python网络爬虫爬取策略对比分析
2020-03-30翟普
翟普

摘要:随着网络技术的迅猛发展,网络已经成为信息的栽体,网络随处可见,打开网络,大量的信息充斥而来。如何有效提取并利用网络中有价值的信息将会成为未来一个很大的挑战。网络爬虫是一个可以自动提取网页的程序,Zh.;b-维网上下栽网页,提取信息。通常爬取的页面比较多,如何快速有效地爬取页面是关键,该文通过当当网新书畅销排行榜实例来分析对比现有的四种方式,得出结果异步爬虫和scrapy框架爬虫速度最快。
关键词:网络爬虫;异步爬虫;scrapy框架爬虫
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2020)01-0029-02
1什么是網络爬虫
搜索引擎,如baidu、google、yahoo、sougou等是人们通过网络检索信息的入口,但是这些搜索引擎存在着一定的局限性,它们大多是基于关键词进行检索,它们的目标是尽可能大地覆盖到网络,检索出来的数据形式也多样化,如:图片、文字、音频、视频、数据库等。但是,通常情况下不同背景的用户检索目的和需求有所差异,对搜索引擎返回的大量结果可能并不关心,对于一些信息含量密集并且具有一定结构的数据不能很好地发现和利用。而搜索引擎也会基于服务器资源有限,而网络资源无限产生资源之间的矛盾。
为了解决这些问题,网络爬虫随之而诞生。网络爬虫实质是一个程序,它可以自动地下载网页,根据特定的需求,提取爬取网页的某些内容和信息,可以选择性地从网络上抓取相关网页和链接,为面向主题的用户提供数据资源。
一个网络蜘蛛就是一种机器人,通常,网络爬虫首先会爬取一组url,一个url对应一个页面,然后对每一个页面里面的url链接再进行反复爬取。爬虫的基本流程为:
第一步:向要爬取的网页服务器发出请求
通过request库的get方法向目标站点服务器发出请求,等待目标服务器的响应;
第二步:获得请求响应的内容
如果目标站点服务器能够正常响应,就会返回一个Re-sponse对象,该对象包含请求网页的内容;
第三步:解析网页内容
第二步得到的页面内容可能是HTML格式的,使用第三方页面解析库或者使用正则表达式进行解析;
第四步:处理网页内容
处理解析出的网页内容,提取重要的信息,进行保存或者格式化输出。
2python与网络爬虫的联系
2008年,自Android将移动操作系统开源以来,一批新的计算机技术和概念迅速涌现,这些技术促使现有的计算机技术升级换代。这些概念包括云计算、移动互联网、互联网+、大数据、可穿戴计算等。这些概念让计算的平台和应用变得更多样化,同时不可避免也带来了更复杂的安全问题。虽然概念很多,但是,在这个阶段很难有哪个技术能够独领风骚,面对复杂的功能性和紧迫的迭代周期,计算机需要更抽象级别的程序设计语言来表达可编程性,python语言称为这个阶段的主流编程语言。
