针对混合型分类数据改进的K-modes算法距离公式
2020-03-19杨有龙
袁 方,杨有龙
西安电子科技大学 数学与统计学院,西安710126
1 引言
数据挖掘是从大规模数据中发现深层次的、有趣的、新颖的模式的过程,并且数据挖掘的过程具有可描述、可理解、可预测等特性。而聚类则是数据挖掘众多技术中最重要的一种,它将m 维空间中的n个样本点划分为若干个组内相似度较高的簇。从而发掘出包含有用信息的数据簇。例如,通过应用聚类算法,在保险信息中得到一组平均索赔成本很高的交通保险保单持有人。
迄今为止,已经有大量的聚类算法被提出对数值属性的数据集进行聚类。而为了解决分类属性的聚类问题,Huang 拓展了经典的K-means 算法[1-2],使之适用于分类属性的数据集,这就是K-modes 算法。这之后,将分类属性的聚类算法与数值属性的聚类算法相结合,衍生出了混合数据的聚类算法。但大多数的混合数据聚类算法只是关于数值属性与无序分类属性的数据集[3-8],而对于混合分类属性的数据集则研究较少。从本质上讲,聚类是根据不同对象之间的相似度处理数据的机器学习算法。两个对象之间的相似度一般是基于对应属性值的差异,通常用距离函数来度量。对于分类属性数据的聚类算法,很多研究者给出了针对算法改进的距离函数[9-13]。简而言之,目前关于分类属性的距离度量方法有以下几种:
(1)基于Hamming距离的简单匹配度量方法
两个分类属性属性值之间的距离为0 或1。这种距离度量方法往往导致簇内相似性较弱,忽略了分类属性中隐含的相似关系。这种方法的思想已经在许多典型的聚类算法及其衍生算法中得到应用,如原始K-modes算法、模糊K-modes算法和K-prototype算法等[9-13]。
(2)基于粗糙集理论的度量方法
粗糙集理论是Pawlak 于1982 年构建的一种关于分类属性信息系统的很有代表性的机器学习理论[14]。近年来,粗糙集理论被广泛应用于各种聚类和分类算法中[15-16]。Chen 等利用粗糙集理论来处理数据相似性度量中出现的模糊性和不确定性[17]。Jiang 等利用粗糙集理论中的隶属函数概念[9],提出了一种基于隶属函数的检测异常值的方法,并且给出了寻找异常值的算法。Cao 等根据生物学分类和粗糙隶属函数思想[18],将属性值在数据集中的分布作为一个重要信息添加到相似性度量的方法中,最终得到了一种新的距离度量方法。
(3)映射原数据集到新度量空间的度量方法
Qian 等将原始分类数据集转换为对应的欧几里德空间[19],然后在新的度量空间进行聚类。Jian 等定义了一个耦合相似性度量方法,将分类属性的属性值成对地映射为固定值,并且建立起一个关系矩阵[20]。Qian的方法提出了一种有效的度量方法,但度量空间的维数比原数据集要高,使得计算的复杂度随着数据量的增加成指数增长。
以上几种距离度量方法对分类属性的类型不加区分,但是在实际应用中,分类属性有两种不同的类型:
无序分类属性(disordered categorical attribute):其属性值之间没有顺序或等级关系,仅仅只有定性描述,例如性别特征、国家、民族等。
有序分类属性(ordinal categorical attribute):其属性值之间存在明显的顺序或等级关系,这一特性使属性值之间既可以比较是否相等,也可以比较大小顺序。例如学历、成绩等级(优、良、中、差等)等。这种分类属性也被称之为有序属性或序属性。
有序分类属性在现实生活中广泛存在,例如调查问卷以及一些评价系统。原始的K-modes 算法和一些改进的K-modes 算法在运行时并没有对这两种属性加以区分,从而在聚类过程中忽视了有序分类属性所蕴含的序信息[21-22]。例如,在学历这一属性(包含“小学、中学、大学、研究生”)中,可以直观地发现“研究生”这一属性值与“大学”和“初中”这两个属性值的距离是有差别的,在不考虑序信息的算法中,这两个距离是相等的,这样就造成了信息的丢失,所以需要一种新的有序分类属性的距离度量公式来挖掘存在于有序分类属性中的序信息。
本文在原有算法的基础上,基于挖掘有序分类属性序信息的思想,提出了一种新的有序分类属性距离度量方法,最终给出了针对混合分类属性数据的距离公式,并且改进了原有的K-modes算法。
2 K-modes算法
K-modes 算法是对K-means 算法的扩展,适用于分类型数据。该算法用众数代替了均值,并且基于简单匹配的思想,采用Hamming 距离来计算两个样本点之间的距离。
2.1 算法距离公式
设X={x1,x2,…,xn}为有n 个样本点的分类型数据集,其中样本点表示为xi={xi,1,xi,2,…,xi,m},其属性为{A1,A2,…,Am}。 每 个 属 性 Ai的 值 域 为任 意 两 个 样 本 点xi={xi,1,xi,2,…,xi,m}和xj={xj,1,xj,2,…,xj,m},K-modes 的算法中它们的距离为:

其中:

2.2 算法流程
K-modes算法流程如下:
(1)在确定好簇数K 后,随机选取K 个点作为初始质心。
(2)计算每个样本点与K 个质心的距离,将样本点分配给最近的一个质心。
(3)在划分完数据集中的样本点后,更新每个簇的质心。
(4)不断重复步骤(2)和步骤(3),直到算法达到终止的条件(目标函数最小或者簇内样本点不再变化)。
3 改进的距离公式及算法流程
本文对于算法的改进主要是建立了一种新的适用于混合型分类数据的相似度度量公式,从而给出了新的距离公式。新的距离公式分为两部分进行阐述,第一部分为无序分类属性的距离公式,第二部分为有序分类属性距离公式。最后,本文给出一个改进的K-modes 算法距离公式。

3.1 无序分类属性的距离公式
基于粗糙集理论,该部分阐述了一种新的无序分类属性的距离公式。假设数据是以矩阵的形式储存的,其中每一行表示一个样本点。这样的一个数据矩阵同样也是一个信息系统[23-24]。
定义1一般地,一个分类属性的信息系统指的是这样的一个四元组IS=(U,A,V,f),其中,U 为非空的数据集,称为论域(universe);A为非空的属性集合;V 为非空的属性值的集合表示属性a 的属性值范围,即属性a的值域;f:U×A →V,是一个信息函数,它为U 中各对象的属性指定唯一值。
定义 2设一个分类属性的信息系统IS=(U,A,V,f),且P ⊆A,可构造对应的二元等价关系:

则称IND( )
P 为由P 构造的不可分辨关系。
定义3设一个分类属性的信息系统IS=(U,A,V,f),且P ⊆A。对∀a ∈P,x,y ∈U,x,y 之间的相似度定义为:
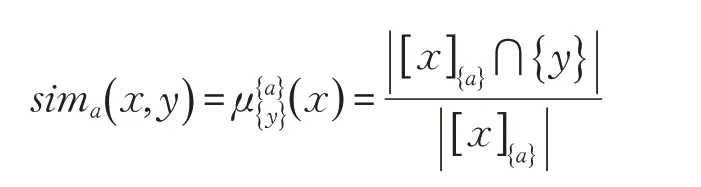
在定义3 中,样本点x 与y 的相似度也就是它们在信息系统中的相对重叠程度,sima( x,y )在本文中改写为:

xi,xj∈U,且,其中:
当f( xi, nomk)=f( xj, nomk)时f( xi, nomk)≡f( xj, nomk)=1
当f( xi, nomk)≠f( xj, nomk)时f( xi, nomk)≡f( xj, nomk)=0
在聚类算法中,利用上述原理计算出的相似度有助于找出组内凝聚更紧密的簇,并且根据得到的相似度,本文定义了如下距离公式。
定义4∀xi,xj∈X,属性集A,xi,xj之间的距离为:

其 中 , Ndisnomk( xi,xj)=1-simnomk( xi,xj), 且
3.2 有序分类属性的距离公式
以上,考虑到有序分类属性的序信息,其距离公式与无序分类属性的距离公式有很大不同。在聚类算法中,有序分类属性的距离公式应该体现其特征,并且在混合数据集中,应该考虑到与无序分类属性的距离公式平衡的问题。基于上述考虑,给出了一种定量描述有序分类属性层级差异的度量方法。首先,将给出一个与之相关的集合的定义。
定义5有序分类属性匹配集(Mate Set of Ordinal categorical Attribute,MSOA)指的是由满足下述条件的无序分类属性nomt构成的一个集合:

其中,ηt为nomt值域的元素个数,δ 为指定有序分类属性值域的元素个数。
根据上述定义5,对于某个有序分类属性ordl,以及xi,xj∈U,建立如下的距离公式:

其中,δl指的是有序属性值域的元素个数,而ηmax指的是无序分类属性的值域元素数的最大值,即

(1)当1 ≤δl≤2
该有序分类属性的值域元素个数最大为2,所以它与无序分类属性并没有显著差异,从而依然以无序分类信息的相似度为标准对该属性进行度量。
(2)当2 <δl≤2ηmax
首先,计算出参数Dod1的值。参数Dod1,即层级差异(difference of degree),是计算有序分类属性距离的一个核心问题。根据下述方法计算得到Dod1。
(1)根据定义5,得到ordl的有序分类属性匹配集MSOA( ordl)。一般情况,MSOA( ordl)包含一到两个无序分类属性。
(2)∀nomt∈MSOA( ordl),∀xi,xj∈U,计算得到所有非0的值,参数Dod1取其最小值,即

(3)当2ηmax<δl
由于有序分类属性的属性值值域元素个数已经大于无序分类属性值域元素个数较多,为了平衡两种属性之间的差异,Dod2的计算公式为:

3.3 改进的距离公式
以上,分别给出了两种属性的距离公式,由此,得到改进的算法距离公式。
首先给出两点间的距离公式,∀xi,xj∈U,距离公式为:

算法在执行时,会不断地生成新的簇,就要计算样本点与质心的距离,一般而言,可以将质心作为数据集中的样本点,依然按照上述距离公式计算。为了提高聚类效果,在上述基础上给出一种新的距离度量公式:
∀xi∈U,zi( i= 1,2,…,k )为相应的簇的质心,其无序分类属性的距离公式与两点间距离公式相同。
∀xi∈U,zi( i= 1,2,…,k )为相应的簇的质心,则xi到质心zi的有序分类属性距离公式为:
(1)当1 ≤δl≤2时
Odisordl( xi,zl)=1-simordl( xi,zl)
(2)当2 <δl≤2ηmax时
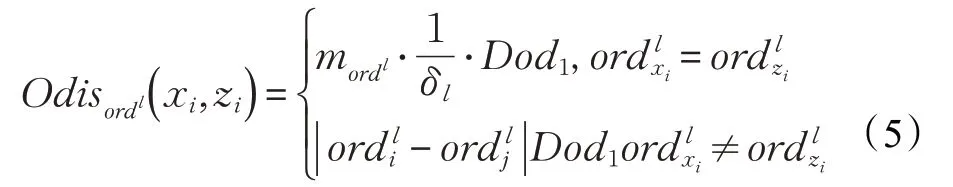
(3)当2ηmax<δl时

依据新给出的样本点到质心的有序分类属性距离公式,给出数据集中任意一点xi到质心zi的距离为:

为了进一步说明新距离公式在算法运行中的实际效用,以下面的例子进行说明。
例1表1 中数据为Car-evaluation 数据集的一部分数据,其中属性a4(汽车的维修费用,属性值为“很高、高、中、低”),属性a5(汽车的价格,属性值为“很高、高、中、低”),属性a6(安全性“高、中、低”)具有明显的顺序等级关系,其为有序分类属性。样本点x6和x7为不同类的质心。

表1 car-evaluation部分数据
应用两种距离公式对数据进行聚类,结果如下:
(1)不区分有序与无序分类属性,都采用无序分类属性距离公式进行距离计算

可以发现,在不区分两种属性的情况下,5个样本点到两个质心的距离都相等,无法给出样本点属于哪个簇。
(2)采用改进的距离公式进行距离计算
首先,计算出3 个有序分类属性的属性值个数为δa4=4,δa5=4,δa6=3, 可 以 得 到 其 相 对 应 的MSOA( a4)={a1},MSOA( a5)={a1},MSOA( a6)={a2},进一 步 计 算 出 3 个 属 性 对 应 的,然后根据公式(5)与公式(7)计算可得:

从而,x1、x2被分配到第一个簇当中,x3、x4、x5被分配到第二个簇当中,分配结果正确。
从例1 可以看出,当考虑有序分类属性的序信息时,不同属性值之间的距离是有差别的,本文提出的距离公式挖掘出了序信息提供的差别化的距离数值,从而使得样本点与质心的距离数值不仅能反应出样本点离某个质心是否更近,也能反应出与其他质心距离之间的比较关系。不考虑序信息的情况下,样本点与质心的距离数值只能反应与某个质心是否更近,而不能反应与其他质心之间的比较关系,因为样本点与其他质心的距离数值不存在距离差异,从而样本点与其他质心之间的距离都是相同的。并且,改进的距离公式还考虑了簇内属性的属性值占比这一权重因子,这些特点有助于获得更强的簇内相似度,使算法可以更有效地将样本点分配给更合理的簇。
3.4 改进的算法流程及算法复杂度分析
由于采用了新的距离公式,并且新的距离公式是基于样本点之间和样本点与质心之间这两种情况给出的,算法的执行流程也与原始算法流程有差异,算法1 给出了改进的K-modes算法的具体步骤。
算法1改进的K-modes算法:
输入:数据集X={x1,x2,…,xn},簇的个数k。
输出:k个类。
初始条件:随机确定k 个样本点作为初始质心z1,z2,…,zk,目标函数值初始化为F(W ,Z )=0;
1.for j从1到n
2.for i从1到k
3.用式(4)计算xj与质心zi之间的距离;
4.endfor
5.endfor
6.if xj与质心zi之间的距离为最小
7.分配xj到第i个簇中;
8.end if
9.更新质心并计算目标函数F( )W,Z 的值;
10.while 目标函数F( )W,Z 未达到终止条件,则循环执行下列步骤:
11.for j从1到n
12.for i从1到k
13.用式(7)计算xj与质心zi之间的距离;
14.end for
15.end for
16.if xj与质心zi之间的距离为最小
17.分配xj到第i个簇中;
18.end if
19.更新质心并计算F( )W,Z 的值;
算法的整个执行过程详细解释说明如下:
(1)在确定好簇数k 后,随机选取k 个点作为初始质心。
(2)步骤1~8,应用式(4)计算数据集中每个样本点与k个质心的距离,将样本点分配给最近的质心。
(3)步骤9 在划分完数据集的每个样本点后,更新质心,并根据得到的质心计算目标函数值。
(4)步骤11~15 依据公式(7)计算数据集中每个样本点与k个质心的距离,再一次划分样本点。
(5)不断重复步骤11~15,直到满足算法终止条件(目标函数值F( )W,Z 最小或簇不再变化),则跳出循环,算法终止。
接下来,给出算法的复杂度分析,在算法执行过程中,参照公式(1)和公式(2),计算两点间无序分类属性距离Ndis的计算复杂度为O( npk)。

参照公式(7),总的距离公式计算复杂度为:

假设迭代的次数为t,则应用改进的K-modes 聚类算法的计算复杂度为:

4 实验结果
本章比较了基于3种不同度量的K-modes算法的实验结果。
4.1 评价指标及数据集说明
真实数据集Car-evaluation、Nursery、Solar Flare、Hayes-Roth、Primary Tumor、Solar Flare、Soybean 均来自UCI数据集(http://archive.ics.uci.edu/ml/)。其中Carevaluation 数据集的类别包含的样本点个数不平衡,对它进行了处理,得到了3 个类内样本点个数平衡的子数据集。这些数据集的属性都是分类属性,并且数据集的属性都包含有序分类属性与无序分类属性两种不同属性,它们都是混合型分类属性数据集。例如,Car-evaluation数据集中的“价格”属性(属性值为“很高、高、中、低”),“维修费用”属性(属性值为“很高、高、中、低”),“安全性”属性(属性值为“高、中、低”)都为有序分类属性。其他属性都为无序分类属性。总的数据集属性情况如表2和表3所述。

表2 数据属性说明

表3 数据集数据说明
同时在算法运行前,对数据集的属性值进行转换,其中有序分类属性都依照第3 章所提出的序数转换方法进行了转换。
4.2 改进算法的稳定性分析

图1 算法稳定实验分析
为了测试算法的稳定性,使用Nursery 数据集进行实验。该数据集包含12 960 个样本点,并且包含8 个属性。本文测试了两种情况下的算法稳定性,图1(a)表明了算法与数据集的数据量相关的稳定性,图1(b)表明了算法与给定的簇数相关的稳定性。从图1 可以看到运行时间随着参数的变化呈线性递增,这说明改进的算法在能达到更高精度的同时也具有良好的稳定性。
4.3 改进算法的有效性分析
比较了原始K-modes 算法、Cao 提出的K-modes 算法和本文改进的K-modes算法的有效性。
实验过程中,对每个数据集,分别运行了100 次程序,并计算了每一次实验的AC 指标,最后计算100次实验结果的平均值,得到了算法的平均正确率,用来比较算法的优劣。在实验中,算法的簇数k 为数据集的类别数量,参数γi的值为1,

