基于深度图像的零件识别及装配监测
2020-03-19田中可陈成军李东年赵正旭
田中可 ,陈成军,李东年+ ,赵正旭,洪 军
(1.青岛理工大学 机械与汽车工程学院,山东 青岛 266033;2.西安交通大学 机械制造系统工程国家重点实验室,陕西 西安 710049)
0 引言
现代大型复杂机械装备涉及的装配知识较多,单纯依靠工人的经验、技术和知识难以高效完成复杂机械装备的装配工作。而使用纸质和电子手册时,操作者需要边操作设备边手动查看手册,操作难度大、效率低,而且注意力需要在手册和设备之间频繁切换,容易受周围环境的影响,使装配出现差错。随着增强现实技术的发展,增强现实装配诱导逐渐受到各国研究者的重视。国外空客军用飞机公司已将增强现实技术应用在A400M 军用运输机布线诱导中[1],美国海军将增强现实技术应用于舰船维修[2],Webel 等[3]将增强现实技术应用于产品装配技能培训;国内南京航空航天大学的赵新灿等[4]研究了增强现实维修诱导系统交互技术;北京理工大学的万毕乐等[5]研究并实现了虚拟环境中的线缆建模和快速布线;青岛理工大学陈成军等[6-7]提出基于语义情境的机械设备拆装增强现实诱导方法和基于特征包围盒模型的装配诱导信息自适应显示方法。
现有的增强现实装配维修诱导系统多采用语音、键盘的方式查询诱导信息,其人机交互性差,而且只是诱导,并不能检查装配的正确性,如装配位置和装配顺序的正确性等。因此,目前需要一种装配体零件识别和装配监测方法来准确地识别出装配过程中装配体的各个零件及其状态,以监测装配过程中的零件装配位置和装配顺序的正确性。
目前,已有不少学者对机械零件识别及装配过程监测进行了研究。在机械零件识别领域,严华等[8]提出基于边界矩的零件图像轮廓特征提取方法,实现了机械零件的有效分类;匡逊君等[9]采用不变矩与支持向量机(Support Vector Machine ,SVM)结合的方法实现了机械零件的分类识别;Cao等[10]提出一种新的零件图像特征提取算法,并通过实验证明该方法的有效性。在装配监测领域,Yin 等[11]提出一种面向飞机装配监测的无线射频识别(Radio Frequency IDentification,RFID)布局方法,满足了飞机装配过程的监测要求;陈培等[12]设计了基于高级精简指令集计算机(Advanced Reduced instruction set computer Machine,ARM)的线缆智能生产监控系统,满足了线缆生产自动化控制中的监测要求;周铨[13]提出过盈压装装配工序的过程监测系统,该系统通过实时监测生产线进行装配过程的质量控制和数据采集;汪嘉杰等[14]提出的航天电连接器智能识别与装配引导方法,实现了航天电连接器的装配监测。本文主要研究了基于深度图像和像素分类的装配体零件识别与装配过程监测方法。
目前,基于深度图像和像素分类的识别方法主要集中在人体部位识别和姿态识别、人手监测与跟踪、手势识别与交互等问题上。Keskin等[15]提出一种手的实时骨架拟合算法,并实现了对手的深度图像的实时识别;Shotton等[16]提出一种基于单幅深度图像的人体姿态估计算法,采用深度差分特征,运用随机森林分类器,实现了对人体的实时识别与跟踪;林鹏等[17]在Shotton研究的基础上对数据选择、特征提取和训练方法3方面进行简化,进一步提高了识别准确率;张艳[18]在对人手关节点识别研究时加入了像素点对质心的偏移角度,使其在有效区分人手部位的同时兼具旋转鲁棒性;张乐锋等[19]提出改进型深度差分特征,引入人体部位尺寸比例因子,在一定程度上提高了人体部位识别的准确率。
受以上研究成果的启发,本文借鉴人体部位识别和人手识别方面的研究成果,将基于深度图像和像素分类的识别方法应用于装配体零件识别和装配监测研究中,包括建立深度图像标记样本集、提取深度差分特征、利用随机森林分类器实现像素分类、根据分类结果完成装配体零件识别及装配过程监测。
1 方法框架
本文的方法整体框架如图1所示。首先建立深度图像标记样本集,包括合成标记样本集和真实标记样本集;接着利用改进后的深度差分特征对标记样本集内的深度图像进行特征提取,建立训练集与测试集,文中所建真实标记样本集只用于测试,不用于训练;然后建立随机森林分类器并确定各相关参数,对深度图像的像素进行分类;最后,根据像素分类结果获取像素预测图像,实现装配体零件识别及装配过程监测。

