基于多粒度的蒙汉神经机器翻译研究
2020-04-18苏依拉牛向华范婷婷仁庆道尔吉
高 芬 苏依拉 牛向华 赵 旭 范婷婷 仁庆道尔吉
(内蒙古工业大学信息工程学院 内蒙古 呼和浩特 010080)
0 引 言
神经网络机器翻译[1](Neural Machine Translation,NMT)是用神经网络实现机器翻译的技术。NMT与语言无关,它负责把一个输入序列转换成为一个输出序列[2],输入序列的基本粒度对翻译结果有一定的影响[3]。
我国是一个由56个民族组成的国家,蒙古族是重要的组成成员之一。伴随着“一带一路”经济带的发展,我国内蒙古自治区经济逐渐繁荣,对外贸易日益频繁,越来越多的企业与个人来到内蒙古地区进行贸易往来和旅游。因此蒙族与汉族的交流日益频繁,蒙古语被使用的范围越来越广泛。蒙汉神经机器翻译的研究有利于蒙汉之间文化融合和信息共享,具有非常重要的理论和应用研究价值。然而,由于人才和资源的缺乏,蒙汉机器翻译的研究还处于相对比较落后的阶段。
蒙古语有传统的蒙古语和西里尔语蒙古语。本文研究的语料库特指的是传统的蒙古文本和中文文本。传统的蒙古语属于阿尔泰语系,汉语属于汉藏语系,因此两种语言在形式、特征和构成上都有所不同。在蒙文-中文机器翻译任务中,由于蒙汉平行语料缺乏,导致数据稀疏性问题严重,严重影响了模型的翻译效果。在神经机器翻译模型中,词切分技术被广泛应用于西方语言的神经机器翻译中,并取得了良好的效果。因此,语料库的切分是预处理过程中特别重要的一步。语料库粒度的差异导致翻译结果差异很大[4]。较大的输入序列粒度可以保留更完整的局部信息和特征,但可能会导致数据稀疏问题严重。使用较小输入序列粒度可以缓解数据稀疏问题,但是将丢失大量局部信息和特征。因此,为了在有限的数据和硬件资源条件下,提高蒙汉神经机器翻译系统的性能,考虑合适的切分粒度处理是非常重要的。
1 预处理
为了选择合适的翻译粒度,我们分别在源端蒙语和目标端汉语上从词-词、词-子词、子词-词、子词-子词这四个切分方向进行实验。
1.1 词级粒度
蒙古文属于阿尔泰语系[5],它在拼音的方法上与西欧和世界各地的主要拼音文字一样。下面为蒙文句子:

可以看出,蒙古文句子各个词之间由空格隔开,故蒙文本身就属于词级粒度。
不同于蒙古文句子,汉语句子中没有词的界限,因此在进行训练时,一般要将中文进行分词,汉语分词是按照某种规则将连续的中文字符序列进行分割。本文的汉语分词是使用双向LSTM+CRF来实现的。
CRF[6]即条件随机场,是判别式模型,计算公式表示为:
(1)
(2)
式中:Z(x)为规范化因子;tk、sl是特征函数,值取1或者0,当满足特征条件时取值为1,否则为0,tk依赖于当前位置和前一个位置,sl依赖于当前位置;λk、μl是tk、sl对应的权值。
双向LSTM+CRF模型网络结构图如图1所示。
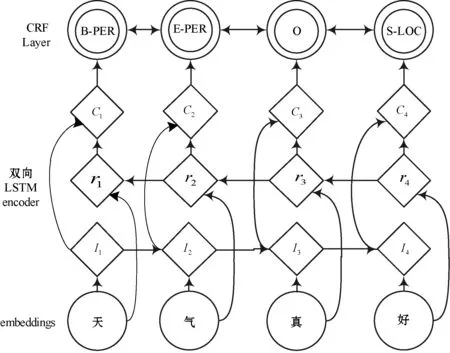
图1 双向LSTM+CRF模型网络结构图
图1中:Ii代表当前单词i以及当前单词左侧上文的信息;ri代表当前单词i以及当前单词右侧下文的信息;Ci代表连接ri和Ii产生的包含上下文信息的单词i的向量。
双向LSTM+CRF其实就是序列标注,输入一个句子时,首先对句子进行字符嵌入,将得到的结果输入给双向LSTM[7],双向LSTM输出当前位置对各词性的得分,然后加一个CRF就得到标注结果[8]。CRF层约束了当前位置对各词性得分加上前一位置的词性概率转移。CRF层的好处是引入一些语法规则的先验信息。
(3)
式中:A代表转移矩阵;P代表双向LSTM网络的判别得分。
训练过程的实质其实是最大化条件概率P(y|X),P(y|X)是正确词性序列的条件概率。
(4)
双向LSTM+CRF分词后的中文句子如下:
不规则 多边形
中文句子经过双向LSTM+CRF分词后,一个中文序列被切分成一个单独的词。
1.2 子词级粒度
子词粒度切分是利用 Sennrich等[9]开发的subword-nmt开源系统进行BPE技术处理。
BPE的思想:将训练语料中的单词拆分成为更常见的子词,在文本长度和词表大小两个方面取得较为平衡的状态,并且一些低频单词的翻译可以通过翻译其中的高频子词来实现。BPE处理后的分词后的中文句子如下:
不@@ 规则 多@@ 边@@ 形
中文进行BPE处理后,由“不规则”变成了更常见的子词“不”和“规则”,“多边形”变成了更常见的子词“多”、“边”和“形”。
BPE处理后的蒙文句子如下:
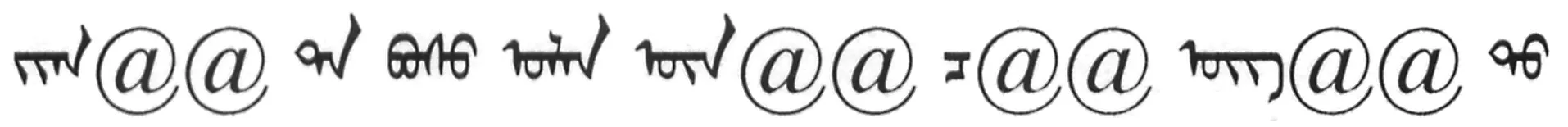
将词分割成合适粒度的子词,能够让机器翻译模型自动学习到一些复杂种类词的翻译方式,例如复合词、同根词等。同时,对蒙古文词进行细粒度切分,可以挖掘其中包含的隐藏信息,使得神经机器翻译模型从更小的层面来学习蒙古文到汉文的翻译。
2 神经网络机器翻译模型
2.1 基于LSTM的蒙汉神经机器翻译模型
LSTM[11]是RNN的一种特殊形式,它有能力学习长期依赖关系,LSTM可以默认记住长时间以前的信息。
门是一种让信息选择性通过的方式,它由一个Sigmoid神经网络层和一个逐点相乘操作组成。Sigmoid层输出{0,1}之间的数字,表示每个组件有多少信息允许通过。0表示不允许信息通过,1表示让所有信息通过。
一个LSTM核心部件有3个这样的门,分别为遗忘门、更新门和输出门。
(1) 遗忘门:决定对于之前状态Ct-1是留下还是去除,其通过输入xt和上一层的隐藏状态ht-1来决定是否需要保留之前的状态。
ft=σ(Wf·[ht-1,xt]+bf)
(5)
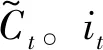
it=σ(Wi·[ht-1,xt]+bi)
(6)
(7)
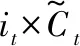
(8)
(3) 输出门:决定隐藏状态ht的输出值。
ot=σ(Wo[ht-1,xt]+bo)
(9)
ht=ot×tanh(Ct)
(10)
式(5)-式(10)中:x表示输入向量;t表示时刻;h表示隐藏层节点向量;f表示遗忘门的输出;σ为sigmod函数;W为参数矩阵;b为偏置值;C表示状态。LSTM的结构如图2所示。
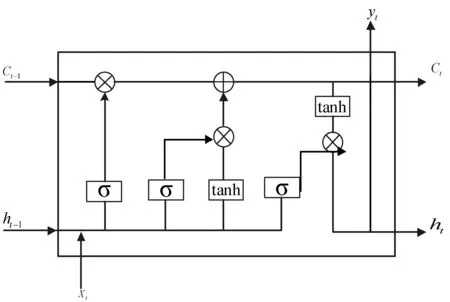
图2 LSTM结构图
2.2 基于Transformer的蒙汉神经机器翻译模型
Transformer[12]是端到端的Seq2Seq[13]结构,它已基本取得了目前神经网络机器翻译最好的效果,完全使用注意力机制。
注意力机制的本质来自源于人类的视觉注意力机制。注意力机制函数可以被描述为一个查询(Query)到一系列键-值对的映射[14]。注意力机制原理如图3所示。
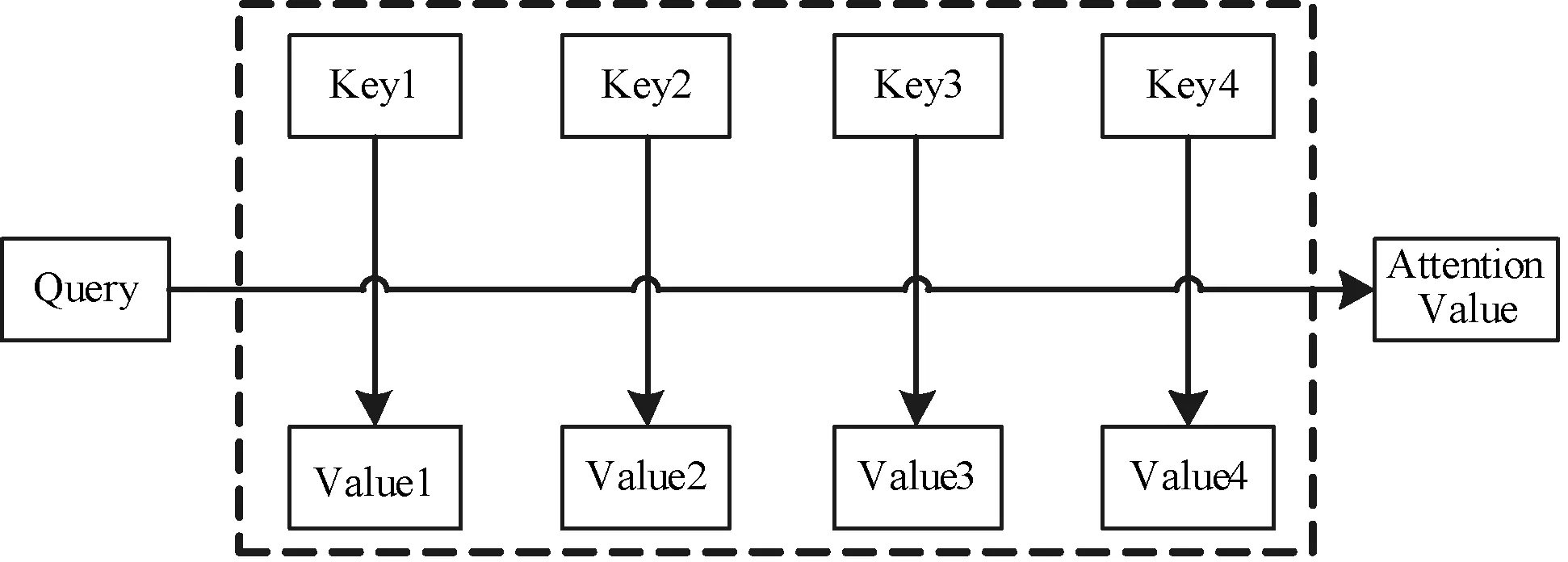
图3 注意力机制原理图
Attention(Query,Source)=
(11)
注意力函数计算分为三步:
(1) 将Query和每个Key进行相似度计算得到权重;
(2) 使用Softmax函数对这些权重进行归一化处理;
(3) 将权重和相应的键值进行加权求和得到最后的Attention。
Transformer包含Encoder和Decoder,如图4所示。在蒙汉神经机器翻译中,Encoder负责理解蒙文,Decoder负责产出中文。编码器的输出作为解码器的输入。Transformer翻译模型中,编码器和解码器都有多层。首先在编码器到解码器的地方使用了多头自注意力[15]进行连接,其实就和主流的机器翻译模型中的注意力一样,利用编码器和解码器注意力来进行翻译对齐。然后在编码器和解码器中都使用了多头自注意力来学习文本的表示。

图4 Transformer结构简图
编码器结构图如图5所示,在Transformer翻译模型中,编码器有6层,每一层包含2个子层。
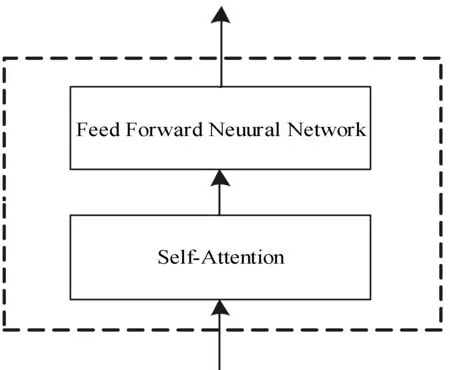
图5 编码器
解码器结构图如图6所示,在Transformer翻译模型中,解码器也有6层,它和编码器的不同之处在于解码器多了一个Encoder-Decoder Attention,编码器Attention用于计算输入权值,解码器 Attention用于计算输出权值。

图6 解码器
自注意力表示当前翻译和已经翻译的前文之间的关系。在自注意力中,Key=Value=Query,Key、Value、Query分别是编码器层的输出(Key=Value)和解码器中多头注意力的输入。例如在蒙汉翻译中,输入一句蒙语,那么里面的每个词都要和该句子中的所有词进行注意力计算。目的是学习句子内部的词依赖关系,捕获句子的内部结构。
