卷积神经网络在ADAS中的应用
2020-04-07徐嘉伟谈至存温秀平
徐嘉伟 谈至存 温秀平
摘 要:针对原有卷积神经网络(Convolutional Neural Networks,CNN)算法耗时长,即时性差的缺点提出了一种应用在高级驾驶辅助系统(Advanced Driving Assistant System,ADAS)领域的网络,较诸原有的网络,其达到了较快的运行速度,适用于ADAS这样对FPS要求高的领域。同时使用YOLO算法得到目标在图像中的位置,从而得以实施避障、跟车、变道等后续操作。与Faster R-CNN和ResNet50结合的网络相比每秒帧数(Frames Per Second,FPS)提升89.36%。結果表明,该方法解决了原有网络检测耗时的缺点,具有一定的泛化能力。
关键词:卷积神经网络 YOLO ADAS 目标检测
中图分类号:P618 文献标识码:A 文章编号:1672-3791(2020)01(c)-0004-04
Abstract: A network in the field of Advanced Driving Assistant System (ADAS) has being put forward, aiming at the time-consuming of the original Convolutional Neural Networks algorithm and the poor realtime presents. Compared to the original network, it reach a faster speed, which is suitable for fields like ADAS to require higher quality of FPS. At the same time, YOLO algorithm is used to get the location of the target in the image, so as to implement subsequent operations such as obstacle avoidance, car following, lane change. Compared with the combined network of Faster R-CNN and ResNet 50, the Frames Per Second (FPS) increased by 89.36%. The result illustrates that this method solves the problem of time consuming and has the ability of generalization.
Key Words: Convolutional Neural Networks; YOLO; ADAS; Target Detection
美国早在20世纪80年代即已展开对ADAS领域的研究,并于1990年开发出Navlab-5[1],在2007年举办所举办的Urban Challenge[2]亦为ADAS领域里程碑式的大赛,该赛事完全模拟城市交通情况。欧洲于20世纪80年代所展开的普罗米修斯计划[3]同样汇聚了一批高校人才。国内的相关研究几乎与欧美国家同时开始,2013年之后我国相关产业发展迅速,包括广汽、比亚迪在内的一众汽车厂商均开始此类研究,甚至乐视、小米等科技公司亦在此列。由此可见,ADAS领域具有巨大的商业价值和研究价值。
