基于协同过滤和隐语义模型的混合推荐算法
2020-04-15李小波陈华辉
徐 吉,李小波,陈华辉,许 浩
(1.宁波大学 信息科学与工程学院,浙江 宁波 315211;2.丽水学院 工学院,浙江 丽水 323000)
0 引 言
随着互联网的发展,人们获取信息的方式愈加丰富,海量信息在满足需求的同时,也为人们带来一些困扰。大量信息中的无效信息一方面干扰了人们对正常信息的判断,另一方面也降低了人们对信息的处理效率[1]。协同过滤算法[2]一般根据用户的评价信息来推测用户的喜好,但受到数据稀疏问题[2-3]的影响,很多时候无法得到较为理想的推荐结果;除此之外,一般协同推荐算法忽略了用户兴趣的动态变化;文中对传统协同过滤算法存在的上述问题进行了研究,并提出了改进后的协同过滤混合推荐推荐算法,用以解决上述问题。
就目前的现状来看,用的最多的当属协同过滤算法,它的突出缺点就在于解决数据稀疏性上表现不佳,导致在数据稀疏时,推荐性能大打折扣。LFM算法[3]是一种协同滤波算法,但是建立在模型的基础之上,而经过改进的LFM在缓和稀疏性问题上有一定的作用,但是它进行降维处理时容易造成数据的丢失[4]。传统的推荐算法已经无法再产生较为精准的模型数据,究其缘由,很大一部分是由于算法的局限性,当然,也不排除和数据本身的差异性有关。当前越来越多的推荐系统会选择融合多种策略,将各种算法的优点整合到一起,以克服单一算法的局限。
1 协同过滤算法
1.1 相似度计算方法
对于协同过滤算法来说,其最关键的内容是对用户或者是项目间的相似度进行计算[5]。在这个过程中可以采用不同的计算方法,下面对其中几种比较典型的方法进行介绍。
(1)Pearson相关系数法。
当前在推荐算法中已经较多地使用了Pearson相关系数法[6-7]对用户或者项目间的相似关系进行计算,具体如下所示:

(2)余弦相似度法[8-10]。

(2)

在实际中不同的用户间往往存在明显的差异性,各个用户的评价标准也不相同。改进的余弦相似度[9]公式如下所示:
(3)
(3)Jaccard相关系数法[8,10]。
在很多情况下主体的特征属性值并不是连续的,在这些情形下无法直接对其相似度进行衡量,而是需要采用一些特殊的符号进行描述。有学者提出了Jaccard相关系数法,其公式如下所示:
(4)
对于此类问题可以采用1/-1代表用户喜欢/不喜欢,0代表未标注,可以将用户U,V间的Jaccard相关系数计算公式表示为:
(5)
其中,ui表示用户u对项目i形成的标注,1{*}表示指示函数。
1.2 改进的项目相似度计算方法
相似度计算结果的准确性比较依赖于数据量的大小,如果数据量较小,往往难以得到较好的效果。这些方法也比较容易受到数据稀疏性的影响,这必然会造成相似度计算结果的不准确。可以采用合理的方式对其相似度计算方法进行优化,如果两个项目间没有共同评分项目,此时无法直接对两个主体间的相似度进行计算,其中的稀疏评分矩阵即如表1中所示。

表1 稀疏评分矩阵
通过表中数据可以明显地看到,项目a,b不存在共同评分用户,因此难以直接对项目a,b的相似度进行计算。经过分析可以发现出现这种问题的主要原因是数据的稀疏性。在表1中虽然没有直接对项目a,b共同评分的用户,但可以发现其他项目与a之间含有一些共同评分用户,其中的一些项目与b也有明显的相似度关系。此时可以根据项目a与其余项目间的相似度关系构建可信模型,然后可以间接得到项目a与项目b间的相似度关系。在表中可以发现c,d,e,f和a都含有可信关系,并且与b也有一定的相似性,因此可以通过间接的方式得到二者的相似度,具体的传递方式是b->f->a,b->e->a。
1.3 可信关系建模
首先是根据项目来进行可信关系建模,然后将其应用到相似度的传递过程中。在日常生活中当有人向你推荐他信任的物品时,你会有较高的可能性去接受这种推荐,因此人们之间存在一定的信任关系。在对协同过滤算法进行设计时可以考虑这种信任关系,然后将其应用到信任网络的构建中。然后可以进行可信关系建模并完成对相似度的传递。基于上述方式能够实现对间接相似度的计算。
由于大量的用户可能会对这两个项目进行评分,各个用户的评分存在一定的差异性,如果这种差异性不明显,这说明推荐的效果比较好。一般可以将用户对项目的评分情况设置一个阈值,当用户的评分在阈值范围内时,即认为项目之间存在较为可靠的信任关系。
准确推荐的含义可以表述为:用户a,b都对项目i进行评分,并且其评分结果在阈值θ之内。准确度可以表示为如下公式:
Success(a,b,i)⟺|Ra,i-Rb,i|≤θ
(6)
根据相同的定义,当用户u对两个项目i,j都评分,而用户a对项目i进行评分,此时可以将正确推荐的公式表示为:
Success(i,j,u)⟺|Ru,i-Ru,i|≤θ
(7)
项目j可以正确推荐项目i的集合如下所示:
SuccessSet(i,j)={(u,v,i):success(u,v,i)}
(8)
项目间的信任关系可以表示为:

(9)
基于先前的分析可知,正确推荐所占据的比例对存在明显的影响。此外,信任关系还与其自身可靠性相关。但是还需要注意一个问题,即当其权重和用户的评分数目是正相关关系时,会导致评分数目多的项目受到更大的影响,此时应该使用一个影响权重进行处理,其可以表示为如下公式:
(10)
在传递相似度时,两个物品i,j的信任关系即为:
(11)
1.4 相似度传递的计算
由于数据中往往存在明显的稀疏问题,将会影响到相似度的计算结果,因此需要通过对相似度的传递来解决此问题。在这个过程中要利用项目之间的信任关系进行分析,其具体的过程如下所示:首先根据信任矩阵得到信任度最高的项目集合,然后根据步骤1中的结果得到项目间的间接相似关系。
首先需要根据信任矩阵得到项目i的信任集合,并且已知p属于I,然后求解两个项目i,j的间接相似度,其中传递时的权值是项目i对项目p的信任关系,最后采用加权平均的方式计算间接相似indirectsim(i,j),其公式如下所示:
其中直接相似度可以采用余弦相似度方法进行计算,而间接相似度的计算过程较为复杂,其需要先根据项目之间的信任关系进行建模,在此基础上传递直接相似度。整个算法可以划分为如下多个过程:
(1)根据用户项目评分矩阵对其相似度进行计算;
(2)根据用户项目评分矩阵来构建可信关系模型;
(3)基于上一步得到的可信关系模型来传递相似度,并得到其间接相似度;
(4)根据得到的直接与间接相似度进行加权计算,可以计算出项目间的相似度;
(5)根据相似度获取项目的最近项目邻居集合;
(6)可以对未评分项目进行评分。
2 隐语义模型
2.1 定 义
隐语义模型[11]是一种利用矩阵分解得到结果的算法,实质就是通过降维的方法将一些没有用的信息和噪声剔除,从而提高预测数据的准确性,也在一定程度上缓和了数据稀疏带来的不良影响。LFM当属矩阵分解算法中最适合推荐系统的模型。
Simon Funk[12]将高维矩阵进行分解,得到维数较低的两个矩阵的乘积,如下所示:
R=PTQ
(13)
其中,P是m行k列的矩阵,Q则为n行k列的矩阵,m和n则分别代表用户的数量与项目的数量。则用户u对项目i的评分可以表示为:
(14)
可见,隐语义模型的思想本质上是借助最小化的评价方法RMSE[13-15]对矩阵P、Q学习的一个过程,其中puk=P(u,f),qik=Q(i,f)。
2.2 用户兴趣迁移模型
隐语义模型着重强调的是最小化求解原则,用户对项目的评分是在保持条件不发生变化的理想条件下的,但是事实情况是,用户的兴趣有一个变化的过程,这在传统的隐语义模型中并没有得到体现。
在进行样本训练的过程中发现,与推荐时间最接近时,用户对项目的评分最能反映出用户的喜爱程度。为了比较客观地反映这种喜好,则需要将每个时间段的评分按照时间由远到近的顺序选取一个相应的权重系数,就可以很好地反映出用户的爱好在这段时间里的一个变化过程[16]。在面对这种问题时,需要将时间因素纳入到整个评分计算公式中,作为推荐算法的一个部分,可以更好地反映出哪些更加合适用户的个人喜好。这当中的一个典型模型就是基于遗忘的兴趣模型。目前,心理学家普遍认为,喜好和记忆遵循着相似的变化规律,即随着时间向后推移而慢慢弱化,直至被人遗忘,并且,越到最后遗忘的越慢,最终会达到一种稳定状态。世界文明的一个心理学家—艾宾浩斯,对人类的遗忘现象做过一个数学统一,得到一条遗忘特性曲线,这就是著名的艾宾浩斯遗忘曲线[17],如图1所示。

