性和可用性受到严重威胁和制约,易造成无法估量的损失。
软件老化是指软件在长期不间断地运行若干时间后系统的性能持续下降、占用的资源不断增加、错误不断累积,最终导致软件失效或系统宕机的现象[1]。为尽可能减少甚至避免老化损失、提高软件的可靠性和可用性,Huang等[2]提出一种主动性的容错策略——软件再生技术,通过间歇或定期中止系统运行,清除内部状态以及运行环境,使之恢复正常,从而避免因软件老化引起突发性失效。
尽管通过抗衰操作可消除软件老化带来的不良影响,然而何时实施抗衰是一个值得探究的问题[3]。再生过于频繁易导致停机时间增长,损失进一步扩大;再生频率过低则无法及时解决老化问题。如果可以准确地对软件老化趋势作出预测,在系统失效前及时发现老化现象并采取合理的软件再生策略,就能尽可能降低因实施软件再生所造成的损失,有效避免因停机所造成不良影响,提高系统的可靠性。因此,准确地对软件老化趋势进行预测至关重要。
目前对于软件老化趋势的预测主要是根据老化性能参数信息,对系统的资源消耗情况进行分析预测。常用的建模方法可分为传统的基于数学建模和基于机器学习的两大类预测方法,包括回归分析[4]、时间序列法[5-6]以及BP神经网络[7-8]等。其中传统的回归分析法和基于时间序列的预测方法目前已经成熟,但相对来说建模形式单一,难以捕捉老化性能参数存在的隐藏规律,无法满足软件老化数据突变和多依赖的非线性要求;而基于机器学习的预测技术在解决复杂的非线性问题时有较高的解决能力,预测更加准确。然而当前大多数预测模型所使用的神经网络层数浅,难以提取更深层次的特征,而且在网络构建过程中未充分考虑前后时刻老化数据间的相互影响,忽略了老化数据间因时序关联而存在的长期依赖问题,致使模型预测精度较低,很难达到理想的预测效果。
循环神经网络模型(Recurrent Neural Network,RNN)是一种具有循环结构的深度神经网络,通过引入时间维度,增加时间状态属性,不仅能自动获取原始数据更多的波动以及规律性特征,而且能有效地克服传统神经网络对序列信息进行处理时的局限。其中长短时记忆(Long Short-term memory, LSTM)循环神经网络作为一种特殊的RNN,通过引入门结构,能有效学习时序数据间的长期依赖关系,并解决传统RNN易产生梯度爆炸或弥散的问题,在各领域已得到广泛应用[9]。然而,随着输入序列的增长,各节点信息在远距离的传递过程中仍会造成损耗,而且由于时间维度上不同时刻的时序特征重要程度不同,对最终序列数据的影响程度也不同,单一的LSTM易忽略重要特征对输出结果的影响[10]。