2 标记样本集的建立
标记样本集的建立主要包括获取合成标记样本集和采集真实标记样本集。
在建立合成标记样本集时,首先建立三维装配体模型,然后利用三维渲染引擎,以图形渲染的方式自动生成所需模型的深度图像标记样本集及对应的颜色标签图像标记样本集,改变模型角度,重复以上渲染过程,批量获取不同角度下的合成深度图像和颜色标签图像构成合成标记样本集。在改变模型角度时,考虑到本文所采集的实物图像多数为正面朝上,本文主要修改装配体模型偏航角(Yaw)的度数,对于滚动角(Roll)和俯仰角(Pitch)只做略微调整,图2a所示为合成标记样本集。
在建立真实标记样本集时,本文利用Kinect 2.0采集装配体实物的真实深度图像,利用背景差分法去除背景部分,通过转换实物的角度获取不同角度下的真实深度图像。为了更好地显示出所有零件,此处的实物转换角度主要绕Z轴旋转。最后,利用人工标记法对真实深度图像的各零件进行颜色标记获取对应的颜色标签图像,真实深度图像与颜色标签图像共同组成真实标记样本集,图2b所示为真实标记样本集。

图2的每对图像中左边为深度图像,右边为颜色标签图像。图2a为合成深度图像,为了与Kinect 2.0所采集的深度图像保持一致,获取更好的像素分类效果,本文设置背景灰度值为205,图像大小为512×424,视景体的视野垂直角度为60°,深度范围为1 000 mm~1 500 mm,并通过图像灰度值范围 0~255来体现。图2b中的深度图像是经背景差分法去除背景后所提取的前景部分深度图像,拍摄距离为1 000 mm~1 500 mm,颜色标签图像通过PS(Adobe Photoshop)人工标记法获取。
3 深度差分特征提取
考虑到像素分类法是通过将图像内各像素点分类来识别图像内的各部分,比较适合本文对装配体深度图像内各零件的识别研究,本文选择像素分类法对装配体深度图像内各零件进行识别。在选择像素点特征时,考虑到深度差分特征提取算法运算简单、易于实现,本文选择深度差分特征作为本文像素分类的像素点特征。
3.1 经典型深度差分特征
Shotton等提出的深度差分特征结合了梯度特征与点特征的优点,具体定义为
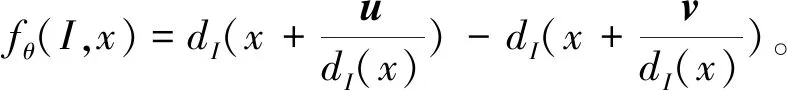
(1)
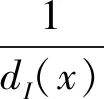
3.2 深度差分特征的改进
本文在继承Shotton等经典型深度差分特征的基础上,提出对深度差分特征进行改进,方法引入了边缘因子b,改进后的深度差分特征增加了去噪能力及边缘像素点偏移向量的自适应能力。改进后深度差分特征值的计算公式为

(2)

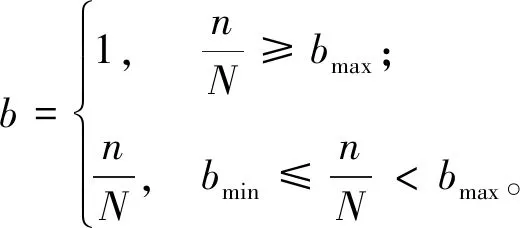
(3)


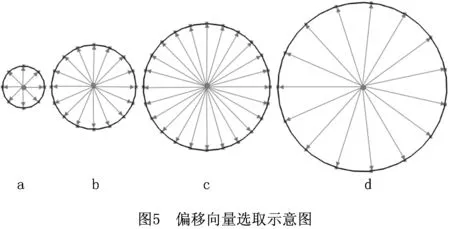
综上所述,相比Shotton等[11]提出的经典型深度差分特征,本文提出的对深度差分特征的改进之处主要体现为:①提高了偏移向量的自适应能力,如图4所示;②增强了本方法的抗噪能力。

3.3 对偏移向量u,v的确定

4 随机森林分类器
随机森林[20]分类器是由多个决策树[21]分类器组成的强分类器,相比单个决策树分类器来说,其最大的优势在于有效避免了决策树分类器经常出现的过拟合现象。随机森林分类器的工作特点是每棵决策树单独工作,互不影响,每棵树所使用的训练集都是从总的训练集中有放回地随机抽取,其通过多棵决策树的投票结果进行分类,得出最后的判断结果。因为随机森林分类器不会像单独决策树那样对同样的样本犯同样的错误,所以其分类准确性得到显著提高。图6所示为随机森林分类模型。

