基于多视图循环神经网络的三维物体识别
2020-04-06李文生张文强
董 帅,李文生,张文强,邹 昆
(电子科技大学中山学院 广东 中山 528406)
近5 年,基于深度学习的计算机视觉技术[1]飞速发展,已广泛应用于智能安防和无人驾驶等多个领域。在大规模目标数据集中,针对具体的识别或检测任务,深层卷积网络可以通过端对端的方式自适应地学习如何从输入数据中提取和抽象特征,以及如何基于该特征进行决策。深层卷积网络既可作为图像特征提取和分类操作的统一体,又可以只作为特征提取网络供实例检索任务使用[2-3]。目前大多数基于深度学习的图像分类网络和目标检测框架都是针对二维图像提出的,但随着深度学习逐步应用到机器人导航和无人超市等领域,三维物体的识别技术也逐渐得到了研究人员的广泛关注。与二维图像相比,三维物体识别的难点在于,同一物体的不同侧面可能存在较大差异,从不同角度观察会呈现出不同的形态,而不同物体在某个侧面上的差异可能很小,甚至呈现出相同的形态。这使得直接使用单视图(即二维图像或投影)分类网络的识别效果较差。
在深度学习受到广泛关注之前,有许多学者采用了SURF 等传统几何方法[4-7]对三维物体的识别技术进行了探索,取得了一定的成果,但这类方法的鲁棒性和泛化能力较差。近几年,研究者逐渐将深度学习推广到三维物体识别领域,提出了多种方法。这些方法可以大致分为两类:基于三维数据表示的方法和基于多视图表示的方法。文献[8]提出了基于体素网格和三维卷积的VoxelNet,该网络是二维平面卷积到三维空间卷积的直接推广,由于计算量过大,输入模型的体素分辨率一般较低,进而导致识别精度也较低。文献[9-10]提出了针对三维点云的PointNet 及后续的一系列方法,这些方法基于点云的无序性提出多种非欧卷积网络[11-12],具有较大的影响力,但同样存在计算量大和训练困难的问题。文献[13]提出了基于SSD 的6 维位姿估计目标检测框架,开创性地将位姿估计和目标检测二者结合,具有启发性。文献[14]提出了基于深度霍夫投票的3D 目标检测框架VoteNet,该框架主要用于场景的识别,未关注单个实例的分类和检索问题。文献[15]提出的基于多视图的卷积神经网络(MVCNN),与基于三维数据的方法并行。MVCNN 在分类和检索任务上的表现均优于基于三维数据的识别方法。在文献[16]中,对MVCNN、PointNet++和VoxelNet 等多种方法进行对比,并指出多视图方法的优异表现主要得益于庞大的二维图像数据集。但MVCNN 存在两个方面的不足:1)依赖于精确的3D 模型,且采用了固定视角的视图,这并不符合真实的应用场景,导致算法泛化能力不足;2) 采用了最大值池化操作来对多视图进行融合,融合后的特征会损失大量信息。
针对MVCNN 存在的问题,本文提出了一种基于MVRNN 的三维物体识别方法。首先,设计了一个包含特征辨识度指标的目标函数用于训练网络,能够得到辨识度更高的物体单视图特征和融合特征;其次,使用循环神经网络(recurrent neural network, RNN)对多个视图特征进行融合,得到一个更加紧凑且包含更丰富信息的融合特征作为物体的注册特征;最后,利用单视图特征对注册特征进行检索。与MVCNN 相比,MVRNN 存在以下优点:1)不依赖于3D 模型,在实际应用中,只需要采集2D 图片提取特征并进行融合;2)对视图的视角和数量没有要求,对不同视图的特征信息利用更充分;3)利用循环结构网络进行特征融合,兼具紧凑性和完备性。