注意力机制[11]是对人类视觉分析的一种模拟,通过对同一物体分配不同注意力的方式,增加对特定输入部分的关注,从而快速获取重要信息。不同时间的老化序列数据中的特征重要程度存在差异,对最终老化趋势会有不同的影响程度。
基于上述分析,根据老化数据的时序特性,本文提出并设计了一种基于自注意力机制的长短时记忆单元(Self-Attention-LSTM, SATLST)循环神经网络软件老化趋势预测模型。该模型通过LSTM循环神经网络相互连接,对过去时刻的老化数据建立依赖、产生记忆从而挖掘老化数据更多的规律特征。同时在LSTM隐层引入注意力机制,通过对不同时刻的老化数据分配不同的注意力系数,更加全面地对局部老化信息特征的重要程度进行区分学习,并且增强对局部老化信息的关注度,从而有效提取更加丰富的老化序列特征,提高Web系统老化趋势预测的准确度。
1 模型原理
1.1 LSTM模型


图1 按照时序展开的RNN结构图
相比于传统神经网络,RNN不仅通过层与层间的连接进行信息传递,而且通过引入环状结构,使得不同时间维度上的老化数据建立了联系,能有效捕捉老化数据间的依赖关系,在处理具有时序特性的老化数据时有明显优势,但也存在自身问题。在实际计算中,RNN能有效利用短时间内的老化数据进行学习,但因老化过程缓慢,涉及到的大量数据因时间跨度有限,越远的时间点,梯度回传的老化信息就会越少,RNN的学习能力就会变弱,即存在梯度弥散的问题。为解决该问题,LSTM在其结构基础上增加了一个用来记录传递信息的细胞状态,并通过三个基于Sigmoid函数的门结构对老化信息保留或取舍的程度进行判断,通过线性积累,使得网络模型能够较长时间保存并传递信息[13],从结构上克服了RNN长期依赖的局限。LSTM具体单元结构如图2所示。

图2 LSTM单元结构图
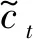
ft=σ(Wf·ht-1+Wf·xt+bf)
(1)
it=σ(Wi·ht-1+Wi·xt+bi)