本文采用OpenCV机器学习库MLL中的随机森林分类器相关算法工具和类库构建随机森林分类器,单棵决策树的训练过程如下:
(1)随机选取一组候选属性φ=(θ,τ),其中θ为深度特征的偏移向量对,τ为候选分割阈值。
(2)根据候选属性φ将输入训练数据S={(I,x)}分割为左右子集:
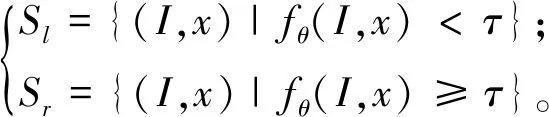
(4)
式中:Sl为左子集,Sr为右子集,fθ(I,x)为深度图像I上像素点x的深度差分特征值。
(3)计算左右子集的基尼指数,以左子集为例,假设左子集所含类别数为m,则基尼指数
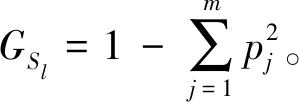
(5)
式中pj为j类元素出现的频率,同理可求出右子集的基尼指数GSr。
(4)计算属性φ划分样本集S的基尼指数GS,φ*,并求出最小基尼指数对应的属性φ*:
(6)
φ*=argminGS,φ。
(7)
(5)得到最小基尼指数GS,φ*后,判断当前节点是否达到树生长终止条件,是则设置当前节点为叶子节点,该叶子节点的预测输出为当前节点样本集合中数量最多的那一类,然后继续训练其他节点;否则重复迭代步骤(2)~步骤(4),直到满足终止条件为止。
由于本文直接借用OpenCV机器学习库MLL中随机森林分类器的相关函数进行训练,所以训练过程主要涉及对训练图像数量、随机森林分类器中决策树的最大深度、随机森林分类器中决策树的数量上限等参数的确定,这部分将在实验部分叙述。
5 装配过程的识别与监测
5.1 装配体零件的识别
在合成模型深度图像时,本文用不同颜色标记不同的零件,并记录各零件所标记的RGB(red,green,blue)值;然后用模型深度图像训练随机森林分类器,使用训练好的分类器对待测深度图像进行像素分类;最后根据分类结果绘制待测深度图像对应的像素预测图像。
本文将像素预测图像与颜色标签图像进行比对,通过分析颜色标签图像获取各零件与标记RGB值的对应关系,通过分析像素预测图像内各部分的RGB值来直观呈现深度图像内各零件的形状和位置,并将统计像素分类测试时每种颜色的像素分类正确率作为本文方法对每种零件识别的准确率。
5.2 装配过程监测
因为在装配过程中,多数装配体的底座都会被固定或者存在几种有限位置,所以本文假设装配体底座在装配过程中的位置不变,相机的拍摄角度也不变。鉴于装配过程中常出现的装配错误为零件错位和零件漏装,本文选择将待测状态像素预测图像与正确装配像素预测图像进行对比来判断以上两种装配错误。
判断过程如下:在监测装配过程之前,首先获取装配体在该位置下正确装配所对应的正确装配像素预测图像,命名为像素预测图像a;监测装配时,采集装配过程中装配体的深度图像并进行像素分类,获得待测像素预测图像,命名为像素预测图像b;将像素预测图像b与像素预测图像a进行比对,分别计算出像素预测图像b中各零件相对于像素预测图像a的像素重合率qz和像素减少率qn,有

