基于随机森林算法的河南省冬小麦产量预测最佳时间窗和影响因子研究
2020-04-01邵怀勇
林 滢,邵怀勇
(成都理工大学地球科学学院,四川成都 610059)
我国是人口大国,粮食安全至关重要。小麦是我国主要粮作物之一。据统计,2018年我国小麦播种面积2 427万hm2,总产量13 143万t,占全球小麦产量的17.62%[1]。及时准确掌握小麦生长信息,并进行估产分析对农田管理、农业政策制定等具有重要意义[2-3]。目前作物产量预测主要采用经验统计模型和面向过程的作物生长模型。传统方法中,许多国家的作物产量统计数据通常是将地面观测与产量报告相结合计算得出。如Reynolds[4]在2010年将实时卫星图像引入到地理信息系统(GIS)和粮食及农业组织(FAO)的作物特定水平衡(CSWB)模型中,开发了一种可操作的作物单产模型,并取得较好效果。但是基于地面实地考察的数据收集成本高昂、耗时且效率低下,同时无法确定过程中的可靠性,因此可能会导致作物产量评估效果不佳[5-6]。且经验模型往往因地理位置、作物品种和生长季节而异,模型的空间泛化能力低。遥感技术的出现为农业研究提供了新的方法[7]。充分利用遥感数据,可实现农作物长势监测与产量估算,研究作物遥感估产的基本机理与方法[8-9]。如吴炳方[10]利用每旬的最大NDVI图像对全国范围的作物进行遥感长势监测,估算作物种植的面积。作物估产模型包括农业技术转移决策支持系统(DSSAT)、农业生产系统模拟器(APSIM)、捕捉大面积作物-天气关系的模式(MCWLA)和世界粮食研究模型(WOFOST)[11]。虽然模型可以更高的精度模拟作物产量,但运行模型需要大量的参数输入(例如气候变量、肥料、灌溉、土壤和水文特征),费时费力,当实验区较大时会因无法获取某些数据而受到限制[12]。随着人工智能快速兴起,机器学习作为新技术,在数据挖掘与分析方面展现了强大的功能,从而为农业应用提供了新的技术与途径(包括作物类型分类和产量预测),并推动了农业的发展[13]。因其在处理多维数据集方面的强大能力,机器学习技术将为改进产量预测模型提供强有力的支持。近年来,已有机器学习方法运用于作物产量估测,如人工神经网络[14]、高斯过程[15]等。然而,许多研究基于整个生长季节选择变量,在收获日期之前实际上难以估计最终产量。此外,很少有研究确定冬小麦产量预测的最佳训练时间段,而找到能够很好地反映冬小麦估产的最佳时间窗,将有助于提高作物估产模型的应用效果。
随机森林(random forest,RF)是一种需要模拟和迭代的基于分类树的算法[16]。它可以在不增加运算量的情况下保持良好的准确性[17],并且可以评价自变量的重要性,避免回归分析中多重共线性现象[18]。目前,随机森林算法已应用于农业研究,例如Yvette Everingham使用随机森林算法根据不同大小预测范围对甘蔗产量进行预估并取得良好效果[19];王娣运用随机森林算法建立水稻估产模型,并进行模型精度评价[20]。
已有学者对比不同机器学习算法在作物估产中的效果[21],但就不同时间段训练样本对预测模型精度影响的讨论不多。本研究尝试以河南省113个县的冬小麦为例,运用随机森林算法,探讨河南省训练样本选择的最佳时间段,并分析不同影响因素对产量预测的相对重要性,以期提高该算法在作物估产的应用效果。