(2)
(3)
(4)
ot=σ(Wo·ht-1+Wo·xt+bo)
(5)
ht=ot⊙tanh(ct)
(6)
式中:ft、it、ot分别表示遗忘门、输入门、输出门的结算结果;Wf、Wi、Wo分别为遗忘门、输入门、输出门的权重矩阵;bf、bi、bo分别为遗忘门、输入门、输出门的偏置项;xt为t时刻输入的单元状态;Wc为输入单元状态权重矩阵;bc为输入单元状态偏置项;tanh(·)为激活函数;⊙表示hadamard乘积。
1.2 注意力机制
由于长时间老化序列数据在输入LSTM网络时会分为若干短子序列,而不同的短子序列所包含的特征对老化趋势的影响程度存在差异,若对不同时间输入的老化信息分配不同的权重,就可有效提高网络的预测效果。
注意力机制就是对人类视觉分析的一种模拟,通过对同一物体分配不同注意力的方式,增加对特定输入部分的关注,从而快速获取想要的信息。这种重点关注局部注意力的特性,极大地提高了获取信息的速度和能力。从本质上来说,注意力机制是对输入信息进行加权求和的过程,具体结构如图3所示。

图3 注意力机制结构
首先将i时刻的老化序列信息Xi与j时刻的老化信息Yj进行对比,通过计算F(Xi,Yj)函数,得到期望输出yi与输入变量xi的相似度,然后经过Softmax函数归一化处理得到一个称为权重的相似数值。该值越大表明该段老化序列信息对最终输出的影响越大,反之则影响很小。然后根据计算得到的相似度,对所有输入的老化信息进行加权求和并得到最终输出。这种设计能更好地关注对最终结果有影响力的老化数据,从而提高模型的预测精度。
由于F的实现方式不同,注意力模型也不同。其中加性注意力和乘性注意力主要是对(Xi,Yj)加权求和以及按权相乘进行计算,而自注意力(Self-attention)是注意力机制的改进,通过激励函数为tanh和Softmax的两层全连接网络对注意力权重进行计算。其减少了对外部信息的依赖,只关注输入数据本身所具有的特征,通过自动找寻并赋予数据以不同的权重系数,更擅长捕捉数据内部相关性[15]。因此,本文采用自注意力的方法,对LSTM老化预测模型进行改进。具体计算公式如下:
f(xi,y)=wTσ(W1·xi+W2·y)
(7)
(8)
该方法将计算得到的相似性分数通过Softmax函数映射到(0,1)区间并设为权重,加权求和得到最终输出。
2 模型构建
2.1 基于SATLSTM的软件老化预测模型
结合自注意力机制后的LSTM资源消耗预测模型由输入层、LSTM层、自注意力层以及输出层四大部分组成,具体结构如图4所示。
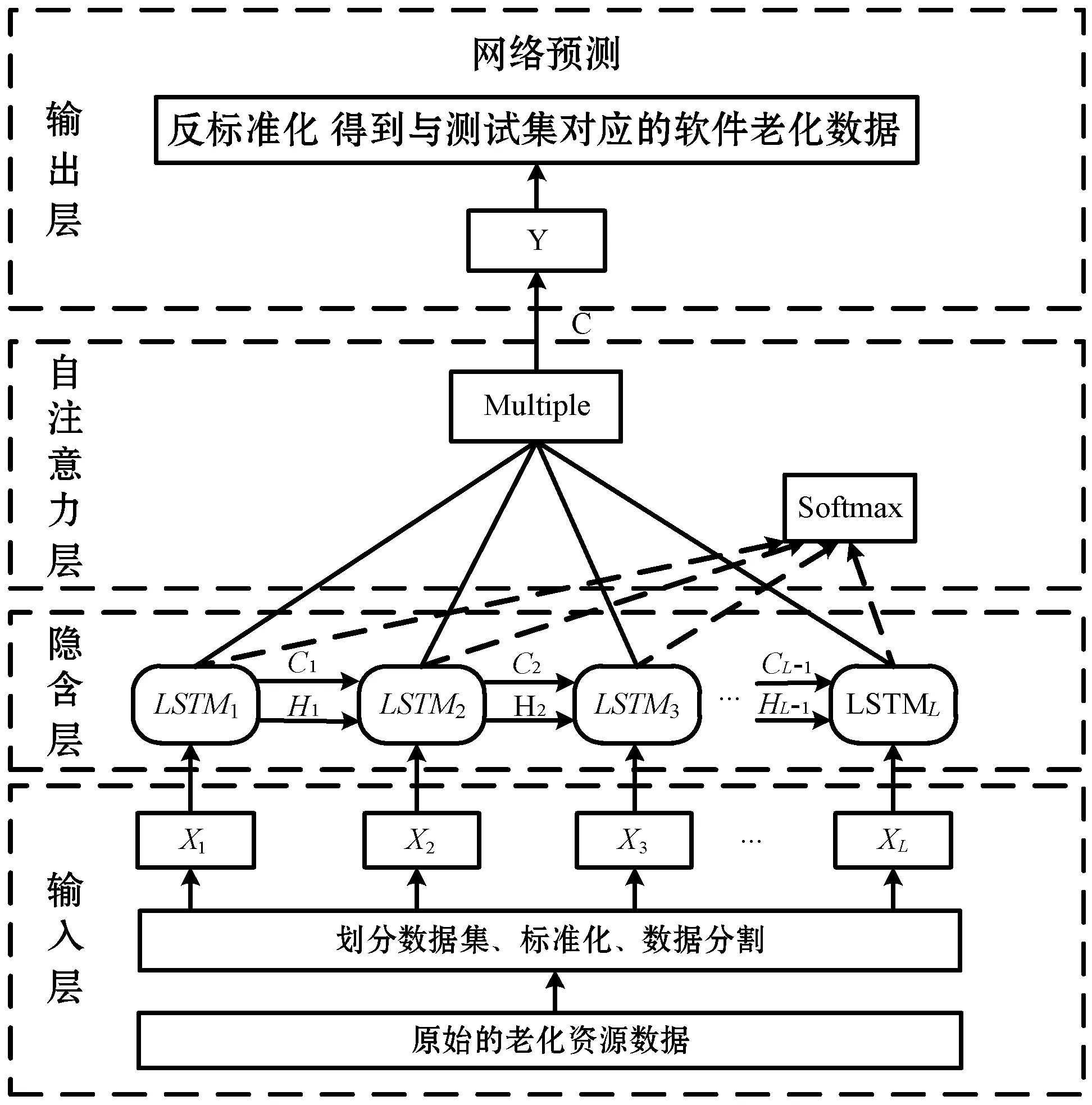
图4 SATLSTM老化预测模型结构
输入层负责输入各时间点对应的老化信息,并对原始老化数据清洗后进行处理、划分;LSTM层主要将老化资源数据以循环结构的方式进行连接,并深入挖掘老化性能参数存在的隐藏规律;自注意力层为每个输入的老化节点数据分配一个0-1区间的注意力系数;输出层负责输出老化数据最终预测结果。
2.2 SATLSTM预测模型算法
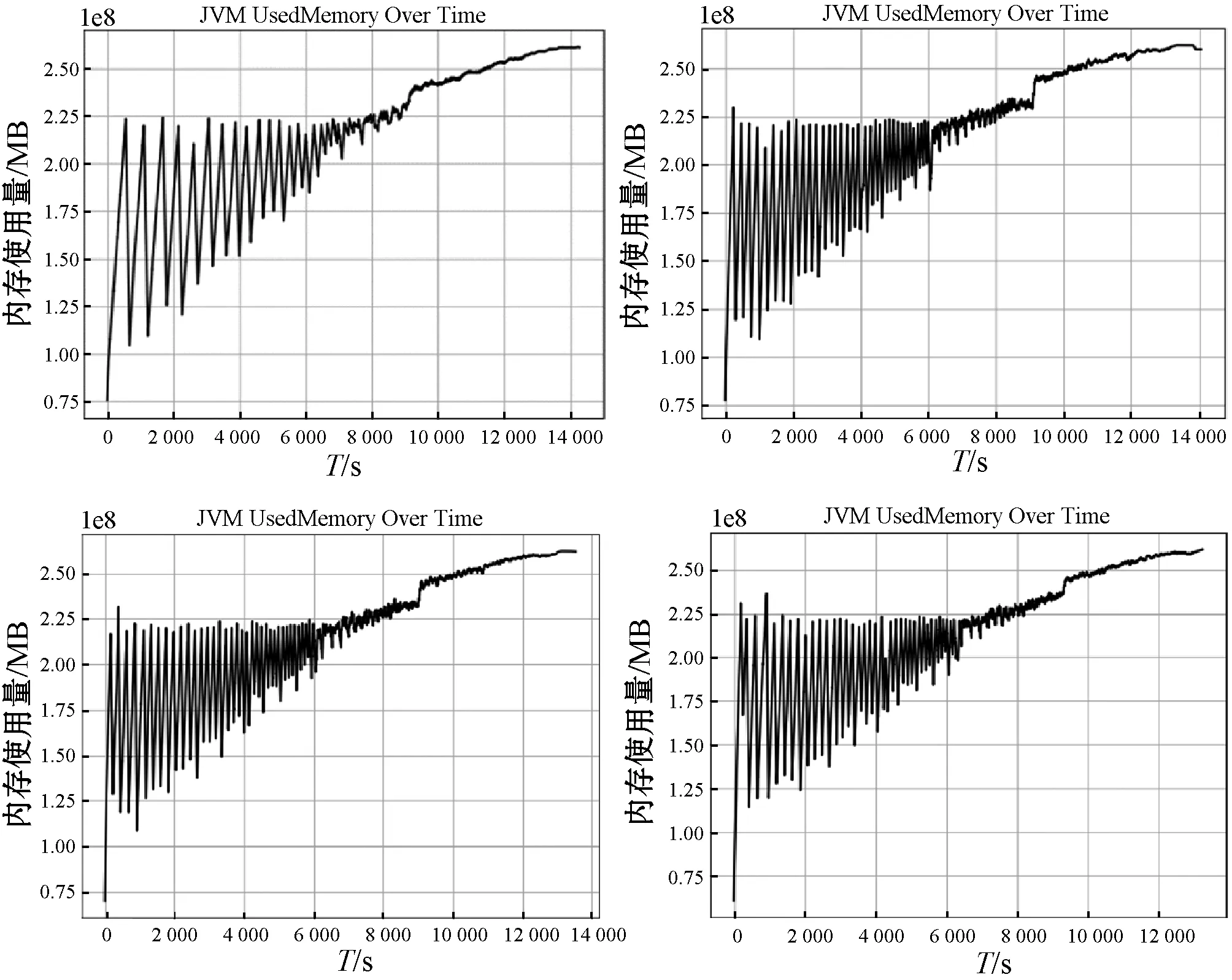
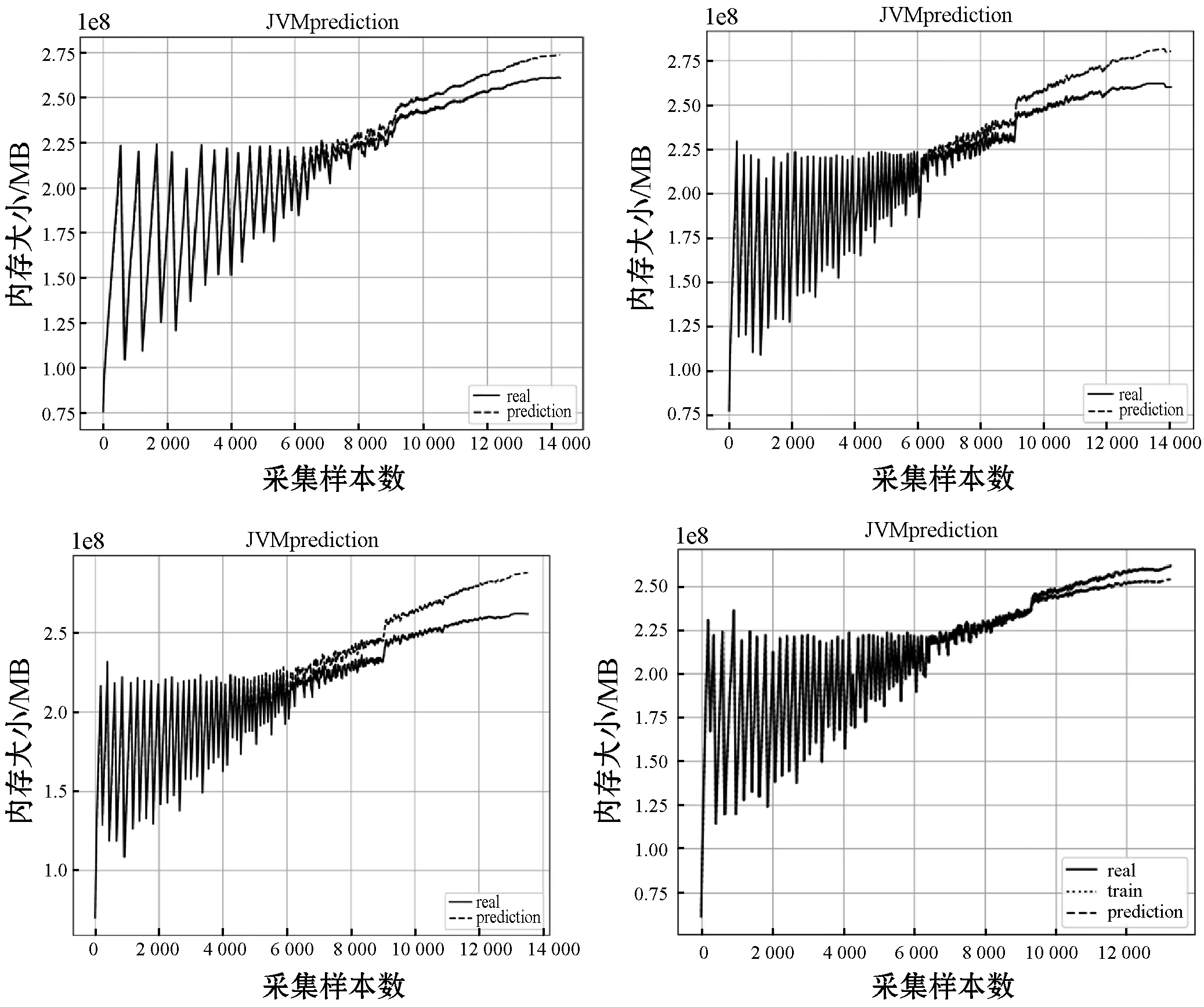
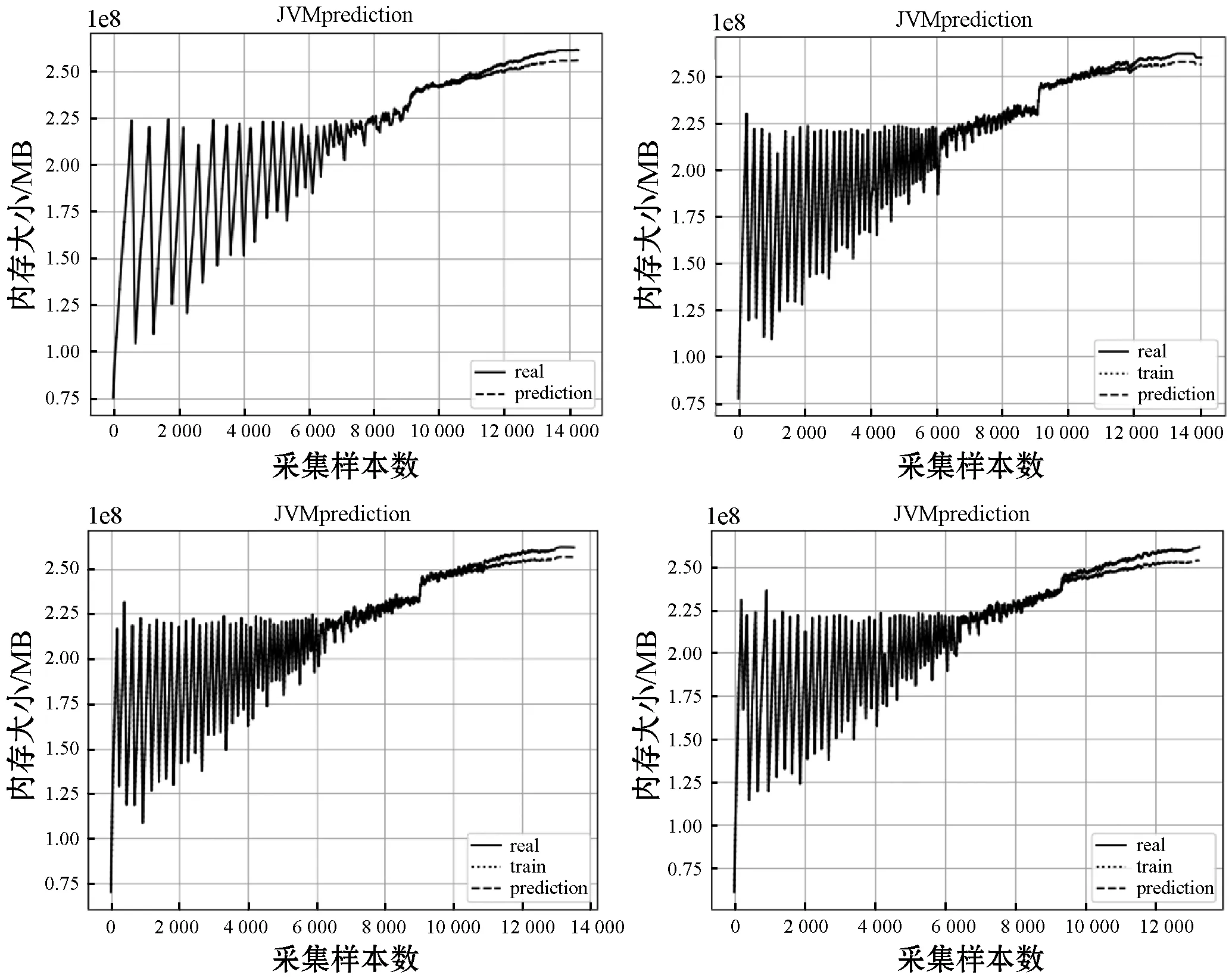
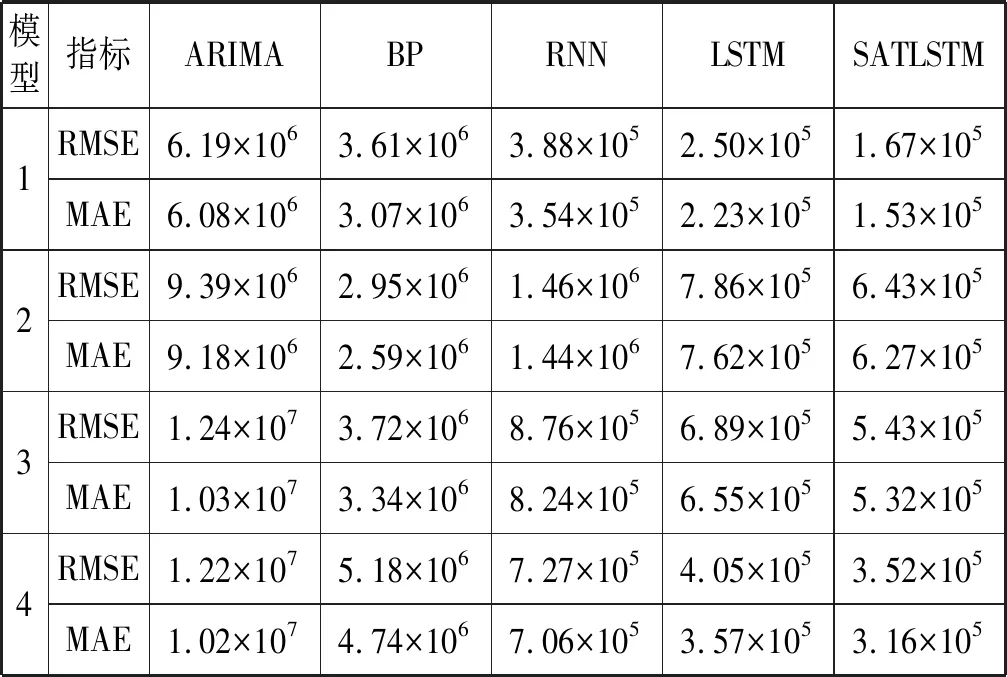
(1) 网络训练。定义老化资源损耗数据f={f1,f2,…,fN},将其划分为测试集ftrain={f1,f2,…,fm}和训练集ftest={f1,f2,…,fn},其中m (9) 为满足网络输入要求,将测试集Xtrain按照滑动窗口的大小分割为N个长度为time_step(s)的老化序列,则分割后的模型输入为: (10) 对应理论输出如下: (11) 将输入矩阵X={X1,X2,…,Xs}首先输入LSTM层,则t时刻xt经过LSTM隐含层得到映射ht,即: ht=f1(xt,ht-1) (12) 根据式(1)-式(6)计算遗忘门ft、输入门it、以及输出门ot各值,经过隐藏层输出结果可表示为: (13) 式中:CP-1和HP-1分别表示上一个LSTM细胞的状态以及隐含层的输出。 (14) (15) 将LSTM层的输出和注意力层的输出进行融合得到模型的输出C。 (16) 经过自注意力层输出结果可表示如下: (17) 将均方误差作为误差计算公式,则损失函数计算公式如下: (18) Pf=SATLSTM(Yf)={pm-s+2,pm-s+3,…,pm+1} (19) 式中:m+1时刻的预测值为pm+1。