1 问题描述
1.1 多视图数据集
PASCAL3D+和Tsukuba 等公开三维数据集主要针对三维模型的分类,并不适用于多视图的识别场景。文献[15]基于ModelNet 建立了多视图的数据集,但只采用了图1 所示的12 个固定位置和视角,并不完全符合实际应用的场景。为了充分展现MVRNN 的优点,本文自建数据集MV3D (multiview 3D)用于对比试验。
MV3D 采用Unity 软件制作,将三维模导入软件,并在Camera 的视场中随机平移和旋转模型,得到二维视图。该数据集共有95 个三维物体模型,每个物体包括100 个二维视图。物体模型较ModelNet 更加精致,纹理也更加丰富。该数据集中存在一些在不同视角角度下外观差异较大的物体,以及一些属于不同类别但在某些视角下形态十分相近的物体。图2 展示了该数据集中的部分样本。
1.2 MVRNN 三维物体识别框架

在MVCNN 中, F(·)采用了简单的最大值池化;此外, F(·)还可采用均值池化和直接拼接等实现方法。本文利用RNN 代替最大值池化实现特征融合,此即为MVRNN 的由来。
由于多个模块同时训练难度较大,整个框架采用分步训练的策略:1) 训练分类分支 E(·)和 C1(·),固化 E(·)并提取单视图特征;2)训练分类分支F(·)和 C2(·), 固化 F(·)计算融合特征;3)训练二分类网络 M(·)。 C1(·)和 C2(·)只 用于 E(·)和 F(·)的训练,并不直接参与预测。
2 MVRNN 具体实现方案
2.1 特征提取网络
与MVCNN 一样,在MVRNN 中 E(·)和 C1(·)直接采用了ResNet-18[17]的结构,并加载了预训练的参数进行微调。输入图片尺寸为224*224,输出特征长度为512。训练时,采用的损失函数为:

2.2 循环多视图特征融合网络
特征融合网络的作用是对多个视图特征进行融合,得到一个能够完整描述物体形状和纹理信息的特征。本节借鉴视频分析方法,采用RNN 来融合特征,其结构如图4 所示。物体的多个视图在时间上无相关性,但在空间上是关联的,因此能够借助RNN 的记忆能力来融合特征。
F(·)网络采用图5 所示的结构,每个循环体中包括线性全连接层(full connection, FC)和双曲正切单元Tanh,最后的分类层 C2(·)包括了线性全连接FC 和Softmax 操作,全连接层神经元数量均为1 024,融合后特征长度为512。 F(·)循环体的数量可以随输入视图的数量变化,即输入视图数量不固定。 F(·)的训练同样采用了式(1)所示的损失函数,λ 取0.01,µ取0。
2.3 检索匹配网络
相似度匹配模块 M(·)是一个二分类模型,使用了三层的全连接神经网络结构,输入由单视图特征和融合后特征拼接而成,隐藏层由线性全连接、Batch Normalization 和ReLU 组成,输出层由线性全连接FC 和Softmax 组成,隐藏层神经元数量均为1 024,网络结构如图6 所示。 F(·)的训练同样采用了式(1)所示的损失函数,其中,λ取0.000 5,µ取0。
3 特征融合方法对比
