基于LCS的逻辑重构算法的研究
2020-04-18黄玉林
黄玉林 刘 丹
(东北林业大学信息与计算机工程学院 黑龙江 哈尔滨 150040)
0 引 言
软件工程开发的复杂度越来越大,系统维护成本越来越高。同时,维护人员也难以理解和维护系统,并且维护效率不高。国内外学者对如何降低系统的复杂度来提高系统的可维护性、可扩展性做了许多研究。
软件复杂度主要依赖于系统结构复杂性,因此分析软件结构成为了关键的问题。有研究者通过软件模块划分来分析软件结构,其实际上可以视为聚类问题[1]。一些研究者改进了传统的聚类搜索方法,如模糊C均值(fuzzy C-means,FCM)聚类算法[2]、模糊聚类算法等[3]。还有一些研究者使用基于复杂网络的理论来解决软件模块划分问题[4-6]。文献[7]提出面向关系的架构的概念,用重构三步法来降低软件复杂度,实际上也是在划分模块。重构三步法主要是获得系统的组件和组件的关系,然后对提取的组件和组件的关系进行逻辑重构,再把逻辑重构得到的架构植入到遗留系统当中。重构三步法让架构易于理解,运用在维护中时容易发现系统中的问题,降低软件维护的成本,对架构中组件之间的关系用二维表表示,运用机器学习中非监督学习的方法处理二维表来得到架构[11]。对提取的架构进行逻辑重构实际上是对软件的模块进行重新划分。关于逻辑重构中的划分方法,有研究者在逻辑重构中使用关联规则的方法MINP_Apriori,通过寻找频繁集来对软件模块进行划分。文献[7]从优化角度,计算带约束的距离总和的最小值来对软件模块划分进行研究。虽然这些逻辑重构的方法准确度高,但是效率较低。
本文为提高逻辑重构的效率提出了改进的方法。通过用二维表表示组件之间的关系并以其行为向量,找出有交集的行向量。用行向量之间的交集数量来刻画行之间的相似程度,以此来获得软件的模块划分。与已有的关联规则方法和等级簇聚合算法不同的是,此方法不需要反复寻找频繁集或者计算距离。
1 算法设计
1.1 软件重构
软件重构[12]分为物理重构和逻辑重构。物理重构需要改变代码,而逻辑重构无需改变代码和软件可观察行为[13-14]。从旧架构到新架构这一步骤为逻辑重构,如图1所示。重构三步法为:1) 通过爬取,获得遗留系统组件和组件的关系,得到旧架构;2) 对旧架构进行架构转换;3) 把组件关系清楚的新架构植入到遗留系统中。