然后将该值与Yf最后的s-1个数据点进行合并得到新的数据: (20) 将Yf+1输入SATLSTM网络后得到m+2时刻的预测值为pm+2,并以此类推得到预测序pte={pm+1,pm+2,…,pn}。 最后对其进行反标准化处理后得到最终老化预测序列: (21) 研究表明,软件系统内存的泄漏易引起内存耗尽。作为重要的老化诱因之一,内存使用情况是评估软件是否发生老化的一个关键指标。因此,使用内存对Web系统老化现象进行预测:通过监测软件系统的运行状况,根据采集到的内存老化数据,建立一个基于SATLSTM的Web内存老化预测模型,以此来预测Web系统老化趋势。 由于软件老化是一个错误不断累积的过程,一个Web系统需要耗费大量时间才能观察到系统故障。当前绝大多数的老化实验只是简单识别老化效应,很难准确把握软件老化的整体趋势[16]。因此针对软件老化的特性,本文根据Matias等[17]提出的系统化方法,将工业领域已成熟应用的加速测试理论引入到软件领域。 3.1.1Web软件老化加速寿命实验 为研究因内存泄漏而导致应用程序故障的老化效应,本文以一个典型的Web应用服务器为研究对象,搭建了一个引入内存泄漏的软件老化测试实验平台。该平台由一个Web服务器、一个数据库服务器以及一组模拟客户端组成,具体环境配置如表1所示。 表1 实验环境 服务器端实现了一个符合TPC-W基准测试规范的多层电子商务网站系统。该系统模拟了一个在线售书网站,包括主页、畅销页面、新书页面、搜索页面、购物车和订单状态页面等14种不同类型的网页,并规定了一系列模拟真实电子商务环境下顾客的访问规则。客户端则是依照TPC-W规范开发的一系列模拟浏览器(Emulated Browser,EB) ,以会话(Session)为单位与服务器端建立逻辑请求,按照上述规则对服务器进行访问。每个EB能产生三类不同的工作负载:Browsing,Shopping,Ordering。因Shopping行为出现的次数介于Browsing和Ordering间,因此本实验客户端主要模拟Shopping这种类型,以随机生成的概率对不同页面进行访问。 3.1.2内存泄漏注入 为产生软件老化现象,修改服务器端商品查询请求的TPC-Wsearch_request_servlet页面,为其注入内存泄漏代码。