基于降维和聚类的协同过滤推荐算法
2020-04-15李玲娟
陈 希,李玲娟
(南京邮电大学 计算机学院,江苏 南京 210003)
0 引 言
随着信息技术与互联网的迅猛发展,人们进入了一个信息“爆炸”的时代,如何从海量信息中找到自己感兴趣的信息,如何让自己释放的信息脱颖而出受到关注都成为迫切需要解决的问题[1]。个性化的推荐系统成为继分类目录和搜索引擎后解决信息过载问题的代表性方案。推荐系统不需要用户提供明确需求,而是通过分析用户的历史行为记录主动推荐满足用户需求的信息。
在现有的推荐技术中,基于协同过滤的推荐算法使用最为广泛,主要分为基于用户和基于项目两种协同过滤,原理都是通过用户—项目评分矩阵计算相似度进行推荐[2]。可是随着用户与项目数量的不断增加,出现了评分矩阵稀疏、搜索最近邻耗时久等问题,导致传统的协同过滤算法推荐质量有所下降。为解决数据稀疏性问题,大部分研究人员采用填充法(0,均值,众数)来补全缺失值,但不能从根本上解决数据稀疏性问题;文献[3]提出使用奇异值分解(SVD)来解决数据稀疏性问题,但当数据量庞大时SVD效率会很低;文献[4-6]中都构建了基于用户聚类的协同推荐算法,通过对用户评价矩阵进行分析,采用K-means聚类算法把兴趣和偏好相似程度较高的用户分到同一个簇中,以减少搜索最近邻的时间,但会因为初始质心的选取不当导致推荐质量下降;有人尝试采用BP神经网络来预测评分[7],此方法虽然可以降低数据稀疏性所带来的影响,但需花费更长的近邻查找时间。
文中设计了一种基于主成分分析法(principal component analysis,PCA)和二分K-means聚类的新算法(命名为PK-CF算法),对输入的用户-项目高维稀疏矩阵使用PCA进行降维,提取主成分因子,并在降维后的数据上进行二分K-means聚类,寻找当前用户的所属类别,进而快速确定其最近邻,最后通过最近邻相似度加权计算出当前用户对未评测项目的预测值。
1 相关知识
1.1 基于用户的协同过滤推荐算法
如果部分用户对某些项目的感兴趣程度比较类似,则他们对其他项目的感兴趣程度也会比较相似,可以把他们归为同一个群体。基于用户的协同过滤推荐算法以此为前提,通过分析目标用户的最近邻居(最相似的若干用户)对某个项目的评分来预测目标用户对该项目的评分[8]。该算法主要包括两个步骤:
(1)查找与目标用户有相似兴趣的用户集合;
(2)将用户集合中用户最感兴趣且目标用户未使用的项目推荐给目标用户。
此类算法的核心是计算用户间的相似度,计算方法包括Jaccard、皮尔逊相关系数、欧几里德距离和余弦距离。其中的皮尔逊相关系数方法在数据不规范时能给出更好的计算结果,具体公式如下:
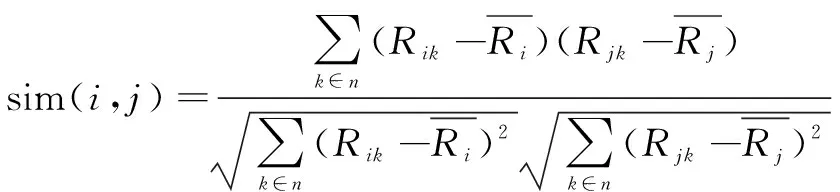
(1)
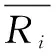
文中将通过求皮尔逊相关系数来计算用户间的相似性。
1.2 PCA降维技术