(9)
式中:nc为零件Pn分别在像素预测图像a和像素预测图像b中坐标重合的像素点数;nz为零件Pn在像素预测图像a中所包含的总像素点数;na和nb为零件Pn分别在像素预测图像a和b中所包含的像素点数。
最后,通过分析各零件qz和qn的值来判断可能出现的装配错误,其中像素重合率qz用于判断装配过程是否出错,像素减少率qn用于判断装配过程出错的类型。判断过程如下:当某零件的qz≪1而qn≫0,即该零件的像素点重合率较低且像素点数差距较大时,基本可以判断该零件漏装;当某零件只有qz≪1而qn的绝对值接近0,即该零件的像素点重合率较低但像素点数变化不大时,基本可以判断该零件错位。
6 实验及结果分析
本文所使用的装配体为双级圆柱圆锥减速器。采用SolidWorks进行建模,Mutigen Creator对零件的颜色进行标记,具体标记如图7所示。
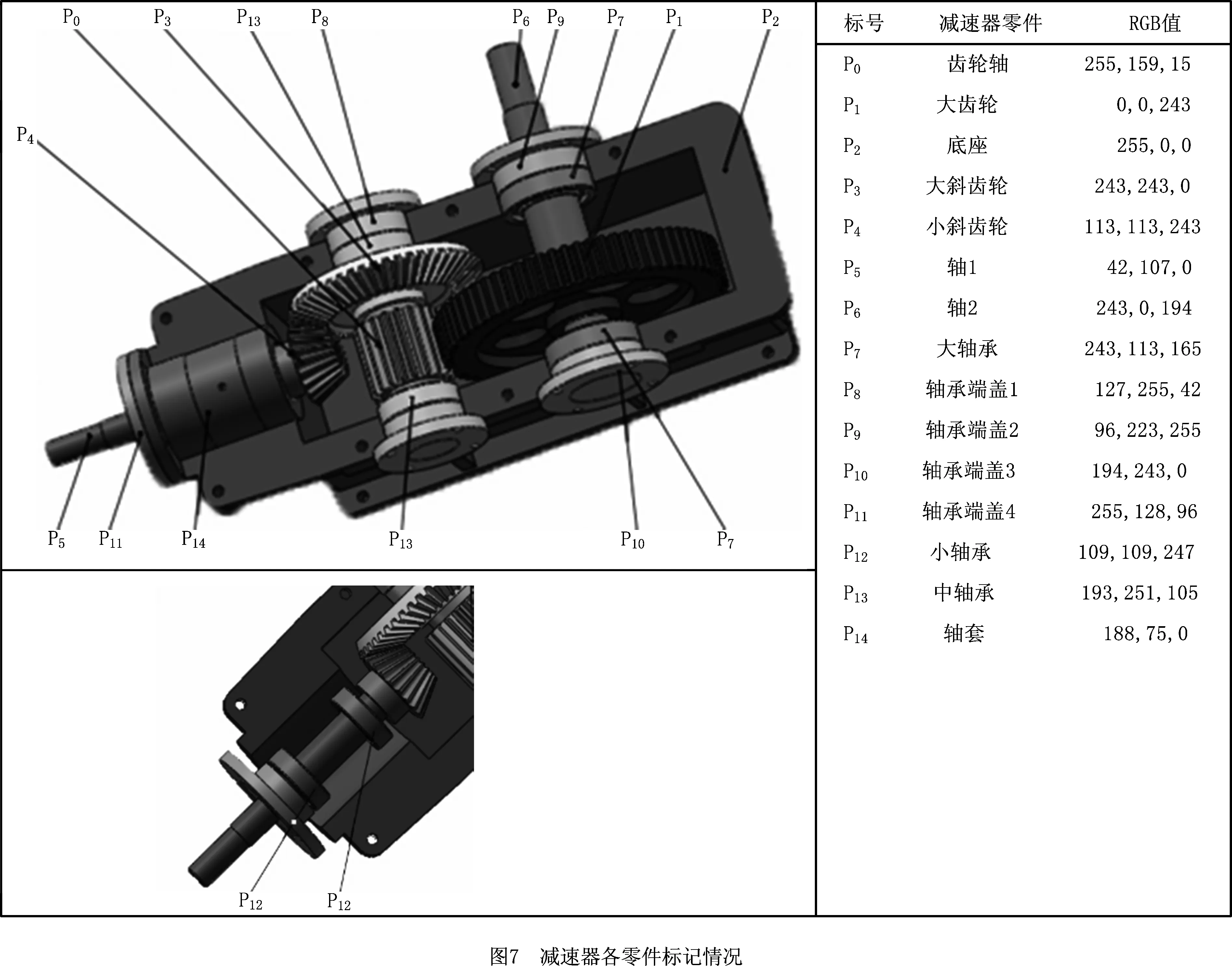
通过OSG(open scene graph)三维渲染功能生成实验所需的合成样本集;采用Kinect 2.0进行采集,采用人工标记法进行标记,获取实验所需的真实样本集。实验减速器的实物如图8a所示,真实深度图像采集场景如图8b所示。

本文实验环境配置如下:计算机为Intel® Xeon(R)CPU E5-2630 V4 @ 2.20GHz x 20,64 G内存,Ubuntu 16.04 LTS系统;深度图像获取传感器为Kinect 2.0;编译环境为GNU编译器套件(GNU Compiler Collection, GCC)编译器。
6.1 参数的确定
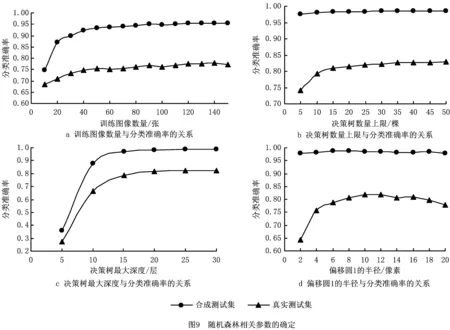
为确定随机森林分类器的各主要参数及偏移圆1半径的最佳取值,本文设计了若干组实验。实验中的训练集完全来自合成标记样本集,每张深度图像随机选取2 000个像素点进行特征提取。测试集分为合成测试集和真实测试集两类,合成测试集是从合成标记样本集中随机选取10张深度图像,每张深度图像随机选取3 000个像素点进行特征提取形成的;真实测试集是从真实标记样本集中随机选取10张形成的,其选点方式与前者相同。实验数据如图9所示。
(1)训练图像的数量
一定量的训练图像是分类器进行识别的前提。理论上,训练图片的数量越多,分类准确率就会越高,识别能力也会越强,然而由于设备和时间的限制,加上随机森林自身的特点,实际应用中仍需使用者通过实验来确定最佳训练图片的数量。本实验将决策树数量的上限设置为20,决策树的最大深度设置为25,训练图像的数量从10张逐渐增加到150张,每次增加10张,图9a所示为本实验的实验数据。由实验数据可得:开始时,随着训练张数的增加,分类准确率快速上升,直到120张后开始上下浮动,虽然这种饱和很可能是因决策树的棵数及最大深度有限而导致的相对饱和,但是考虑到时间成本和硬件限制,最终确定训练图像的数量为120张。
(2)决策树数量的上限
随机森林分类模型之所以很好地解决过拟合现象,依靠的就是拥有大量决策树,其分类结果是由所有决策树单独分类结果共同投票决定的。对于一个随机森林分类模型,如果决策树较少则会出现过拟合现象,如果太多又会增加训练时间,提高实验成本,因此本文为了确定最佳的决策树数量的上限,设计了图9b所示的两组实验。实验将训练图片设置为120张,决策树的最大深度设置为25,决策树的数量上限从5增加到50,每次增加5,实验数据如图9b所示。由实验数据可见,随着决策树数量的增加,分类准确率先快速上升,大约在35棵后上升速度减缓,因此本文确定决策树的最佳数量为35。
(3)决策树的最大深度
随机森林的分类准确率由随机森林中各决策树的分类准确率共同决定,因此要获得最佳的分类准确率,必须先确定最佳的决策树深度,使每棵树都具有最佳的分类性能。本文实验设定训练图片的张数为120,决策树的数量上限为35,决策树的最大深度从5增加到30,每次增加5。图9c所示为确定决策树最大深度的实验,由实验数据可见,随着深度的增加,分类准确率快速上升,直到25时不再变化,因此本文确定决策树的最大深度为25。
(4)偏移圆1的半径
偏移圆半径的大小直接影响偏移向量u,v的大小,因此需要通过实验来确定各偏移圆半径的最佳取值;又因为4个偏移圆半径之间存在1:2:3:4的关系,所以只需确定偏移圆1的半径即可。本文为此设计了图9d所示的两组实验,实验设定训练图片张数为120,决策树的数量上限为35,决策树的最大深度为25,偏移圆1的半径从2增加到20,每次增加2。图9d所示为本实验的实验数据,由实验数据可见,偏移圆1的半径对合成测试集的分类准确率影响不大,而对真实测试集的影响比较明显,随着偏移圆1半径的增大,分类准确率先上升后下降,大约在偏移圆1的半径为12时达到最大值,因此本文确定偏移圆1的半径为12。
本文确定的各主要参数值如下:训练图像数量为120张,决策树最大深度为25,决策树的数量上限为20,偏移圆1的半径最佳取值为12。后文实验中除特殊说明外皆采用此组参数。
6.2 边缘因子的影响
为了探究边缘因子对分类准确率的影响,本文设计了表1所示的两组对比试验。实验中,训练集全部选自合成标记样本集,共120张,每张深度图像随机选取2 000个像素点进行特征提取;测试集中,合成测试集是从合成标记样本集中随机选取10张深度图像,每张深度图像随机选取3 000个像素点进行特征提取形成;真实测试集是从真实标记样本集中随机选取10张形成,其选点方式与前者相同。实验数据如表1所示。

表1 边缘因子引入前后像素分类准确率对比 %
由表1可得,边缘因子的引入对合成测试集准确率的提高并不明显,可能是由于引入前分类器对合成测试集的分类准确率已经很高;对真实测试集像素点分类的准确率有明显提高,大约提高了1.50%左右。
为了探究边缘因子对图像识别时间的影响,本文设计了2组对比实验,实验条件与上文完全相同。实验中,因为单张图像的识别总时间包括特征提取时间和像素分类时间,其他部分时间相对较短,可忽略不计,所以本文主要统计了特征提取时间和像素分类时间,统计数据如表2所示。

