3DMM与GAN结合的实时人脸表情迁移方法
2020-04-18黄法秀刘春平
高 翔 黄法秀 刘春平 陈 虎*
1(四川大学计算机(软件)学院 四川 成都 610065)2(四川川大智胜软件股份有限公司 四川 成都 610045)3(四川大学视觉合成图形图像技术国防重点学科实验室 四川 成都 610064)
0 引 言
具有真实感的人脸表情生成方法目前已经被广泛应用到各个行业,在电影动画、虚拟人物、商业服务、医学美容等方面都有了具体的应用场景。特别是在动画电影方面,逼真的人脸和人体动画、表情丰富的虚拟人物,能有效增强人物与场景的真实感和观看人的沉浸感。此外,二维人脸识别受图像中的光照条件、人脸姿态和表情等可变因素影响巨大,动态环境下局限性较大,且防伪性能不好[2]。三维人脸识别方案能够解决现有的这些问题,例如Apple公司利用三维结构光建模的人脸识别技术。从早期的利用手工构建三维人脸参数模型,到现在主流的利用二维图像生成三维人脸模型技术,利用三维人脸建模技术,生成动态逼真的人脸表情具有较高的实用价值。如何快速、健壮地生成自然逼真的人脸表情更加是急需解决的热点问题。
本文提出了一种基于二维单目摄像头的实时真实感人脸表情迁移方法,可以在具有二维单目摄像头的计算机设备上,实现人脸的自动捕捉、目标人脸估算、三维人脸的重建和自动渲染,并达到实时效果。图1为迁移算法的流程。
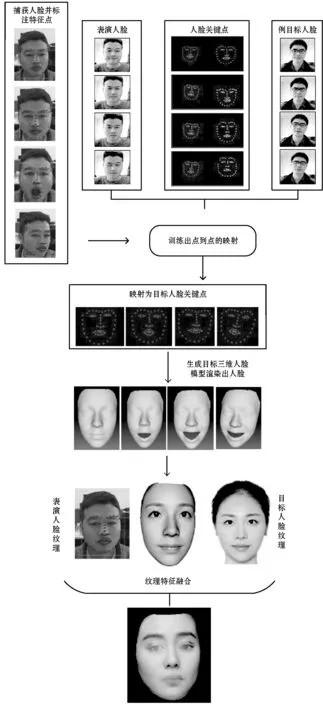
图1 人脸表情迁移算法流程
1 相关工作
人脸重建与表情迁移技术,在计算机图形学和计算机视觉领域有着悠久的历史,本文主要关注基于外部设备的实时表情迁移方法。参考Rousselle等[3]针对人脸表情捕获进展和Zollhöfer等[4]关于单眼三维人脸重建、跟踪和应用的最新报告,对使用受控采集设备具有高质量结果进行了概述。由于面部表情的复杂多样性,使得高真实感的人脸表情的合成具有较大难度,1987年Waters等[5]根据人脸表情的组成根本,提出肌肉驱动模型来模拟表情生成过程,在这基础上和Lee等[6]合作提出生理模型,可以生成更为真实自然的面部表情。Koch等[7]则利用有限元的方法来模拟人脸的生理结构,提出的表情生成模型可以准确地模拟表情产生过程中脸部机构的受力情况。