图1 艾宾浩斯遗忘曲线
接着,便逐渐开始有学者将这种规律运用到推荐算法的模型中。Koychev等人[18]利用推荐系统将用户的喜好漂移导入了兴趣模型中,在他们看来,人们喜好的变化会按照艾宾浩斯曲线规律发展,因此,他们提出了一个遗忘规律性的兴趣变化模型。这种模型在记忆曲线的基础上对不同项的评分分配一个比重系数,并且设置一个阈值,如果权重的取值低于这个阈值就忽略不计。Maloof[19]在此基础上又提出了一种基于遗忘窗口的兴趣变化模型,在这种模型中,用户的评分会随着权重的推移而慢慢减少。
但是在实际的推算中发现一个问题,那就是直接将记忆曲线导入推荐系统中会导致与推荐时间接近的兴趣值被过分放大,反之,较远的兴趣值会被基本忽略。对于上述问题,需要改进一下函数,重新建立一个模型,如下表示:
fu,i=α+(1-α)*e-(tnow-tu,i)
(15)
其中,α是一个0-1之间的变量,表示兴趣变化的影响范围,tnow是现在的时间到初始时间之间的差值,tu,i是用户u进行项目评分时的时间和初始时间的差值,初始时间的选取一般选择某个时间点作为参考点。
通过对该函数的定义进行简单分析可知,用户对项目的这种爱好程度会推着时间的推移而呈现出一个衰减的状态。在推荐时间的节点处,函数取得最大值,当时间趋向无穷远处时,函数取得最小值,无限接近α。关于α的取值,1代表的是它将用户的评分同等看待,这和传统算法是完全一致的,若α的取值是0,则意味着用户喜好的变化遵循艾宾浩斯曲线的规律特性。可见,通过对α的值进行调节,可以找到一个合适的值,使得用户的兴趣喜好可以很好地与评分匹配,更能满足用户的客观需求。
2.3 引入时间参数的隐语义模型
把含有用户兴趣变化的函数引入到改进的模型中,改进之后的RMSE可以更好地对样本集进行训练,以此来求出最佳的P、Q。所以,改进后模型的损失函数重新进行如下定义:
(16)
为了将该损失函数最小化,需要通过梯度下降方法[20]将其做最优化处理。函数在迭代的过程中,经历一段时间的运算,便会到达一种稳定的状态,为此,可以设置一个合适的阈值,当迭代计算到这一步时,就可以停止继续迭代。
文中算法先设定一个数值K来判断该函数是否需要继续运算,通过梯度下降的方法进行求解的过程如下所示:
(1)设定两个参数变量α和K,前者表示迭代的步长,而后者表示需要进行迭代的次数。需要指出的是,随着迭代过程的推进,步长会慢慢的缩减。
(17)

使用下面的公式进行迭代计算,刷新puk和qik的数值。
(18)
(3)记录迭代计算的次数与K值进行比较,当迭代次数超过K时,停止迭代计算,反之再进入第二步。
一般情况下,函数CostFunction在迭代过程中一定会找到一个极值,如果不出意外的话,这一点就是要求的最小值。
3 混合推荐算法
尝试着将以上两种算法整合到一起,既可以解决降维处理时的数据丢失问题,也可以在一定程度上缓和稀疏问题。时间函数的引入可以很好地反映出用户的喜好兴趣的变化,更有助于提高系统的推荐性。在融合时,采用将两种算法隔离开来同时运行,得到的运算结果再进行加权求和的方式。
具体的计算公式如下:
(19)
传统意义上的协同算法,计算相似度时,主要借助的是相关系数法。文中拟采用线性回归法进行求解,为此,需要改写上面的计算公式:
(20)

