大数据上函数查询解答的复杂度分析
2020-04-09吴文莉刘国华张君宝
吴文莉,刘国华,张君宝
(东华大学计算机科学与技术学院,上海201620)
0 引言
函数查询是大数据应用中一种重要的操作,随着大数据地位的提升,如何解决大数据环境下函数查询解答的复杂度问题是大数据应用亟待解决的问题。针对大数据环境下查询复杂度问题,文献[1]进行了开创性研究:首先,指出了数据多样化特性给查询带来了新的挑战,即使是简单的线性查找,在大数据环境下其所需时间也远远超出用户可以接受的最大限度;其次,说明了大数据环境下P 类查询也会变得难以处理;在此基础上,对什么样的查询在大数据上是易处理的、如何求解大数据查询的复杂度等问题进行了讨论。
文献[1]中所研究的查询主要是传统意义上的查询,即查询是一个由数据库到关系的函数[2],没有涉及查询本身包含函数的情况。作为对文献[1]研究成果的一个补充,本文重点研究大数据上函数查询解答的复杂度问题。
本文首先从计算理论角度对函数查询解答问题进行研究,使用映射可归约方法将函数查询语言归约到已知的可判定语言,证明函数查询解答问题的可计算性;其次,使用一阶语言描述函数查询,从数据复杂度及表达复杂度两个方面分析一阶语言的复杂度;最后,在此基础上分析了大数据上函数查询解答的复杂度。
1 函数查询相关定义
文献[3]对关系查询的结构特征进行了详细分析并且给出了查询解答问题复杂度的分析方法和结论,本文首先引用文献[3]关于数据库及查询的定义,并在此基础上进行扩充定义。
定义1数据库[3]。令U 是某个可数论域;数据库是元组B=(D,R1,R2,…,Rk),其中D ⊂U,D 是有限的。对于每一个1 ≤i ≤k,当ai≥0 时,Ri⊂Dai。ai为Ri的秩,B 的类型可以看作=(a1,a2,…,ak)。将向量R1,R2,…,Rk简写成,将数据库写成B=(D,)。
例1 令论域U={2,3,4,5},数据库B=(D,R1,R2),D={2,3,4,5},R1={(2,5),(3,2),(4,3),(5,2)}⊂D×D,R2={4,2}⊂D,k=2,a1=2,a2=1,则该数据库如表1、表2所示。
定义2查询[3]。类型为→b 的查询是部分函数,如下:
满足以下条件:
1)如果Q(B)是有定义的,那么有Q(B)⊂Db。
2)Q是部分函数。

表1 数据库B中的关系R1Tab.1 Relation R1 of database B

表2 数据库B中的关系R2Tab.2 Relation R2 of database B
下面对定义1的数据库和定义2的查询进行扩充定义。
定义3属性。数据库B=(D,)与定义1 含义相同,B中关系Ri中的每个属性都是函数。Att={Att1,Att2,…,Attk}是个集族,Attj是个属性集,Attj中属性的个数与Ri的秩相同。Attj中每个属性(即简单属性)表示如式(1)所示:

其中:l表示行号,i表示列号;函数ti:RO×CO →D,RO表示行号的集合,CO 表示列号的集合,由函数ti确定Attj中每个属性Ai的属性值。
EAtt={EA1,EA2,…,EAk}是扩充属性集,扩充属性EAi对应于中的扩充属性,扩充属性的个数与关系Ri的个数相同。扩充属性表示如式(2)所示:

其中:l 表示行号,i 表示列号;函数eti:Dc→U,Dc表示Attj中某些属性的属性值的笛卡尔积,由函数eti确定属性EAi的属性值。