Williams等[8]采用行为驱动的方法从采集的视频画面中获取人脸的纹理、形状等信息,然后利用可变形的网格驱动人脸。Liu等[9]提出从视频序列中恢复人脸纹理的方法,解决表情合成方法不能恢复人脸形变的缺点。Isola等[10]利用对抗生成网络根据图像特征从像素级直接生成对象的部分真实纹理,具有借鉴意义,也成为最近表情迁移的热门技术。
近年来国内的研究人员也着手于人脸表情合成技术的研究,并取得了许多有效的成果。晏洁等[11]在模拟表情、纹理映射等领域有较为深入的研究,早期提出了基于人脸模型变形方法,在三维虚拟特定人脸生成方面做出探索。梅丽等[12]采用参数化驱动方式驱动三维人脸模型,忽略了人脸表情皱纹等纹理信息。姜大龙等[13]对人脸表情合成领域的相关技术问题展开相应研究,通过使用局部表情比率图(partial expression ratio image,PERI)与MPEG-4中人脸动画参数相结合的方法实现人脸动画中细微表情特征的参数化表示,并提出了具有参考意义的优化措施。周坤等[14]通过使用变形导向的GAN,生成从二维人脸图像直接驱动的目标人脸表情,得到了较为优秀的结果。搜狗实验室最近也发布了全球第一个虚拟主持人,相信在接下来的时间国内外在人脸表情合成、迁移等领域会有更加优秀的进展。
结合前人的工作经验[15]可知,目前真实感人脸表情的研究还存在问题,例如:大多数技术只能应用到虚拟动画,并不能应用到真实人脸,表情动态过度僵硬,不具有个性化;人物动作僵硬,对输入的视频有较大的依赖性,无法自动生成目标人脸个性表情;无法应对头部的动作变化,只能应对人脸表情的修改。因此,本文提出一种基于3DMM与GAN结合的实时人脸表情迁移方法来解决上述问题。
2 方法设计
本文方法是多个组件的协作。图1描述了该方法的基本流程,将表演者与目标人脸作出区分,目标人物必须按照表演者的表演动作做出一系列的模仿。参与人员通过人脸跟踪检测,获取其人脸关键点,本文使用的是人脸的hog特征和级联分类器作为分类方法。为了将表演者与目标人脸做出映射,使用pix2pix[16]的对抗生成网络,通过表演者的表情自动生成目标人脸的表情关键点。使用Ruiz等[17]深度学习的方法,对二维人脸坐标点进行三维姿态的估计,渲染出不同姿态的可视化二维人脸。利用3DMM[18]三维人脸重建方法,用生成的目标人脸二维坐标点结合目标人脸纹理,实时拟合出三维人脸模型。使用泊松图像融合[19]的方法将当前表演者的人脸与目标人脸融合,生成最终的表情迁移人脸。在此过程中为了达到实时渲染的要求,同时利用多线程编程对整个人脸坐标采集、三维人脸生成、实时渲染、面部表情融合等过程进行了加速。
