基于编码器-解码器重构框架的蒙汉神经机器翻译
2020-04-18孙晓骞苏依拉赵亚平王宇飞仁庆道尔吉
孙晓骞 苏依拉 赵亚平 王宇飞 仁庆道尔吉
(内蒙古工业大学信息工程学院 内蒙古 呼和浩特 010080)
0 引 言
自从2013年Cho等[1]提出基于编码器-解码器架构的神经机器翻译开始,该框架在机器翻译领域获得了迅速发展,相对于统计机器翻译而言在翻译质量上获得了显著提升。其中编码器和解码器均为循环神经网络(Recurrent neural network,RNN),编码器RNN将输入的源语言句子编码为维数固定的向量表示,解码器RNN将该表示解码为目标语言句子,通过联合训练编码器和解码器最大化了输入句子的条件概率[2-3]。在此基础上,Bahdanau等[4]提出了在端到端机器翻译模型基础上添加注意力机制的方法,该方法有效地提高了神经机器翻译的质量。然而研究人员并没有因此停止对机器翻译研究的步伐,2015年Luong等[5]研究了两种简单有效的注意力机制,一种始终关注所有源词的方法,另一种只关注源词子集的局部方法。分别证明了全局注意力和局部注意力在英德互译中的有效性。为了缓解机器翻译过程中的梯度消失以及长距离依赖等问题,研究人员提出了一种基于句子级别的长短时记忆模型(Long Short Time Memory,LSTM)的机器翻译系统[6]。
尽管传统的端到端神经机器翻译框架已经取得了显著的效果,但依然存在着一个主要的缺点,该框架倾向于反复翻译某些源词,而错误地忽略掉部分词。这就导致了严重的过译和漏译现象。这是由于传统的编码器-解码器架构没有一种机制来确保源端的信息完全转化到目标端。