降维是应用最为广泛的数据预处理方法之一,这种方法通过去除高维数据中的噪声和无关紧要的特征,提升数据处理的速度进而节省大量的时间和成本。虽然降维造成了一定的信息损失,但在实际的应用中,通常只需要保留数据最重要的特征,一定范围内的信息损失是可允许的[9]。降维的方法有线性和非线性之分,线性降维将n维的高维数据通过某种线性投影的方法映射到一个p维的低维空间,即用线性无关的p个新特征取代n个旧特征并保留数据的主成分(包含信息量最大的维度),从而实现在保留原数据较多特性的情况下将n维数据降到p维的目的。
PCA(主成分分析)是最常用的线性降维方法之一,经过PCA降维后的数据将转换到一个新的坐标系中。新坐标系的坐标轴方向为数据方差最大的方向,方差反映的是数据与其均值之间的偏离程度,通常认为方差越大数据的信息量就越大。计算原数据中方差最大的方向,把它作为第一个坐标轴,第二个新坐标轴选择的是与第一个新坐标轴正交且方差次大的方向,重复该过程,重复次数为原始数据的特征维数[10]。在最后获得的新坐标系中,最先确定的坐标轴包含了数据最具特征的维度,余下坐标轴所包含的信息量几乎为0,可忽略不计。因此,只保留前面几个坐标轴,也就实现了对数据特征的降维处理。PCA算法的主要步骤如下:
输入:数据集X为m个n维的样本x1,x2,…,xm。
Step1:将X的每一维进行去均值化,即减去这一维的均值。
Step2:用式2计算样本的协方差矩阵。
(2)
Step3:求出协方差矩阵特征值及对应的特征向量。
Step4:将特征向量按对应特征值大小从上到下按行排列成矩阵,取前s行组成矩阵P;
输出:Y=PTX,Y即是X降到s维后的数据。
为了缩小投影的误差,需要选取合适的s值,可用如下公式来确定s值:
(3)
其中,m表示特征的个数,分子计算的是数据原始点与投影后的点距离的总和;Error表示误差,误差越小说明保留的主成分越多,降维的效果越好。一般控制Error的值小于0.01,即保留原数据99%信息特征。
1.3 K-means聚类与二分K-means聚类
数据挖掘的主要任务之一是聚类分析,它将物理或抽象对象的集合划分成多个类簇,同一个簇中的对象彼此相似,不同簇中的对象彼此相异[11]。
K-means聚类算法在众多聚类算法中应用最为普遍。该算法首先根据数据集大小随机确定k个初始点为质心;然后将数据集中的每一个点分配到一个簇中,即为每一个点找到距其最近的质心,并将其分配给该质心所对应的簇;最后,每一个簇的质心更新为该簇所有点的平均值,重复以上步骤,直到质心不再变化[12]。K-means算法对初始质心的选择比较敏感,随机生成的k个质心可能出现质心聚集的情况,导致聚类效果可能是局部最优的。
误差平方和SSE是一种用于度量聚类效果的指标,其值是所有簇中的全部数据点到簇中心的误差距离的平方累加和。SSE公式如下:
(4)
其中,k为指定的簇数;ci为第i个簇的质心;x为质心为ci的簇中的数据;dist计算的是两个向量的欧几里得距离。SSE的值越小,说明全部数据点越靠近于它们各自所属的簇的中心(即质心),聚类效果也越好。
作为K-means算法的优化算法,二分K-means聚类算法首先将所有数据点看成一个簇,然后将该簇一分为二,并选择一个簇进行k均值(k=2)划分。选择的标准是被划分的簇能最大限度降低SSE的值,以此进行下去,直到簇的数目等于用户给定的数目k为止。该算法与K-means算法相比,聚类速度更快,受初始质心的影响更小,聚类效果更好。