逻辑重构是对提取的组件和组件之间的关系分类。数据规模较小时,从竖线的左半边到右半边或者相反方向移动组件或者表,使穿过中间竖线的线条数最少。如果规模增大,先使用上述方法先把组件分为两部分,使得穿过竖线的线条数最少,再对各个部分使用相同方法,直到每次划分穿过竖线的线条数最少,最后把混乱的组件关系变得清晰[7]。图2为简单例子的移动步骤,原始的混乱组件关系中穿过中间的竖线的线条数量为10,移动组件5到竖线右边后,穿过竖线的条数为8,移动组件4和组件2到竖线的左边。接着移动组件3到竖线的右边,穿过竖线的条数为7,经过多次移动组件或者表,穿过竖线的条数为1,此时不能再进行移动来减少穿过竖线的条数,最终组件被划分成两部分。当用二维表来表示组件关系进行移动时,组件划分具有可计算性,运用上述方法容易得到架构的模块数目以及层次关系[15-16]。后续还需要经过相关算法处理,得到层次分明的架构。
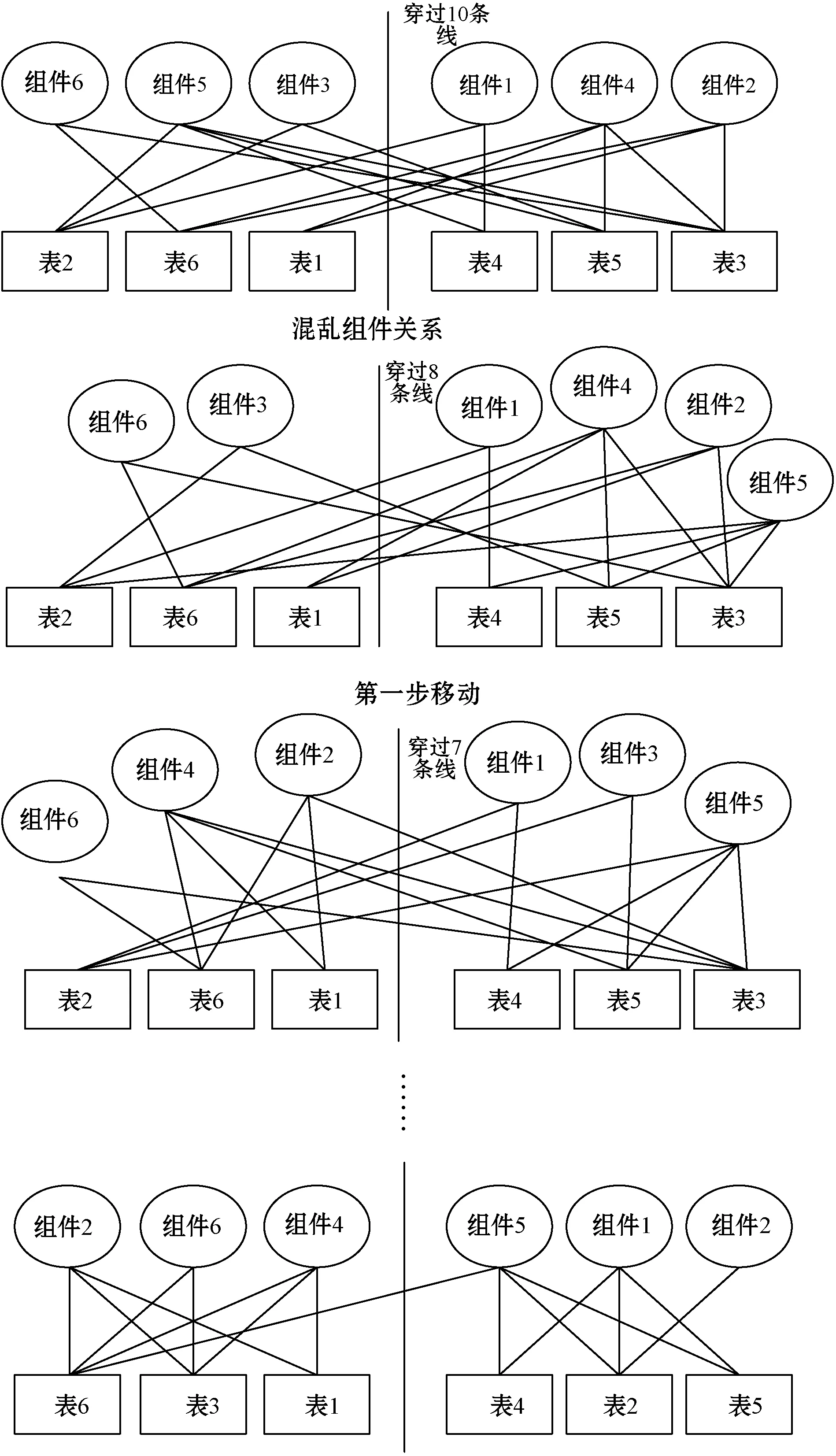
图2 逻辑重构实例移动步骤[7]
1.2 设计思想
设计的软件内聚越高,组件间的相似程度越高。等级簇聚合算法在高内聚的基础上,通过距离来刻画组件的相似程度,最终得到模块。等级簇聚合算法需要反复计算组件之间的距离,因此算法时间复杂度为O(n3)。当数据规模变大时,计算时间会成为劣势。由于系统中一些组件会频繁对数据库操作,若多个组件对相同的几个数据表操作,那么这些组件的相似程度高。依据组件和数据表之间的关系,使得相似程度高的组件聚集,从而改善等级簇聚合算法在规模变大时的效率低下的状况。另外,若通过二维矩阵计算有交集的组件之间的距离,可以减少等级簇聚合算法的计算量。因此,可以基于高内聚以及组件和数据表的关系,以及二维表计算组件间的相似程度来区分不同的组件,最后得到清晰的组件关系。
设n维空间的向量F1=(x11,x12,…,x1n)和F2=(y11,y12,…,y1n),且x,y∈{1,0}。如果把两个向量当作0与1的字符串,容易得知两字符串中同一位置不同的字符数量R:
(1)
进而可知字符串中同一位置相同且为1的数目L:
(2)
若L大于设定的阈值η=(max(Nj)-min(Nj)+1)/2,Nj为组件间交集的数量,那么F1与F2相似,否则不相似。其中Nj为组件间交集的数量。