针对上述问题,2016年Tu等[7]提出了神经机器翻译的覆盖模型,有效地缓解了带有注意力机制的神经机器翻译中的过译和漏译现象。该方法的实现原理是:在基于注意力机制的神经机器翻译模型上,让覆盖向量和注意力向量做一些结合,即在解码器解码的过程中,对那些已经被翻译过的源语言的单词降低“注意力”,也就是降低其被再次翻译的可能性。直接的解决办法就是:把覆盖向量和注意力结合在一起,这样用覆盖向量去调节注意力,从而起到“纠正”注意力的作用。然而该方法只能在带有注意力机制的神经机器翻译模型上实现,并不适用于所有的基于端到端的神经机器翻译模型。
因此,Tu等[8]提出了一种在传统的编码器-解码器框架的基础上添加重构器的方法,目的是通过为传统的编码器-解码器框架添加一种机制来确保源端的信息完全转换到目标端,该方法适用于所有的编码器-解码器框架。实验结果表明,译文的充分性确实和重构器具有紧密的联系。
本文在Tu等研究的基础上,提出基于编码器-解码器重构框架的蒙汉神经机器翻译方法,同时使用词向量的分布式表示将实验使用所有数据集转化为向量的形式,将传统的带注意力机制的编码器-解码器框架作为基线系统。实验结果显示,该方法能够有效地缓解蒙汉神经机器翻译中的过译和漏译现象。
1 模型搭建
1.1 词的向量化表示
为何机器可以理解人类的语言并完成对于人类来说非常耗时的任务?如:机器翻译、人机对话、文本分类等任务。是因为在自然语言处理中,首先对自然语言的符号进行了数学化,该过程被称为词的向量化表示[9-10]。
在自然语言处理任务中,词的向量化表示方法主要有两种:词的独热表示和词的分布式表示[11-12]。
(1) 词的独热表示 词的独热表示是指:将每个词表示为一个很长的向量,该向量的维度是词典的大小,其中绝大多数元素为0,只有一个维度的值为1,这个维度就代表了当前的词,因此,该方法也被称为1-of-K。到目前为止,在自然语言处理中,因其简单易用性成为最常用的词表示方法。