1 卷积神经网络简介
卷积神经网络是一种前馈神经网络(CNN)[4],自2012年Alex Krizhevsky使用AlexNet[5]在ImageNet竞赛中一举夺魁之后,CNN便成为了计算机视觉的主要技术手段之一,与传统的神经网络(如BP神经网络、RBF神经网络)和分类算法(如SVM)相比,能更好、更快地提取目标特征,在识别准确率和运算速度方面均能满足ADAS的需求。目前已有许多成熟的深度学习网络,Zeiler等人提出ZFNet[6],专注于网络可视化,使CNN有了更强的理论依据,但对于精度与运行时间并无很大提高,Simonyan等人提出VGG[7],其在迁移学习上表现优秀,但一部分的全连接层(Fully Connected layer)严重影响了网络的运行速度,何凯明等人提出具有残差模块的ResNet[8],解决了一部分梯度消失的问题使更深的网络成为可能。但此类网络基于庞大的数据集往往注重分类结果的准确度而对网络的运行速度要求不高。该文所提出的网络舍弃了分组卷积、多维特征提取与合并等操作,更能适应ADAS这一领域。
2 CNN设计思路
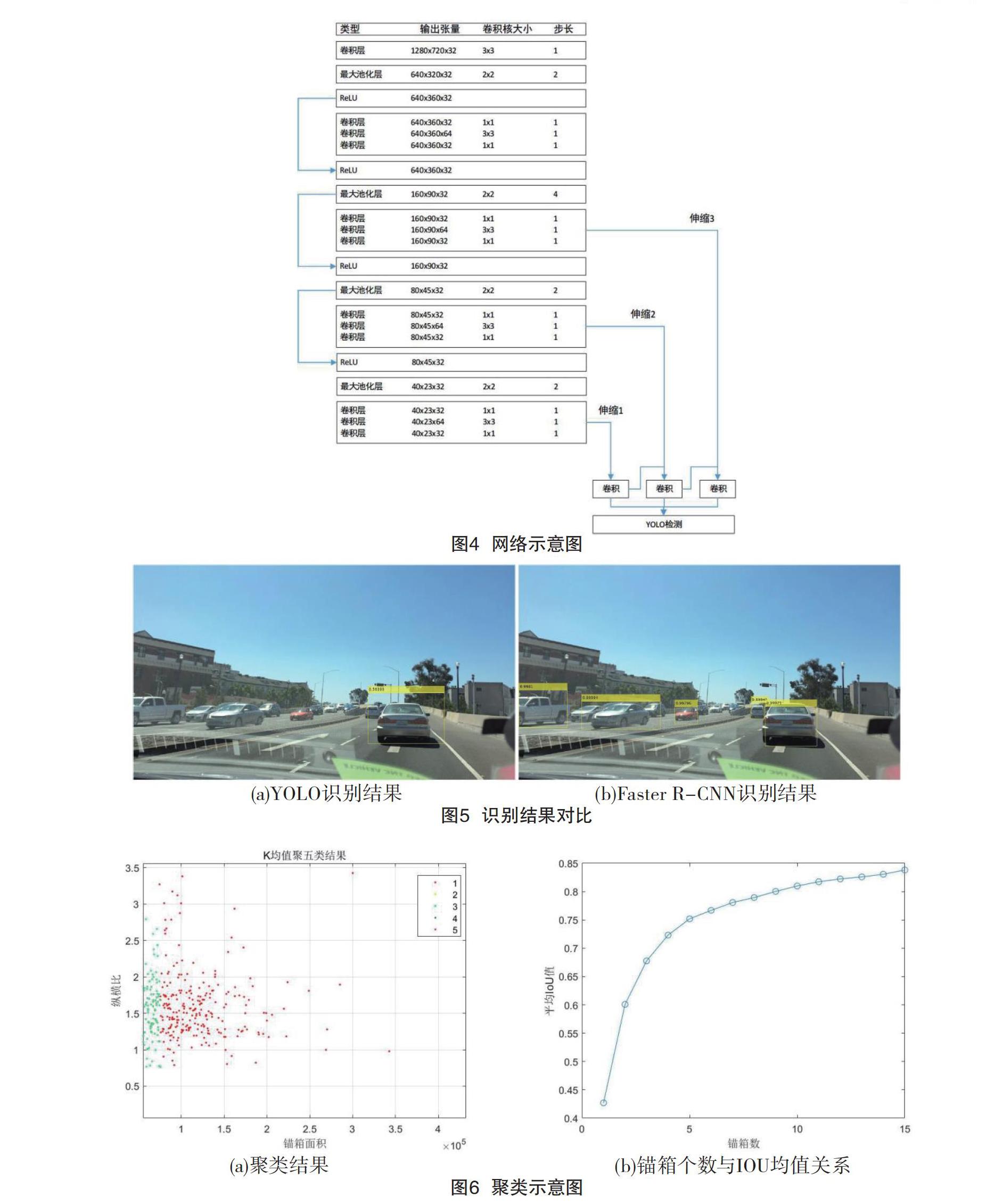
考虑到ADAS领域需要较大的图片尺寸以获得宽广的视野,该文选择BDD100K[9]的一个子集作为数据集。手工标注了汽车(不区分类型)、车道线、交通信号灯3类检测对象。CNN的输入层为720×1280的三通道rgb图片。
该文吸收了过去各类不同CNN结构的优点,在对结果准确率影响不大时,更侧重网络的运行速度,思路如下。
(1)采用了GoogleNet[10]提出的小卷积核串联代替大卷积核的思想,在不减少提取能力的同时减少计算量,同时使用1×1的卷积核进行升降维操作,提取更多的非线性特征。
(2)引入ResNet提出的残差网络来消弭网络潜在的梯度消失风险。
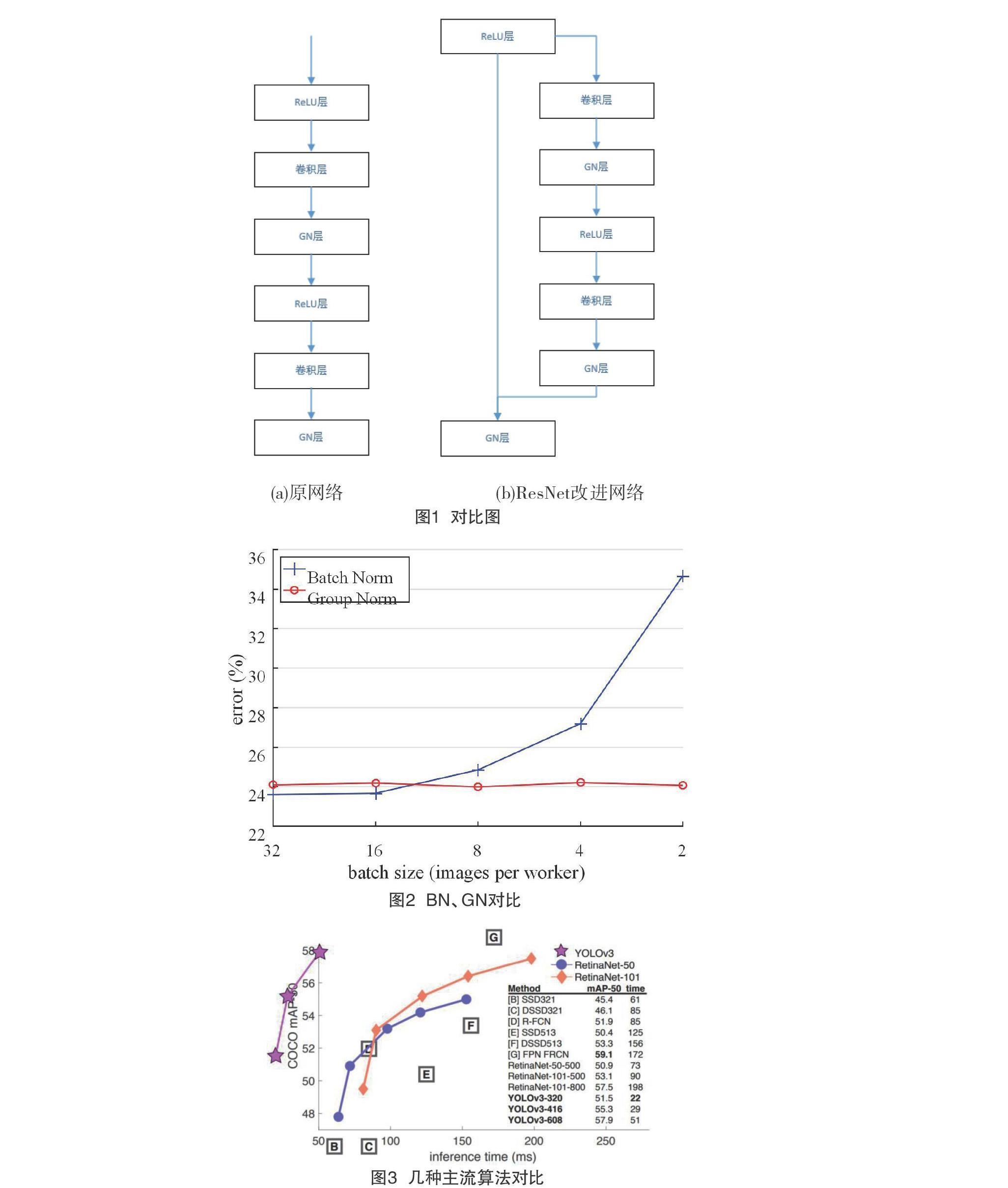
设图1(a)输入到输出的映射为f:x→f(x),则图1(b)所示映射为h:x→h(x)=f(x)+x。
实验证明,这样的“恒等快捷连接”有助于解决梯度消失问题。
(3)考虑到目标特征明显且易于辨识、目标种类很少,欠拟合可能性很低,该网络舍弃了多维度特征提取与拼接的方式以减少参数量,提升训练速度和运行速度。
(4)Batch Normalization[11]是一种在分类领域有效的归一化方式,其将每层神经元的输入都转化成标准正态分布以增大梯度从而加快了网络收敛速度,但在图像识别方面,受限于显存,mini-batch size往往很小,Batch Normalization效果不明显。该文采用了BN算法的变种——Group Normalization[12]。由图2中显示,在batch size较小时,GN错误率显著低于BN。
3 YOLO V3算法
YOLO V3[13]是一种一段式(one stage)目标检测方式,在工程中得到了广泛运用,官网显示其检测速度相较于Faste R-CNN[14]快1000倍左右,也比采用RPN函数的Faster R-CNN[15]快100倍左右。
DPM[16]算法计算图像的梯度,采用滑动窗口法和支持向量机(SVM)进行目标检测,计算速度慢,算子的选取依赖于过往经验,不适用于ADAS这样对即时性要求高的领域。在FasterR-CNN中,regionofinterest(roi)区域使用RPN网络生成,尽管其利用权值共享的思路与FastR-CNN共享一个CNN,速度比原先的searchselective快很多,但是额外的卷积层、池化层、分类器仍极大加重了计算量;iou阈值由人为选定,较为主观,容易出现将背景识别为目标的状况。