1 数据与方法
1.1 研究区概况
河南省地处北纬31°23′-36°22′、东经110°21′-116°39′之间,位于黄河中下游,地势西高东低,大部分区域属暖温带气候。河南省小麦种植区属于黄淮海冬麦区,耕作制度为一年两熟。土壤肥沃,生产环境佳,适宜小麦生长,是我国冬小麦的核心生产区之一。2017年,河南省冬小麦播种总面积达547.5万hm2,总产量355亿kg,占全国总产的四分之一[1],因此其小麦高产稳产对全国小麦生产与供求平衡具有重要影响[22]。
1.2 数据来源
试验获取的数据包括2001-2015年的遥感、气候、土壤和产量数据。所有数据空间分辨率统一为1 km×1 km,时间分辨率统一为一个月,并且所有变量将基于小麦生长像素进行掩膜,并按县求平均值。数据处理主要在ArcGIS进行。
1.2.1 遥感数据
归一化植被指数(normalized vegetation index,NDVI)和增强型植被指数(enhanced vegetation index,EVI)与作物产量有较好的相关性[23-25],因而常被用于作物估产研究,将NDVI与EVI结合可为作物估产提供更多的信息[26]。河南省2014和2015年的两种植被指数来自于MOD13Q1,周期为16 d,空间分辨率为250 m×250 m。
1.2.2 气候数据
气候对农作物的产量、生长发育、种植制度均有重要影响[27-28]。参照前人的研究[29],本研究选取每月最高温度(Tmax)、最低温度(Tmin)、干旱指数(Psdi)和降水量(Pr)作为气温变化要素参与作物产量预测。采用Terra Climate数据集提取出研究时间段内所需气候指标[30],在GEE平台处理数据并计算每个县的气候变量。
1.2.3 土壤数据
土壤理化性质是作物产量的关键影响因素[31-32]。本研究选取土壤深度、土壤质地、有机碳含量、pH、阳离子交换容量、地表土层容重和地下土壤层容重作为土壤影响因子。土壤理化性质数据来自世界土壤数据库(HWSD)[33]。
1.2.4 冬小麦产量数据
冬小麦产量数据收集自《中国农业年鉴》和县级统计数据,个别区域数据缺失。
1.3 研究方法
冬小麦不同生育阶段的形态、生理特征不同,因而估产选择不同生长阶段的数据进行产量预测的精度不同。河南省冬小麦的一般9月份播种,来年6月收获。本研究从冬小麦生长季中抽取8个时长不同的时间段(9-5月、9-6月、10-3月、10-4月、10-5月、11-3月、11-4月、12-3月)数据,其中以2001-2013年的数据作为测试数据训练模型,进行十折交叉验证。用训练好的模型分别预测2014和2015年河南的冬小麦产量,与实际产量做精度对比选择出最佳的样本选择时间段。
1.3.1 随机森林算法预测作物产量
随机森林算法由一系列不同的回归树(CART)组成基于多个分类树的算法,它对数据集的适应能力较强,能有效地运行大数据集。由于随机性的引入,随机森林法不容易陷入过拟合并且具有很好的抗噪声能力,提高了学习的稳定性。目前,该算法已在生态学[35]、水利水电[36]、地灾评估[37]等领域有所应用。主要公式如下:
(1)