但这种表示方法也具有一定的缺陷,随着词典规模的增大,会引起维数灾难问题以及任意两个词之间都是孤立的,根本无法表示出语义层面上词与词之间的相关信息等问题[13]。
(2) 词的分布式表示 如何将语义信息融入到词典中呢?1954年Harris[14]提出的分布式假设为这一设想提供了理论基础。词的分布式表示方法有:基于矩阵的分布式表示、基于聚类的分布式表示以及基于神经网络的分布式表示,基于神经网络的一般称为词嵌入。
词嵌入是随着深度学习和神经网路的兴起而开始流行的词表示方法[15]。该方法由Hinton提出,主要思想是:在词向量中抓取一个词的上下文信息,用来刻画该词与其上下文之间的联系,缓解了独热表示中无法表示语义层面词与词之间关联的缺陷,同时将向量中每个元素由整型改为浮点型,变为整个实数范围的表示,将原来稀疏的巨大维度压缩嵌入到一个更小维度的空间,缓解了独热表示中的维数灾难问题。
因此,本文采用词向量的分布式表示方法。2013年谷歌公开了一款用于训练词向量的软件工具Word2vec[16]。Word2vec采用skip-grams[17]或连续词袋模型(CBOW)[18]获取与上下文相关联的词向量,skip-grams的结构如图1所示。
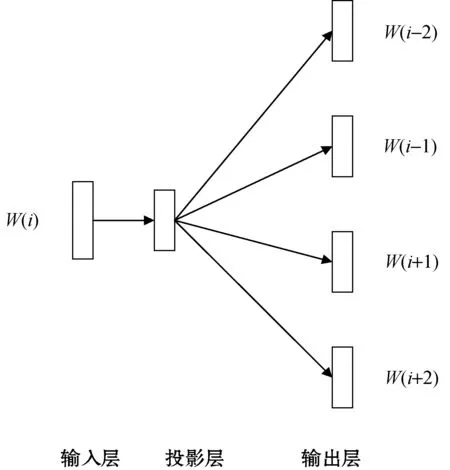
图1 skip-gram模型结构
由图1可知,skip-grams模型与去除隐含层的前馈神经网络模型正好相反,其原理是根据上下文分类当前词。采用当前词wi训练上下文词向量来估计周围词的词向量用以表示上下文信息。该方法的优点是可以从大规模数据集中得到较高质量的词向量,并缓解维数灾难问题。
1.2 编码器-解码器架构
自编码器-解码器架构被提出以来,受到了研究人员的广泛关注,现已成为神经机器翻译的基本模型[19]。其结构如图2所示。