本文方法最关键的一部分就是目标人脸关键点的生成,在这个过程中,通过使用二维单目摄像头采集表演人脸和目标人脸的一系列不同表情视频,然后利用pix2pix对抗生成网络成对训练表演人脸和目标人脸的映射关系,最终达到了生成目标人脸关键点的需求。另外使用纹理融合算法对表演人脸和目标人脸的部分纹理进行部分融合。
2.1 数据采集
在构建目标用户的面部模型之前,首先需要捕捉一组预先定义的图像序列,这些图像由用户一组不同的表情面部图像组成,借鉴Cao等[20]的方法将人体头部运动分为刚性运动和非刚性运动两个部分。如图2所示,第一部分为刚性运动,要求捕获人脸15个不同的姿态,这些姿态由头部的不同的角度组成并且人脸带有中性表情。这些转动使用欧拉角(yaw,pitch,roll)来表示,其中:yaw从-90°到90°,每隔30°为旋转尺度共6个姿态;pitch从-30°到30°每隔15°为旋转尺度共4个姿态;roll和pitch的旋转尺度保持同样的分布,为4个姿态。图2第一行为其中部分姿态:从左至右为0°、yaw30°、pitch30°、roll60°、yaw-60°、yaw-90°。用户只需要近似匹配上述标准,无需精准测量上述尺度。第二部分是旋转尺度保持在-30°到30°之间的15个不同人脸表情的非刚性人脸集合。包括:微笑,皱眉,厌恶,挤左眼,挤右眼,愤怒,张嘴,咧嘴,抬下巴,撅嘴巴,漏斗形嘴,鼓脸,闭眼睛,左撇嘴,右撇嘴。图2第2行所示分别为:微笑,张嘴,厌恶,咧嘴,闭眼,皱眉。

图2 人脸刚性运动和非刚性运动采集示意图
最终,为表演人脸和目标人脸分别捕获并挑选了825幅图片,每个不同的姿态和不同的表情分别25幅。使用的设备为普通的二维单目摄像头,采集目标距离设备1米。为了达到较高的对齐效果以完成下面的任务,要求测试人员尽量保持亮度一致,以达到较高的对齐效果。
2.2 人脸关键点定位
基于二维图像的三维人脸建模需要从图像中提取出相关的人脸特征信息,其中包含人脸位置、人脸的关键点以及人脸的颜色信息提取,提取上述信息需要对人脸进行检测、人脸对齐等操作。针对前面所获取的人脸数据集,采用人脸对齐的方法为它们自动标定68个关键点,分别位于人脸的眉毛、眼睛、鼻子、嘴唇和脸部边缘位置,其中0~16位于人脸边缘,17~21为左眉毛,22~26为右眉毛,27~35为鼻子,36~41,42~47分别为左右眼睛,48~67为嘴巴,标注如图3所示。现在二维人脸对齐技术[21-22]已经很成熟,可以任意完成上述对齐,这里使用的为开源人脸对齐基于ERT(Ensemble of Regression Tress)算法[21]。ERT展示了如何使用回归树集合直接从像素强度稀疏子集估计面部的关键点位置,通过高质量的预测展示了实时性能。

图3 人脸关键点标注示意图
使用上述方法对数据集中825对图像进行人脸关键点的对齐,并且将关键点画至黑色背景图形,归一化人脸大小后形成对抗生成网络的数据集。
2.3 对抗生成网络生成目标关键点
2.3.1准备训练数据集
根据表演和目标人脸数据集的人脸关键点的标定结果,形成成对包含825组的人脸关键点数据集,数据点描绘在黑色背景上,如图4所示,A为目标人脸画出的对应人脸的关键点示意图,B为表演人脸数据,均归一化为512×256大小的成对人脸关键点数据集作为网络训练数据。将数据集的75%作为训练集,25%作为测试集,使用pix2pix的对抗生成网络[10],自动生成目标人脸的68个关键点。
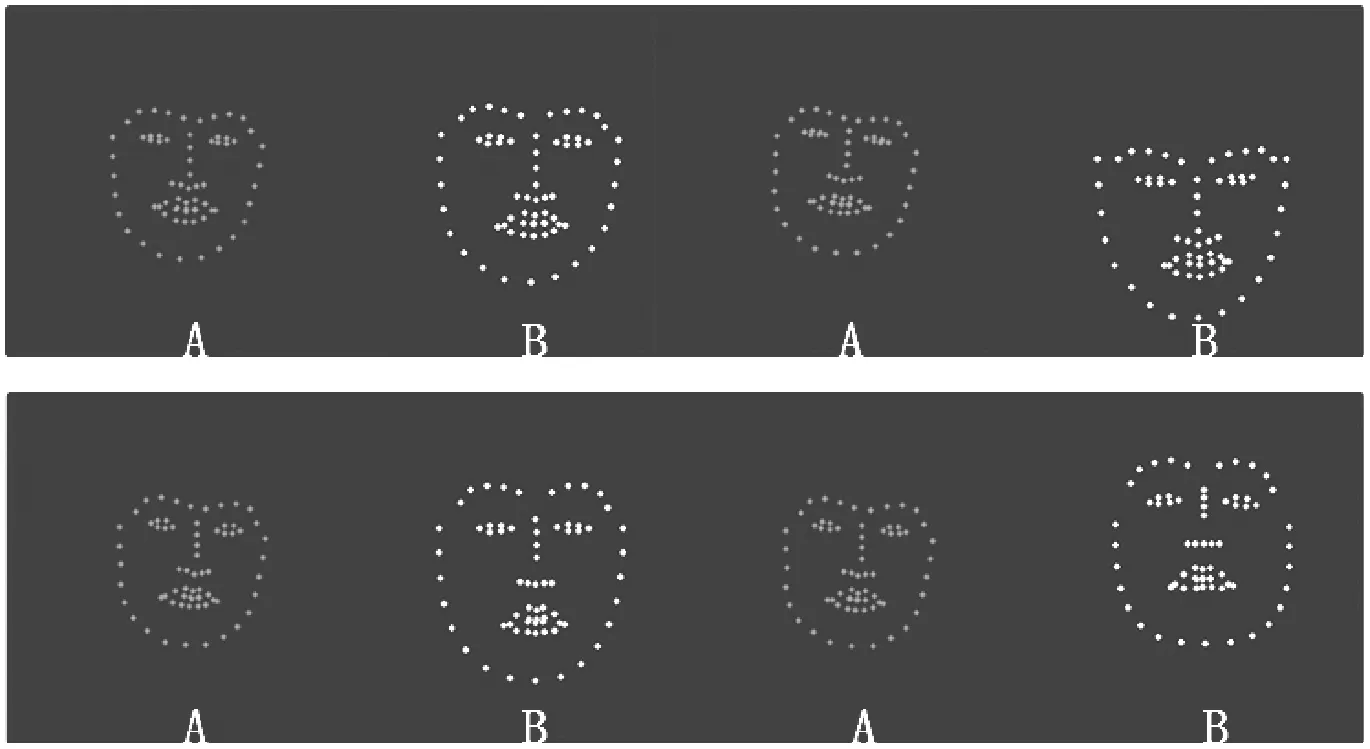
图4 目标人脸和表演人脸对应人脸关键点图片
2.3.2目标函数
GAN[23]是一种生成模型,用来学习一组z(随机噪声)向量到y(目标图片)的映射:y:G:z→y。相比之下,条件GAN学习观测图像x和随机噪声z到y的映射关系,y:G:{x,z}→y。
在此pix2pix的训练模型为GAN网络的变形,损失函数为:
LCGAN(G,D)=Ex,y[logD(x,y)]+Ex,z[log(1-
D(x,G(x,z)))]
(1)
式中:G目的是最小化该函数值,D目的为最大化该函数值,即G*=arg minGmaxDLCGAN(G,D)。
为了对比效果,同时训练一个普通GAN,只让D(判别网络)判断是否为真实图像。
LGAN(G,D)=Ey[logD(y)]+Ex,z[log(1-
D(G(x,z)))]
(2)
对于图像生成任务而讲,G(生成网络)的输入和输出之间共享信息,比如上色任务。因而为了保证输入和输出图像之间的相似度,加入L1 loss:
(3)
汇总的损失函数为:
G*=arg minGmaxDLCGAN(G,D)+λLL1(G)
(4)
(1) 生成网络G。常见的编解码网络(Encoder-decoder)输入和输出之间会共享很多信息,如果使用普通的卷积神经网络会导致每一层都承载保存者所有信息,这样的神经网络容易出错,所以使用U-Net[24]网络来进行减负,结构如图5(b)所示。U-Net的区别是加入跳线链接,对应的feature maps和decode之后的同样大小的feature maps按通道拼(concatenate)一起,用来保留不同分辨率下像素级的细节信息。
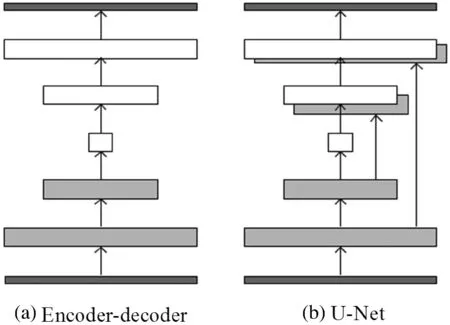
图5 Encoder-decoder和U-Net网络结构对比
(2) 判别网络D。用来保证局部图形的精准性,通过Patch-D[10]实现,将生成图像切分为固定大小的Patch输入进入判别网络进行判断。
将归一化后的训练数据送进网络中,在训练过程中,G(生成网络)、D(判别网络)交替进行训练,可有效地生成目标人脸的人脸关键点位置,如图6所示。将关键点的位置提取出来,作为生成三维人脸模型的输入。从图6中可以看出,生成的目标人脸的关键点位置,比表演人脸脸型更为纤细(目标人脸为图1流程图对应人脸),带有目标人脸的特征表现,可以作为驱动目标人脸三维模型生成的输入数据。

图6 使用GAN生成目标人脸的关键点位置
2.4 3DMM生成三维人脸模型
为了通过二维人脸关键点得到和目标人脸相似的三维人脸模型,本文使用了基于3DMM的人脸三维模型拟合框架。萨利人脸模型是3D形变模型包含了PCA形状模型和PCA颜色模型,而且每个模型拥有不同分辨率级别以及对应的元数据,例如二维的纹理信息和对应的人脸坐标信息。
3DMM主要是在获得萨利扫描模型的基础上,利用单幅人脸图片的二维坐标点,通过IMDR算法[25]多次逼近求得二维坐标到多分辨率三维人脸模型的稠密对应关系,达到二维到三维重建的效果。该方法使得人脸的三维重建模型实时性显著提高。
