TiDB的多索引访问优化
2020-04-09彭煜玮
兰 海,韩 珂,申 砾,崔 秋,彭煜玮*
(1.武汉大学计算机学院,武汉610072;2.北京平凯星辰科技发展有限公司,北京100096)
0 引言
在大数据时代,各个公司需要更高的数据处理和分析能力,保证迅速地做出商业决策以及用户响应,数据处理引擎因而成为了各个公司的核心系统。随着数据持续增多、处理性能要求提升、处理场景和类型的多元化,对数据处理引擎提出各方面的挑战[1],因此,在传统关系数据库外,发展出了NoSQL[2-3]、NewSQL[4-6]、流式处理[7-9]等各类数据处理引擎。其中,TiDB[10]是受Google 的F1[11]以及Spanner[12]系统启发的一款开源分布式混合事务分析处理(Hybrid Transaction/Analytical Processing,HTAP)数据库,结合传统关系数据库管理系统(Relational Database Management System,RDMS)和NoSQL 的特性,兼容MySQL 语法,支持无限水平扩展,具有强一致性和高可用性。TiDB 现在逐渐被许多商业公司在业务系统中使用。
当前TiDB 的优化器对大部分查询请求都能生成性能极佳的物理计划,但仍有不足之处。下面通过举例来描述其中之一,同时也是本文中要解决的问题。假设有表1 所示的模式。
查询“SELECT*FROM t1 WHERE a1<1 OR a2>10”发送给TiDB,当前TiDB 优化器生成的物理计划为在t1 表上的全表扫描。假定t1 表上有100 万个元组,且满足条件“a1<1”和“a2>10”的元组各仅有一个。使用全表扫描需要访问100 万个元组。如果利用索引“i1”(后文以i1(a)表示名为i1 建立在列a 上的索引)获取满足条件“a1<1”的元组,利用索引“i2”获取满足条件“a2>10”的元组,然后将两个结果进行并操作,即得到结果。在这种执行方式中仅需要访问4 个元组,其中两个为数据元组,两个为索引元组(TiDB 中索引非树状结构,索引扫描没有中间节点访问的开销)。同样的环境下,后者性能提升明显。

表1 模式信息Tab.1 Mode information
从上述例子可知,当约束条件涉及多个索引属性时,首先利用单个索引获取结果,然后将结果进行并(条件为析取范式(Disjunctive Normal Form,DNF))或者交(条件为和取范式(Conjunctive Normal Form,CNF))操作以获取最终数据元组的方案优于用全表扫描或单个索引扫描的执行方式。
本文研究在TiDB 中利用多个索引提供更优的数据访问方案。将利用多个索引进行数据访问的路径称为MultiIndexPath,具体根据约束条件类型又分为MultiIndexOrPath以及MultiIndexAndPath。