多头注意力其实就是多个自注意力结构的组合,每个头学习到的注意力的侧重点不同。多头注意力的优势在于进行了h次计算而不仅仅计算一次,这样的好处是可以允许模型在不同的表示子空间里学习到相关的信息。
3 实 验
实验分别选用了哈佛大学开源的机器翻译库OpenNMT和谷歌开源的机器翻译库Tensor2Tensor训练标准神经网络模型,可以更加全面和客观地验证实验的有效性和可靠性。OpenNMT是基于LSTM和注意力机制的机器翻译模型。Tensor2Tensor是完全使用注意力机制来建模,即基于Transformer的翻译模型。
在蒙汉翻译系统中,为了在源端和目标端选出合适的输入序列粒度,本文基于LSTM和Transformer翻译模型,分别在源和目标端上从词-词、词-子词、子词-词、子词-子词这四个切分方向进行实验。图7为系统结构图。
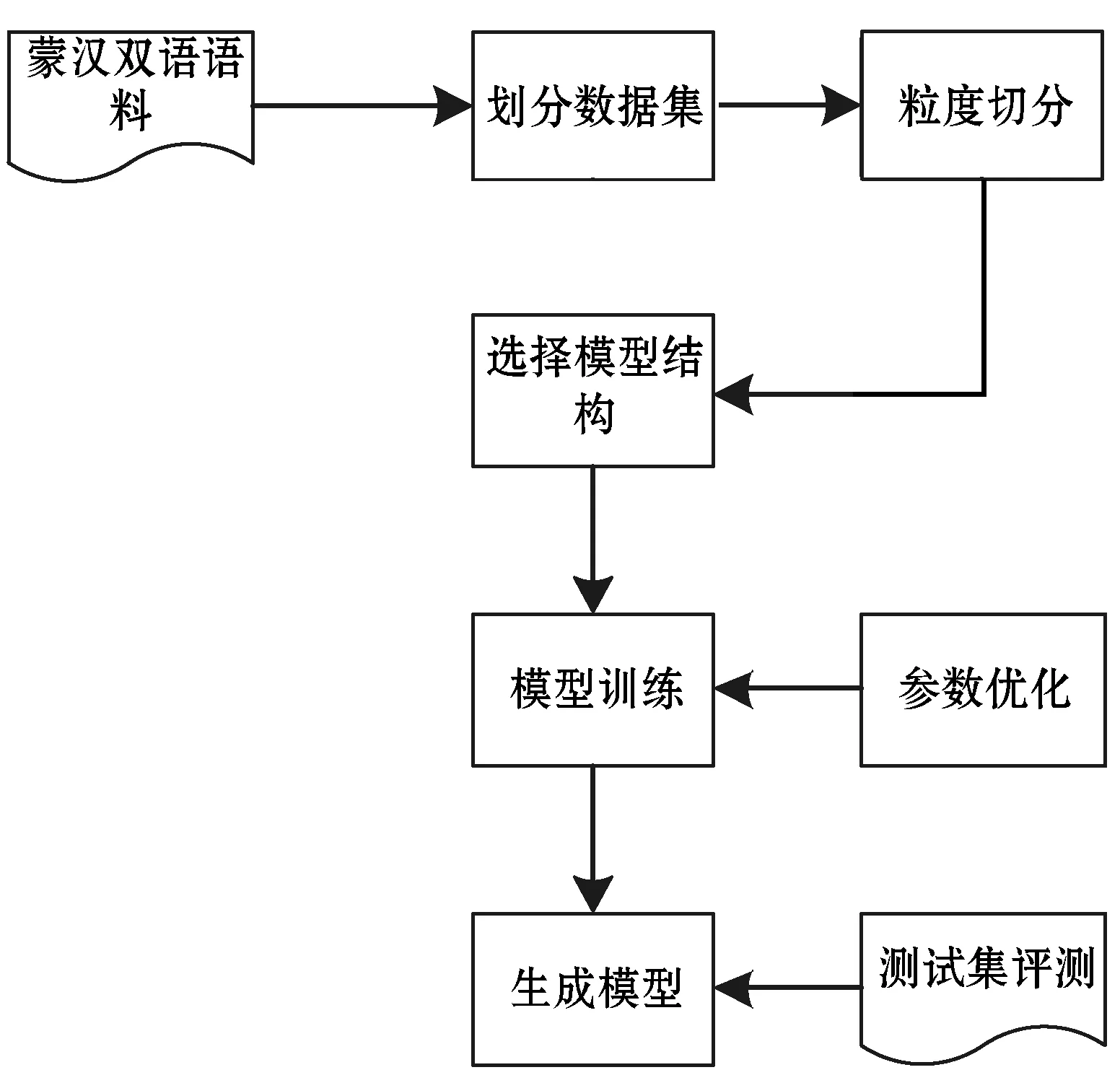
图7 系统结构图
3.1 实验设置
本文使用了CWMT去重校正过的116 002句对蒙汉平行语料为训练集,1 500句对蒙汉平行语料作为验证集,1 000句对蒙汉平行语料作为测试集。为了保证训练集和测试集的数据在同一个分布中,我们先将语料库打乱混合在一起,然后再将数据集划分为训练集、验证集和测试集。
实验环境为Ubuntu16.04 Linux系统,Python 2.7.0,TensorFlow 1.6.0,PyTorch 0.4.3。使用GPU进行训练,提高运行速度。
基于LSTM的翻译模型参数设置:编码器和解码器中 LSTM 神经网络的网络层数设置为 2 层,编码器/解码器上设置500个隐藏单元,选择tanh()为激活函数,Adam[16]为优化算法,Dropout 设置为 0.3,迭代步数train_steps=100 000,学习率初始值learning_rate= 0.1,学习率衰减速率设置为 1,batch_size设置为64句。选择 BLEU 值作为翻译译文质量的评测指标。