表4 聚类结果正确率比较表
根据表4 呈现的实验结果可以看出,在这8 个数据集中,本文提出的改进算法获得了良好的聚类效果。尤其在Nursery、Solar Flare、Car-evaluation(1)、Car-evaluation(3)这4 个数据集上表现出了相当优异的聚类效果。其中,在数据量最大的Nursery数据集上,准确率提高了2%以上,在类数最多的Solar Flare 数据集,准确率提高了10%以上。同时求得8 个数据集的聚类结果的平均值,也高于其他两种算法的平均值。
结合数据集本身的特点,对实验结果进行如下分析。首先可以看出,在正确率都高于同类算法的几个数据集中,有序分类属性的个数所占属性总个数的比例较高。在Car-evaluation 这个数据集上,有序分类属性的个数占到了属性总个数的1/2,所以,尽管Car-evaluation(3)包含4 个不同类,但是算法在该数据集上的准确率也是最高的。
由于改进的距离公式不仅考虑到了有序分类属性蕴含的序信息,也考虑到了簇内属性值所占比例,这使其能反应出样本点与各个质心距离之间的比较关系,随着类别数的增加,聚类的正确率也随之增加,例如:Car-evaluation(1)与Car-evaluation(2)的类别数都是2,它们的准确率都在0.70 左右波动,而Car-evaluation(3)具有4 个类别,正确率却达到了0.79;Primary Tumor 数据集有17 个属性,有2 个分类属性,分类属性的占比为2/17,较其他数据集的有序分类属性个数占比较低,但因为其类别数为5,在数据类别数里较高,所以其聚类准确率依然可以达到0.66,同样,Solar Flare 数据集中有序分类属性的占比也较低,但由于其数据类别达到了6个,是最高的数据类别数,所以算法的聚类准确率在该数据集上也达到了0.74。
而对于Soybean 数据集,首先,有序分类属性个数的占比为2/35,远低于其他数据集;其次,类别数也只有4个,相比于其他数据集的类别数并不算高,从而算法的聚类效果较差,较之其他两个算法,本文提出的改进算法的聚类准确率也只比其中一个算法的准确率高。
通过以上对实验数据的分析,可以看出,本文提出的新的距离公式和改进的相应算法,在混合型的分类属性数据集上表现出了良好的性能,这说明改进的距离公式和算法更加适合聚类混合型分类属性数据。
5 方法评价与改进
K-modes 算法在分类属性聚类中有着广泛的应用,而距离公式对聚类算法的有效性起着至关重要的作用。本文基于挖掘有序分类属性的序信息的思想,建立了一种K-modes 算法的距离公式。新的距离公式解决了Kmodes 算法处理这类数据集时存在的两个主要问题:如何构建针对有序分类属性的距离公式,从而有效挖掘有序分类属性包含的序信息;如何在总的距离度量公式中,有效平衡两种不同类型属性的距离公式的量纲问题。
尽管改进的距离公式实验效果良好,并且扩大了算法的数据集适用范围,但是还有两个问题值得深入探究:一是可以对有序分类属性任意两个相邻属性值间的等级差异有更深层次的讨论。二是对于属性权重γi取值的讨论,在某些数据集中,有序分类属性或许会贡献更大的聚类作用,这时应该赋予更大的权重,但是如何在初始状态下确定有序分类属性的权重,是一个值得讨论的问题。
6 结束语
大多数现有的分类数据聚类算法的距离公式都忽略了其中的有序分类属性,从而在聚类过程中遗漏了这一重要信息。而有些算法注意到了这个问题,但是并没有建立起合理的有序分类属性的层级差异,或者给出的层级差异计算公式粗糙,对两种属性的距离公式计算数值的平衡性造成了较大的不良影响。本文在前人的基础上,对K-modes 算法的距离公式进行了改进,提出了一种切实可行的发掘序信息的距离公式,并且改进的距离公式没有造成计算的不平衡问题。改进算法对混合型的数据根据属性的差异,定义了不同的距离公式,同时给出了总的混合型数据的距离公式。实验表明,改进的距离公式和聚类算法对于解决混合型分类属性的数据集聚类问题给出了一个良好解决方案。现实生活中,大量问卷调查数据和网络平台的注册信息数据都属于混合分类属性数据,针对这类数据的聚类分析,本文的方法有望给出一个有效的解决方案。
