基于大数据分析的社区矫正对象再犯罪预警研究
2020-04-13周逸璇李晶晶徐津霞刘红杏
◆周逸璇 李晶晶 徐津霞 刘红杏
(1.云南司法警官职业学院“科学研究基金项目”课题组 云南 650211;2.云南中医药大学 云南 650211)
社区矫正最初起源于西方国家,我国从2003 年开始在北京等6 个省、市开始社区矫正试点工作,2007 年推广至全国实行[1]。十多年来,经过各地社区矫正机构的共同努力下,成功地将一大批社区矫正对象教育矫正为守法公民,在社会治理和法治中国建设中发挥了重要的作用,节约了国家的刑罚执行成本,维护了社会的和谐与稳定,有效促进了司法文明的进步与发展[2]。2020 年7 月1 日起开始施行的《中华人民共和国社区矫正法》,将国家支持社区矫正机构提高信息化水平写入了总则,第一次以立法的形式确立了运用现代科学技术对社区矫正对象进行监管和教育帮扶的法律地位,为社区矫正信息化发展提供了有力的法律依据[3]。
在现阶段,利用数据挖掘、模式识别和机器学习等大数据技术对社区矫正对象从入矫、施矫到解矫全过程产生的数据整合成数据集,然后进行聚类、关联、分类和深度分析,提炼信息规律,获取知识,基于数据分析对社区矫正对象再次犯罪的相关因素进行研究,进而对社区矫正对象再犯罪的危险性进行预测预警,可以有效预防和减少犯罪,提升教育矫正质量,达到维护社会安全稳定的目的[4]。
1 相关概念
1.1 社区矫正