式中,F(x)是一个组合模型,hi是单一决策树,Y表示输出变量,I表示特征函数。试验使用的树数量为100。数据不被提取的概率为1-1/N,收敛为1/e≈0.368,即有约37%的训练数据不会被运用到单个模型构建中。边缘函数如下:
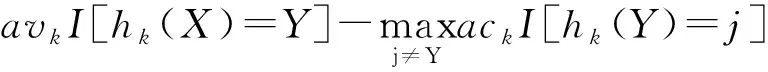
(2)
该式表达模型的可靠性,即函数值越大,分类越可靠。分类器的通用表达如下:
PE*=Pxy[mg(X,Y)<0]
(3)
其中,(X,Y)为概率空间。随着决策树数目的增加,PE*序列将变为:
Pxy{Pθ[h(X,θ)]=Y-maxPθ[h(X,θ)=J]}<0
(4)
当树的数量增加,泛化误差总是收敛的。具体模型构建原理参照Breiman等[16]方法。
1.3.2 精度评估指标
用决定系数(R2)、均方根误差(root mean square error,RMSE)[38]、平均绝对误差(mean absolute error,MAE)[39]和误差系数评估模型预测的精度。
(5)
(6)
(7)
(8)
1.3.3 重要性评价
为了探索模型中不同预测变量的重要性,可计算基于均方误差(MSE)的预测精度下降的平均值。准确性平均值的下降表明,如果排除该特定变量,则随机森林模型预测精度也将下降。预测变量准确度的平均值下降幅度越大,认为该变量就越重要[40]。
本研究以产量为因变量,NDVI、EVI、Tmax、Tmin、Psdi、Pr和土壤水分七个每月变化的因素为自变量,运用R语言做随机森林回归,可以得到自变量的相对重要程度。
2 结果与分析
2.1 不同时间段预测精度比较
由表1可知,整体上利用不同时段数据训练出来的模型对小麦产量的预测精度没有太大差异。在2014年,11-3月和12-3月时段的模型预测精度较好,R2分别是0.81和0.80,MAE和RMSE值均最小。2015年,只有12-3月时段的模型预测精度最好,R2为0.81,MAE和RMSE也都最小。两年相比,2014年的预测精度整体上优于2015年。2015年有6个时间段RMSE大于1 000 kg·hm-2,预测精度不够好。
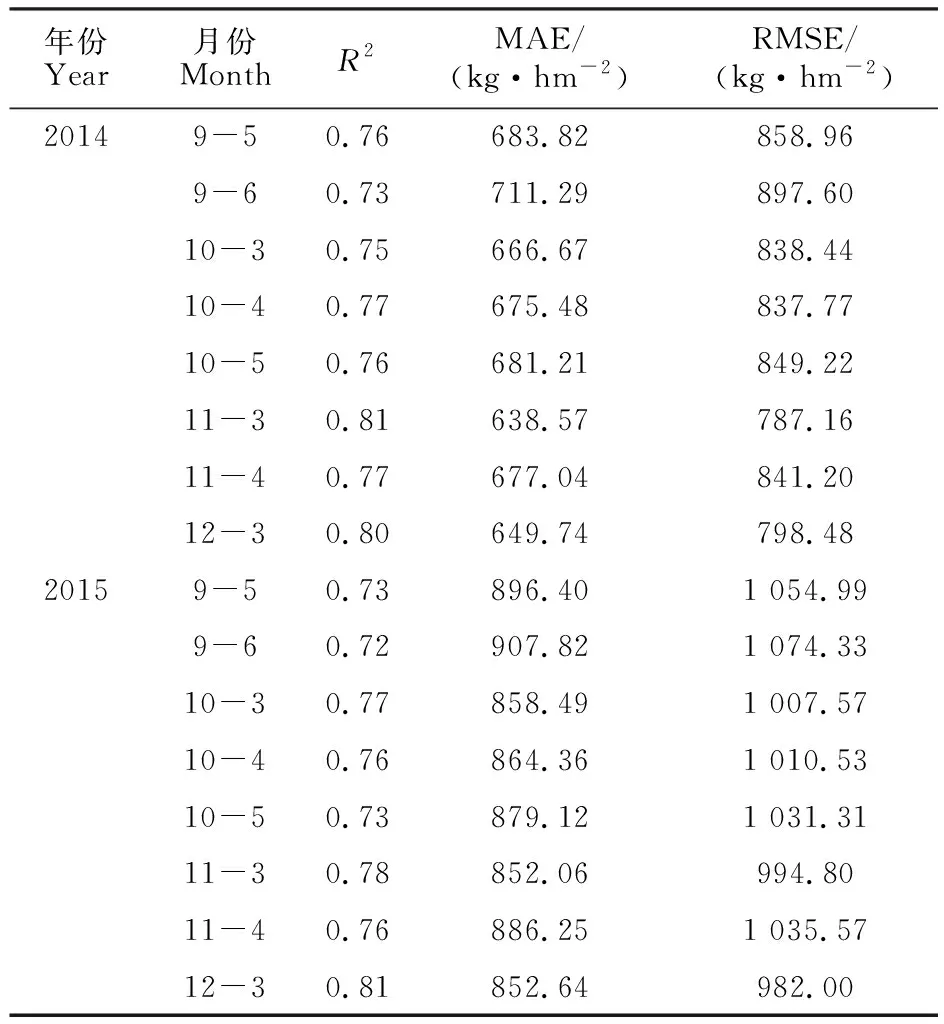
表1 2014、2015年随机森林算法在不同时间段小麦产量预测精度对比Table 1 Comparison of accuracy in different time period by random forest algorithm
综合分析表明,12-3月时段的R2在2014和2015年均大于0.8,因而将该时段作为河南省冬小麦最佳训练样本选择时间段。该时段的预测精度较高可能是因为该时间段冬小麦处于返青期,植株生长及气候特征相关性较高。从拟合曲线上看,在低产区,预测值低于实际值;在高产区,实际值略高于预测值(图1)。
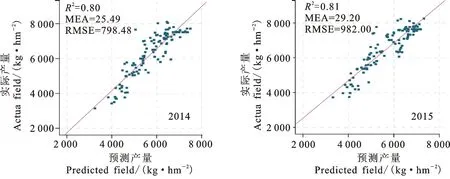
图1 2014、2015年小麦预测产量与实际产量散点图Fig.1 Scatter plot of predicted and actual yield of wheat in 2014 and 2015
2.2 产量预测空间分布特征