在TiDB 上增加MultiIndexPath 的支持并不容易,存在如下难点:第一,如何将路径生成算法与TiDB 系统融合,以生成可能的MultiIndexPath。第二,索引选择。如果表上的一个约束条件有多个可使用索引,如何选择其中一个。第三,代价模型。由于TiDB 将计算与存储分离,两者通过远端程序调用(Remote Procedure Call,RPC)进行通信以及数据传输,增加了网络开销;同时,TiDB 运用大量并行执行技术,增加了代价模型的建模难度。
针对以上难点,本文首先基于TiDB 现有的优化器机制实现了MultiIndexPath 的生成算法。其次,当有多个索引可选时,采用启发式方法,进行索引选择,后文通过实验证明了该方法的有效性。第三,在充分考虑了网络以及并行等因素后,给出了MultiIndexPath 的代价模型。最后,在TiDB 的执行架构基础上,实现了物理计划的执行框架;并进一步结合TiDB架构特点,提出了一种Pipeline模式的执行算法。
1 相关研究
单机关系型数据库针对上述问题已经能生成利用多个索引的物理计划,但在实现方案上均有所不同。
MySQL 提供了IndexMerge[13]。当前MySQL 支持三种方式利用多个索引:Intersection(交)、Union(并)以及Sort_union(排序并)。交、并操作需要每个索引返回的表元组按照Rowid 排序,然后将从不同索引获取的表元组利用归并操作得到最终结果。
PostgreSQL 中用Bitmap Index Scan 以及Bitmap(位图)操作[14]来实现多个索引的使用:首先利用Bitmap Index Scan 构建每个索引要访问的物理页的位图,然后利用位图的交或者并确定最终要访问的页,最后访问页并从中取得满足条件的元组。
商业数据库DB2 中,首先利用单个索引获取满足索引条件的Rowid,然后再将这些不同的Rowid 集合执行交或者并操作获取最终Rowid 集合,最后将利用这些Rowid 进行数据获取。商业数据库Oracle 中有多个方式利用多个索引,如IndexJoin 以及Bitmap Merge。其中IndexJoin 将不同索引返回的结果根据Rowid 来进行Join,然后返回。Bitmap Merge 则利用Oracle 中的Bitmap 索引,通过Bitmap 的交或者并位操作来获取最终满足结果的Bitmap,再将Bitmap 变为Rowid,通过Rowid 获取最终的表数据。对商业数据SQL Sever 中or 的情况,首先通过多个IndexSeek 获取满足条件的索引元组,再利用Sort+Concatenation 或者MergeJoin+Aggregate。对于and 情况也是利用类似的方式。
2 TiDB的数据获取
