热力管道应力分布式计算系统研究
2020-03-30韩金池郭建东文欢常雪姣王钦松
韩金池,郭建东,文欢,常雪姣,王钦松
(电子科技大学信息与软件工程学院,四川 成都 611731)
热力管道在工业生产和热量传输中有着广泛的使用,它通常用于运送高温高压的蒸汽或流体介质。由于管道在使用过程中会承受较大的膨胀力与冲击力,一旦设计不当,会产生管道破损,引发蒸汽,热液体泄漏,甚至危及工厂人员的生命安全,因此,管道必须满足应力计算规范后才能投入使用。设计过程中,工程师需要凭借自身的经验和复杂的数学计算,考虑管道材质、不同工况下管道的受力分配、管道支吊架类型的设置等难题。管道节点的支吊架类型多样,需要工程师长年的设计经验和复杂的矩阵计算才能得到最终的受力情况,成为了管道设计的难点之一。
Spark on YARN是结合了Spark与Hadoop的分布式架构,它通过Hadoop的分布式文件平台进行资源管理,调度Spark进行高效分布式计算。开发人员可以在此架构下编写分布式计算程序,分配集群资源,提高运算效率。MongoDB是可以分布式储存的非关系数据库,用于储存文档类型的非关系数据,并具有高扩展性,支持动态文档的深度查询。Spark官方提供了MongoDB的数据链接器,允许在分布式计算程序中向分布式数据库中读写数据,为两者的结合提供了可能,两者都开放了Python语言的API,这更提供了与TensorFlow等机器学习库联合运用的条件。上述体系非常适合与构建文档类型数据的大数据平台。
1 体系结构
1.1 实验环境
此体系涉及多种软件的协作运用,需要选取合适的版本以保证服务于相同的Java-jdk文件。具体实验环境如下:
操作系统:Ubuntu-18.04
编程环境:jdk-9.1 python-3.5
应用软件:
Hadoop-2.7.7
Spark-2.1.1
MongoDB-4.0.1
1.2 体系结构
图 1中,HDFS是 Hadoop提供的分布式储存平台,在此体系中的作用是进行资源管理,用于集群共享计算代码、日志文件、JAR程序包等文件。HDFS平台适合于文件储存,但对于单条数据的查询效率低下,难以胜任高度自定义化的数据分析查询。非关系型数据库MongoDB满足分布式储存,同时具备文档类数据的自由查询能力,因采用MongoDB进行管道计算结果储存。Hadoop本身具有MapReduce分布式计算能力,但Spark在内存运用方面更为高效,Hadoop相较之在资源管理方面又更为完善,因此采用Spark on Yarn的模式,用Hadoop的Yarn模块进行资源管理,调用Spark内存使用规范进行任务计算。
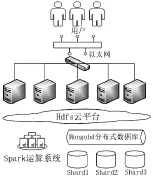
图1 体系结构图

图2 MongoDB分片储存
以三台机器为例,MongoDB分布式数据库搭建如上。每台机器有一个Mongos进程作为数据读写入口,一个ConfigServer用于配置路由查找,保证各机器之间的地址联系。同时每台机器还复制了三分相同的数据分片,保证部分机器死机时,用户依然能够通过其他机器上的分片数据读写完整的数据,使得分布式集群可靠性更强。
2 实验方案
2.1 资源配置
采用5台配置有Ubantu18.04操作系统的电脑进行集群搭建,5台电脑配置如下。
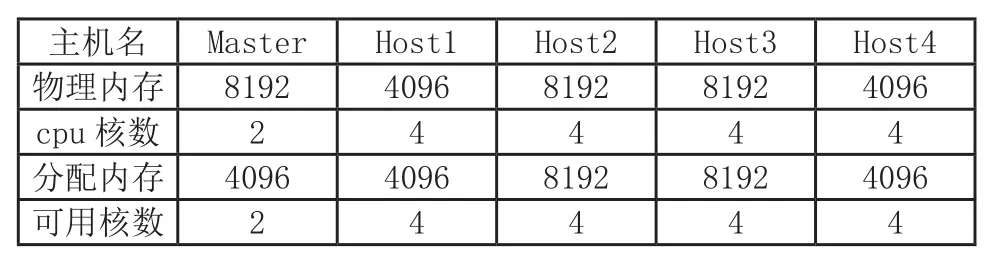
表1 集群配置表
机器的内存和CPU核数是影响计算速率的主要条件。由于Hadoop的MapReduce运算流程是一次性在集群中完成任务分发,任务完成的总时间受各种因素影响,需要在Hadoop与Spark中进行相应配置,保证任务的分发数量能充分利用机器资源,才可以达到最短的任务完成时间。