首先通过对数据库中的扫描三维人脸点云模型进行PCA主成分的提取。这里将形状模型表示为点坐标(x,y,z)的向量集合S∈R3N和颜色模型表示为(RGB)颜色信息的向量集合T∈R3N,N表示模型中点的数量。每个PCA模型表示为:
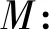
(5)
式中:v∈R3N为样本的均值;V为样本的主成分的集合V=[v1,v2,…,vn-1]∈R3N×(n-1);σ∈Rn-1为样本集合的标准差;n为用来构建模型的扫描次数。
通过计算得出新的面部模型:
(6)
式中:m≤n-1是主成分的数量;a∈RM是PCA形状空间中的实际坐标,为式(5)计算得出标准差集合。PCA颜色模型也服从于上述坐标向量的分布,可通过类似计算方式得出。
通过上述的方法得到了一个三维人脸的平均模型,在三维人脸模型拟合的过程中,首先对二维人脸图片进行人脸关键点的检测,然后通过采用仿射摄像机模型,实现了黄金标准算法[26],找到给定的一定数量的二维-三维点对的摄像机矩阵的最小二乘近似。
得到人脸关键点的二维坐标后,通过使用二维到三维坐标的形状稠密对应算法[25],找到和二维坐标最为接近的PCA坐标向量,代价函数为:
(7)
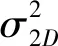

图7 人脸可变模型框架生成三维人脸模型
2.5 面部表情融合
根据目标人脸的关键点坐标生成对应的三维人脸模型,根据二维人脸关键点位置估计出三维空间内的摄像机矩阵,调整三维目标人脸的视角,渲染出对应姿态的目标人脸。通过萨利模型拟合出的三维人脸不包含口腔模型,因此渲染出的人脸无法构建目标人脸说话过程,不存在舌头以及牙齿的变化,针对眼睛的动态也无法根据单张二维人脸进行合成。由于系统是根据检测表演人脸动作姿态和表情去生成目标人脸,目标人脸和表演人脸在动作过程中,头部姿态和脸部表情基本处于同步状态。本文使用人脸关键点定位算法定位到表演人脸和生成人脸图像的嘴巴和眼睛位置,将当前表演人脸的眼睛和嘴巴纹理图像,根据目标人脸的特点进行变形,使用泊松纹理融合[19]方法复制到目标人脸对应的眼睛和嘴巴的位置,填充眼睛和嘴巴的动态纹理,弥补光照和颜色的差异。