TiDB 主要包括三个核心部件:TiDB Server、PD Server 和TiKV Server[15]。其中:TiDB Server 是计算层,负责SQL语句的执行;TiKV Server 是存储层,为TiDB 提供了分布式存储;PD Server 负责集群管理,包括集群相关的元数据存储、全局事务的管理以及TiKV集群的负载均衡。
以表1 中模式为例,如果查询为“SELECT*FROM t1 WHERE a1<2 AND a3=3”,该查询语句有两种可能的表上数据访问方式:全表扫描和索引扫描。
2.1 全表扫描
TiDB Server 通过PD 了解表上数据分布位置后,将全表扫描计划以及过滤条件“a1<2 AND a3=3”发给对应的TiKV。TiKV 对表t1上的元组逐一扫描并判断是否满足条件,将满足条件的元组返回给TiDB Server,最后由TiDB Sever 返回给用户。
2.2 索引扫描
TiDB 的索引扫描包含两种:Index-only 扫描以及一般索引扫描。Index-only 扫描适合于查询目标列被索引覆盖的场景。一般索引扫描先用索引获取满足条件的元组Rowid,然后利用Rowid去获取对应的表数据。
3 整体框架与代价模型
为能在TiDB 中利用多个索引协同完成查询,本文提出了一种新的访问路径:MultiIndexPath。
3.1 整体流程
TiDB 中构建逻辑计划时,将生成一个全表扫描路径以及所有可能的索引扫描路径。MultiIndexPath 的生成位于逻辑优化结束后、物理优化开始前。在此过程中,优化器会根据表上的条件以及索引信息生成可能的MultiIndexPath 加入备选路径中。进行物理优化时,对每个MultiIndexPath 备选路径根据4.2 小节中的代价模型估算代价,最终选中代价最低的物理计划(记为MultiIndexPlan)。
MultiIndexPlan 有两种可能的执行方案:1)利用索引扫描得到实际元组,对各个索引得到的实际元组执行并或者交操作;2)利用索引获取表上数据的Rowid,然后对Rowid 进行交并操作,再根据结果获取对应的表数据。
本文基于以下几点考虑选择了后一种方案:1)第一种方案需要获取表元组的Rowid 值执行交并,增加了一次对元组的解析操作;2)由于TiDB Server 利用RPC 从TiKV 获取实际元组,重复元组会耗费额外的网络带宽;3)TiDB 中索引扫描的流程是从TiKV 先获取Rowid,然后通过Rowid 取表数据,这种执行模式为第二种方案提供了实现基础。
MultiIndexPlan的执行如图1所示。其中涉及到三类协程(routine):
1)IndexWorker:每个索引对应一个,执行索引扫描,获取满足条件的Rowid;
2)AndOrWorker:对返回的Rowid 集合进行交并得到最终的Rowid集;
3)TableWorker:根据AndOrWorker得到的Rowid集,获取表元组。