YOLO V3采用端到端的检测方式,以logistic回归算法进行锚箱预测,放弃使用softmax分类器以应对多标签场景,将多尺度的特征圖融合较诸V3提升了对小目标的检测能力。
4 对比实验
该文在GeForceGTX1060(@1.5GHZ)环境下分别训练FasterR-CNN与ResNet50结合的神经网络和该文提出的CNN与YOLOV 3结合的神经网络,并在不同的从训练时间、网络运行时间、预测准确率3个方面比较优劣性。
从训练时间看,该文网络相较于ResNet50较浅,导致训练时间变短,YOLO的训练过程为一段式,而FasterR-CNN的训练过程需经历RPN函数训练、利用RPN函数训练FastR-CNN、通过权值共享重新训练RPN函数、用更新过后的RPN函数训练FastR-CNN网络4个步骤,这两个因素导致YOLO V3的训练时间远低于FasterR-CNN的耗时,具体见表1。
从识别结果看,YOLO仍有对小目标识别不精准的缺陷,但在ADAS领域,大目标具有更高的优先级,对FPS的要求也极高。在实际应用中,可根据需要选择不同的锚箱数量,在降低识别效率的同时提高识别准确率具体,见图5。
如图6(a)显示,在平方欧氏距离下,该文锚箱大致分为两类,考虑到系统鲁棒性,该文选择5种大小的锚箱进行识别,图6(b)展示了锚箱个数与IOU均值之间的关系,当锚箱数大于5时,IOU增长变缓,该文选择5类锚箱具有一定合理性。
5 结语
该文所提出的网络能有较高的FPS,同时精度下降不多,能满足ADAS的相关需求。受限于硬件,该文网络的泛化能力不足,随着算力发展,可考虑使用更大的数据集或采用增加网络通道数与层数的方式获得更好的泛化能力与精确度。
参考文献
[1] Thorpe C, Herbert M, Kanade T,et al.Toward autonomous driving:the cmu navlab.ii.architecture and systems[J].IEEE Expert,1991,6(4):44-52.
[2] Buehler M,Iagnemma K,Singh S.The DARPA urban challenge: Autonomous vehicles in city traffic[EB/OL].https://www.doi.org//0.1007/978-3-642-03991-/?nosf=y.
[3] Povel R.Prometheus-programme for a european traffic with highest efficiency and unprecedented safety - definitionsphase schlussbericht[Z].1987.
[4] Goodfellow I,Bengio Y,Courville A.Deep learning[M].MIT Press,2016.
[5] KRIZHEVSKY A, SUTSKEVER I, HINTON G. Imagenet classification with deep convolutional neural networks[A].International Conference on Neural Information Processing Systems.[C].2012.