表2 边缘因子引入前后的图像识别时间对比 ms
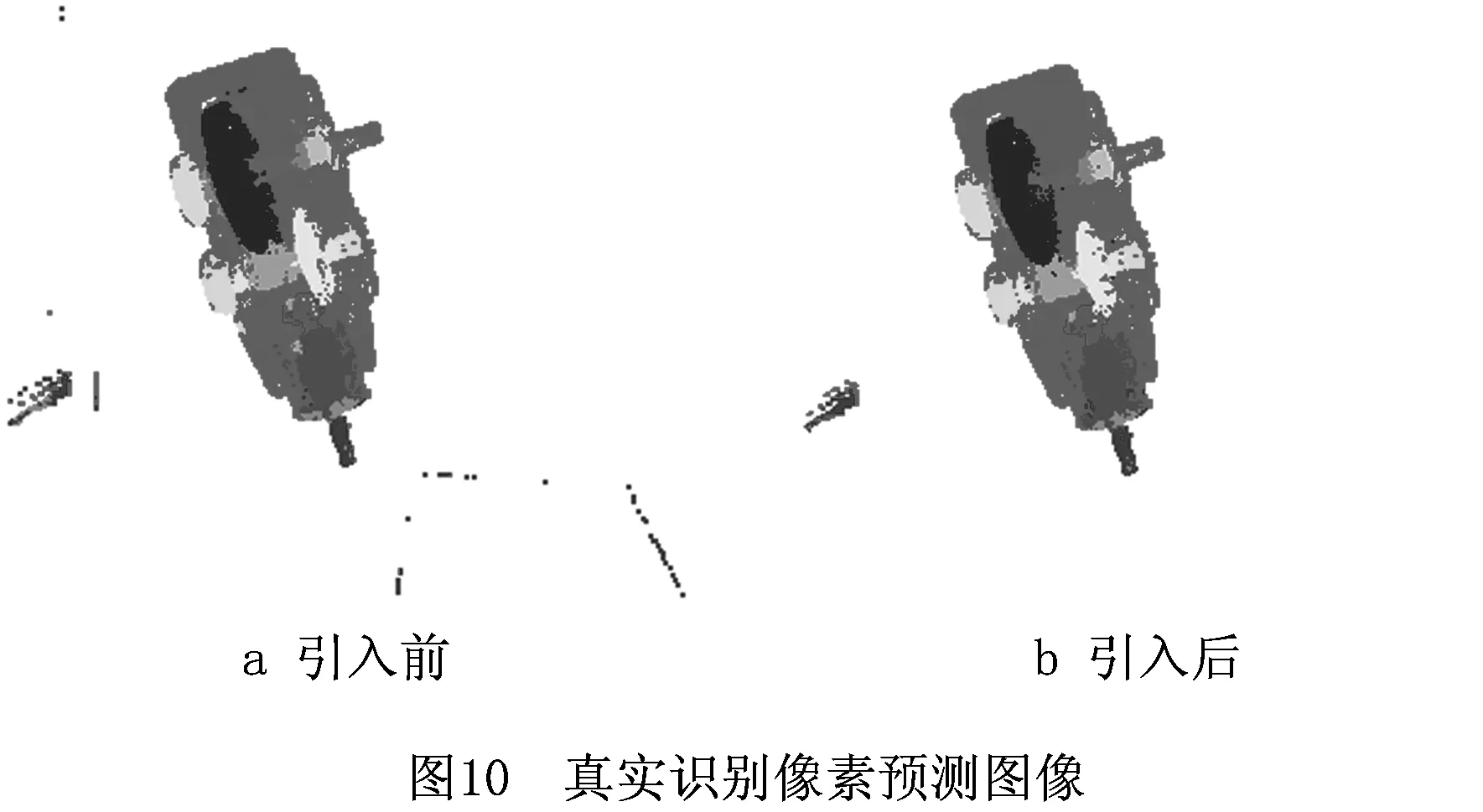
由表2可得,在单张图像采集点数为3 000像素点的情况下,本文方法对单张合成图像的识别时间大约为3 s,对单张真实图像的识别时间大约为4 s 。对比边缘因子引入前后的数据可得:边缘因子的引入使合成测试集的识别时间增加了约0.38 s,使真实测试集的识别时间增加了约0.22 s,虽然时间有所增加,但是增加程度不大,在降低效率方面对实际生产的影响基本可以忽略。图10所示为边缘因子引入前后分类器对真实深度图像的识别像素预测图像,通过图像明显可见改进后的深度差分特征比经典型深度差分特征具有更强的抗噪能力。
6.3 对装配体各零件的识别
为了获取本文方法对装配体各零件的像素识别率,设计以下两组实验。其中,训练集与测试集的来源与6.2节实验相同,实验数据如图11所示,图中横坐标为零件标号,标号的具体意义可参照图7,纵坐标为各零件像素的识别率。

由实验数据可得,本文方法对合成测试集整体像素的识别率达98.58%,对各零件的像素识别率基本都在96%以上;对真实测试集整体像素的识别率达82.70%,对各零件的像素识别率基本都在60%以上。图12所示为经分类器分类后的深度图像及对应的像素预测图像,其中每组图像右边为深度图像,左边为像素预测图像。