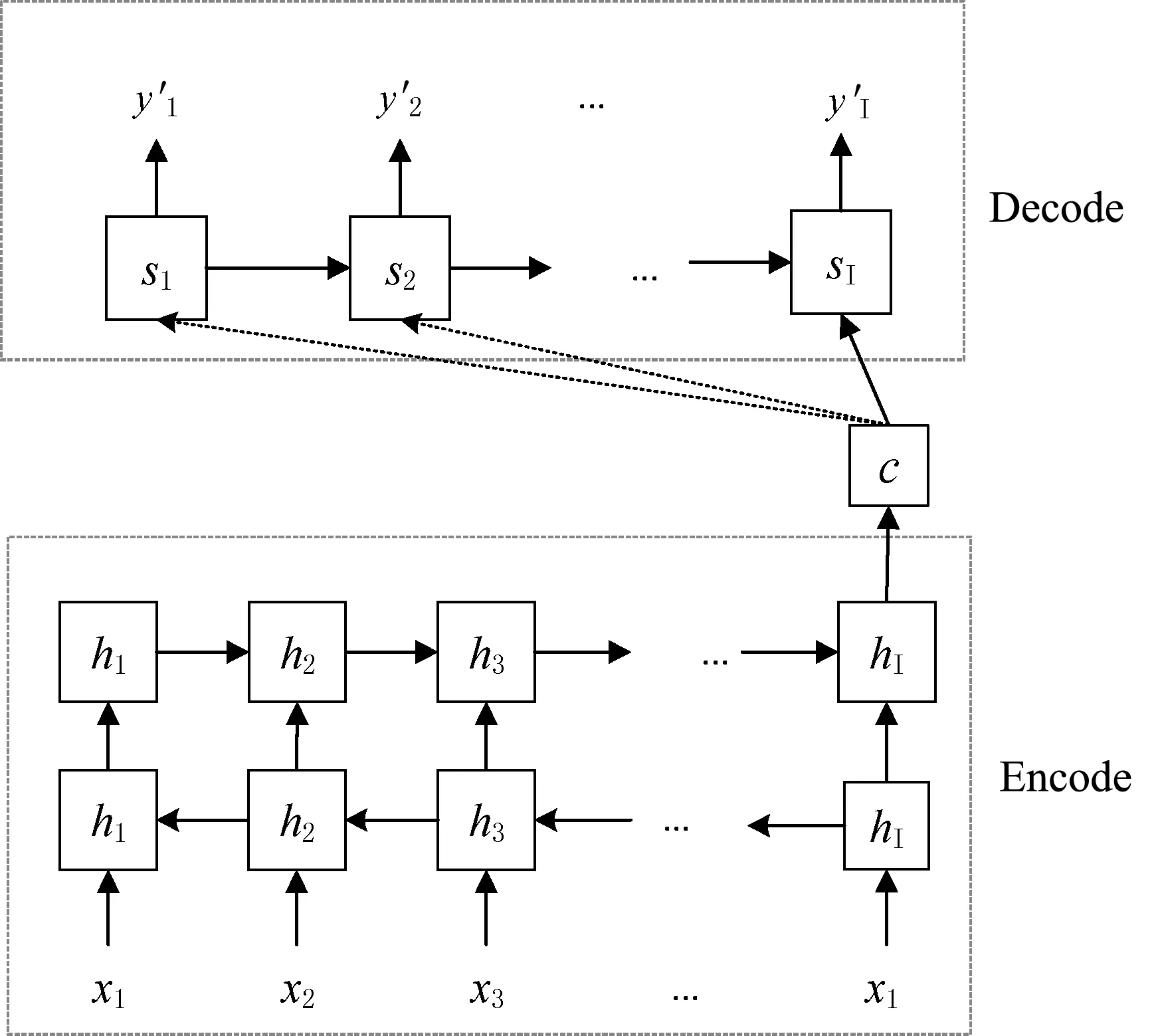
图2 编码器-解码器框架
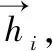
(1)
c=q({h1,h2,…,hn})
(2)
式中:f和q均为非线性函数。
得到上下文向量c和前i-1个已经生成词{y1,y2,…,yi-1}的条件下,通过训练解码器来预测下一个词yi。生成词yi的概率计算式表示为:
(3)
p(yi|{y1,y2,…,yi-1},c)=g(yi-1,Si,c)
(4)
式中:si表示解码器i时刻的隐藏层状态,表示为:
si=f(si-1,yi-1,c)
(5)
1.3 基于注意力机制的编码器-解码器架构
相比于统计机器翻译,基于编码器-解码器架构的神经机器翻译方法显著提高了机器翻译译文的质量。但是,单纯的编码器-解码器框架在计算产生某个词的概率时,使用了固定的上下文向量c,意味着无论生成目标语言中的哪一个词,参与生成这个词的上下文向量都是相同的,这显然是个很粗糙的做法。注意力机制在神经机器翻译中的应用有效地解决了这个问题,其结构如图3所示。
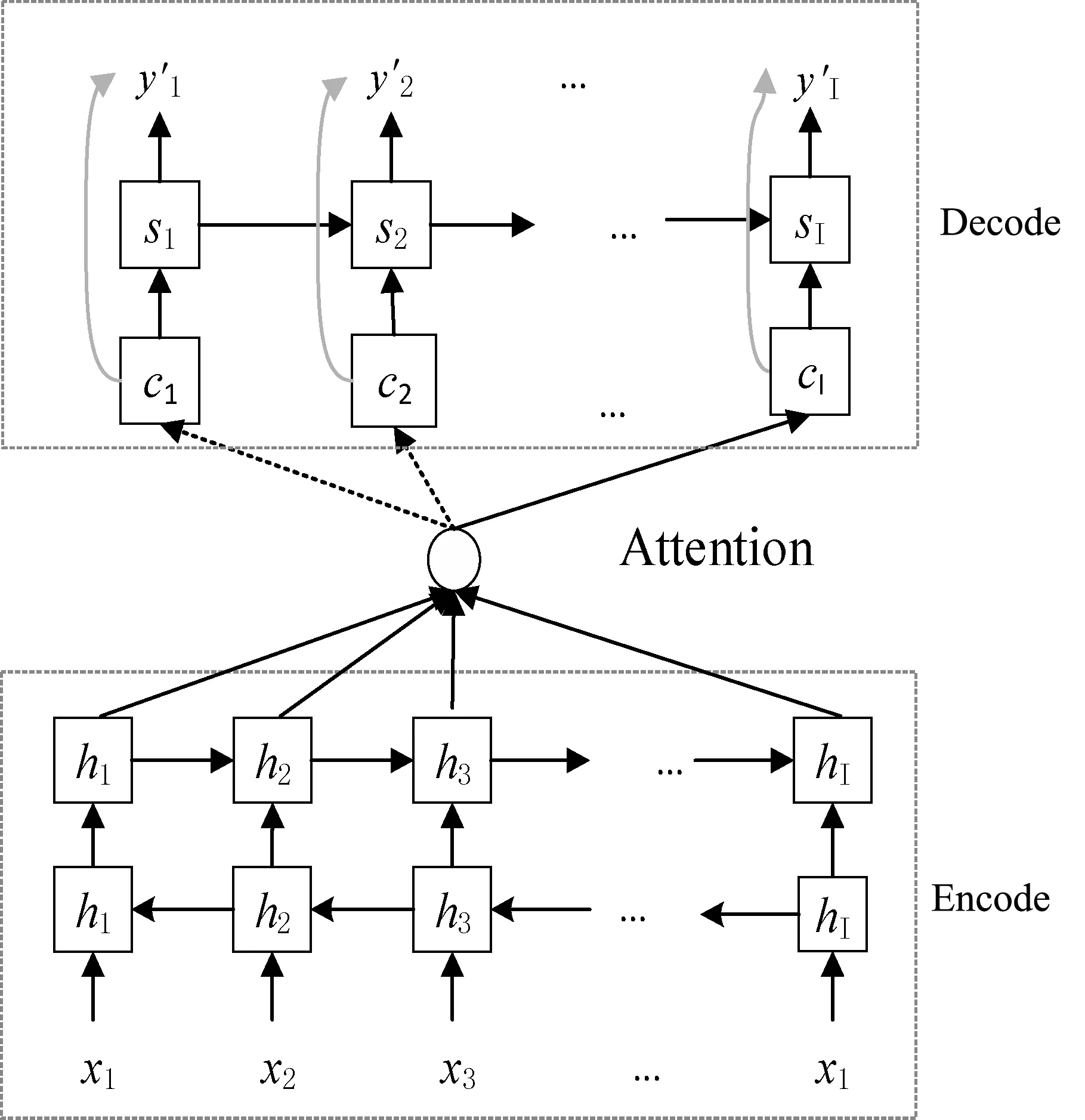
图3 基于注意力机制的编码器-解码器框架
在基于注意力机制的编码器-解码器架构中,生成第i个词的概率,表示为:
p(yi|y1,y2,…,yi-1,x)=g(yi-1,si,ci)
(6)
值得注意的是,此时的上下文向量由原来固定的c变为了ci,即在生成目标语言中的每一个词时,源语言中的词对待生成的词的影响是不同的,比如:“Tom chase Jerry”,在生成“汤姆”这个词时,注意力会主要集中在“Tom”这个词上,显然这能够提高将“Tom”译成“汤姆”的概率,可以有效地提高译文的质量。式(6)中ci计算式表示为:
(7)
(8)
eij=a(si-1,hj)
(9)
1.4 编码器-解码器重构框架
重构器通常由神经网络实现,如RNN、LSTM等,是由Bourlard等于1988年提出。重构是用来测量重构输入与原始输入是否相似,用在机器翻译中,就是考虑机器译文与人类译文的差距,从而判别机器的译文是否充分。编码器-解码器重构框架是Tu等2016年提出的一种缓解机器翻译过程中过译和漏译现象的神经机器翻译新框架。该模型是在基于注意力机制的编码器-解码器架构基础上提出的,此重构器可以在任何端到端的神经机器翻译框架上使用。编码器-解码器重构框架如图4所示。
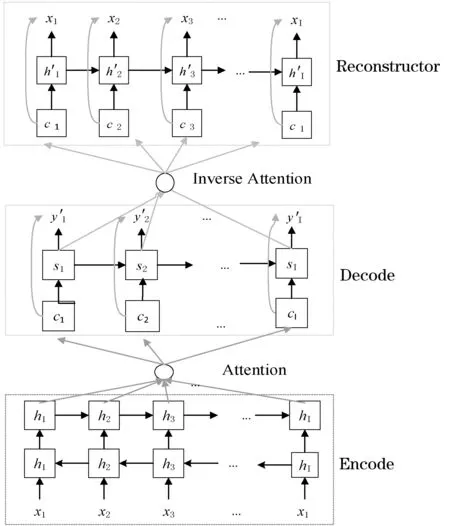
图4 编码器-解码器重构框架
(1) 实现原理 首先,模型中的编码器读取输入语言句子,在本文中就是蒙古语句子,然后解码器生成相对应的汉语句子,最后重构器读取解码器的隐藏层序列并输出重构的输入语言句子,也就是蒙古语。
(2) 实现步骤 首先编码器-解码器架构读取源语言蒙古语句子,产生目标语言汉语句子,该过程与基于注意力机制的编码器-解码器架构实现步骤完全相同。然后,重构器逐字重构出源语言句子。其中重构的概率计算式表示为:
(10)
(11)
(12)
通过观察发现,重构器的重构过程和解码器的解码过程非常相似,只不过解码器是将源语言句子的向量表示解码为目标语言句子,而重构器是将目标语言句子的向量表示重构为源语言句子。
1.5 模型的训练和测试
在模型训练时,使用所有的蒙汉平行数据集(用M表示),同时训练编码器-解码器的参数P(y|x;θ)和重构器的参数R(x|s;γ),其目标函数表示为:
λlogR(xm|sm;γ)}
(13)