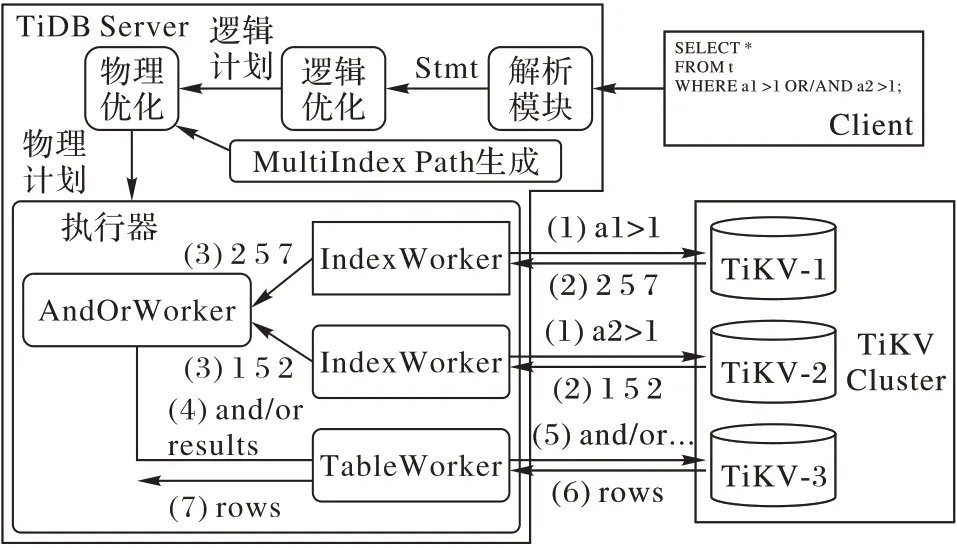
图1 MultiIndexPlan执行框架Fig.1 MultiIndexPlan execution framework
3.2 代价模型
MultiIndexPlan 的代价包括:索引扫描代价、Rowid 传输代价、表数据扫描代价、过滤条件计算代价、表元组传输代价以及执行交并操作的代价。代价模型中用到的符号说明见表2。
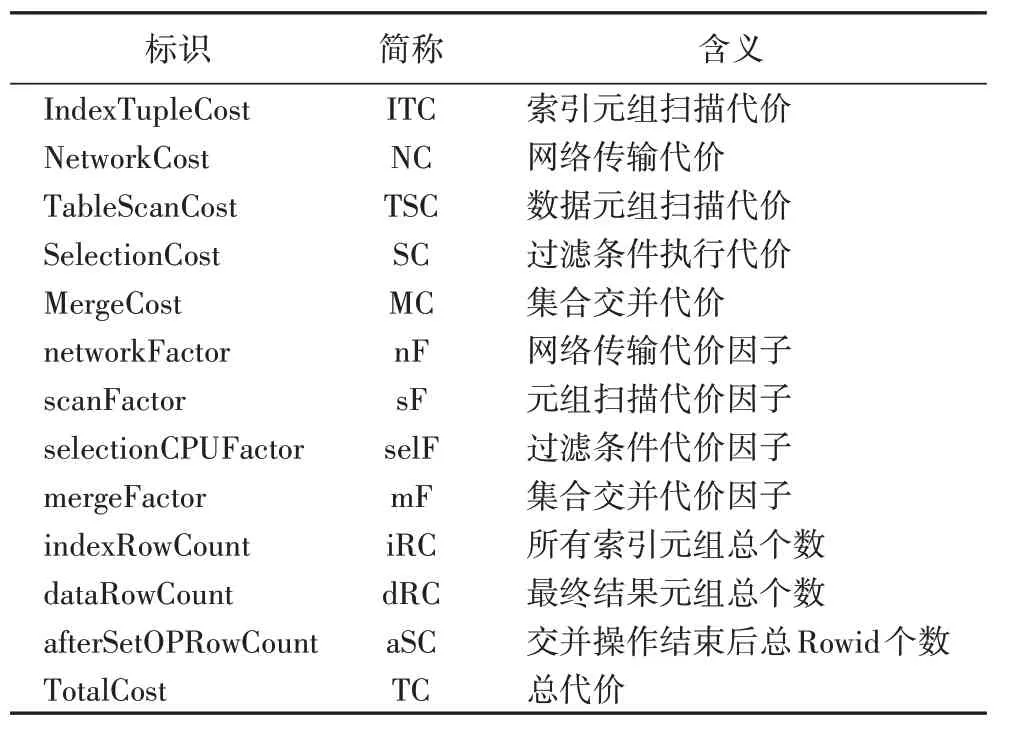
表2 代价模型的符号说明Tab.2 Symbol description of cost model
在3.1 节中描述的本文所采用的执行模型中,多个IndexWorker 并 行 进 行Rowid 扫 描,得 到 的Rowid 由AndOrWorker 处理,最初增加并行度能够提高性能,但过高的并行度会让AndOrWorker 成为瓶颈,无法带来性能提升。因此本文的代价模型中仍然按串行执行的方式计算代价:

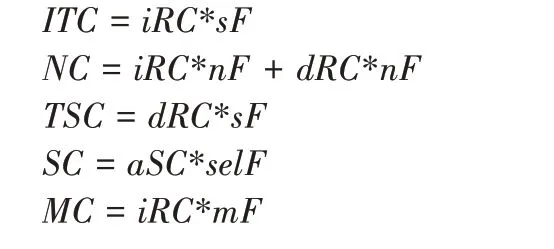
4 路径生成算法
路径生成分为两个阶段:第一阶段生成所有可能的MultiIndexOrPath;第 二 阶 段 生 成 所 有 可 能 的MultiIndexAndPath。
4.1 MultiIndexOrPath 生成
MultiIndexOrPath 生成算法如算法1 所示,输入需要访问的表上的索引集合Is 以及条件数组PCs,输出为所有可能的备选MultiIndexOrPath(记为CP)。
算法1 GenMultiIndexOrPaths。

算法依次处理条件数组的每一项,对每一个数组元素cond,首先检查该条件是否由OR 连接的表达式:如果不是则取数组的下一个条件进行处理(见算法第4)行);如果是OR连接表达式,则将其展开。例如“((a1>1 OR a2<10)OR a3=5)”,将展开为[a1>1,a2<10,a3=5]。如果a1>1、a2<10、a3=5都能够利用索引来进行数据获取,从它们三者就能够得到一个MultiIndexOrPath 备选路径。如果展开项中有一个不能利用索引,则该cond 不能生成MultiIndexOrPath(见算法12)~15)行)。
每个子表达式可能有多个可用索引,当前采用启发式规则选择其中一个索引:1)优先选择覆盖更多表达式中属性的索引;2)优先选择索引列数目最多的索引;3)如果通过上述两条规则都无法确定,则随机选择一个索引。当单个索引扫描路径生成后,生成最终的MultiIndexOrPath(见算法19)行)。
4.2 MultiIndexAndPath 生成