定义4扩充数据库。令U是某个可数论域;扩充数据库是元组Bf=(D,R1,R2,…,Rk,S1,S2,…,Sk),其中D ⊂U,D 是有限的。对于每一个1 ≤i ≤k,函数集合Si对应关系Ri中的属性的集合,当(ai+1)≥1 时Ri⊂Uai+1。(ai+1)为Ri的秩,亦是Si中函数的个数。其中前ai个函数Sai为简单函数(即简单属性),第(ai+1)个函数Sai+1为复杂函数(即扩充属性)。B的 类 型 可 以 看 作=((a1+1),(a2+1),…,(ak+1))。将向量R1,R2,…,Rk简写成,将向量S1,S2,…,Sk简写成,将扩充数据库写成假设扩充数据库每个关系中只有一个扩充属性。
例2 令论域U={2,3,4,5,6,7},扩充数据库Bf=(D,R1,R2,S1,S2),D={2,3,4,5},R1={(2,5,7),(3,2,5),(4,3,7),(5,2,7)}⊂U×U×U,R2={(4,6),(2,3)}⊂U×U,S1={A1,A2,EA1},S2={A3,EA2}。k=2,(a1+1)=(2+1),(a2+1)=(1+1)。该扩充数据库如表3、表4 所示。其中扩充属性集EAtt={EA1,EA2}。
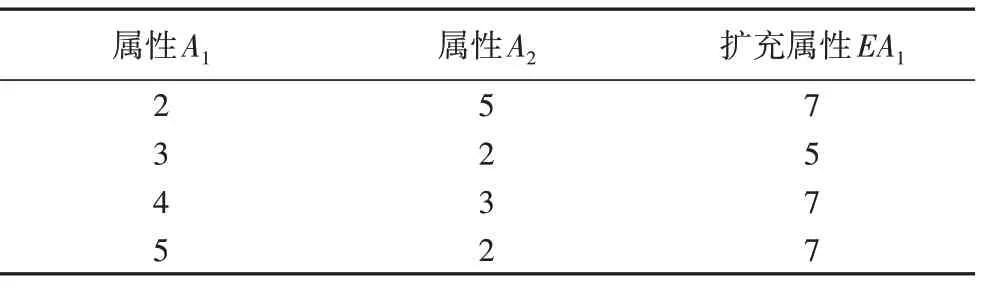
表3 扩充数据库Bf中的关系R1Tab.3 Relation R1 of extended database Bf

表4 扩充数据库Bf中的关系R2Tab.4 Relation R2 of extended database Bf
定义5函数查询。类型为的函数查询是部分函数:
满足以下条件:
1)Qf满足部分递归;
2)如果Qf(Bf)是有定义,那么Qf(Bf)⊂Ub且Qf(Bf)是有限的;
3)函数查询Qf满足一致性条件。
2 大数据上函数查询解答的复杂度
2.1 函数查询解答问题的可计算性
问题描述:已知扩充数据库Bf以及函数查询Qf,问该查询计算机是否可计算。
在计算理论[5]中,论证一个问题是否可计算可以把该问题转化为一个判断一个串是否属于一个语言问题,因此,该问题转化为如下形式:
定义6映射可归约性[5]。如果存在可计算函数f:Σ*→Σ*使得对每个ω,有:
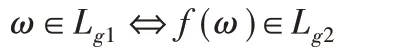
那么语言Lg1是映射可归约到语言Lg2的,记作Lg1≤mLg2。称函数f为Lg1到Lg2的归约。
引理1[3]语言E={〈B,Q(B)〉|B 是数据库,Q(B)是能够在B上解答的查询}是可判定的。
引理2[5]如果Lg1≤mLg2且语言Lg2是可判定的,则Lg1也是可判定的。
定理1语言F={〈Bf,Qf(Bf)〉|Bf是扩充数据库,Qf(Bf)是能够在Bf上解答的函数查询} 是可判定的。
证明 由引理1可知E是可判定的。设M是E的判定器,f是从F到E的归约。F的判定器N的描述如下:
N=“输入查询Qf的编码〈Bf,Qf(Bf)〉:
1)计算f〈(Bf,Qf(Bf)〉)。
2)在f〈(Bf,Qf(Bf)〉)上运行M,输出M的输出。”
因为f 是从F 到E 的归约,如果〈Bf,Qf(Bf)〉∈F,则f〈(Bf,Qf(Bf)〉)∈E。因此,只要〈Bf,Qf(Bf)〉∈F,则M 接受f〈(Bf,Qf(Bf)〉)。故N 的运行可以判定F,即语言F 是可判定的。
2.2 函数查询解答问题的复杂度
已有的复杂类有LOGSPACE、NLOGSPACE、PSPACE、NPSPACE、PTIME、NPTIME、EXPTIME、EXPSPACE[6-12]等。文献[12]详细介绍了两种方法衡量查询解答复杂度,分别为数据复杂度和表达复杂度,以下给出两种复杂度的衡量方法。
