基于深度学习的蛋白质亚细胞定位算法概述
2020-04-17谭博

摘 要 蛋白质亚细胞定位是分子细胞生物学和蛋白质组学的一个重要课题,有助于了解蛋白质的性能和功能。荧光显微镜法是亚细胞定位最常用的方法和手段,常见方法有专家观测荧光图像标注蛋白质、利用形态学特征提取自动识别以及神经网络提取特征等,但多标记荧光蛋白质细胞图像的多标签分类任务其准确度还远低于人工观测。
关键词 蛋白质亚细胞定位;神经网络;多标签分类
Abstract subcellular localization of proteins is an important subject in molecular cell biology and proteomics, which is helpful to understand the properties and functions of proteins. Fluorescence microscopy is the most commonly used method and means of subcellular localization. Common methods include expert observation of fluorescent image to label protein, automatic recognition by morphological feature extraction and feature extraction by neural network, etc. However, the accuracy of multi label classification task of multi label fluorescent protein cell image is far lower than that of manual observation.
Key words Protein subcellular localization; Neural network; Multi label classification
引言
随着技术的发展,高通量荧光显微镜已经可以自动快速的产生大量亚细胞定位图像,位于不同亚细胞位置的蛋白质会在显微图像中呈现不同的分布形态,也可观测到某种蛋白质同时存在于多个亚细胞的情况,人工观测方法基于分布形态的特征标注蛋白质亚细胞位置。也有学者利用机器学习的方法自动识别多标记的显微图像,但由于某些细胞器太小,如线粒体蛋白质分布呈现为小颗粒,相比于大的细胞器则很容易被忽略,所以现存的多标记蛋白质亚细胞分类算法的精度还远比不上专家级的人工标注。卷积神经网络可以自动学习到分层次的特征表示,其特征具有平移、伸缩、扭曲等不变性,可以准确获取到细微的细胞器特征,提高多标记蛋白质研习班分类算法的精度。
1 数据集
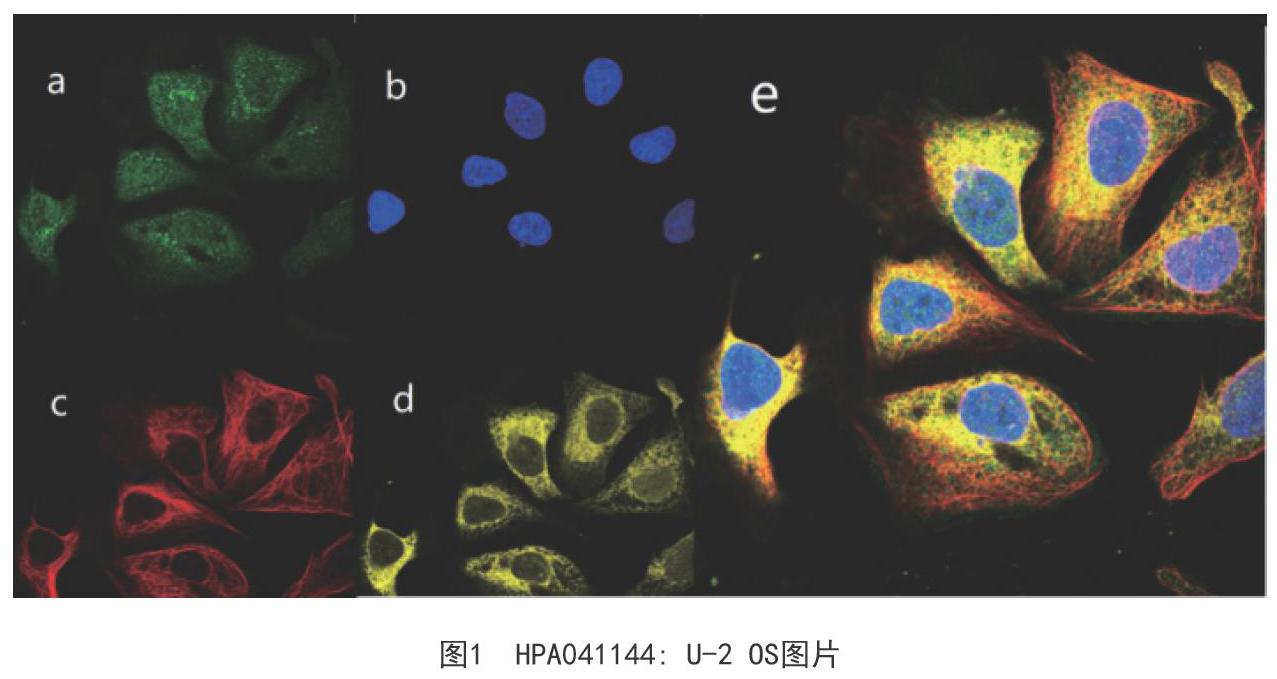
人类蛋白质图谱(The Human Protein Atlas,简称HPA)是瑞典的一项旨在绘制细胞,组织和器官中所有人类蛋白质的倡议,其使用共聚焦显微镜绘制人类蛋白质组的亚细胞分布图,数据库的当前版本HPAv18包含了12390种蛋白质42774张图像数据(www.proteinatlas.org)。图1为编号HPA041144: U-2 OS图片,分辨率为512x512,分为四个通道,其中a绿色为荧光蛋白质,b蓝色为细胞核,c红色为细胞微管,d黄色为内质网,e为四通道合成的细胞显微图。