2.2 实验方案
Container是Hadoop里面的资源分配模块,在任务进行中,子机上Container的数量对应投入于MapReduce的机器资源,其数量可在Spark on YARN的工作模式下由Spark的Num-Executors配置决定。
MapReduce分片数指分布式任务的子任务数量,可在程序代码中进行设置。
可变节点数是指管道配置文件中可选取多种型号支架的管道节点,此处设置每个变换节点都有2种型号支架可选择,假设可变节点数为n,通过穷举所有变换,共需计算2^n个文件。
以上三个都与任务完成时间密切相关,通过控制变量,可以根据以下实验方案表研究各个数据对运算速率的影响特性。
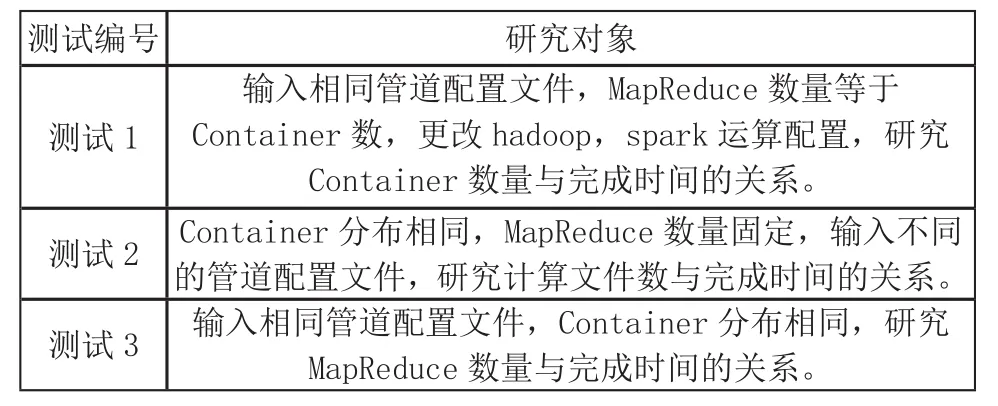
表2 实验方案表
3 性能测试
3.1 测试 1
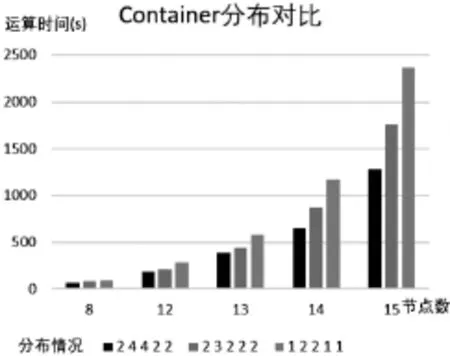
图3 Container分布与运算时间图
参考图3,在输入文件相同的情况下,Container总数越多,运算时间越快。图中灰色条形柱代表Master,Host1-4分别有1,2,2,1,1个Container时候的运算时间,除了MapReduce过程中Reduce部分使用的1个Container,Map运算的Container共有6个,相较蓝色条形柱(共13个Map运算Container)速度要慢很多。实验验证了运算时间与参与运算的资源数量的反比关系。
3.2 测试 2
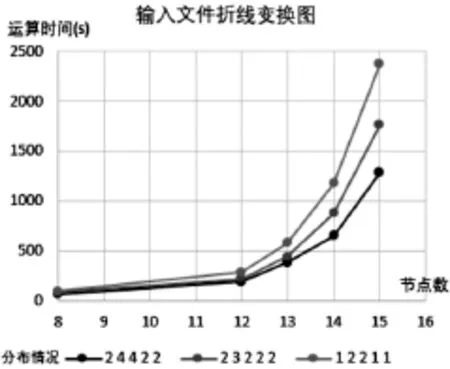
图4 输入文件变化与运算时间图
参考图4,在Container分布相同的情况下,输入文件的点数越多,运算时间成指数级增加,符合运算时间与变换文件的数量的对应递增关系。
3.3 测试 3
测试3在输入文件为12节点(输出文件为),各节点Container分布为1,2,2,1,1的情况下进行。

图5 Mp数量与运算时间图
参考图5,在Mp数量低于Container总数的时候,增加Mp有助于提高速度,而在Mp数量高于Container时,增加Mp对运算时间无正面影响。可推测Mp分片数要契合Container资源数,才能最大化运算效率。
3.4 测试结论
分布式计算的资源分配与机器性能的关系类似于排队论的关系,如图6。
在分配任务数固定的情况下,各电脑配置应尽量相同,特别是内存大小要与CPU性能匹配。由于任务一次性分发,在CPU性能好、内存不足的情况下,高级CPU只计算了少量任务,浪费了CPU资源;CPU性能差,但内存充足的情况下,低性能CPU计算大量任务,会导致计算时间增大。
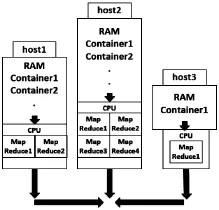
图6 资源分配关系图
同理,整个计算任务的完成时间也会因不同机器配置间的木桶效应增长,因此,各个电脑最好采取完全相同的内存与CPU配置,以便大型集群的任务分配与管理。
4 未来展望
在工作流程方面,目前通过在节点变换中设置人为干预来减少需要计算的管道节点数量,减少系统的运算总时间。未来可通过Python编程,引入机器学习来协助管道分析,实现对错误设计方案的智能剔除。
在系统展示方面,目前主要以传统的文本方式进行管道设计与参数调整。未来可引入WebGL进行网页渲染,将管道设计文件投射为可视化的3D模型,用户可以直接操作3D模型来管道设计文件进行参数调整,实现传统管道设计的3D可视化。
在集群架构方面,目前用到的软件相互孤立,需要对各个软件进行单独安装,造成了集群部署耗时耗力。未来可以通过Docker容器对平台软件进行包装,提高软件的移植性,增强集群的伸缩性,方便集群新机的软件部署。