式中:目标函数由两部分组成,似然函数用来衡量翻译的流利度,而重构器用来测量翻译的充分性。λ是平衡似然和重构的超参数,本文中选λ为1。使用BLEU值作为本文译文质量的评测标准。
2 实 验
实验数据为67 288句对蒙汉平行语料,由内蒙古大学开发。首先对蒙汉平行语料进行了预处理同时分别生成了大小为3万的蒙汉对齐词典,然后通过使用自动法进行语料的划分,划分结果如表1所示。
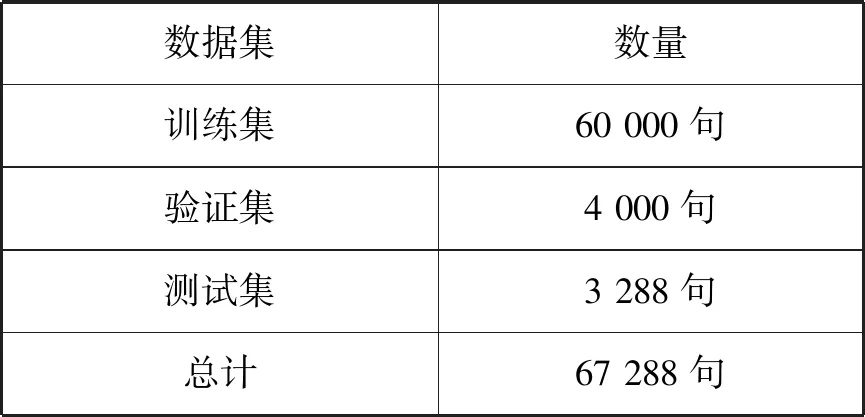
表1 数据集划分表
本文的整体框架如图5所示。
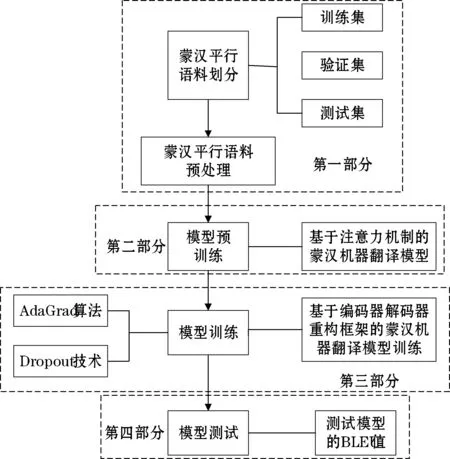
图5 整体框架图
图5中,第一部分是对数据集的划分及预处理,将67 288句对蒙汉对齐语料划分为训练集、验证集及测试集,将蒙汉对齐语料中的汉语进行中文分词。第二部分为模型的预训练即对基于注意力机制的蒙汉神经机器翻译模型的训练。第三部分为基于编码器-解码器重构框架的训练,使用了AdaGrad算法及Dropout技术,缓解了蒙汉翻译模型的过拟合现象。第四部分通过测试BLEU对基于编码器-解码器重构框架的蒙汉神经机器翻译进行评价。实验中采用Skip-gram模型在训练集上训练与上下文相关的词向量,词向量的维度设定为512。
2.1 模型训练
(1) 模型预训练 基于编码器-解码器重构框架的蒙汉神经机器翻译模型的训练需要首先对基于注意力机制的编码器-解码器框架进行预训练,本文使用了东京都立大学开源的神经机器翻译模型nmt-chainer。将经过预处理的67 288句对蒙汉平行语料通过该框架进行预训练,测试得前30轮所得模型的BLEU值如表2所示。
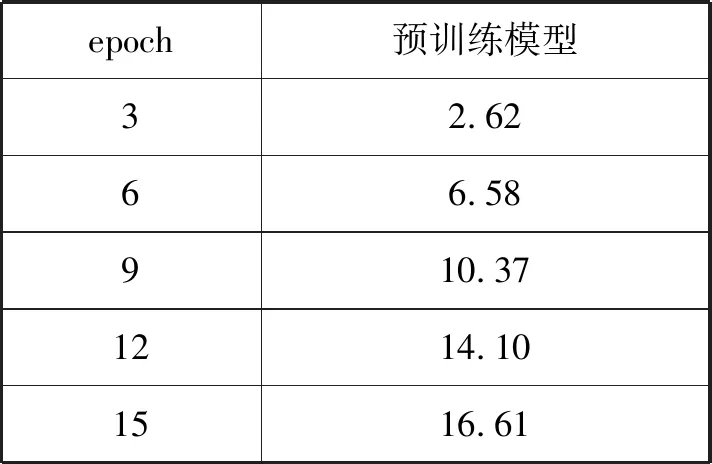
表2 预训练模型的BLEU值
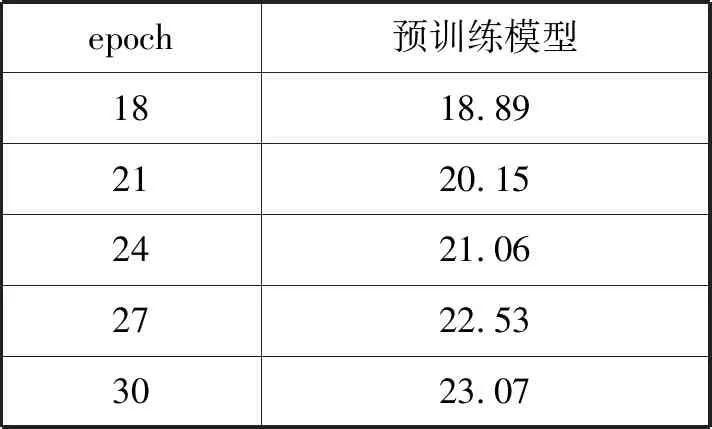
续表2
