大数据环境下电力信息系统监控预判的智能分析
2020-04-13卢经
卢 经
(国网新源水电有限公司新安江水力发电厂,浙江 杭州 311608)
大数据环境背景下,电力信息系统的建立要以电力数据为基础,实现对海量数据信息的利用,完善电力系统的功能,避免电力系统运行中各种外部因素所造成的运行故障。电力信息系统监控预判的智能分析对于减少电力系统故障、实现故障处理与预警等具有重要的意义,是当代电力行业发展中的热点议题。
1 项目背景
本项目以电厂作为研究对象,在电厂内部包含了大量的电网运行数据,数据库、服务器等较多。文章中的研究包含了1 个虚拟平台与7 个核心业务系统,在这些系统的使用中,每年所产生的性能检测数据极多,数据存储量每年急速上升。在这种情况下,可以对这些数据利用大数据的手段,采用数据挖掘技术,获得电网系统运行所需要的有效数据,从而为电力系统的决策等提供重要的数据支持。
2 项目目标
在本项目的研究中,主要是以电厂的磁盘使用率、CPU 使用率等作为主要的数据挖掘对象,从而根据挖掘结果,将目标数据划分为5 个警告等级。在此过程中,有必要建立相应的数学模型,通过该数学模型来预测各个样本数据发生的警告等级,如果是高警告等级的样本数据,还需要预测和判断其发生的时间等。
就电厂的实际情况来看,硬件设备、系统数据资源等较多,要保证其预测的准确性,最终选用随机森林算法来建立模型。
3 相关模型以及实现
3.1 系统设计目标以及方法
在本项目的研究过程中,包含的状态较多,在这种情况下,需要采用3 级告警转为5 级告警的概率预测方式。具体的应用过程中,需要从所获得的告警数据中获得提取相应的正负样本。对每个5 级样本而言,需要将前一天的所有3 级告警作为一条正样本,而每个5 级告警之前5 天的3 级告警作为一条负样本,正样本的数量要略微少于负样本的数量。由于采用的是随机森林算法,需要在决策过程中依据相关的技术建立决策树模型,从而确定其最终的分类结果。就随机森林算法的应用效果来看,其本身对于复杂问题的分析与分类等能力较强,使得其在应用中对于一些噪声数据等具有较好的稳定性。该算法在运算速度、变量重要性度量等方面有明显的有效优势,因此在很多检测问题的处理上有着极为广泛的应用。
3.2 系统结构具体设计
(1)主站结构设计。要实现对电力系统故障的预判,使得大数据环境下电力信息系统可以发挥其应有的作用,就需要建立相对完善的系统结构。电力系统中应该包含主站与子站,主站的承担着子站数据的汇总功能,需要在应用的过程中根据系统的功能差异性,实现对这些数据的合理利用,从而发挥数据的最大价值。主站与子站之间存在着紧密联系,两者之间需要通过通信网络实现连接,一般通过TCP/IP 与电话拨号的方式进行连接,以实现两者之间的数据传输与共享。
(2)子站结构设计。在子站的设计过程中,要避免子站与监控系统的组网连接,因为监控系统是一种实时传输系统,在此情况下,子站与监控系统同时处于安全运行状态下,不同的安全区需要采取必要的隔离措施。因为在实际的生活中,Windows 系统的应用较多,这也就使得子站系统在设计与使用中存在病毒因素的干扰,因此,需要在设计中将其子站系统与保护系统实现共网,从而减低子站系统运行中受到其他因素的干扰作用。
4 数据预处理
4.1 缺失值处理
在电力信息系统的数据处理中,常常存在着数据缺失问题。很多因素都会诱发数据缺失现象,一般将这些缺失原因分为人为与机械两种。机械原因主要是由于机械问题所引发的数据丢失或者数据保存失败等,比如存储器损坏使得系统运行数据不能有效保存,在特定的时期内,服务器无法获得相关的数据;人为原因主要是主观失误等造成的。在缺失值的处理上,一般通过删除与填充进行处理,而在填充过程中,还需综合分析系统运行的情况,科学进行数据填充。