将随机森林算法通过12-3月的数据预测的2014和2015年冬小麦产量及误差系数进行空间可视化,结果如图2所示。整体上,河南省冬小麦2014年和2015年的实际产量空间分布状态相当,均呈现西低东高的状态。对比发现,两年预测产量分布与实际产量特点大体相似,但在高产区存在整体预测结果较低的情况。结合误差系数可以发现,预测结果整体效果较好,大部分区县的误差系数介于-0.1~0.1之间,存在个别预测值过高或过低的情况。2014年研究区西部存在局部估产过高的情况,2015年东部有个别过低估计产量的区县。

图2 2014、2015年小麦预测产量及误差系数空间分布图Fig.2 Distribution of wheat yield and error coefficient
2.3 影响因子重要性评价
用R语言对冬小麦整个生长期数据进行随机森林建模回归分析,结果(图3)表明,月降水对小麦产量的影响远大于其他因素,重要性达到了29.79,即当降水发生变化时,对模型精度的影响最大,与水分是影响作物产量的重要环境因子的事实相符。其次是月最低温度和增强植被指数,重要性分别是23.76和22.64。NDVI、干旱指数、土壤水分的重要性相当,分别是21.05、21.05和21.04;最后是月最高温度,重要性只有20.75。

图3 影响因子重要性统计图Fig.3 Importance of impact factors
3 讨 论
作物产量快速预测可为粮食销售决策制定提供参考依据,同时可以指导整地、除草、施肥等田间管理。本研究利用随机森林算法实现了冬小麦产量的预测。利用作物生长模型如农业生产系统模拟器(APSIM)进行估产时,通常需要大量的输入变量,不仅有许多假设,而且输入变量的数据大多需要田间测量,在大范围的产量预测方面具有一定的局限性,且大范围的田间调查需要消耗大量的人力物力。随机森林等机器学习算法的一个显著优点是在较少的假设下,可以组合能免费获取的遥感等数据,通过信息挖掘较好地实现大范围的作物产量预测,过程相对简单,且具有通用性的潜力,但相比于作物模型,该方法无法表达各因素对产量影响的具体机理。同时,本研究发现,利用不同生长时段的样本建模,模型的预测精度不同,表明变量的时段是模型非常重要的影响因素之一。刘峻明等[41]探讨了基于随机森林算法的河南省冬小麦平均拔节期到平均抽穗期(3-5月)气象要素对产量预测的作用,主要引入气象特征。本研究主要探讨基于冬小麦整个生长期(9月-来年6月)的最佳预测时间窗的选择,同时考虑到气候因子对产量预测的影响,引入植被指数等与作物生长相关的要素,使训练模型的因子选择更丰富。由于气候、地形、纬度等差异,作物产量预测的最佳时间窗口可能存在着空间差异性。此外,农户的管理措施(如作物品种、播种量等)对作物产量也具有较大影响,这些信息应该包括在未来的建模方法中,即将管理投入与模型结合是未来研究的一个有前景的途径。
4 结 论
选择2001-2013年河南省冬小麦八个时间段数据作为训练样本,应用随机森林算法建立基于训练样本的估产模型,进而预测2014和2015年产量,其中12-3月的估算精度在两年都最佳,预测产量与实际产量在空间分布上也基本一致,该时段可作为随机森林算法估算河南省冬小麦产量选择训练样本的最佳时间;在影响因子中,月降水对冬小麦产量的重要性最大,其次是月最低温度和EVI,NDVI、干旱指数、土壤水分和月最高温度重要性相当。