(2) 编码器-解码器重构模型训练 编码器-解码器重构框架同样使用了由东京都立大学开源的模型Reconstructor-NMT[20]。首先从预训练模型中挑选出BLEU值最高的一轮作为重构模型训练的初始模型。在训练的过程中,使用AdaGrad算法,学习率为0.01,batch_size为32,dropout为0.2,epoch设为30,最终测得前30轮所得模型的BLEU值如表3所示。
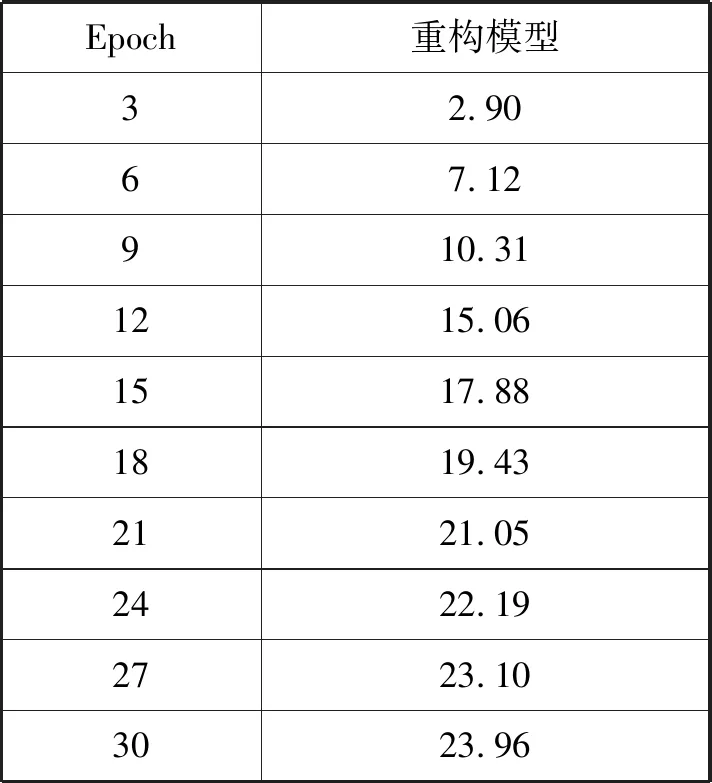
表3 重构模型的BLEU值
2.2 实验结果对比与分析
将基于注意力机制的神经机器翻译模型(Baseline-NMT)作为基线系统,训练了没有经过预训练的编码器-解码器重构框架(Reconstructor),另外,从基于注意力机制的神经机器翻译模型中挑选出BLEU值最高的模型作为初始模型来训练编码器-解码器重构模型(Reconstructor(Jointly))。分别对三个模型的BLEU值进行了跟踪,得到3种模型的BLEU值对比结果如表4所示。
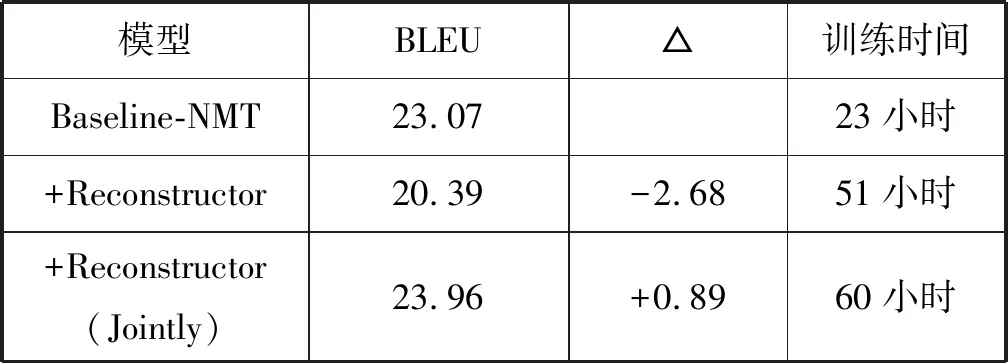
表4 对比实验的BLEU值
由表4可得,如果在训练编码器-解码器重构框架之前不做模型的预训练,加了重构器之后的模型翻译效果反而会比基线降低;而首先通过预训练,然后再进行编码器-解码器重构框架的训练,得到的模型翻译效果会比基线增长0.89个BLEU。加了重构器的模型训练时间明显加长了。
对基线模型即基于注意力机制的翻译模型和(Reconstructor(Jointly))模型的BLEU值进行跟踪,得到这两种模型的BLEU值随着训练周期的增加而变化的情况如图6所示。
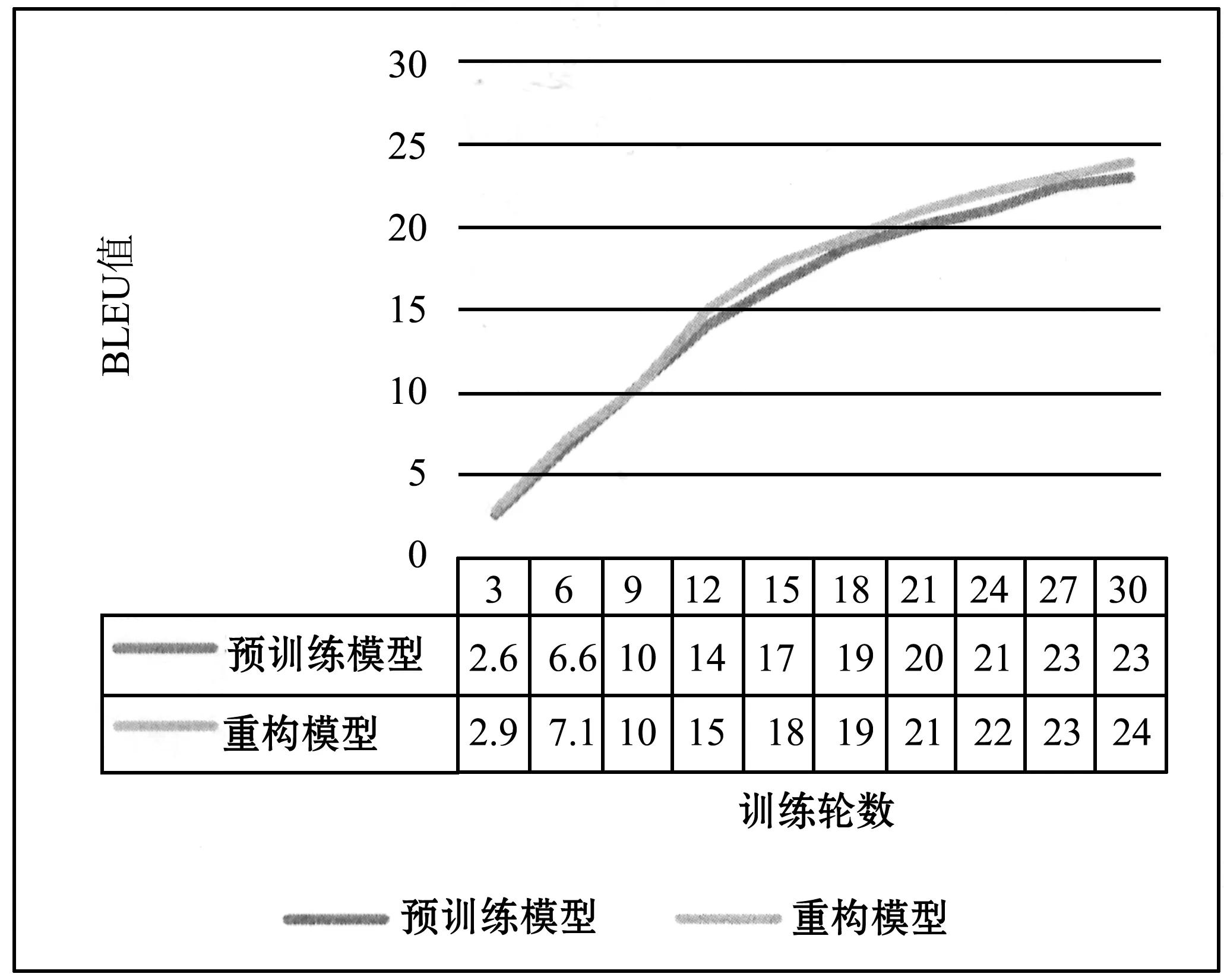