首先通过对目标人脸进行脸部关键点的对齐,找到对应的眼睛和嘴巴的位置,在人脸关键点分布在如图8中对应的眼睛鼻子所对应的位置,创建一个黑色蒙版用于找到需要融合位置的区域。然后对表演人脸图片蒙版图片和目标人脸图片进行归一化,将待融合位置进行对应,通过泊松融合得到最终的目标人脸。图9为纹理融合过程。
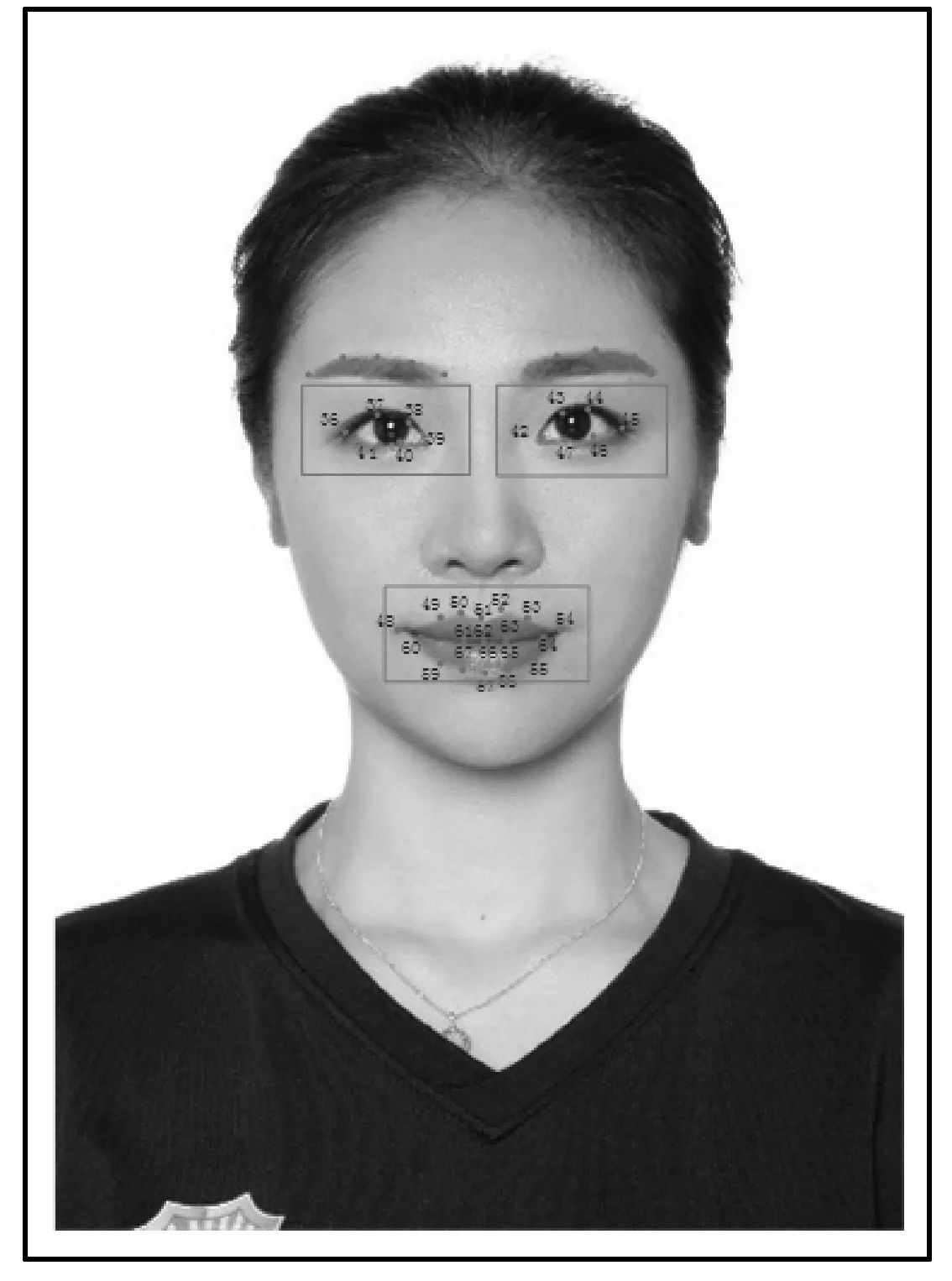
图8 纹理融合位置
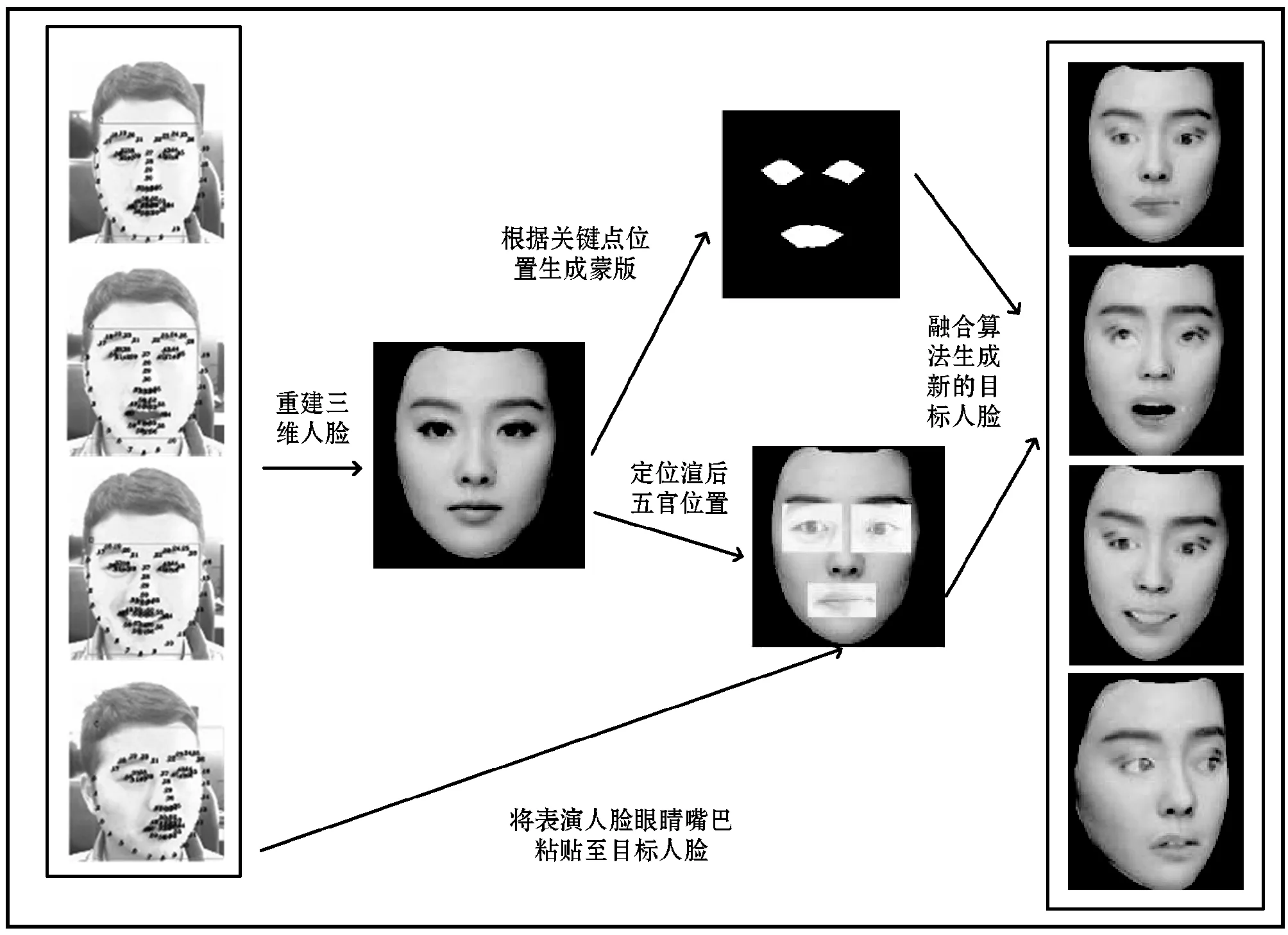
图9 渲染后的人脸图像和表演人脸的融合过程
3 实验结果与分析
本文实现了基于3DMM的三维人脸表情迁移:输入目标人脸和表演人脸的特定视频,对视频进行分帧提取脸部关键点信息,利用生成对抗网络进行表演人脸和目标人脸关键点进行映射,自动生成目标人脸的脸部关键点;利用生成的人脸关键点进行三维人脸的拟合,生成目标人脸三维模型同时做纹理映射,在此基础上融合表演人脸的五官特点,最终生成人脸迁移结果,如图10所示。可以看出,本文结果对比单纯的三维人脸建模的结果更具有真实性,可以较为真实地迁移表演人脸表情至目标人脸,能够展示眼睛,嘴巴的动态效果。如图11所示,生成人脸能较为生动地模仿目标人脸的表情动态和部分神情,对嘴部和眼睛的表情融合有较好的效果,从感官上能够达到分辨出不同表情的区别。

图10 生成各种姿态表情表演人脸对比

图11 目标人脸和生成人脸表情对比
人脸表情仿真和迁移领域并无统一的质量评价测试方法,无法模式化量化最后的结果,故参考文献[28],设计了一套比对方法。通过对The Extended Cohn-Kanade Dataset(CK+)数据库[29]中不同人脸表情和生成的对应人脸表情两组实验数据进行挑选,并结合本实验的实现条件,使用Tuputech[30]网站提供的在线人脸表情打分功能分别对两组数据进行打分比对,验证本文方法的迁移效果。
本文设计了对比验证实验共涉及10个不同人脸对象的图片,共80幅人脸图片包含来自于(CK+)数据库女性8种不同人脸表情:中性、愤怒、蔑视、厌恶、恐惧、高兴、悲伤、惊讶。通过Tuputech网站系统[30]对(CK+)数据库中不同表情人脸进行预测试,发现并不能准确对部分表情打分,部分打分效果如图12所示。从中选择打分在70分以上的图12(b)、(f)以及一幅中性表情图片作为对比标准,来统计两组数据的分数分布。对10个不同对象人脸的自然表情和生成表情,包括喜悦、惊讶、中性进行打分比对。部分结果如图13所示。