特征融合是传统机器学习中比较常用的手段,一般需要根据先验知识来提取不同类别的特征信息,并进行协同决策。特征融合在深度学习领域也得到广泛应用,比如ResNet 的残差模块和DenseNet的跨层连接,都对不同层的特征进行了融合。常见的特征融合方法包括直接拼接(concatenating)、堆叠(stacking)、相加(adding)、最大值池化(max-pooling)和均值池化(average-pooling)等。其中,堆叠可以看做是直接拼接的特例,相加则等效于均值池化。衡量特征融合方法的主要准则有两个:1) 原始特征的信息是否会损失,即信息的完备性;2) 融合后特征是否便于后续计算,即特征的紧凑性,一般指融合特征的长度。此外,传统机器学习的特征融合还比较注重被融合特征之间的差异性,差异越大则信息量越多,但该准则对于本文所解决的问题并不适用。
对于三维物体的多视图特征融合任务而言,直接拼接能够保证信息的完备性,但融合后特征长度较大,会导致网络规模较大,且训练难度增大;最大值池化和均值池化得到的特征比较紧凑,但会损失部分信息;而RNN 则兼具完备性和紧凑性。几种方法得到的融合特征长度比较直观,直接拼接方法的完备性也是毋庸讳言。
为了对比两种池化方法和RNN 的完备性,本节设计了一个比较极端的二维特征融合任务,对比结果如图7~图10 所示。图7 包含10 个物体的不同视图特征,每条曲线表示一个物体,曲线上的点表示不同视图的特征。特征空间可以分为左上、左下、右上和右下4 个子空间,子空间内的物体特征存在较大的相似性。从每条曲线随机抽取5 个点进行融合,重复得到融合特征的分布。最大值池化的结果如图8 所示,其中,左下两个物体特征出现了重叠,右上的类似。均值池化的结果则是左上和右下的物体特征出现重叠,具体如图9 所示。RNN采用了单隐含层10 神经元的全连接网络,其融合结果如图10 所示。RNN 引入了新的网络层将特征映射至新的空间,10 个物体被有效区分。
4 实验结果与分析
为了说明MVRNN 在融合多视图特征上的优越性,本节在ModelNet 数据集[15]和自建数据集MV3D 上进行了多组对比分析。
从ModelNet 数据集随机抽取4 000 个物体,每个物体分别抽取6 张和12 张视图,按照6:1:3 的比例划分训练集、验证集和测试集。MVCNN 和MVRNN 在融合特征分类任务和实例检索任务上的性能如表1 所示。从表1 可以看出,相较于MVCNN,MVRNN 在分类任务上有一定的提升,且融合的视图越多,二者的准确率都有提升;在检索任务上,MVRNN 明显优于MVCNN;需要注意的是,随着视图的增多,MVCNN 检索的准确率会下降,这是由于ModelNet 数据集中模型本身都比较简单粗糙,缺乏具有辨识度的纹理,最大值池化操作更容易丢失信息,图片越多,更有可能导致部分关键信息的丢失。

表1 MVCNN 和MVRNN 准确率对比(ModelNet)
由于ModelNet 数据集具有固定视角的限制,无法充分验证MVRNN 的性能。因此,本文利用Unity 3D 制作了MV3D 数据集,其中训练集包含65 个物体,测试集包含30 个物体,每个物体包含100 张视图。数据集的设定如下:
1)训练特征提取网络时,训练集中所有的视图(6 500 张)全部参与训练。
2)训练特征融合网络时,从每个物体随机抽取6 个单视图特征构建六元组作为网络输入;训练集包含65 个物体,每个物体包含2 000 个六元组;测试集由同样的65 个物体生成,每个物体包含500 个六元组。即训练样本数量为130 000,测试样本数量为32 500。
3)训练匹配网络时,从物体A 随机抽取7 个单视图特征A1~A7,从物体B 抽取1 个单视图特征B1,构建正负两个七元组样本作为网络输入,其中A1~A6 输入特征融合网络生成融合特征,A7 为检索特征正样本,B1 为检索特征负样本;训练集包含65 个物体,每个物体包含2 000 个七元组;测试集包含30 个物体,每个物体包含2 000个七元组。即训练样本数量为130 000,测试样本数量为60 000。