社区矫正是立足我国基本国情发展起来的具有中国特色的刑事执行制度,是与监禁矫正相对的非监禁刑罚执行制度,是指将管制、缓刑、暂予监外执行、假释的符合法定条件的罪犯置于社区内,由专门的司法行政机关、社区矫正机构和司法所在相关社会团体和社会志愿者的协助下,在判决、裁定或决定确定的期限内,矫正其犯罪的行为恶习和心理,促进其改造为遵纪守法的合格公民,促进其顺利回归社会的非监禁刑罚执行活动[5]。
1.2 社区矫正对象
被判处管制、宣告缓刑、假释或者暂予监外执行的罪犯[6]。
1.3 大数据分析
关于大数据的定义,在不同领域有着不同的概念。麦肯锡的报告提出,“大数据”是一种数据集,该数据集超出了一般普通数据库软件的采集、存储、管理和分析能力[7]。大数据并不是描述数据量的大小,而是在种类繁多,数量庞大的多样数据中快速地获取有用的信息[8]。关于大数据的特点,普遍认为有四个:大量化、多样化、快速化和价值化。通俗地讲,就是从海量的数据中挖掘出有价值的信息[9]。
1.4 社区矫正对象再犯罪
社区矫正对象再犯罪,是指社区矫正对象在社区矫正期间再一次实施犯罪[10]。
2 全国社区矫正对象监管现状
截至目前,全国司法行政机关和社区矫正机构累计接收社区矫正对象478 万人,累计解除矫正对象411 万人。2019 年全国新接收社区矫正对象57 万人,解除矫正59 万人,全年列管126 万人[10]。目前,全国社区矫正对象的再犯罪率为0.2%,但是部分省份的部分地区远远高出了这个数值,因此研究如何利用大数据分析对社区矫正对象的再犯罪情况进行预警,具有非常重要的现实意义。