图12 数据集中7种不同表情打分情况
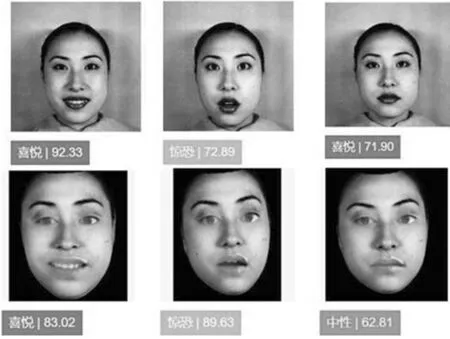
图13 部分自然人脸表情和生成人脸表情对比打分情况
通过对比实验,最终得到10个人脸对象,自然人脸表情和生成人脸表情的三种不同表情的打分分布如表1所示。
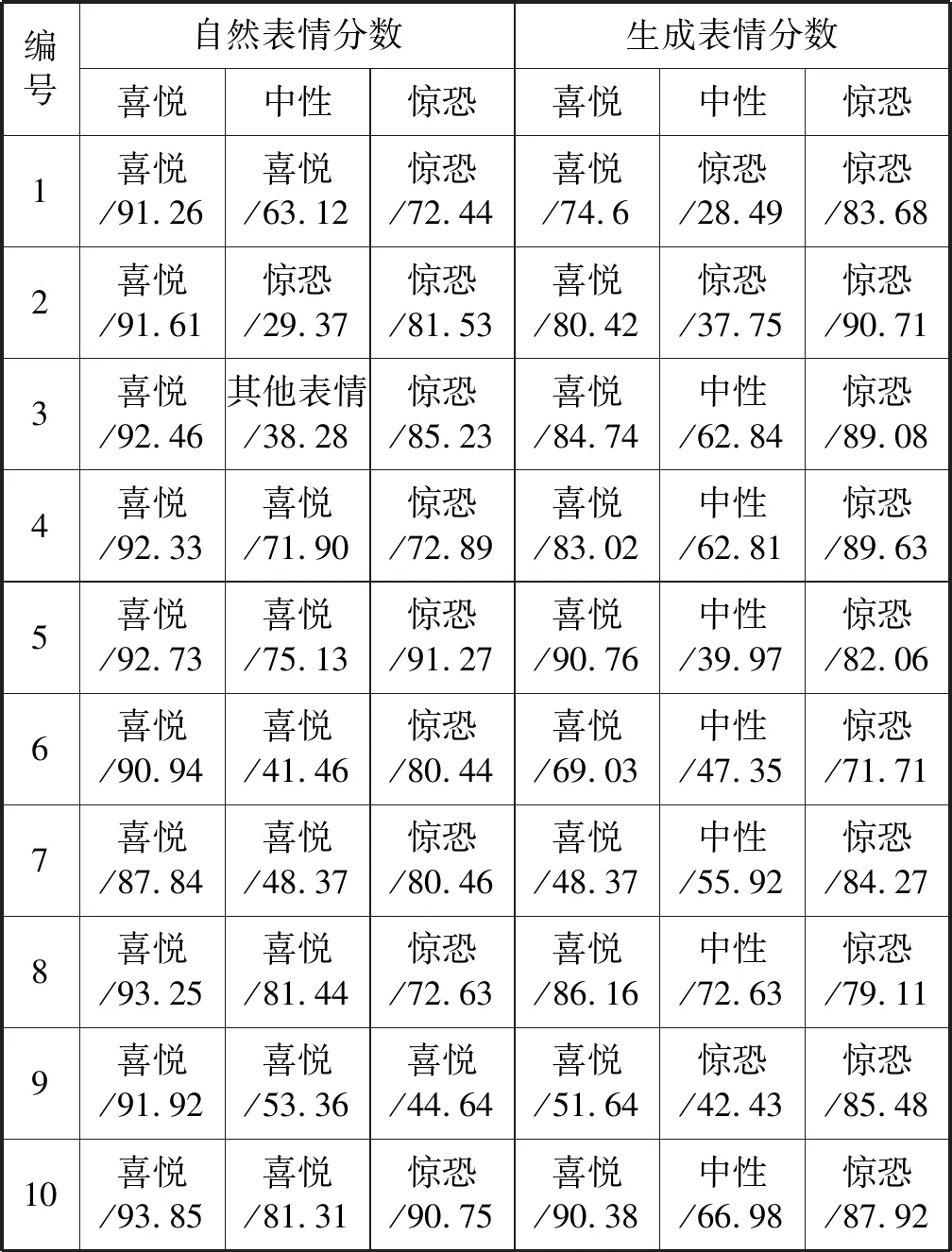
表1 Tuputech系统对自然表情和生成表情打分情况
通过对结果样本进行表情识别,系统可以识别喜悦和惊恐表情种类并进行打分,并有效模仿出每个对象的表情,但由于无法准确识别出中性表情,故本文选择喜悦和惊恐表情作为对比参数。通过本文方法迁移生成表情能够达到模仿人脸自然表情的效果,基本接近自然表情的打分结果。但光照问题会造成脸部有明显合成痕迹以及五官的模糊情况,脸部细节处理不到位,说明本文算法需要在光照一致性上进一步改进。
在一台CPU为Core(TM)i7-8700,主频3.70 GHz,内存16 GB的电脑中,系统通过CPU多线程完成人脸采集、三维模型拟合、人脸表情融合和渲染过程生成连续的人脸表情画面,最快可以达到15.2帧/s,达到实时视频的标准,使用GPU对渲染部分进行加速可以得到更好的效果。
4 结 语
本文通过对同一个人的部分视频进行训练,并设计以逼真演化目标的算法,将表演人脸表情迁移到目标人脸表情。本文方法可以实现实时人脸表情迁移,对于需要用到虚拟人物化身,人脸识别数据的拓展有一定作用。尝试使用GAN和三维建模技术结合,生成更为逼真的三维人脸表情,但在进行最终的人脸表情融合过程中,细节处理不够完美。由于需要进行人脸纹理信息的采集,表演人员需要在特定环境下(光照稳定充足)进行演示,无法应对复杂环境光的问题,而且纹理受采集设备的影响会出现部分模糊。系统正常使用前,需要对表演和目标人脸进行一段时间的视频采集,这也需要进一步改进。整个程序使用多线程编程,存在计算机资源抢占过程,容易产生渲染画面的跳帧卡顿。下一步,会针对以上已知问题进行进一步的研究,如pix2pixHD自动生成目标人脸纹理,使用声纹驱动目标人脸,优化人脸容融合算法,使用更高精度的人脸采集设备,提升纹理融合的精度等。