在MV3D 数据集上进行7 种方法的对比测试,结果如表2 所示。实验的设定如下:1)基于单个视图特征进行分类和检索;2)基于多个单视图特征进行单独匹配,并取置信度最高的视图作为最终匹配结果;3) MVCNN,即 F(·)为最大值池化;4) F(·)为 直 接 拼 接;5) F(·)为 均 值 池 化;6)MVRNN without Lrect; 7) MVRNN with Lrect。各组实验涉及到的卷积网络和相似度匹配模型均采用同样的结构,且所有模型均使用相同的训练方法和超参,batch_size 为50,采用Nesterov[18]梯度加速算法,初始学习率为10−2,稳定后变为10−3和10−4,动量为0.9,dropout 概率[19]为0.3。 top 1_dst定义为在检索正确的结果中,1.0 与最大相似度之间的平均距离,即则表示在检索正确的结果中,最大与次大相似度之间的平均距离,即可以衡量特征辨识度的高低, top 2_dst越大,同时top1_dst越小,则该值越大,也说明特征的辨识度越高。
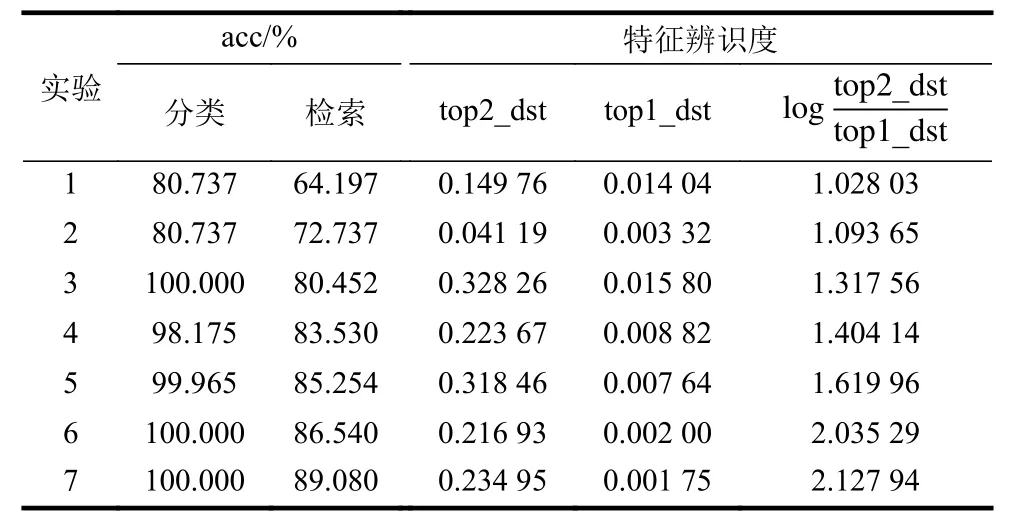
表2 MVRNN 性能对比(MV3D)
从表2 来看,MVRNN 准确率最高,即使损失函数不考虑 Lrect项,结果依然较其他方法好。最大值池化、均值池化和直接拼接3 种方式准确率相近,为第2 梯队;只使用单视图的两种方法效果最差。
在目标函数中增加 Lrect项后,MVRNN 在单视图分类和融合特征检索的准确率上都得到了明显提升,具体结果如表3 所示。结合表2 的特征辨识度指标来看, Lrect能够提升特征辨识度,进而提升分类和检索的准确率。

表3 Lrect 效果对比
为了进一步对比MVRNN 和MVCNN 的性能,本节对表2 中的实验3 和实验7 进行扩展,得到了视图数量分别为2,4,6,8,10 时,训练集物体数量为10,20,30,40,50,65 时的检索准确率,具体结果如图11 所示。从图中可以看出:1)随着训练集物体数量的增加,检索准确率也不断增加;2)在物体数量超过30 后,准确率整体的提升幅度较小,物体数量为30 时对应的训练样本数量为60 000;3)MVRNN 整体准确率较MVCNN 高约8%。
本文还基于MVRNN 开发了一个简单的商品识别系统。该系统包括商品注册和商品识别两个模式,具体应用如图12 和图13 所示。在注册阶段,采集商品实例的不同视图,以提取视图特征进行融合,并对融合特征进行注册;在识别阶段,则根据商品单视图特征对融合特征进行检索。在100 种常见饮料食品类商品上进行测试,注册图片不超过9 张,即可完成大部分商品实例的检索,准确率约为90%。
5 结 束 语
针对三维物体的分类和检索问题,本文对MVCNN 进行改进,提出了MVRNN。通过在损失函数中引入特征辨识度指标,能够有效提升分类和检索的准确率;利用RNN 代替最大值池化操作,使得融合特征具有信息完备性。在ModelNet 数据集和MV3D 数据集上,MVRNN 的表现较MVCNN有了明显提升。在未来的研究中,拟制作大规模商品数据集以开展MVRNN 的应用研究;此外,将MVRNN 与SSD 等目标检测框架结合来估计物体的六维位姿也是一个比较有前景的方向。