2 基于PCA和二分K-means协同过滤推荐算法设计
2.1 基本思路
针对传统基于用户的协同过滤推荐算法所存在的评分矩阵稀疏性与扩展性的问题,文中设计了一种高效的协同过滤推荐算法—基于PCA降维技术和二分K-means聚类的协同过滤推荐算法PK-CF(collaborative filtering recommendation algorithm based on PCA dimension reduction and bisecting K-means clustering)。
(1)稀疏性问题的解决思路。
利用PCA对评分矩阵进行降维处理,保留最能代表用户兴趣的主成分,同时缓解评分矩阵高稀疏性问题。
(2)相似度计算时耗问题的解决思路。
协同过滤算法需要先计算每两个对象间的相似度,再搜索最近邻进行推荐,但随着用户和项目的不断增加,相似度的计算量变得非常庞大,传统算法的可扩展性问题也凸显出来。为此,一些学者使用了数据挖掘中的K-means算法,根据用户的历史评分记录,计算其与每个簇质心的相似度,把目标用户划归到所属的簇内,缩小最近邻搜索范围再进行相似度的计算,减小计算量。但是K-means算法对初始质心的敏感性可能导致聚类效果是局部最优的,会影响最终的推荐准确度。
为此,文中在基于用户的协同过滤算法中引入二分K-means算法,首先将数据集中所有用户—项目评分数据看成一个簇,然后将簇一分为二,当簇值小于指定的K值时,以被划分的簇能最大限度降低SSE的值为标准,选择一个簇进行k均值(k=2)划分,直到簇的数值等于K值时,算法停止。
2.2 PK-CF算法流程
PK-CF算法的流程如下:
Step1:将评分数据转换成用户—项目评分矩阵,然后对每行缺失值进行填充,填充值为此行评分值的均值。
Step2:按图1所示的流程运用PCA算法提取数据中的主成分(保留精度为99%),得到降维后的矩阵R并记录特征值与特征向量。
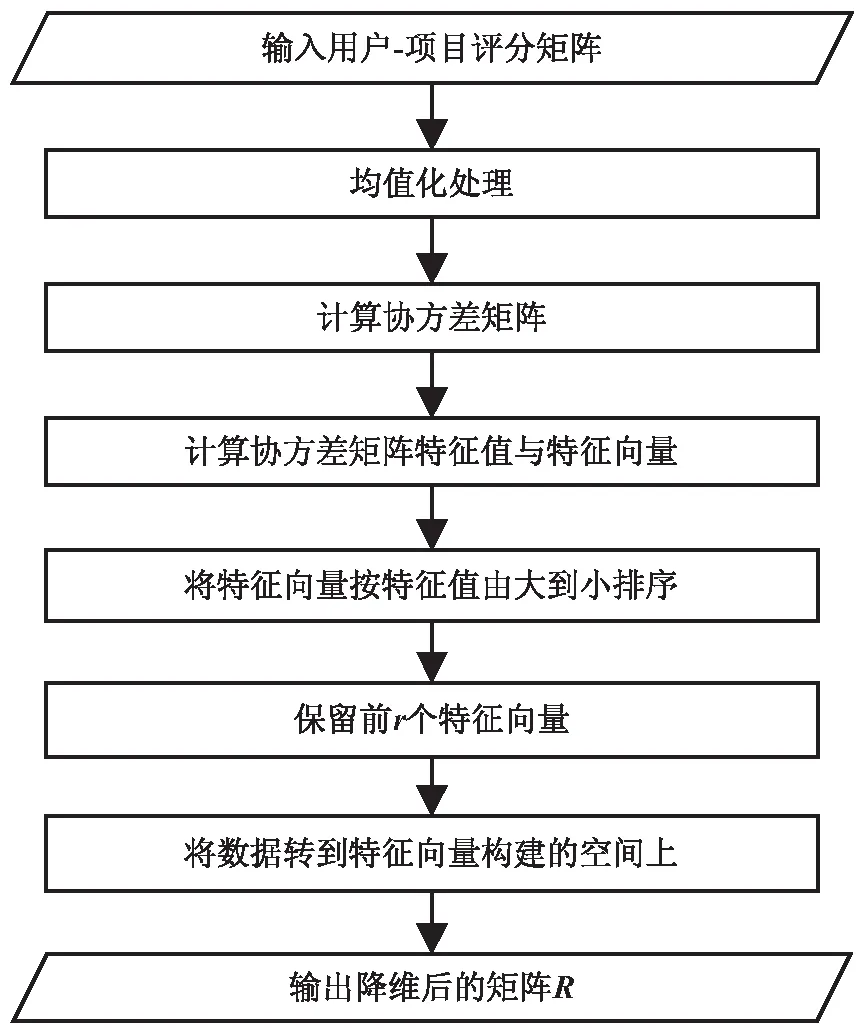
图1 PCA降维过程
Step3:利用图2所示的流程对降维后的矩阵R进行二分K-means聚类,得到多个簇及各簇的质心。
Step4:当要预测用户u时,根据特征值与特征向量求出用户u在主成分向量空间的坐标,并用式1计算其与各簇质心的相似度,用户u属于与其相似度最高的质心对应的簇,再求出u与簇内各用户的相似度,形成一个用户相似度矩阵X。
Step5:用基于最近邻的预测方法[13]来预测用户u对未评分项目i的评分,具体公式如下:
(5)

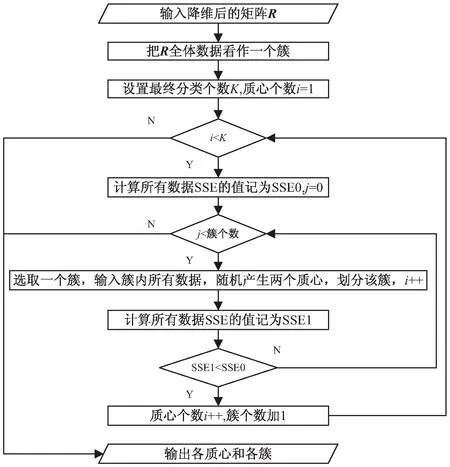
图2 二分K-means聚类过程
Step6:根据预测评分进行TopN推荐,形成推荐列表。
3 实验与结果分析
3.1 数据集
实验使用美国明尼苏达大学GroupLens项目组提供的MoviesLen数据集,该数据集包括943名用户对1 682部电影的100 000条评分记录,记录包含user_id、itme_id、rating和timestamp四个字段,对应用户ID、电影ID、评分值和评分时间四个属性。通过计算在整个数据集中未评分项目所占的比例,得出数据的稀疏程度为93.695 3%,适合检验PK-CF算法在数据稀疏状况下的推荐效果。
3.2 评判标准
实验采用平均绝对误差[14](mean absolute error,MAE)作为推荐预测准确度的评判标准,MAE反映预测的用户评分与实际的用户评分之间的偏差,偏差越小推荐质量越高。MAE计算公式如下:
(6)
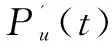
TopN推荐的预测准确度一般通过召回率Recall与准确率Precision来度量[15]。召回率描述的是推荐正确的项目评分记录数与测试集中的所有项目评分记录数之比,准确率描述的是推荐正确的项目评分记录数与所有推荐的项目评分记录数之比。推荐结果Recall和Precision越高,推荐质量越好。召回率与准确率计算公式分别如下:
(7)
(8)
其中,R(u)为对用户u推荐的N个项目的集合;T(u)为用户u在测试集上喜欢的物品的集合。
在实际应用中,需要综合考虑召回率与准确率,最常用的方法是F-Score,它是Recall和Precision加权调和平均。F-Score得分越高,说明推荐准确度也高[16],计算公式如下:
(9)
3.3 结果分析
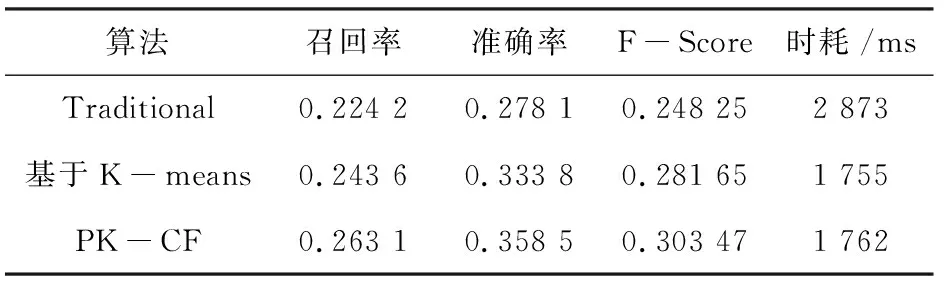
实验前测得最终分类个数在12 文中共进行4次实验来验证PK-CF算法的有效性。随机地把数据集按照4∶1的比例分为训练集与测试集,每次选择不同的训练集与测试集分别运行传统的基于用户的协同过滤算法,基于K-means用户聚类的协同过滤算法和文中的PK-CF算法,对结果取均值。 (1)推荐预测准确度测试。 实验结果如图3所示。 图3 推荐预测质量比较 可以看出,在最近邻个数L=25时,三种算法都取得了较好的推荐质量;而文中的PK-CF算法的MAE值在不同最近邻个数下都比传统的基于用户的算法和基于K-means用户聚类的算法要小,能够有效地提高推荐质量。 (2)TopN推荐的预测指标对比。 表1与表2的数据都是在最近邻个数为25状况下的实验结果。 表1 近邻个数为25,N=10时不同算法的指标 表2 近邻个数为25,N=20时不同算法的指标 可以看出,文中的PK-CF算法能有效提高推荐的召回率、准确率和F-Score值,而且当TopN推荐的N为20时,基于K-means的算法和文中的PK-CF算法的F-Socre值都大于N为10时的F-Score值,所以为了提高推荐质量可以适当增大N的值即推荐数量。在算法运行的时间方面,PK-CF算法和基于K-means的算法运行时长基本相同,但与传统的协同过滤算法相比运行时长明显减小很多。 文中将传统协同过滤推荐算法与PCA降维和二分K-means相结合,设计出新的协同过滤推荐算法。该算法用PCA降维技术缓解数据集稀疏问题,同时使用二分K-means聚类方法对用户聚类减少查找相似用户的时耗。实验结果表明,该算法能够有效提高推荐质量。

4 结束语