4.2 异常数据处理
在异常数据的处理中,常常存在个别数据过大或者过小的情况,如果将这些异常数据与正常数据放在一起加以处理,就会降低数据处理的准确性,从而使得电力系统对于数据处理的有效性不足。而如果采用简单的数据剔除方式剔除异常数据值,就会造成数据缺失,导致系统内缺乏重要的参数信息等。因此,在异常数据的处理上,最为关键的是对异常数据的判断与剔除。判断与剔除是数据处理中的关键环节,其直接影响着数据处理的质量。异常值一般与正常数值存在着明显的差距,一般包括类型不匹配异常、大小不匹配异常、分布异常等,这些异常情况需要结合数据的实际情况来分析数据出现的合理性,从而采取必要的处理方式。
4.3 数据模型的建立及调优
采用随机森林算法加以建模,数据集的80%与20%分别作为训练集与测试集,将袋外错误率作为衡量的标准,科学选择随机森林中树的规模。为了避免过拟合现象的出现,最终选用了92 棵决策树,根据其模型特征分布情况,可以得到其最终的关键指标。
4.4 模型性能评估
精度、召回率等如表1 所示。

表1 模型性能评估
由表1,可以精确获得模型的精度等指标,结合混淆矩阵,最终获得其模型准确率参数为0.77。同时,其预测效果较好,可以为电力系统的可靠运行等提供重要的数据参考。
5 数据处理过程
在电力信息系统模型的数据处理中,一般采用的是Hadoop 结构,该方案是一个分布式系统基础框架,在应用中可以实现对海量数据的分布式处理。在实际的应用过程中,Hadoop 需要与其他核心软件相配合才能发挥其良好的应用效果,也就是MapReduce 和HDFS 软件,这两个软件在数据处理中分别承担着运算与存储的作用。在数据处理过程中,分布式数据处理过程的成本较为低廉,可以在根据电力系统运行所产生的数据建立相关的存储集群。一般情况下,其设计模型包含了决策层、支撑层、数据层。在具体的应用中,各个模型层分别负责各自的任务,决策层包含了数据分析与处理平台、决策者,在运行中可以进行海量数据的分割处理,使得数据的处理更为高效;而支撑层主要负责的是数据的挖掘与存储,但是该存储过程并不是将数据存储于HDFS,而是将其存储于HBase;数据层主要负责的是数据的采集与预处理过程,子站系统可以在获得相应的数据以后对其加以预处理,进而将预处理以后的数据逐步传输于高层,高层再对数据进行进一步处理,如图1 所示。
6 故障预判过程
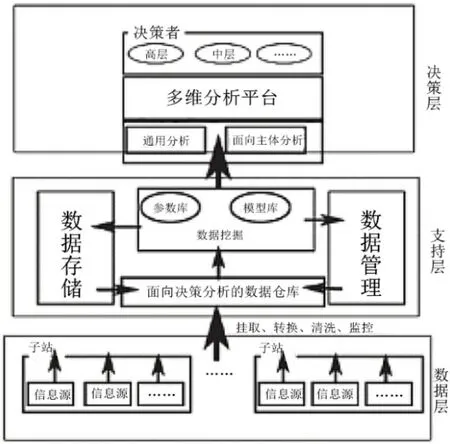
图1 电力信息系统大数据故障处理模型
在大数据环境下的电力信息系统的故障预判过程中,子站系统需要将获得的电力系统运行数据等加以预处理,随后,这些数据逐步传输于主站系统中。在整个电力系统中,包含了一个主站与多个子站,主站可以主动接收来自不同子站系统内的预处理数据,并对这些数据加以精细化的处理,使得其能够变为更为有效的数据。数据预处理过程中,子站可以剔除一些垃圾数据或者无用数据,避免这些无用数据进入主站干扰主站的数据处理过程。要保证数据的剔除效果,就需要重视预处理过程,及时清除子站中包含的一些重复数据等。预处理过程主要包含了数据的抽取、转换、清洗与监控过程,这些环节的处理过程在一定程度上提高了数据预处理的实际效果。
7 结束语
近年来,大数据时代的到来改变了各行各业的发展模式,有些电力企业借助于大数据技术,逐步建立了电力信息系统,实现了故障预判的智能分析,在维持了电力系统稳定性与可靠性的基础上,带动了电力行业的技术创新,实现了电力行业的长远发展。