因为Java虚拟机(Java Virtual Machine,JVM)本身存在垃圾回收机制,当内存分配空间不足时,所有未被引用的对象均会被其回收,而且所占用的内存资源也会同时被释放以便新对象使用。为对内存泄漏现象进行模拟,在TPC-W_search_request_servlet中增加一个HeapLeak类,并保持整个生命周期对该类HeapLeak对象OOMObject的引用,使其在程序运行期间不会被垃圾回收器回收。因Apache自身提供了一定的抗衰机制,为加速软件老化,修改JVM堆内存的配置(表2),使实验在受控环境下进行操作。由于Java堆存放的是对象实例,所以当创建的对象实例数量达到最大堆容量限制后会造成堆溢出。 表2 JVM堆内存配置描述 运行客户端,每隔1 s采集一次JVM内存使用量,实验持续14 400 s,共4个小时,采集到样本14 400个,每30 s取一次均值,不同注入强度下得到的4组数据如图5所示。 图5 内存数据图 预测模型的性能可从主观和客观两个角度进行评估。主观上采用图文形式,通过人工方式观察预测数据与真实值的拟合程度;客观上采用科学的统一标准,使用常用的评价方法,以数值形式准确刻画预测结果。本文使用平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Squared Error,RMSE)两个评价指标客观描述模型的预测精度,具体计算公式如下: (22) (23) 式中:n为Web老化资源参数的样本数目;pt为老化资源参数的预测值;yt为老化资源参数的真实值或观测值。MAE和RMSE越小,模型预测能力越好。 本文将67%的老化数据作为训练集,其余数据作为测试集进行建模预测,即使用反映真实时间近2.6个小时的前9 650个数据对未来近1.4个小时的4 750个数据进行预测。在Jetbrains PyCharm集成开发环境下,使用Python 3.6作为编程语言,anaconda作为解释器,使用Keras框架搭建并训练老化预测模型,并将预测结果用 matplotlib 实现可视化。其中Keras框架作为开源Python包,以TensorFlow或Theano为后端,可灵活快速地搭建深度神经网络并选取参数进行网络训练。