如表1所示,用矩阵表示组件之间的关系。组件间存在关系用1表示,没有关系用0表示。把Function1与Function2当作0与1的字符串,用最长公共子序列的方法来求两者之间的相似程度L。最长公共子序列越长,则相似程度越大。由于字符串中只有0和1,可以把Function1与Function2视为n维的向量。如表1所示,与数据表有最多关系的为Function1,与Function1有交集的行向量为Function2到Function7。Function1与其他向量的相似程度依次为:2、2、4、1、2、2,阈值η为2,则Function1与Function4相似。剩下的向量中与数据表关系最多的为Function2,与其有交集的为Function3、Function5、Function6、Function7。相似程度L依次为:4、3、3、3,此时阈值为1,Function2、Function3、Function5、Function6、Function7相似。分类完成,Function1与Function4为一类,Function2、Function3、Function5、Function6、Function7为另一类,模块数为2。

表1 组件与数据表二维表示
算法具体步骤如下:
输入:通过爬取,获得组件与表、组件与组件的关系表。
输出:集合M。
(1) 读取表中的未作访问标记的关系表,计算每一个组件与其他组件的相关程度,并对相关程度进行排序,得到相关程度最大的组件Fi。记Fi以及与Fi相关的组件为集合S。
(2) 计算Fi与集合S中其他组件两两之间的交集数量Nj,若Nj>η,则记为相似度高的方法集合Mi,并用集合M记录Mi。在二维表中对Mi中的点做访问标记。
(3) 若二维表中还有没被访问的标记,则进行步骤(1),若没有,则结束。
算法流程如图3所示。
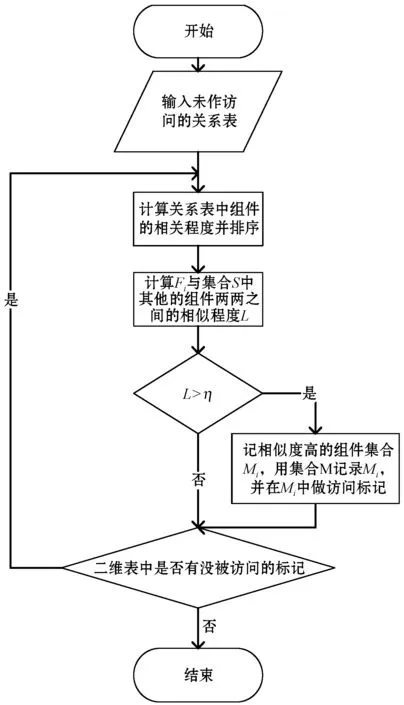
图3 基于LCS的逻辑重构算法流程图
2 实 验
把本文算法和文献[17]算法以及MPIN_Apriori算法[18]对比。文献[17]算法是高内聚领域构建的确定策略。本文对遗留软件进行软件重构可视作软件架构演化,可以用文献[17]算法解决本文的逻辑重构的问题。最后,用开源软件对理论分析的结果进行验证。