基于Transformer的翻译模型参数设置:Transformer的神经网络层数Nx=6,多头注意力为8,隐藏层大小设置为512,过滤器大小设置为2 048。选择Adam优化算法。学习率初始值learning_rate= 0.6,采用学习率衰减策略[12]。解码过程采用集束搜索策略,beam width=4。迭代步数train_steps=100 000,batch_size设置为4 096词,选择BLEU值作为翻译译文质量的评测指标。
3.2 实验结果
表1统计了四组不同切分粒度下,在相同的训练语料中词典规模的大小。可以看出,经过BPE处理后,词典大小明显减少。子词切分粒度缩小了词典大小,进而减少了计算量。
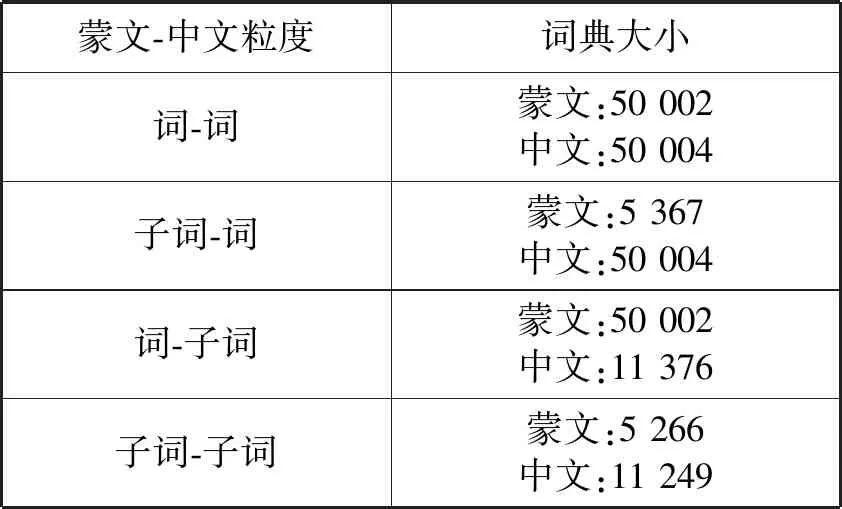
表1 不同粒度的词典大小统计结果
从表2和表3可以看出,无论是基于LSTM翻译模型还是基于Transformer翻译模型,单独对蒙文或者中文进行子词粒度的切分,对翻译效果提升影响不大,但是同时对蒙文和中文进行子词粒度的处理,能显著提高翻译效果。在LSTM蒙汉神经机器翻译系统中,对中文和蒙文同时进行子词粒度处理比词级粒度翻译系统提高2.59个BLEU值。在Transformer蒙汉神经机器翻译模型中,对中文和蒙文同时进行子词粒度处理比词级粒度翻译模型提高了4.12个BLEU值。实验结果同时也表明,Transformer翻译模型性能更优于LSTM翻译模型,BLUE值大约高3~5。
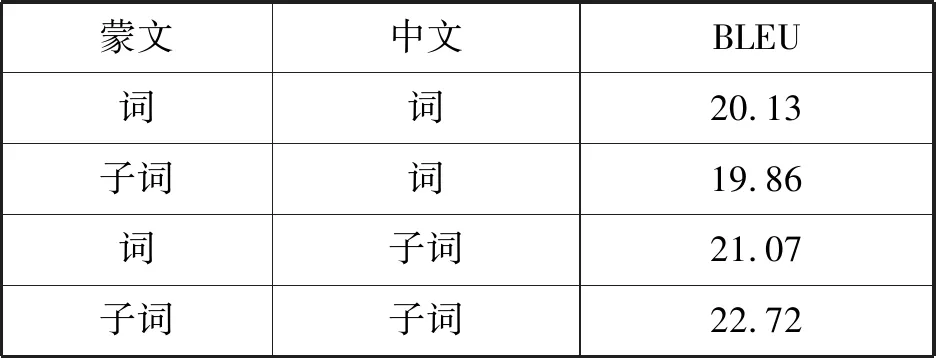
表2 不同粒度在LSTM翻译模型的表现
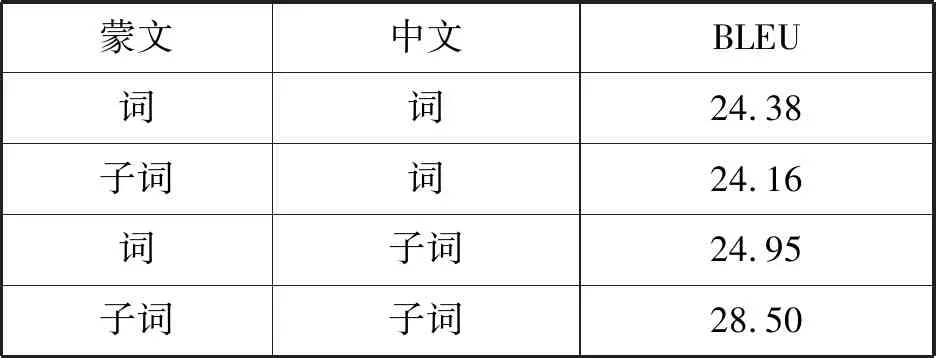
表3 不同粒度在Transformer翻译模型的表现
4 结 语
对语料进行粒度切分,能够减少低频词的数量,缓解数据稀疏,且对于平行语料稀缺的蒙汉神经机器而言尤其重要。本文实验结果表明,对语料进行一定粒度切分可以提升机器翻译系统的翻译质量。
下一步拟将蒙古文字符引入蒙汉神经机器翻译中。蒙古文词都是由基本的蒙古文字符组成,并且其组成具有一定的词法规律[17],将蒙古文切分为蒙古文字符进行机器翻译粒度的输入,机器翻译模型就可以学习到这种词法信息,大部分词法信息与句法信息有所关联,因此有助于提高翻译系统的翻译效果。