训练参数如表3所示。 表3 SATLSTM老化预测模型训练参数 建立一个含30个隐藏神经元的SATLSTM老化资源消耗预测模型,设置迭代次数epoch=20,batch=10,time steps=10,lr=0.001,损失函数为MSE。由于深度神经网络含有多个网络层以及大量参数。为防止模型发生过拟合现象,采用Dropout对数据进行正则化处理[18],即在每轮权重更新时随机选择隐去一些节点,从而限制模型单元之间的协同更新。该模型使用的Dropout为0.5,即含有Dropout的网络层在训练过程中,会有50%的节点被抛弃。为确定该模型最适合的优化器参数,采用控制变量的方式分别对3种激活函数(Sigmoid,Tanh,Relu)和3种自适应优化学习算法(Adam,RMSprop,Adagrad)进行对比实验。选30次作为迭代训练周期,实验结果如图6所示。 图6 不同优化算法均方根误差对比 由图6可知,不同的优化算法收敛速度和收敛效果不同。对于3种激活函数来说,相比于Sigmoid函数,Relu和Tanh函数均方根误差相对较小,其中Relu函数收敛效果更优。对于不同的自适应优化学习算法,在激活函数相同的前提下,RMSprop学习算法均方根误差最大,Adam和Adagrad学习算法效果相对较好,当迭代30次时,基本都达到了较稳定的收敛状态。其中Adam几次迭代计算得到的均方根误差最小,说明对于SATLSTM老化预测模型来说,RMSprop算法性能最差,Adam算法性能最好。因此采用Relu函数作为LSTM层的激活函数,Adam作为自适应优化学习算法对预测模型进行训练。 为验证SATLSTM老化预测模型的优劣,将该模型按照上述参数对4组数据进行实验,预测结果如图7所示。其中实线表示真实值,虚线表示预测值。 图7 SATLSTM预测结果 图7从整体上反映了SATLSTM的预测能力。由图7可知,各组SATLSTM老化预测模型测试值与真实值接近,预测趋势与实际资源消耗趋势基本一致,对于出现较大波动的时间点也有较好的拟合,说明SATLSTM能有效地对软件老化趋势进行预测。 为进一步验证SATLSTM模型的预测能力,将其与主流的预测算法ARIMA模型以及BP神经网络进行对比,实验结果如图8、图9所示。 