MultiIndexAndPath 生成算法如算法2 所示,输入为索引信息Is、条件数组PCs 以及已经被用于生成MultiIndexOrPath的条件数组UCs。生成MultiIndexAndPath至少要两个AND连接的条件,若条件数组中除去已用于MultiIndexOrPath 生成的条件少于两个,则无法生成MultiIndexAndPath,直接返回(算法1)、2)行)。
如果剩下的条件多于两个,首先将已经生成MultiIndexOrPath 的条件加入tableFilters 数组中,其次从条件数组中移除它们(算法4)、5)行)。针对新得到的条件数组的每一个条件表达式,生成所有可能的索引路径。如果无法生成索引路径,则将该条件加入tableFilters 数组中,然后进行下一个条件的处理。如果有多个索引路径生成,则基于启发式规则选择一个索引路径返回(算法6)~12)行)。当处理完所有条件后,得到的索引路径多于2 个则生成MultiIndexAndPath(算法13)~16)行)。
算法2 GenMultiIndexAndPaths。
5 执行优化
在MultiIndexPlan 执行过程中,需要通过索引获取Rowid并作交并操作,再根据结果Rowid 去获取实际的数据。在作交并操作时,可通过有序集的归并或者使用位图方式来实现。两个方法分别在许多数据库都被采用,具体见第2 章描述。获取所有Rowid 建立位图或者获取所有Rowid 后进行排序再归并的操作不能以Pipeline 模式执行。尽管上述两种执行方式将对表上元组的随机扫描变成顺序扫描,在以传统磁盘为介质的环境中可以大幅度提升性能;同时各自都保证了集合操作结果的正确性。TiDB 的数据存储层中的数据获取方式与第2章中描述的数据库有所不同。在TiDB 中,数据存储管理由TiKV 完成,在最底层由RocksDB 进行数据存储。RocksDB 对外提供的数据获取接口包括了prefixseek、get以及next方式。
如果数据连续性比较好,则第一个数据用prefixseek 获取,剩余的数据用next 获取是效率更高的方法。如果数据连续性不好,用一个prefixseek 加多个next 的方式性能会比用多个prefixseek 的方式更差。例如,要从1 000 000 行中返回100行,平均每行之间相隔10 000 个Rowid,如果第二个数据采用next 的方式来获取,则需要先执行9 999 个无用的next。如果第二个数据采用prefixseek 的方式获取,则只需要一个prefixseek 操作。两种方式的代价比约为9 999×1∶8(单次prefixseek 和next 的 耗 时 比 约 为8∶1)。此 外,采 用 一 个prefixseek 加多个next的执行方式还需要额外对所有Rowid 进行排序的代价,而且这是一个断流点。