6.4 对装配过程的监测
本文研究除解决对装配体各零件的识别问题外,还要求能够对装配过程进行监测。本文通过对比正确装配体的像素预测图像与待测装配体的像素预测图像来实现装配监测功能,根据两者的像素重合率qz和像素减少率qn推断待测装配体各零件所处的状态。然而由于Kinect深度图像采集精度及外界环境的影响,本文主要以合成深度图像为例,对监测过程进行详细分析。
案例一待测深度图像为模型的合成深度图像;装配错误为P10件出现漏装。经特征提取及像素分类后获得的像素预测图像如图13所示。

根据式(8)和式(9)计算图13b相对于图13a的像素重合率qz和像素减少率qn,计算结果如表3所示。
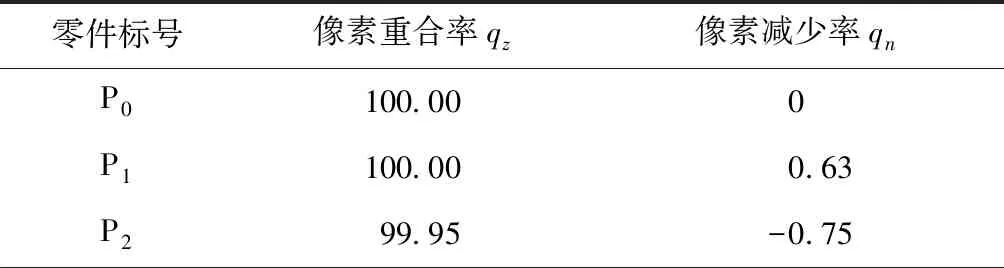
表3 P10件漏装的比对数据 %

续表3
通过分析表3中数据可见,只有P10件的像素重合率明显较低,可以推断该件可能存在装配错误,而且只有P10件的像素减少率偏高,因此基本可以判断P10件出现了漏装现象。
案例二待测深度图像为模型的合成深度图像;装配错误为P0件出现错位。经特征提取及像素分类后获得像素预测图像,如图14所示。