由于python拥有丰富的网络抓取模块,对字符的处理也很灵活,书写爬虫很方便,并且拥有强大的爬虫框架scrapy,所以经常用python来写爬虫。今天我们通过研究几种python爬虫爬行策略,来分析每种策略的优劣。
3python网络爬虫的几种方法一以当当网新书畅销排行榜为例
通过施加不同的策略,可以将Python网络爬虫的方法大致分为四种:同步爬取方法、并发爬取方法、异步爬取方法、scrapy框架爬取方法。下面通过具体介绍每种方法,来对四种方法进行对比分析。
3.1同步爬取方法
3.1.1方法简介
该爬虫方法是用requests+BeautifulSoup的方法。Requests库是使用python语言编写的HTTP库,BeautifulSoup库是一个灵活又方便的网页解析库,处理高效,支持多种解析器。利用它就不用编写正则表达式也能方便的实现网页信息的抓取,BeautifulSoup可以解析网页代码,根据用户的需求获取想要的内容格式化输出。
3.1.2运行结果
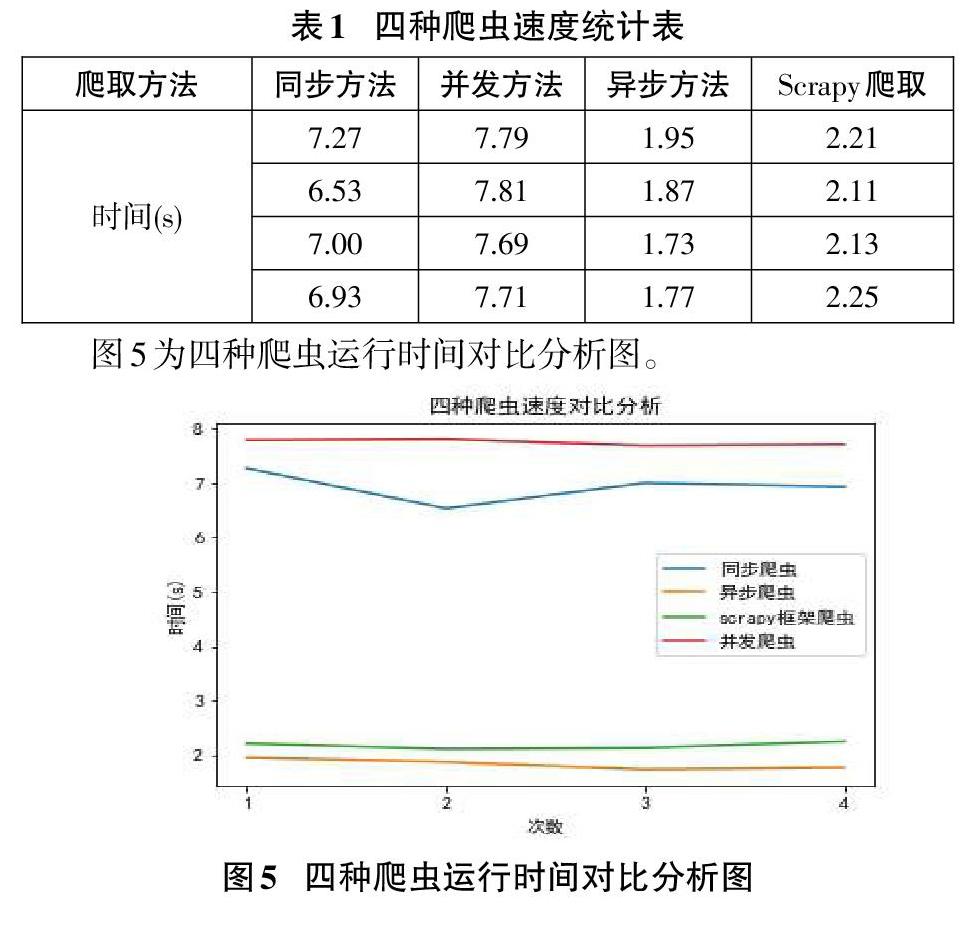
使用一般的同步方法,爬取25页书籍,总共耗时大约为7.27s
3.2并发爬取方法
3.2.1方法简介
该方法利用并发模块concurrent.futures来实现,该模块使用多线程来加速同步爬取的方法,该模块支持线程池和进程池,可以根据实际情况设置线程个数,本文设置线程的个数为16个,因为线程设置越多,切换的开销也会比较大。
关键代码如下:
##利用并发模块concurrent,futures爬取网页
executor=ThreadPoolExecutor(max_workers=61)
##函数submit():parser为函数的名字,uds为传入的参数,可以有多个参数
book_tasks=[executor.submit(parser,urls)for url in urls]
##表示等前面所有的线程全部执行完毕才会进行后面程序的执行
wait(book_tasks,return_when=ALL_COMPLETED)
3.2.2运行结果
使用并发方式,耗时大约为7.79s,说明使用多线程,并不一定会加快爬虫的速度。
3.3异步爬取方法
3.3.1方法简介
使用第三方库aiohttp可以进行异步处理http的请求,使用第三方库asyncio可以进行时间异步10,异步10方法可以很好地提升网络爬虫的速度。这种爬取方法与同步方法的思路和处理方法基本一致,只是在处理HTTP请求时使用了aiohttp模块以及在解析网页时函数变成了协程(coroutine),再利用aysncio进行并发处理,这样无疑能够提升爬虫的效率。
3.3.2运行结果
3.4scrapy框架爬取方法
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,只需要定制开发几个模块就可以轻松的实现一个爬虫。具体步骤如下:
