基于大数据分析的交通拥堵预测技术
2020-04-01林立春刘华洪东
林立春 刘华 洪东


摘要:文章利用大数据分析,挖掘潜在规则对交通拥堵进行预测,为提高预测的准确性并能适应常发性拥堵和偶发性拥堵,运用了多模型融合技术,加以改进的两级加权优化ELM和自适应权重,同时引入了拥堵传导规则,进一步提升拥堵预测的精确性和关联性。当预测或已发生交通拥堵时,在拥堵诱导上采取局部路网总成本最优化,也可为相应管理部门实现全局路网总成本最优化,以提高道路整体通行能力。仿真实验结果表明,多模型融合技术能有效提高并能在较长时限下维持拥堵预警准确度,可为未来规划提供决策辅助,更为建设智慧交通城市助力。
关键词:大数据;预测;交通拥堵;加权优化
0 引言
近年来,国家倡导发展“低碳社会”和“节约型社会”。而交通拥堵问题影响居民生活质量、加重大气污染、降低城市运行效率,已经成为阻碍城市发展的“城市病”。在当今“互联网+”和大数据发展的时代,利用大数据分析可以科学地预测路网的交通拥堵程度,不仅可为市民出行合理规划路线,还可为交通管理部门提出合理疏导方案,提升次干道和支路的利用率,亦可为路网规划部门给出合理的未来规划建議,为建设智慧交通城市助力。
建设智慧交通城市应以人文本,发挥主人翁意识,让人人都是交通参与者,人人都是交通管理者。应打造智慧交通全方位数据平台,建立基于“互联网+”、大数据的“众治”理念,形成多边、民主、透明的交通管理生态环境,完善智慧交通协同服务体系。
1 架构的提出
从成因上来划分,交通拥堵一般可归纳为常发性交通拥堵和偶发性交通拥堵。常发性交通拥堵具有一定规律可循,在大数据分析上具有明显特征。偶发性交通拥堵随机性大,规律不甚明显。本文的侧重点在于对交通拥堵的预测,创新点有:(1)对综合常发性交通拥堵和偶发性交通拥堵通过自适应权重进行预测,并提出两级加权来优化ELM;(2)在模糊C均值聚类上改进,实现可变系数加权聚类优化方法;(3)应用自学习模型和拥堵传导模型,进一步提高拥堵的预测准确性;(4)利用路网总成本的局部最优实现拥堵诱导,以提高城市的整体通行能力。
1.1 常发性交通拥堵
分析历史大数据发现,同一路段的交通流虽然是变化的,但具有一定的周期性规律。例如图1是南宁市厢竹大道某路段在2019年4月18~26日的拥堵指数变化规律呈现图。图的横轴为时间,将纵轴分为5级的拥堵指数。从图中可以看出工作日期间天与天之间具有很强的自相似性。类似的,周末与周末之间也具有较强的自相似性。可以看出从较长统计周期的大数据中挖掘出自相似性上反映出来的变化规律,对交通进行相关指导,具有相当重要的现实意义。
1.2 偶发性交通拥堵
除了分析历史大数据,根据交管部门多年的实测数据表明,诸如交通事故、交通违法、道路施工、大型活动、极端天气和其他特殊状况等因素是导致交通拥堵的直接诱因,本文因其是动态发生的,称其为动态影响因素。以长沙市为例,百度大数据统计动态影响交通拥堵的因素占比如表1所示。将这些因素充分考虑进来,在历史大数据挖掘的基础上,结合实时的交通数据(交通流量、平均速度、浮动车数据等),可以提高各类拥堵情况的预测精度。
1.3 提出架构
基于大数据分析的交通拥堵预警平台架构简图如图2所示。架构的核心是构建规则库,该规则库不仅含有常发性交通拥堵的规则,也含有偶发性交通拥堵的规则,其优劣直接关系到预测精度。在给出未来时刻的预测后,通过时间序列的实时数据验证进行自学习,以期收敛和准确。
2 关键技术
2.1 可变系数加权聚类优化
K均值聚类(K-means)是基础的聚类算法,进行固定数目的样本划分,是一种硬性划分。模糊C均值聚类(FCM)相对来说是一种柔性的划分方法,其划分结果是各个样本的隶属程度,而不是属于某类,是K-means的改进。
基于路段本质特征有车道数量、人行横道数量、红绿灯数量等都是不同的,加之工作日、周末和节假日的数据特征也有很大差异,显然需要对不同维度上的特征加以不同的侧重。故此提出了一种可变系数加权聚类优化方法。
最后一条约束表示多条路径都流经弧(边)aKL,则流经重叠弧aKL的交通量总和∑XKL不超过其通行能力。该模型同样适用于计算整体路网总成本最优,为相应管理部门疏导交通或对未来交通规划辅助决策。
2.4 拥堵传导规则的挖掘
如果路段R1在时刻t0出现交通拥堵,R1的相邻路段(临边)R2在σt个单位时间之后也出现了交通拥堵,这样的时间序列关联规则即为拥堵传导规则。类似于自适应学习算法,σt在阈值T1、T2之内进行自学习收敛,以期在实际应用中给出高时效性的拥堵预测。T1、T2的选取由经验获得,本平台设为可配置的初始值[5,30]。此外,为降低时空复杂度,本平台拥堵传导规则仅计算临边,但整个路网的连通性已能反映出间接拥堵传导。
3 仿真实验
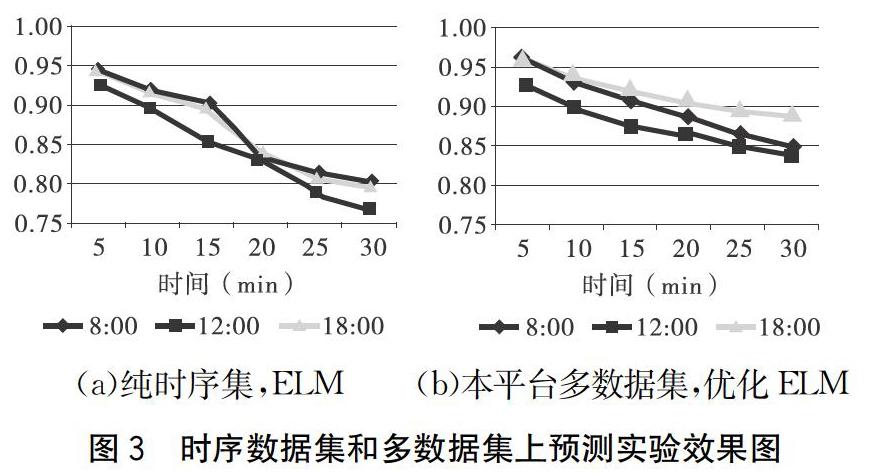
实验在MATLAB平台上进行,软件版本为MATLAB 2014 b(64位)。实验机器配置为Intel Core i7-4770处理器,内存为16 G。样本数据采用广西交通运输云数据中心部分样本数据,模拟环境为南宁市中心城区多条易拥堵路线,在8:00、12:00和18:00 3个早中晚上下班高峰时段进行30 min内的连续预测和验证。仿真结果如图3所示,横轴为预测时长,纵轴为预测准确率。在纯时序大数据集下,随着预测时刻越远,预测准确度下降越大。在本平台综合多种数据集及相应技术的情况下,随着预测时刻的延长,预测准确度趋于平滑。
4 结语
本文在集成学习思想的基础上,融合常发性和偶发性交通拥堵,提出拥堵预警平台框架,引入了可变系数加权聚类优化方法,运用多模型融合技术、两级加权优化ELM和自适应权重模型对交通拥堵的趋势变化、周期性变化和随机性变化进行预测。同时引入了拥堵传导规则,进一步提升拥堵预测的精确性和关联性。在拥堵诱导上采取局部最优化,以提高道路的整体通行能力。实验结果表明,平台的预警精确度较高,均在80%以上,且随着预测时间的延长,预测精度在下降过程中趋于平滑。
拥堵预警的作用和意义重大,除了引言提到的作用,还可为交通运输行业(例如物流)以及其他行业提供有价值的规律,优化其运行方案,为经济发展助力。对于未来的展望,拥堵预警亦可服务于面向车路协同以及无人驾驶的应用上。此外借助于仿真,还可以对未来的路网改造、交通规划方案等提供决策辅助。
这一技术存在的问题有历史原因以及受信息安全和保密管理等相关规定的影响。公安网络历来与互联网等网络都是物理隔离的,公安交通管理部门掌握的数据和资料对外共享较困难,一些数据交流常采用定期开放的方式,实时性不强。建议将系统数据做部分映射,将不涉及隐私和信息安全且又有必要公开的交通数据进行实时共享。对访问的各类用户可以进行资格审查并签署协议,投入商用要适当收取费用。同时,智能交通管理系统所需的外单位数据要尽早形成信息共享,尚需有政策层面的配套保障机制,推动交通大数据技术的发展与应用。
总之,完善智慧交通管理机制体制,打造智慧交通全方位数据平台,建立智慧交通协同服务体系是未来发展的必然趋势。
参考文献:
[1]沈 晴.面向交通拥堵预测大数据的神经网络群组快速学习[D].北京:北京科技大学,2017.
[2]周辉宇.基于大数据规则挖掘的交通拥堵治理研究[J].统计与信息论坛,2017,32(5):96-101.
[3]邓万宇,郑庆华,陈 琳,等.神经网络极速学习方法研究[J].计算机学报,2010,33(2):279-287.
[4]舒 忠.基于大数据的交通拥堵现状与治堵策略研究——以长沙市为例[J].河南科技,2019(22):114-116.
[5]Lichun Lin,Shi Tong.Automatic Spatial Annotation of Image Based on Object Recognition[J].Journal of Information & Computational Science,2013,10(18):5 829-5 847.
[6]薛倚明,饶 涓.整体优化路网交通量分配的系统思想[J].运筹与管理,2000,9(2):79-83.
收稿日期:2020-05-27