综合以上分析以及TiDB 在Rowid 上的天然不连续性,本文认为一个prefixseek 加多个next 的数据获取方式不适合于MultiIndexPlan 的执行,所以,本文提出对任意序的Rowid均能以Pipeline模式进行表元组获取的执行方式。
对于MultiIndexOrPath,采用一个集合来记录当前已经发送给TableWorker 的Rowid,每当索引(无论哪个索引)返回一个新的Rowid,先检查其是否在集合中:如果存在(表示该Rowid 已经被访问过),则跳过该Rowid;如果不存在,将其加入集合中,并将该Rowid 发送给TableWorker 进行表上元组获取。
对于MultIndexAndPath,以图2 所示的例子说明算法原理。对每个索引增加一个集合,用于记录当前该索引已经返回,但是还没有进行表上数据获取的Rowid。在这个例子中记为set1 以及set2。假设上面的“ix1”和“ix2”索引交替返回Rowid。如果一个新的Rowid 从索引“ix1”返回,首先检查该Rowid 是否在set2 中,如果存在,从set2 中删除该Rowid,并发送给TableWorker;如果没有在set2中,将其加入到set1中。同理对“ix2”返回的索引也是类似的处理流程。用表3来描述上例的处理流程。
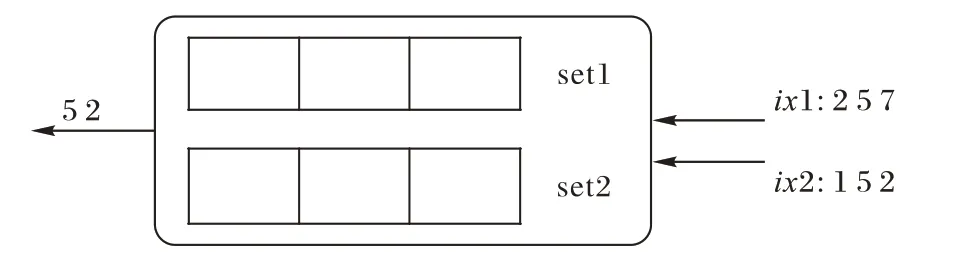
图2 MultiIndexAnd执行示例Fig.2 Example of MultiIndexAnd execution
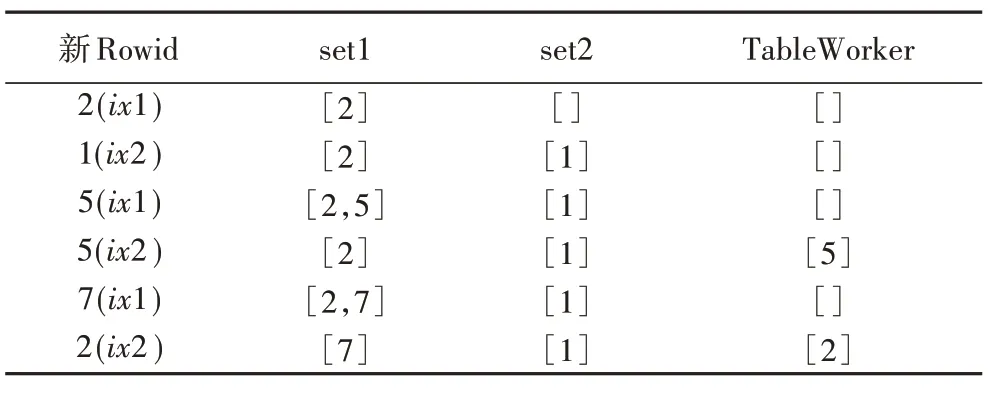
表3 MultiIndexPlan执行流程示例Tab.3 Example of MultiIndexPlan execution process
关于存储Rowid 集合的数据结构,本文首先采用Bitmap来实现。实际测试也表明该方案执行效率很高,但是TiDB 中的Rowid 为int64,所以可能会存储264-1 个位,这会使得Bitmap 的尺寸超过内存容量。本文最终选择普通的Hashmap方式实现,效率仍旧可以得到保证,对内存的占用也较低。
6 实验与结果分析
将本文方法在TiDB 3.0 版本中进行了实现,并通过多方面的实验验证了其效果,接下来就对实验的方法和结果进行介绍。
6.1 实验环境
采用4 台服务器组成集群,每台机器处理器为Intel i7-7700,内存16 GB,存储为256 GB 的SSD;服务器之间通过千兆网连接;其中3 台服务器用于TiKV 集群,另一台服务器上搭建PD和TiDB Server。
实验中用到的数据如表4所示,由2个人工生成的数据集构成。在数据集的每个列上均建有索引。查询语句模板如表5所示。

表4 数据集描述Tab.4 Description of datasets

表5 SQL语句模板Tab.5 Statement templates of SQL
6.2 结果及分析
本实验主要验证下面几个方面:1)添加多索引扫描方式后,针对本文所考虑的场景,查询性能相比未添加该方式是否有性能提升;2)验证在生成路径时的启发式规则的正确性。
6.2.1 性能提升
第一个实验修改$1与$2的值,使得模板DNF 语句的选择率从0.1%到80%。图3 展示了优化前、后TiDB 对DNF 语句的响应时间变化情况。在选择率低于60%的情况下,多索引访问的方式优于TiDB 原来的执行方式,并且在选择率低于8%时,有数量级的性能提升。原来TiDB 的全表扫描,执行时间与表上数据元组数量相关,因而随着表上数据量增多,这种性能提升会更加地明显。当选择率高于4%时,会看到优化后的响应时间会随着选择率成倍增长而对应地倍增,主要原因是随着选择率增加,结果元组增多,而网络开销与结果元组的数目成正比,因而网络开销增大,并占主要部分。
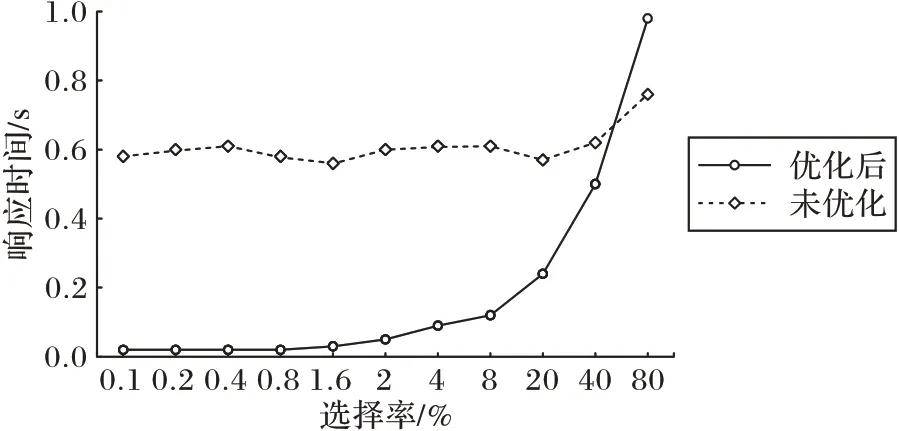
图3 DNF测试Fig.3 Test of DNF
第二个实验修改$1 和$2 的值,使得每个索引的选择率从1%到50%。图4 展示了优化前、后TiDB 对CNF 语句的响应时间变化情况。其中,CNF-1 语句的查询结果为空,CNF-2语句的查询结果非空。上述选择率是指单个索引上的选择率。实验结果表明,对于两种查询语句,多索引的访问方式都略优于原TiDB的扫描方式。
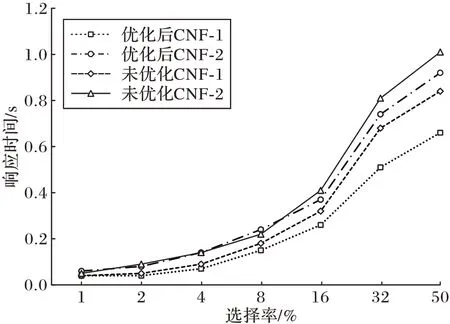
图4 CNF 测试Fig.4 Test of CNF
6.2.2 启发式索引选择方式
按4.2.1 节所述,适合一个条件的索引有多个时,将依照启发式规则选择索引,方便后面能够进行多个索引扫描的合并,减少并行。图5 以及图6 分别表示在DNF 条件以及CNF条件下,优化后不同的并行度对响应时间的影响。从图5 和图6 中看出,在误差允许范围内,随着并行度的增加,性能并没有得到相应的提升,其原因是随着并行度的增加,耗费了更多的物理资源,如处理器、网络带宽等,抵消了性能收益。
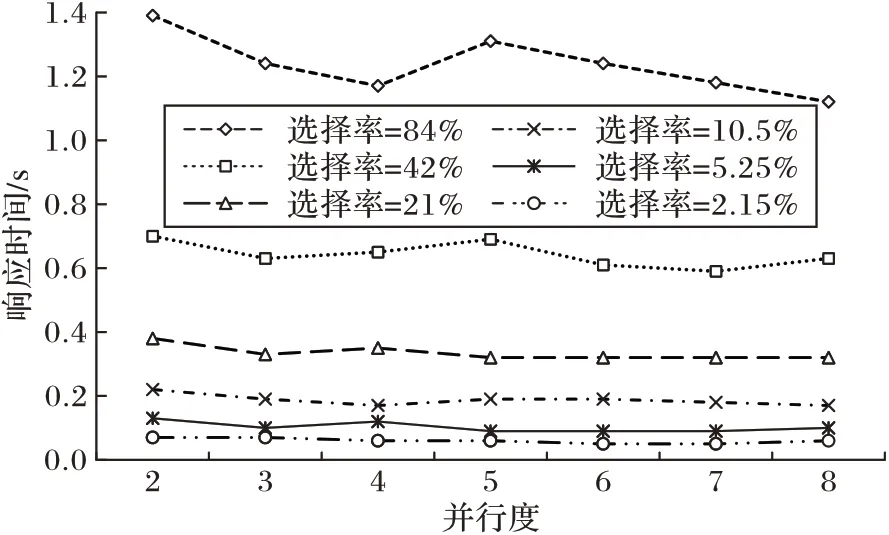
图5 DNF并行度测试Fig.5 Test of parallelism degree of DNF
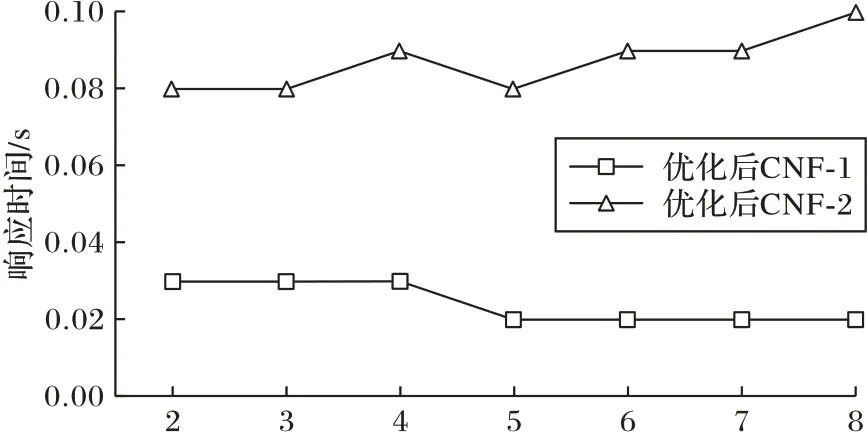
图6 CNF并行度测试Fig.6 Test of parallelism degree of CNF
7 结语
在约束条件含有多个索引属性时,TiDB 不能利用多个索引提供更好的物理计划。为了解决该问题,本文首先在TiDB中设计并实现了MultiIndexPath 的生成算法,并提出了一种Pipeline 模式的MultiIndexPlan 执行算法。实验结果表明在本文所考虑的场景中,利用多个索引的数据访问有明显的性能提升。