3 基于大数据分析的社区矫正对象再犯罪预警研究
目前,全国各省、市均已建立了社区矫正管理信息系统,系统中均包含社区矫正工作产生的结构化数据(例如社区矫正对象基本信息和刑罚执行信息等)、半结构化数据(例如社区矫正对象电子定位数据和教育学习数据等)和非结构化数据(例如社区矫正对象的电话记录、视频监控)等海量数据。
通过大数据分析对社区矫正对象进行再犯罪预警的目标是在采集相关数据的基础上,通过特定算法,分析出哪些社区矫正对象具有较大的再犯罪风险,做出预警判断,可以对预警风险系数较高的社区矫正对象进行有针对性的监督管理和教育帮扶,消除其可能重新犯罪的因素,具体研究内容如下。
3.1 筛选指标
表1 为初始考虑的相关指标,它们当中存在着不尽相同的关联关系,并且会预警结果产生不同的的影响,一些指标可能是噪声指标,因此通过相关性分析选择出核心指标非常关键。
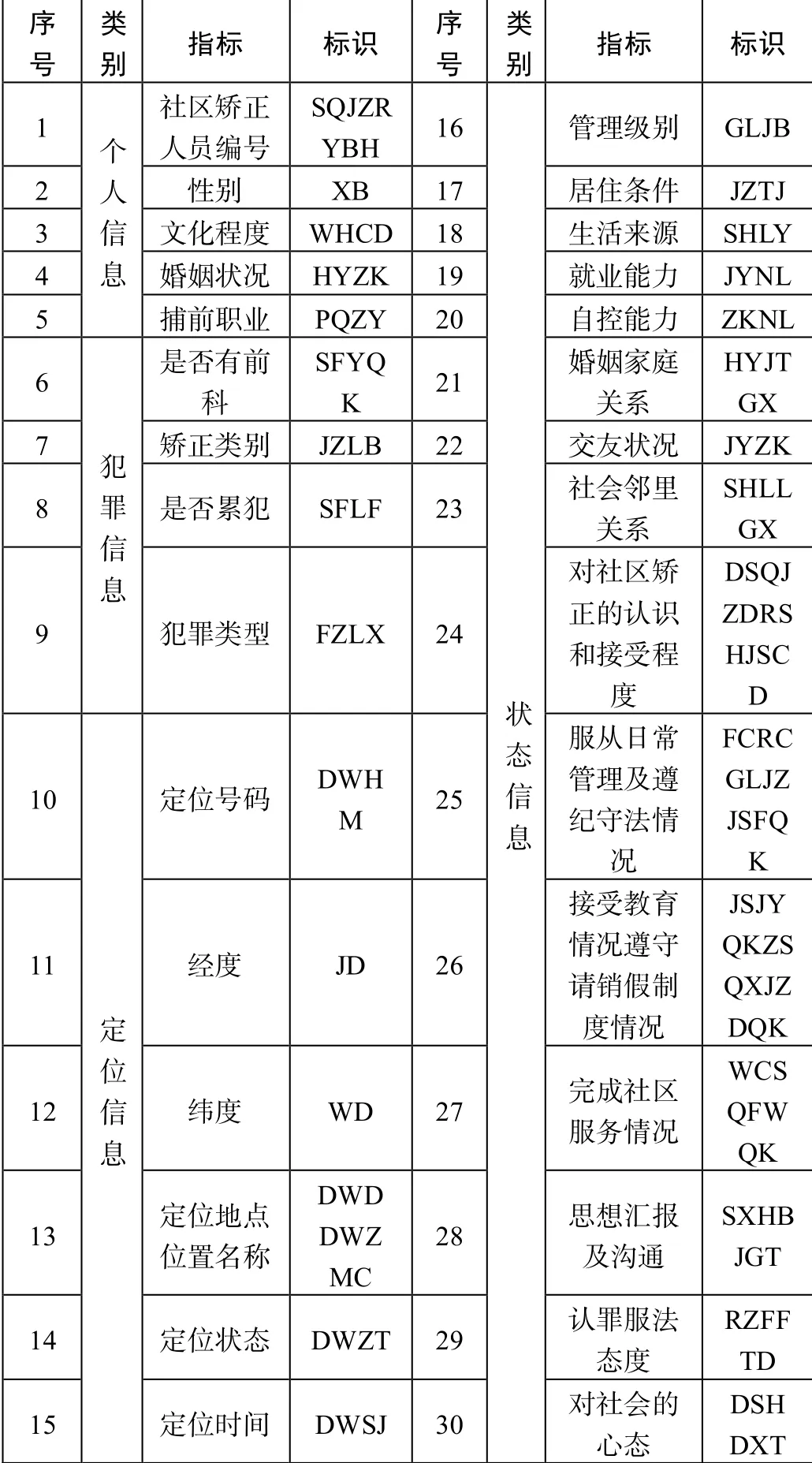
表1 初始考虑的指标
3.2 相关性分析
本研究通过Spearman 相关系数来计算不同指标之间的线性相关性,具体的计算方法为:第一步是变量转换,将指标的变量值转换为排列顺序,第二步是计算转换后的排列顺序数值的相关系数,具体计算公式如下:
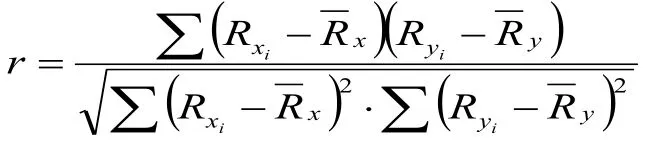
其中Rxi和Ryi分别表示第i个X变量和Y变量重新排序后的次序,x和表示Rxi和Ryi的均值;
根据判断|r|值的不同,则代表的线性相关关系程度如下:

表2 是在对表1 中各类指标与目标变量之间的相关性分析和对目标变量结果的影响程度进行分析之后,得出的关键指标分析结果。
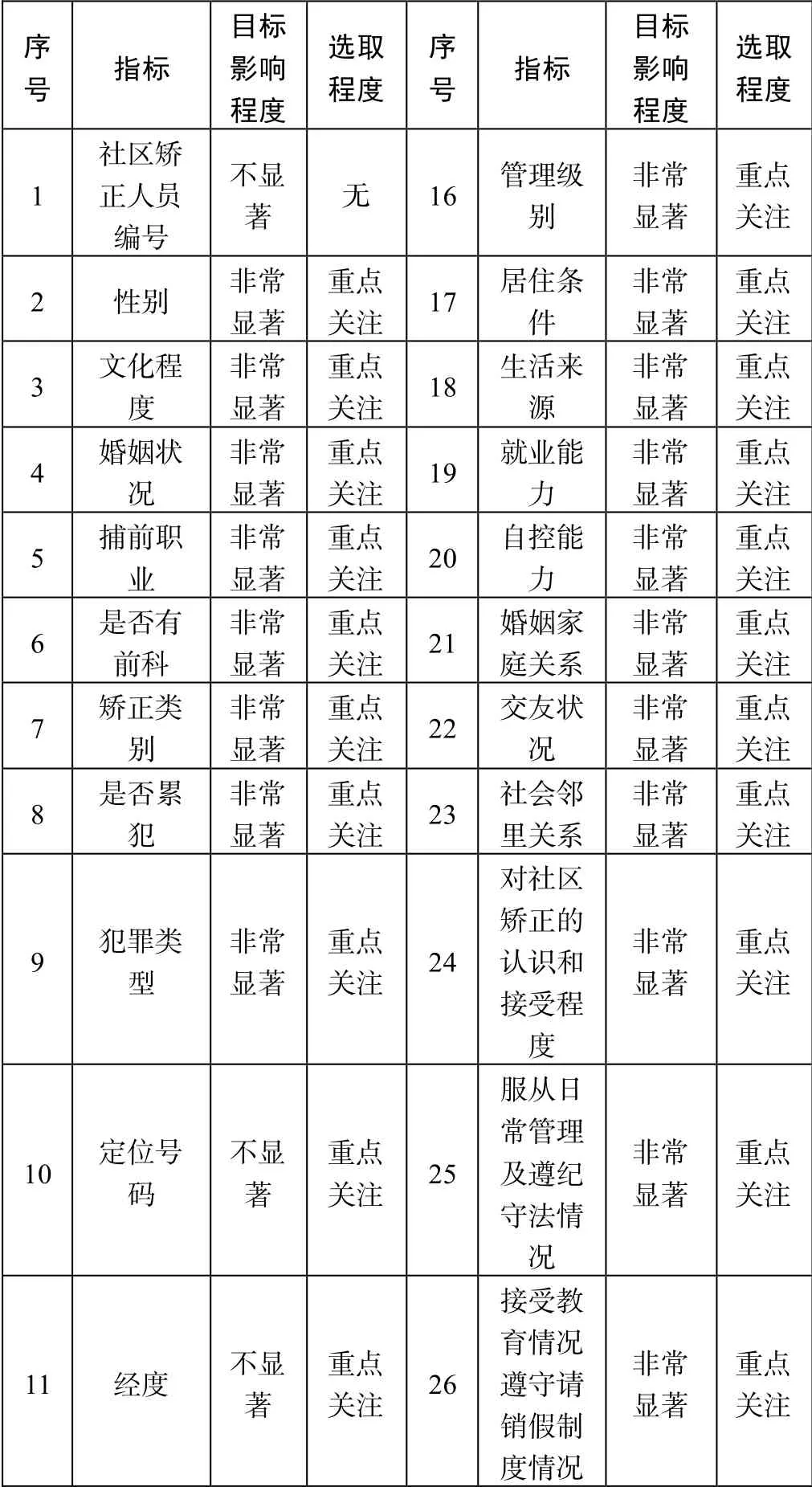
表2 关键性指标分析结果
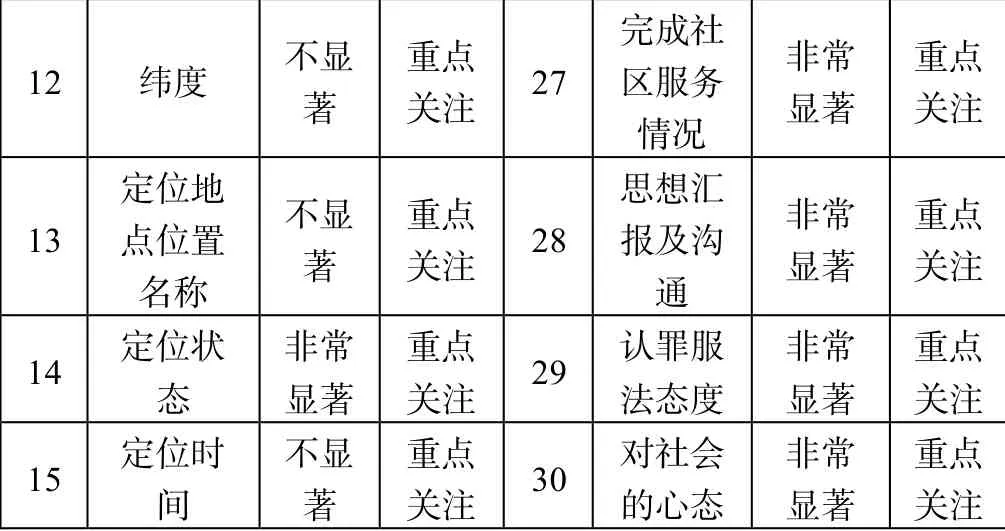
12 纬度 不显著 重点关注 27 完成社区服务情况 非常显著 重点关注 13 定位地点位置名称 不显著 重点关注 28 思想汇报及沟通 非常显著 重点关注 14 定位状态 非常显著 重点关注 29 认罪服法态度 非常显著 重点关注 15 定位时间 不显著 重点关注 30 对社会的心态 非常显著 重点关注
3.3 算法选择
目前,主流的预警算法有决策树、神经网络、逻辑回归等。通过对比分析,决策树具有预测准确率好、速度很快、鲁棒性强、可扩展性很优秀、容易理解等优势,因此本研究选择决策树作为预警算法。
决策树是一个类似于流程图的树形结构,其中每个内部节点标识一个属性测试,每个输出表示一个测试输出,每个叶节点代表类或类分布。也就是说,决策树根据不同的特性,以树型结构表示分类或决策集合,产生规则和发现规律[11]。
综合考虑选取文化程度、是否有前科、是否累犯、对社会的心态、犯罪类型、自控能力、婚姻家庭关系、自控能力、对社区矫正的认识和接受程度、捕前职业、性别、矫正类别、居住条件、认罪服法态度、社会邻里关系为指标,使用决策树对2019 年云南省某县在册120 名社区矫正对象再犯罪进行预测和探索结果,具体分析情况如表3。
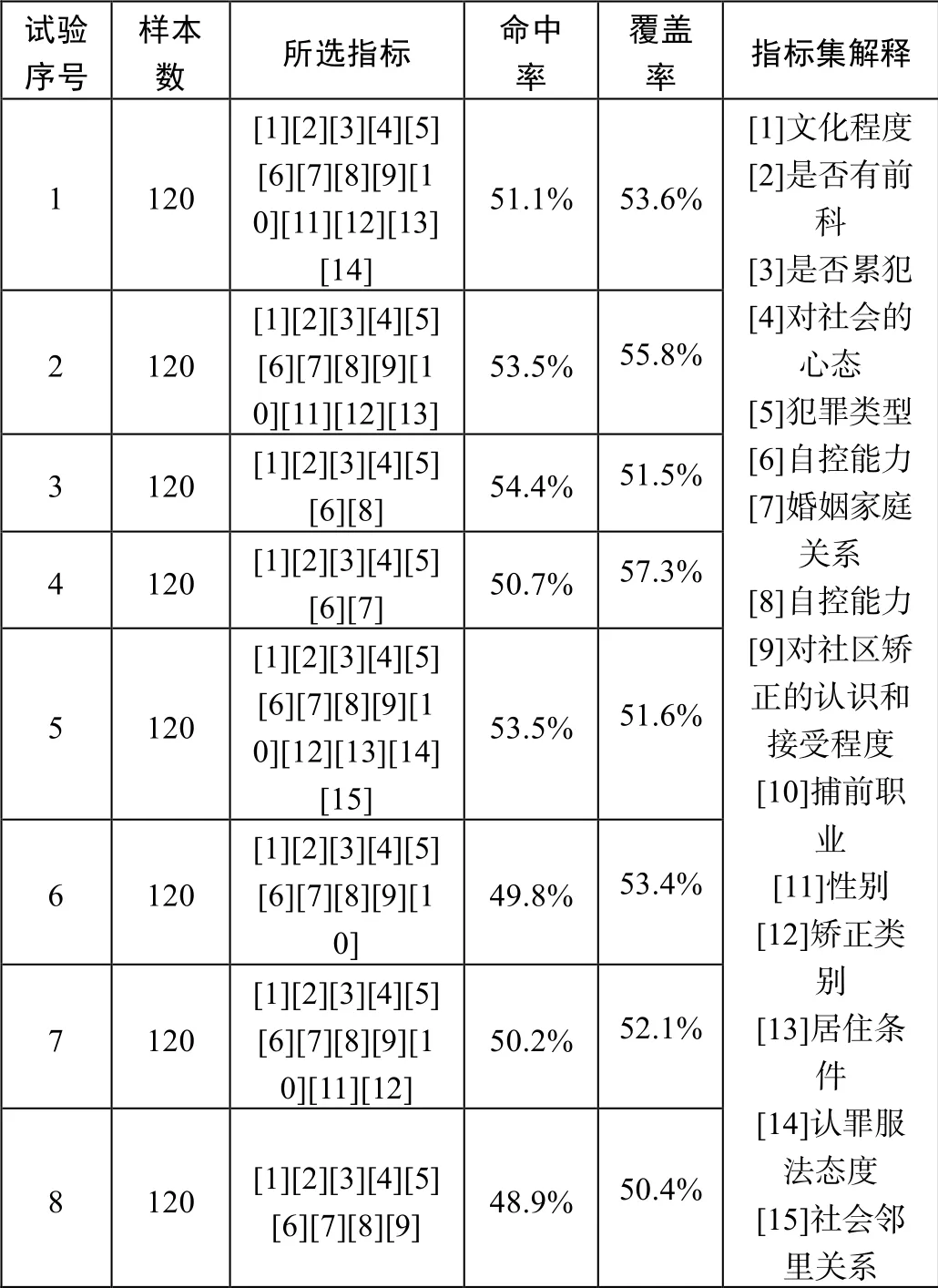
表3 决策树分析结果
3.4 建立模型
利用Clementine 建立模型过程包括数据源的建立->类型选择->字段过滤->特征指标的选择->决策树模型->结果分析,具体操作如图1 所示。

图1 模型建立
表4 内容是对云南省4 个州(市)在册社区矫正对象全年监管情况的再犯罪情况的预测及验证结果。

表4 决策树分析结果
4 结束语
本文在对社区矫正对象监管情况产生的大数据进行指标筛选和相关性分析,得出关键性指标参数,然后通过对比主流的预警算法,选择了决策树作为本预警研究的算法,最后使用Clementine 建立模型,选取云南省4 个州市2019 年列管的社区矫正对象进行预测,并对预测结果进行了验证。
下一步的主要工作是利用计算系统对社区矫正对象的社会关系、同案犯关系等网络进行分析,研究不同社会关系、教育学习和社区服务情况、个人文化程度、心理特征等不同因素对影响服刑人员再次犯罪的显著性并加以分析,为有效预警社区矫正对象再次犯罪提供科学依据。