实验所使用的5个系统如表2所示,其中:电话簿管理系统是自主研发的小型系统;PARTS系统的组件与数据表关系以及组件与组件的关系源自文献[7];仓库管理系统的下载地址为http://www.zuidaima.com/share/3379815806995456.htm,采用Spring框架、Apache Shiro框架、ORM框架;办公后台管理系统的下载地址为http://www.zuidaima.com/share/3832681781857280.htm,采用Spring框架、Spring MVC框架、Mybatis框架;工程财务管理系统的下载地址为http://www.zuidaima.com/share/4238345894398976.htm,采用Spring框架、Spring MVC框架、Hibernate框架。实验中的算法使用MATLAB语言编程实现。部分数据的爬取采用Java语言实现。运行计算机内存为4 096 MB,处理器为Corei5-4210U(1.7 GHz)。

表2 实验数据
2.1 实验设计
实验以开源系统为数据,用基于LCS的逻辑重构算法对实验数据处理,并与等级簇聚合算法、MPIN_Apriori算法结果进行对比,以验证本文算法的有效性以及合理性。
实验从特殊到一般,先用一个简单的系统验证合理性,再用多个开源系统对基于LCS的逻辑重构算法的普适性进行验证。IDEAT是自主研发的小型系统,能够明显得出模块的数目。以IDEAT为测试用例,从理论上验证基于LCS的逻辑重构算法的合理性。随后,使用基于LCS的逻辑重构算法、等级簇聚合算法以及MPIN_Apriori算法对其余3个开源系统处理,并对其中一个系统具体分析。由于仓库管理系统组件与数据表的关系规模较大,适合进行模块分析,所以以仓库管理系统为例。首先使用Java程序对源代码爬取,获得组件和数据表的关系,结果如图4所示。

图4 仓库管理系统组件和表的关系
通过基于LCS的逻辑重构算法对图4中矩阵进行处理,结果如图5所示。

图5 基于数据表的组件划分结果
经过与源代码的对比分析,准确得到了部分组件的划分结果。图5中的组件与数据表有直接关系,即部分组件被划分。结合组件和组件的关系,可以使其余的组件被划分。经过对WMS源代码的爬取,获得图6所示的组件与组件的关系。通过基于LCS逻辑重构算法对矩阵的处理,得到图7所示的组件的划分结果。合并图5与图7的划分结果,得到最终的模块划分。
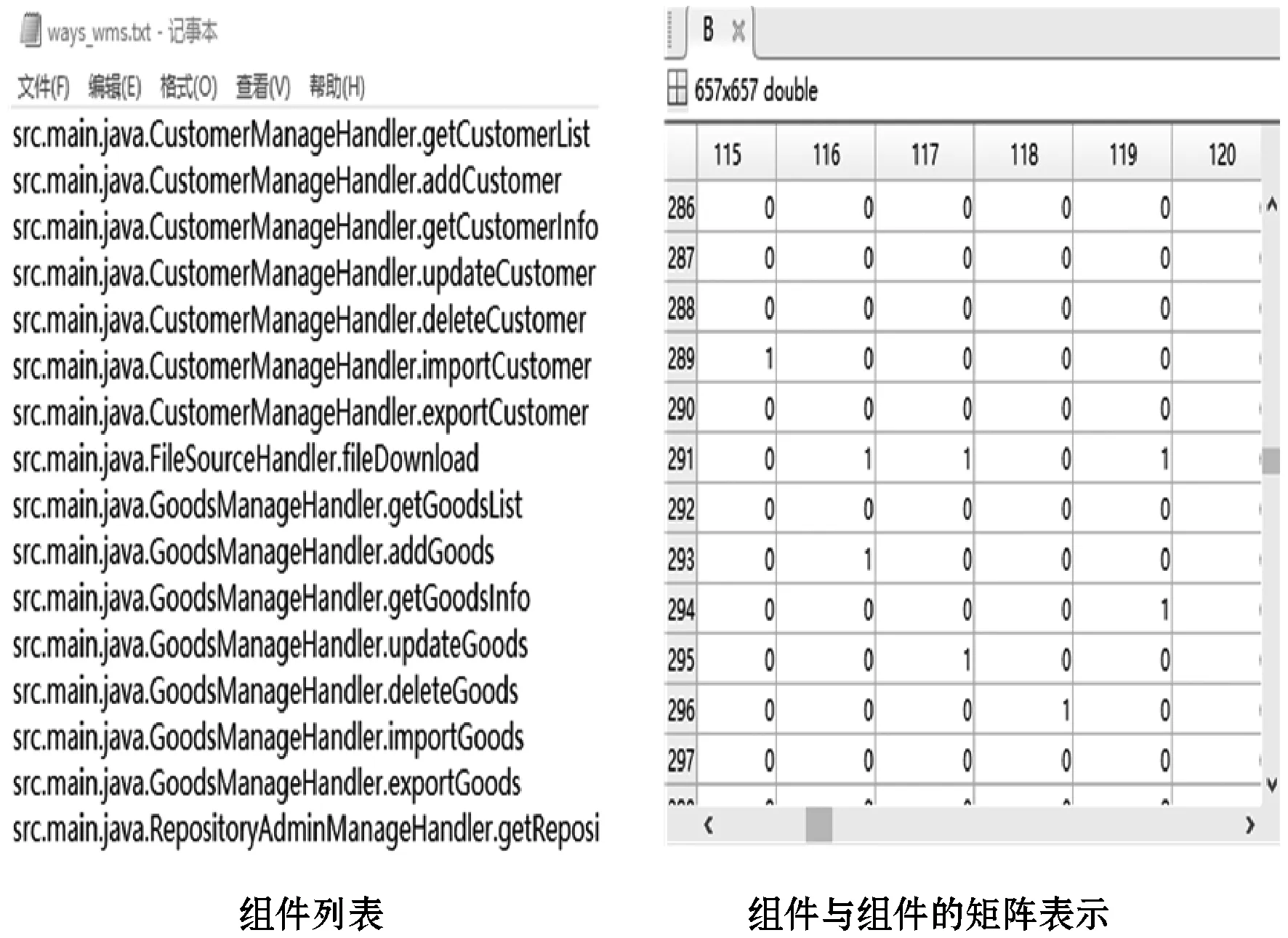
图6 部分组件与组件的关系

图7 基于组件与组件的划分结果
通过把基于LCS的逻辑重构算法、等级簇聚合算法以及MPIN_Apriori的模块划分结果与仔细阅读源代码得到的模块结果对比分析,得到各个算法的划分准确度,结果如表3所示。