该数据集有两个主要的难点。第一,不同类别间学习的困难程度不同,如细胞质、细胞核等在细胞中较大的细胞器容易被学习到,属于简单的学习类别。而溶酶体、线粒体等较小的细胞器,在细胞图像中以十几甚至是几个像素呈现,这些微小细胞器属于困难的学习类别。当一个样本同时拥有简单和困难的类别时,简单类别占主导地位而困难类别则被忽略。第二,多标签分类且类别高度不平衡。定位类别一共分为28类亚细胞结构,分别为细胞核质、细胞质、细胞质膜、线粒体、高尔基体等,每张图像有1~6个标签,其中有12885张图像拥有最常见的标签“细胞核质”(nucleoplasm),而只有42张图像拥有最少见的标签“棒环结构”(rods and rings),28类间数据量高度不平衡。
2 方法
通常情况下,多标签图像分类问题在用神经网络进行学习时,首先通过卷积神经网络(Convolutional Neural Network,简称CNN)将图像信息压缩提取成一维特征向量,元素个数为类别总数,记为预测输出向量。然后使用Sigmoid函数对其激活:
由表1可知,在同样神经网络结构下,改进后的Floss比BCEloss效果提升约16%,比Loc-CAT模型提高约25%,有效的解决HPAv18数据集中困难类和少量样本的问题,进一步逼近专家级标注的精確度。
4 结束语
HPAv18数据集中的困难类别学习和样本不平衡问题是许多生物图像上的共同问题,如何利用图像技术自动识别分类节约人力物力是一个具有实用价值的研究方向。本文利用卷积神经网络加上改进Floss的方法,在多标签蛋白质亚细胞定位任务的HPAv18数据集上验证了对上述两个问题的效果,宏F1得分比之前方法提高明显,进一步逼近专家级标注的精确度。
参考文献
[1] Lin T Y,Goyal P,Girshick R,et al. Focal Loss for Dense Object Detection[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,(99):2999-3007.
[2] Sullivan D P,Winsnes C F,?kesson Lovisa,et al. Deep learning is combined with massive-scale citizen science to improve large-scale image classification[J]. Nature Biotechnology,2018,36(9):172.
[3] Ioffe S,Szegedy C . Batch normalization: accelerating deep network training by reducing internal covariate shift[C]. International Conference on International Conference on Machine Learning. JMLR.org,2015:16.
作者简介
谭博(1995-),男,广东湛江人;学历:研究生,现就职单位:广东工业大学,研究方向:图像处理。