4 实验结果与分析
4.1 实验数据集
本节将通过实验的方式对算法的具体效果进行验证。在进行测试时首先需要获取实验数据集,这里采用的是MovieLens[21]。MovieLens数据集中含有的用户数目与电影数目分别是968和1 762,用户评分范围是在1~5之间,各个用户已经评分的电影数目都高于1/5;为了有效地对算法的效果进行验证,需要将所有数据划分为训练集与测试集,其比例分别是70%与30%。将邻居集合数目设置为多个不同的值。
RMSE[22-23]在推荐系统的评价体系中占据着非常重要的位置,是衡量系统性能的一个不可或缺的指标。一般的推荐系统会在用户登录系统的那一天就开始推荐,但是因为用户兴趣的变化不断,理论上,和推荐当天距离最短的兴趣就越有可能被推荐为当天的兴趣,在RMSE中将这些兴趣点所对应的时间的比例增加,对模型中的RMSE做了如下修改:
(21)

4.2 实验结果
(1)参数α值对RMSE的影响。
参数α的作用就是控制时间造成的用户兴趣的变化,同时会以最小权重的方式设置下限值。事实上,用户喜好的变化是有一定的规律可循的,因此,需要设置不同的时间权重进行数次实验。将邻居集合数目设置为100,迭代次数为200,学习速率为0.05,实验得到的RMSE数值如图2所示。
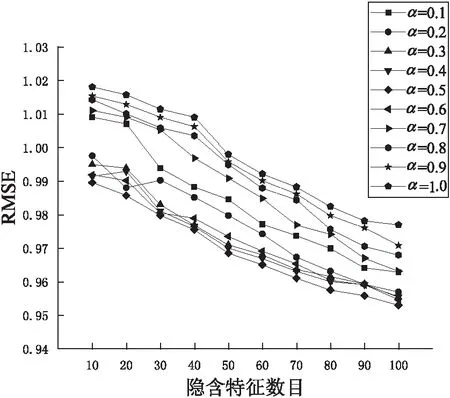
图2 不同参数α下的RMSE
从图2可以看出,在α值变化的过程中,RMSE的数值也会相应地发生变化。当α的取值是0.5时,得到的结果是最好的。
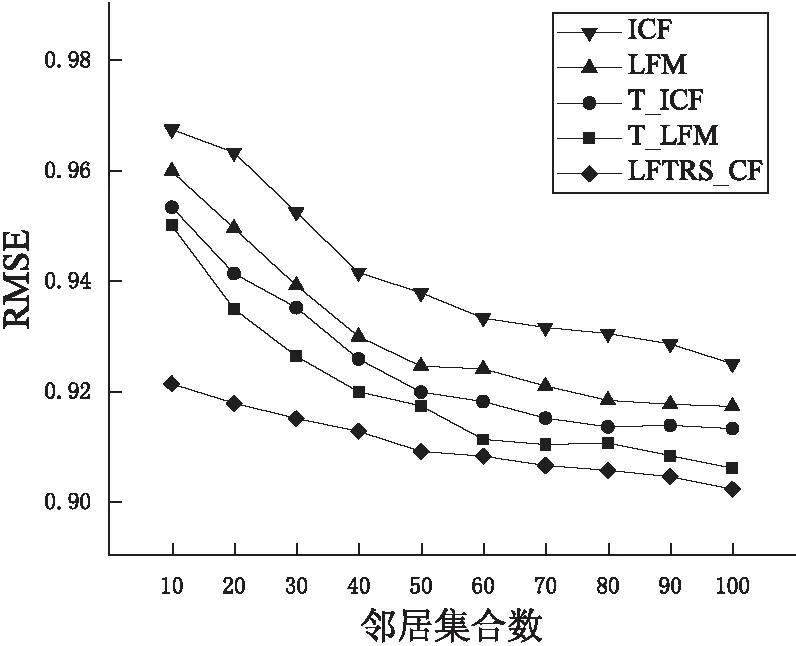
图3 不同邻居个数下各融合策略下的RMSE比较
(2)多种算法对MovieLens数据集的测试。
采用多种算法对数据集进行了测试,设置不同的邻居集合,得到了不同邻居集合下的RMSE,如图3所示。
通过图3能够明显看到,提出的LFTRS_CF算法的RMSE值最小,说明其在准确性方面能够达到较好的效果,优于其他的四种算法。
5 结束语
文中详细研究了推荐算法的优化策略,提出了两种算法,基于项目相似度的协同过滤算法和基于用户兴趣迁移的隐语义模型算法,并在此基础上对其进行线性融合,使得其中存在的数据稀疏性问题和用户兴趣迁移问题得到了较好的解决。提出的混合推荐算法既可以对丢失的信息进行补充,较好地适应用户兴趣的变化,同时大大弱化了数据的稀疏导致的一系列负面影响。