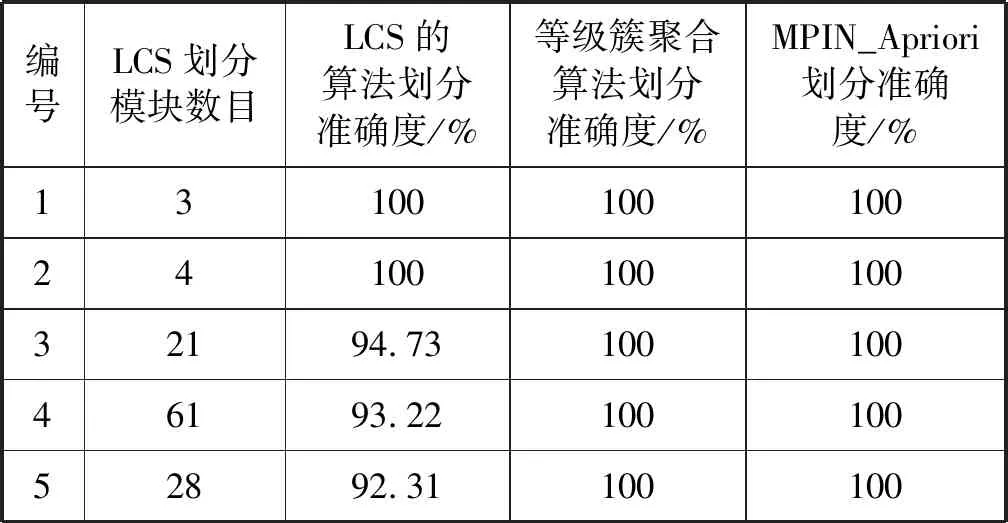
表3 基于LCS的逻辑重构算法划分结果及准确度
在划分准确度的基础上,对算法的划分效率进行了对比,以此验证算法的有效性。图8为基于LCS的逻辑重构算法、等级簇聚合算法以及MPIN_Apriori算法分别对表2中的实验数据进行处理的结果。

图8 三种算法对不同规模数据集的运行时间比较
本文在理论数据的分析基础上,对开源系统也进行了分析。和文献[7]提供的数据规模不一样的是,工程财务辅助系统、办公后台管理系统属于中小型系统,不能直接得到表1中的信息,所以对于这样规模的系统,使用源码分析工具(如Understand)获得实验信息,如方法个数、数据表个数等。实验中的组件关系二维表数据通过Java语言编程获得,也就是对系统中的Function和DataEntity的关系以及Function与Function的关系进行了爬取。实验结果中的耗费时间是通过MATLAB两行代码tic与toc得出。
2.2 结果分析
基于LCS的逻辑重构算法实际上是对关系密切的组件之间的相似程度进行了刻画。在逻辑重构这一步骤中,本文算法和其他的聚类算法相比,优势在于重构速度。由表3与图8可知,与其他聚类算法得到的模块数一样情况下,基于LCS的逻辑重构算法的速度较快。在数据规模为755时,速度提升87.92%,数据规模为1 668时,速度提升33.56%,数据规模为1 702时,速度提升26.44%,基于LCS的逻辑重构算法与MPIN_Apriori算法相比,整体上速度提升51.51%。这表明当数据的规模开始变大时,相比于基于LCS的逻辑重构算法,等级簇聚合算法明显变得慢了。与此同时,本文算法在有较小的误差情况下,速度较其他算法快。基于LCS的逻辑重构算法与其他算法的比较结果如表4所示。

表4 与其他算法的比较
MPIN_Apriori算法计算的时间T为:
(3)
式中:RLen与kM为常量,决定算法时间的是中间一项,可知算法的时间复杂度为O(n2)。等级簇聚合算法的步骤如下:(1) 将每一个变量ki(i=1,2,…,m)初始化为一个簇,并组成一个簇集合;(2) 如果簇集合的长度为1,转步骤(4),否则继续下一步;(3) 簇中变量间的平均距离作为簇间的距离,合并距离最近的两个或多个簇为一个新簇,更新集合C。(4) 结束。步骤(2)和步骤(3)决定着算法的性能,计算时间最多为Tc=CL·CL·CL,其中CL为集合的长度。由此可知等级簇聚合算法的时间最大的复杂度为O(n3)。基于LCS的逻辑重构算法的主要步骤如下:
while length(find(visit(:,2)==0))>0
%若存在没有访问的点,继续循环
……
index6=zeros(length(index4),2);
for k=1:length(index4)
%计算相似程度L
index5=A(index1,1:b)+A(index4(k),1:b);
index6(k,1)=length(find(index5==2));
index6(k,2)=A(index4(k),b+1);
end
value=(max(index6(:,1))-min(index6(:,2))+1)/2;
index7=index6(index6(:,1)>value,2);
index7(length(index7)+1,1)=A(index1,b+1);
……
end
由于计算相似程度L的for循环为常数项,while循环次数为组件的个数,因此基于LCS的逻辑重构算法的时间复杂度为O(n)。
逻辑重构是重构三步法的一个环节,是软件维护过程中分析软件架构的一个重要的方法。基于LCS的逻辑重构算法在各类系统上进行了验证,实验结果表明该方法存在模块划分的误差问题,这与获取源代码中组件关系的算法精度以及基于LCS的逻辑重构
算法阈值的确定有一定的关系,但是对分析整体模块所带来的影响很小[12]。由表4可知,基于LCS的逻辑重构算法优势在于重构的速度,这提高了中小型系统分析软件架构的效率。
3 结 语
本文在高内聚和最长公共子序列的基础上,提出了逻辑重构中一种改进的算法。通过把获取的组件与组件关系的二维表的行作为向量,计算向量的相似程度L,以此来刻画组件的相似关系,最终得到组件的划分模块。实验使用不同规模的开源数据,用基于LCS的逻辑重构算法、等级簇聚合算法以及MPIN_Apriori算法处理实验数据并进行对比分析。实验结果表明,相比于等级簇聚合算法,基于LCS的逻辑重构算法有更快的速度,且与MPIN_Apriori算法相比,整体上速度提升了51.51%。
在重构三步法中,此算法为逻辑重构中分析模块数目的方法。在得到了划分的模块后,还需要其他方法对此结果进行处理,得到一个具有分层结构的软件架构,而如何准确且有效率地得出具有分层结构的架构,还需进一步的研究。