根据式(8)和式(9)计算图14b相对于图14a的像素重合率qz和像素减少率qn,计算结果如表4所示。

表4 P0件错位的比对数据 %

续表4
通过分析表4的数据可见,P0件的重合率相对偏低,可以推断该件可能存在装配错误,而且P0件的像素减少率与其他件相比虽然偏高,但差距不大,因此基本可以判断P0件出现了错位现象;P13件的像素减少率的绝对值虽然较大,但其像素重合率正常,可以判断该件并未出现装配错位,只是由于相邻件出现错位导致其减少率异常。
以上两个案例的待测深度图像均选用模型的合成深度图像,像素识别率较高,仅凭单一视角下的装配体深度图像便可判断出可能存在的装配错误。而对于待测深度图像为实物的真实深度图像,由于Kinect深度图像的采集精度及外界环境影响,导致像素识别率有限,仅凭单一视角下的装配体深度图并不能准确判断装配过程中出现的装配错误。此时,本文选择使用多个深度摄像机,多视角采集装配体深度图像,综合不同视角下的判断结果确定此时的装配错误。
案例三待测深度图像为实物的真实深度图像;装配错误为P3件出现漏装。经特征提取和像素分类后获得像素预测图像,如图15所示。
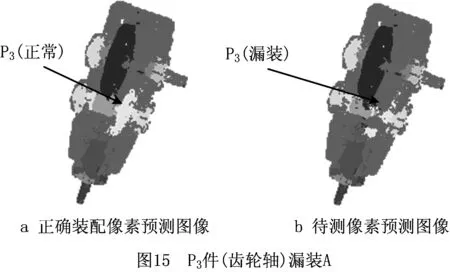
根据式(8)和式(9)计算图15b相对于图15a的像素重合率qz和像素减少率qn,计算结果如表5所示。
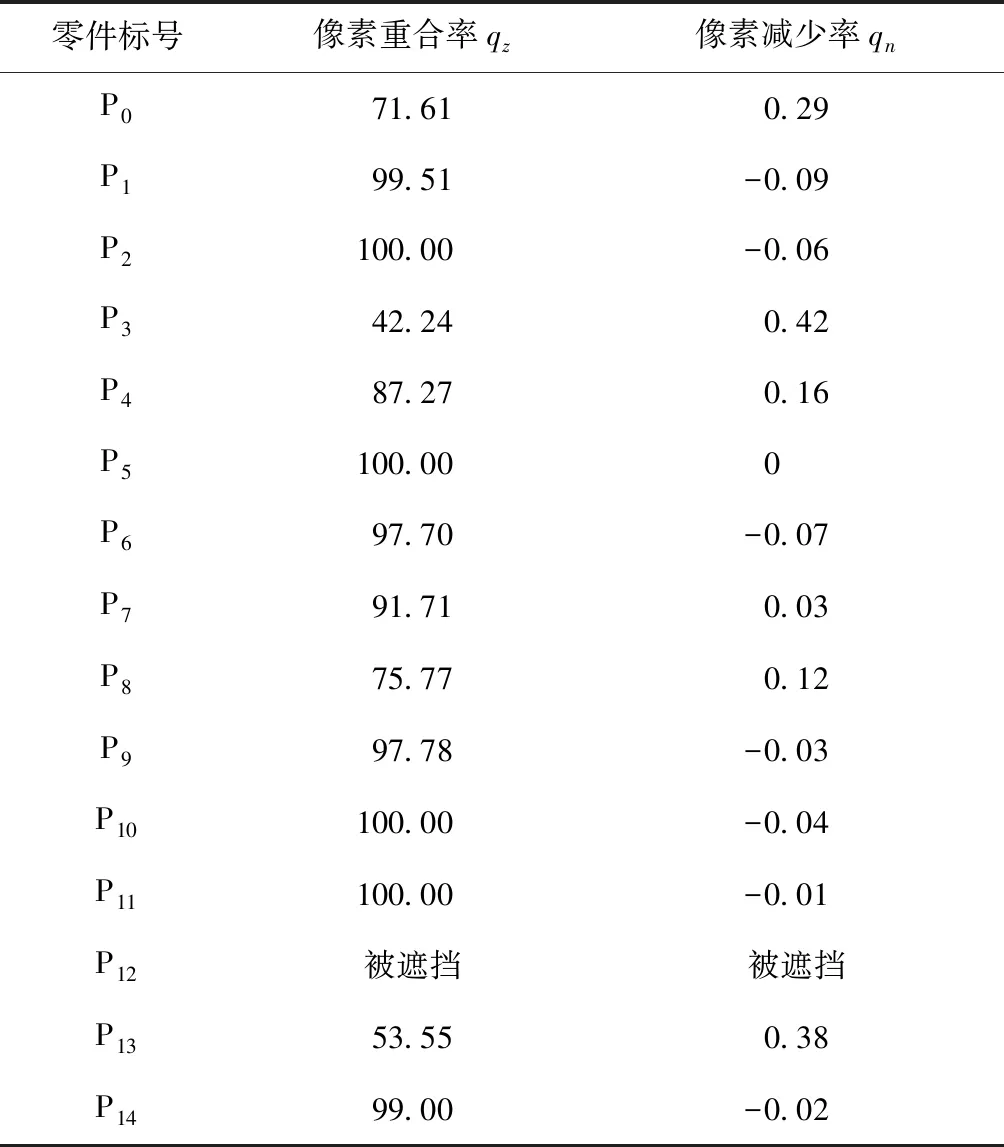
表5 P3件错位的比对数据A %
通过分析表5的数据可见,P3件重合率相对偏低,可以推断该件可能存在装配错误,而且P3件的像素减少率相对较大,因此基本可以判断P3件出现了漏装现象。从表6同样显示,P13件的像素重合率也相对较低,像素减少率也出现了偏大的现象,尽管程度不如P3件,但也有可能存在漏装问题,因此需要进一步判断。图16所示为P3件出现漏装现象但与图15视角不同的像素预测图像。

根据式(8)和式(9)计算图16b相对于图16a的像素重合率qz和像素减少率qn,计算结果如表6所示。

表6 P3件错位的比对数据B %
通过分析表6的数据可见,P3件出现漏装现象,而P13件的像素重合率并无明显异常。综合表6和表7的对比数据,基本可以判断此待测状态下只有P3件出现了漏装现象。
7 结束语
本文针对机械产品装配中零件和装配体的识别、监测问题,提出一种基于深度图像和像素分类的装配体零件识别与装配监测方法。首先,构建了装配体深度图像标记样本集;然后,通过随机森林分类器对装配体深度图像的像素进行分类,对合成深度图像的像素分类准确率可达98.583 3%,对真实深度图像的像素分类准确率可达82.703 3%;最后,对比像素预测图像与颜色标签图像,对装配体各零件进行识别,对比待测状态像素预测图像与正确装配像素预测图像,实现了对装配过程中常出现的零件错装与漏装现象的监测。实验证明,将本文方法用于增强现实装配维修诱导,基本可以正确监测装配过程中零件的装配位置和装配顺序。目前,本文方法仅针对装配环境相对简单且装配效率要求不高的情况,而在实际应用中,装配环境相对复杂,装配监测过程中的遮挡问题将是下一步深入研究的内容。