图8 ARIMA预测结果 图9 BP预测结果 由图8可知,对于像老化数据这种信息丰富且波动复杂的数据,ARIMA模型在短时间内尽管能较准确地描述短期资源损耗情况的细节波动情况,但对于长期趋势的刻画存在滞后性,尤其当资源老化现象明显时,预估值低于真实数据。由图9可知,相较于ARIMA模型,使用BP算法建立的模型与真实数据更接近且较准确地描述了老化的过程,但可以明显看出,BP预测模型训练集上表现良好,但测试集的预测准确度不高,说明样本的泛化能力有待提高。 将图7与图8、图9对比可得,SATLSTM老化预测模型整体上表现良好,无论是趋势还是细节的刻画,与真实数据相比,拟合程度更好。 将4组不同预测模型的评价指标进行对比。由表4可知,相比于其他预测模型,传统时间序列模型ARIMA预测精度不高,存在明显的滞后现象,其评价指标RMSE和MAE均大于其他模型。BP神经网络虽然预测精度得到了提高,但准确度低于循环神经网络,这是因为当数据集规模大且结构复杂时,传统的浅层神经网络已无法获取更多更深层次的规律。若增加神经元的个数并加深网络结构,又面临网络训练难的问题,侧面反映了深度学习领域中的循环神经网络RNN以及LSTM对于时序数据优越的处理能力,其中改进后的SATLSTM模型预测精度明显高于其他模型。 表4 不同预测算法评价指标对比 针对当前老化趋势预测方法未考虑老化数据的依赖关系以及准确率低的问题,本文以深度学习的循环神经网络LSTM为基础,结合老化数据突变和多依赖的特点,对Web系统内存资源的消耗情况进行建模。针对LSTM网络对远距离信息利用率低且前后老化信息对目标输出影响程度不同的问题,在传统LSTM网络的结构上,结合自注意力机制,进一步提出并建立了一个基于SATLST的软件老化趋势预测模型。实验结果表明:SATLSTM预测模型与Web服务器资源老化趋势一致,与传统的预测模型ARIMA以及BP神经网络相比预测度高、泛化能力好、误差较小,能准确地对软件老化趋势进行预测。



3 实 验
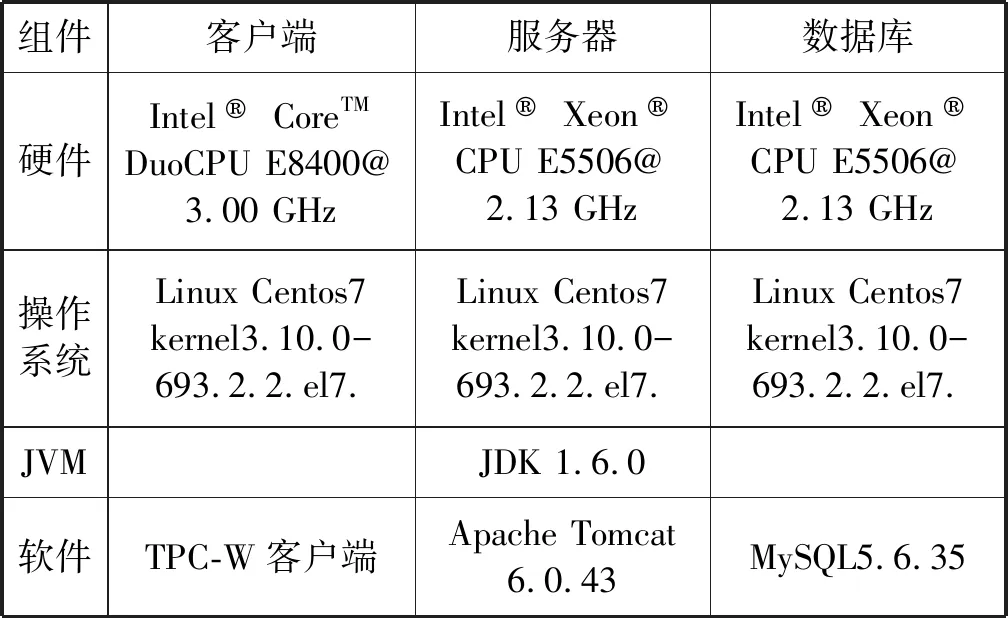
3.1 实验环境

3.2 评价指标
3.3 参数设置与优化

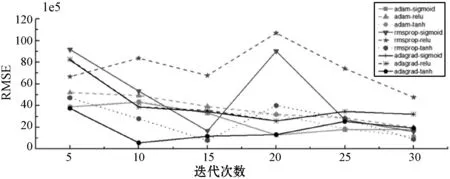
3.4 实验结果分析

4 结 语