数据复杂度 首先确定一个查询,将该查询应用到任意数据库,然后根据数据库大小的函数给出其复杂度。
表达复杂度 需要确定数据库,使用查询语言的任意表达式表示查询,然后根据表达式的长度给出复杂度。
定义7一阶语言。L 是没有函数符号、具有等式的一阶语言,R1,R2,…作为关系符号。使用符号Ri表示关系及作为关系本身,关系Ri的元数隐含在上下文中。First 表示由以下表达式组成的语言:

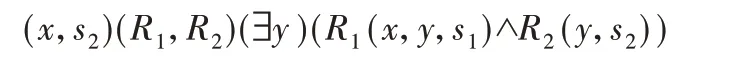
例3如下表达式表示类型为((2+1),(1+1))→2的函数查询。
定理2语言First 的数据复杂度是LOGSPACE(对数空间复杂性类),表达复杂度是PSPACE(多项式空间复杂性类)。
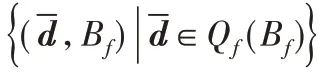
证明 为了测试-d ∈Qf(Bf),需要循环遍历所有量化变量的可能替换。文献[12]中的算法具有LOGSPACE 数据复杂度和PSPACE表达复杂度。
数据复杂度:First的数据复杂性是LOGSPACE[12]。
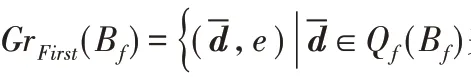
传统意义上的P 类问题在大数据环境下仍然是很困难的问题。比如线性扫描查询类中的每个查询,当数据库中的数据量达到1 PB,得到查询结果所需的时间约1.9 d[15]。因此,传统查询解答问题的复杂度分析已经不适用于大数据上的查询解答。那么,什么样的查询在大数据上是易处理的?哪些查询可以转换为在大数据上是易处理的?
文献[1]提出了Π-tractable 查询的概念,Π-tractable 查询的集合记为,表示经过PTIME(多项式时间)预处理后,可以在NC(并行多项式-对数)[16-17]时间内求解的查询类;用分别为ΠΤP)表示查询类集合(对应于语言集合),该查询类中的查询(对应于语言)通过对其重新分解以进行预处理后,可以将其有效地转换为Π-tractable查询。
文献[1]中所研究的查询主要是传统意义上的查询,没有涉及查询本身包含函数的情况,即没有涉及到函数查询。本文使用量化布尔公式归约将函数查询类归约到布尔查询类中,使用NC-factor 归约将函数查询语言FL 归约到集合ΠΤP中、将函数查询类OFL归约到查询类集合ΠΤQ中,即初步证明函数查询在大数据上可以将其有效地转换为Π-tractable查询。
遵循复杂性理论[18]的惯例,使用符号的有限字母表Σ 编码数据库和查询。数据库可以编码为字符串B ∈Σ*,并且具有必要的分隔符;查询Q也可以编码为字符串Q ∈Σ*。语言Υ是Σ*×Σ*的子集。使用Υ 来编码布尔查询类O,使得对于每个〈B,Q〉∈Υ,Q 是O 中的查询,B 是数据库,Q 在B 上有定义,并且Q(B)为真。即,Υ 可以看作二元关系,当且仅当Q(B)为真时,〈B,Q〉∈Υ。Υ称为布尔查询类O的语言。
使用量化布尔公式归约[13],函数查询类可以归约到布尔查询类O 中。类似地,语言FL 是Σ*×Σ*的子集。使用FL 来编码函数查询类OFL,使得对于每个是OFL中的查询,Bf是扩充数据库。FL称为函数查询类OFL的语言。
下面分别介绍语言及查询类的NC-factor 归约定义及其相关引理。
定义8如果存在语言L1和L2的分解因子和,以及NC 函数α(∙)和β(∙),使得对于所有Σ*中的B 和Q,当且仅当〈α(B),β(Q)〉∈时,〈B,Q〉∈成立,则称语言L1可以NC-factor归约为语言L2。
引理3[1]对于所有语言L1、L2、L3:
定义9对于查询类O1、O2,如果LO1可以NC-factor 归约到LO2,那么O1可以NC-factor 归约到O2,记为其中LO1、LO2分别为对应于O1、O2的语言。
引理4[1]对于所有查询类O1、O2、O3:
语言LBDS={(G,(u,v))},存在分解因子使得BDS 可 以 转 换 为Π-tractable。其 中π1(G,(u,v))=G,π2(G,(u,v))=(u,v)。
引理5[1]在NC-factor归约下:
1)BDS是ΠΤP-complete;
2)查询类OBDS是ΠΤQ-complete。
根据以上定义及引理,下面给出定理3。
定理3函数查询语言FL在集合ΠΤP中,函数查询类OFL在查询类集合ΠΤQ中。
证明 由引理3~5 及定义9 可知,BDS 在ΠΤP中且OBDS在ΠΤQ中,若语言,则FL 在ΠΤP中,OFL在ΠΤQ中。下面证明。函数查询类OFL在查询类集合ΠΤQ中的证明类似。
考虑一个分解因子ϒFL=(π1,π2,ρ),对于所有FL 中的实例,定义并 且。因 为 BDS 是P-complete[16]且FL 在P 中,那么存在NC 函数h(∙)使得当且仅当在BDS中时,成立。然后存在NC函数α(∙)和β(∙),使得和分别对应于BDS 实例中无向图G 的顶点编号和G 中的节点对(u,v)。因此,对 于 所 有,当 且 仅 当时,成 立。其 中为BDS 的语言,ϒBDS为BDS 的一个分解因子。因此,
2.3 Π-tractable查询应用实例
下面将具体分析Π-tractable 查询类中连接查询的复杂度。
例4 某学校学生部分信息如表5 所示。数据库B 中的每个元组指定学生的姓名(NAME)、性别(GENDER)、班级(CLASS)以及成绩(SCORE)。假设查询Q0为查询2 班的学生姓名。求解该查询,则需要找出D0中所有满足条件“CLASS=2”的元组,即元组(WU,F,2,80)、(WANG,F,2,92)、(FANG,M,2,87)。
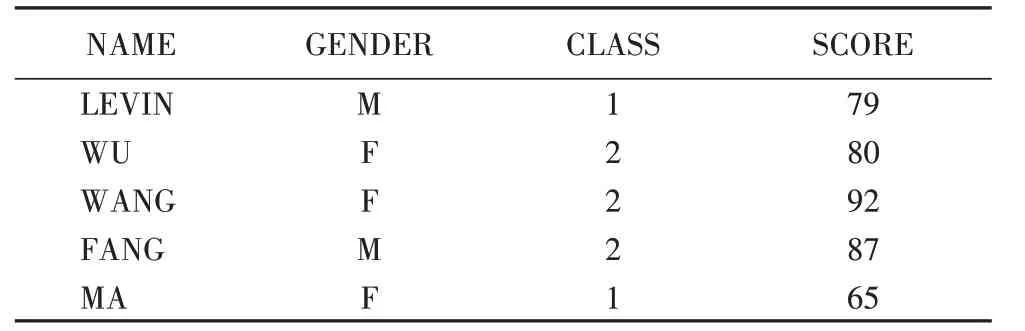
表5 学生表中的部分数据集D0Tab.5 Partial dataset D0 of student table
考虑有点-连接查询类O1,Q1∈O1,Q1是数据库B 上定义的查询,查询是否存在元组t 属于D,使得t[Att]的值为c。其中Att是B 中的属性,c是常量。利用索引查询结果,可以得出点-连接查询类O1在集合中。
对于点-连接查询,首先,在离线的一次性预处理步骤中,可以为数据库B 中的属性Att 列的值构建一个B+树,此时,利用这些索引,点-连接查询类O1中的所有D 上定义的查询Q1可以在O(log|D|)时间内求解。
3 结语
在大数据应用环境下函数查询成为主要操作,但目前还没有人研究函数查询解答复杂性问题。本文针对函数查询解答的复杂度问题,首先对经典的关系数据库进行扩充,给出了扩充数据库及函数查询的形式化定义;然后证明了函数查询解答问题的可计算性,使用一阶语言描述函数查询并且分析了其复杂度,并在此基础上分析了大数据上函数查询解答的复杂度。本文为大数据上函数查询解答问题的进一步研究奠定了理论基础,下一步工作将研究大数据上函数查询解答问题的优化策略。