图6 三种模型BLEU值对比图
使用测试集对基线模型、Reconstructor及Reconstructor (Jointly)模型进行测试,随机抽取部分测试结果的对比如表5所示。

表5 机器翻译译文示例对比
由表5可知,基线系统的译文基本可以表达语义信息,但是存在过译和漏译的现象,Reconstructor (Jointly)模型有效地缓解了基线系统中的过译和漏译现象,而没有经过预训练的重构模型在句意表达上比基线模型更差了。
为了验证加入重构器的优势,从测试集中随机选择了300个句子,表6显示了从测试集里随机选择的300个句子译文中过译和漏译现象的统计结果。
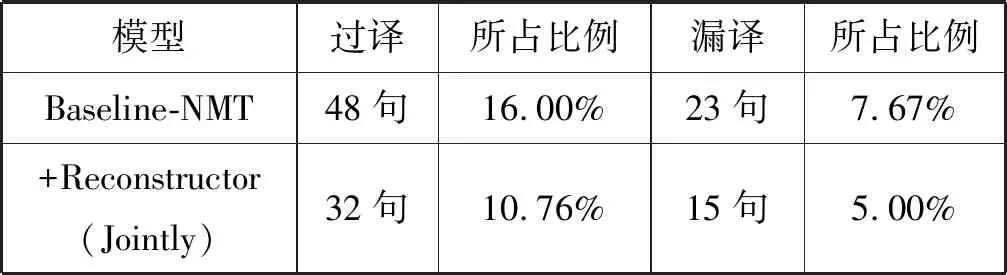
表6 过译和漏译的统计结果
基于注意力机制的蒙汉翻译模型的译文中出现过译现象的句子有48个,出现漏译现象的句子有23个,分别占总数的16.00%和7.67%,而本文所使用的框架得到的译文中,出现过译现象的句子有32个,出现漏译现象的句子有15个,分别占总数的10.67%和5.00%。显然,基于编码器-解码器重构框架的蒙汉机器翻译模型有效地缓解了译文中的过译和漏译现象。
3 结 语
基于端到端的神经机器翻译模型已经相当成熟,但该模型存在过译和漏译问题,因此本文提出了基于编码器-解码器重构框架的蒙汉神经机器翻译方法。为了缓解独热的维数灾难问题,本文首先使用了Word2vec技术处理了蒙汉平行语料库,然后预训练了端到端的蒙汉神经机器翻译模型,最终对基于编码器-解码器重构框架的蒙汉神经机器翻译模型进行了训练,有效地缓解了蒙汉机器翻译过程中的过译和漏译现象。但由于蒙汉平行语料库相对比较匮乏,因此,得到的翻译模型质量不是特别理想,所以获取广覆盖面高质量的蒙汉平行语料库成了未来提高机器翻译效果的研究重点之一。