[6] Zeiler MD,Fergus R.Visualizing and understanding convolutional networks[A].Computer Vision-ECCV 2014:13th European Conference[C].2014.
[7] Simonyan K,Zisserman A.Very deep convolutional networks for large-scale image recognition[EB/OL].https://www.jianshu.com/p/qd6082068f53.
[8] He K,Zhang X,Ren S,et al.Deep residual learning for image recognition[A].2016 IEEE Conference on Computer Vision and Pattern Recognition[C].2016.
[9] Yu F,Xian W,Chen Y,et al.Bdd100k:A diverse driving video database with scalable annotation tooling[EB/OL].https://www.arxiv.org/abs/1805.0468.
[10] Szegedy C,Liu W,Jia Y,et al.Going deeper with convolutions[A]. 2015 IEEE Confernce on Computer Vision and Pattern Recognition (CVPR)[C].2015.
[11] Ioffe S,Szegedy C.Batch normalization:Accelerating deep network training by reducing internal covariate shift[EB/OL].https://www.arxiv.org/abs/1502.03167.
[12] Yuxin Wu,Kaiming He. Group normalization[EB/OL]. https://www.arxiv.org/abs/1803.08494.
[13] Redmon J,Farhadi A.Yolov3:An incremental improvement[EB/OL].https://arxiv.org/abs/1804.02767.
[14] Girshick R. Fast R-CNN[J].https://www.arxiv.org/abs/1504.08083.
[15] Ren S,He K,Girshick R, et al. Faster r-cnn:towards real-time object detection with region proposal networks[J].IEEE Trans Pattern Anal Mach Intell,2017,39(6):1137-1149.
[16] Pedro,F Felzenszwalb,Ross B Girshick,David Mc Allester,er al. Object detection with discriminatively trained part-based models[J].IEEE Tran Sactions on Pattern Analysis and Machine Intelligence,2010,32(9):1627-1645.
