音视频双模态情感识别融合框架研究
2020-03-19宋冠军张树东卫飞高
宋冠军,张树东,卫飞高
首都师范大学 信息工程学院,北京100048
1 引言
人工智能的兴起促使人机交互领域成为当前研究的重点领域,而情感识别在模式识别中具有广阔的应用前景,同时也是实现人机交互的关键技术之一[1]。对于单模态的情感识别研究,例如单一地对语音信号、心电信号、人脸表情、身体姿势等其他生理信号的研究都已经取得了一定的进展。但是人脑情感信息源的多样性和单模态情感识别的不确定性等原因决定了单模态情感识别准确率不高。因此,结合多种模态构建多模态情感识别框架就成为了提高情感识别框架性能的有效手段[2]。多模态情感识别研究中多模态融合策略在充分利用了语音、面部表情等多个模态的互补信息的同时也消除了单模态的不稳定性,从而在一定程度上提高了情感识别的准确率。在人类众多的情感信号中语音信号和面部表情信号含有绝大多数的情感信息,故而大多数多模态情感识别研究集中于语音面部表情双模态情感识别[3-6]。
2011年德国慕尼黑工业大学举办了第一届多模态情感识别的竞赛(Audio/Visual Emotion Challenge,AVEC),该竞赛针对音视频通过机器学习方法进行情绪分析[7],之后该会议以每年一次的频率召开,推进了多模态情感识别研究的进展[8-13]。而随着计算机硬件计算能力的提高,使得深度学习方法应用在多模态情感识别研究上成为了可能,例如卷积神经网络(Convolution Neural Network,CNN)[14]、长短时记忆网络(Long Short-Term Memory,LSTM)[15]等多种深度学习模型,被广泛应用在情绪识别当中。而在多模态情感识别研究中,根据融合不同模态的数据时所处阶段,目前多模态特征融合策略主要分为特征层融合[16-17]和决策层融合[18-19]两种,深度学习模型在这两种融合策略中都有应用。其中决策层融合的方法优点在于不需要语音信号和面部表情信号之间严格的时序同步,而且解决了不同模态的特征可靠性不同等问题。例如,Sahoo 等人在文献[18]中提出一种基于决策规则的音视频双模态决策层融合的情感识别算法,文中首先单独进行语音和面部表情的单模态识别并进行测试,然后设置决策规则,用以在决策层融合视听信息以识别情绪。文献[20]采用核熵成分分析(Ker‐nel Entropy Component Analysis,KECA)方法和决策层融合方法研究人脸表情和语音双模态情感识别,在两个常用的情感库上都取得了较高的双模态情感识别率。文献[21]中采用通用背景模型加上最大后验概率法再结合openSMILE 特征提取方法对音视频信息进行特征提取并进行了决策层融合,然后在eNTERFACE 数据库上进行验证,取得了77.50%的识别率。但是决策层融合往往在训练过程中数据损失量大,这就对识别准确率造成了影响。于是在保证语音信号与面部表情信号时序的绝对同步之下一些特征层融合的方法被提出。例如,在文献[22]中,提出采用CNN 加上openSMILE 工具的方法对音视频以及一些文本进行了特征提取,并在特征层进行了融合,在IEMOCAP 数据库上进行验证取得了76.85%的识别率。Tzirakis 等人在文献[23]中提出了一种端到端的双模态特征层融合算法,其中语音和面部表情模态分别使用CNN 和50 层的ResNet 网络提取情感特征,然后对双模态特征进行直接级联,最后使用两层LSTM 模型进行时序建模,然后以端到端的方式训练系统。
然而,特征层融合的框架仍然有一些不足。首先,Sayedelahl 在文献[24]中证明如果训练样本的数量相对较少,增加特征的集合可能导致情感识别准确率的降低。另外直接级联后可能产生特征高维灾难、不同模态的特征可靠性不同等问题。以上都是在双模态特征直接级联之后会导致情感识别准确率降低的可能因素。其次,语音片段或面部表情信号包含有大量时序信息,而单向LSTM 选择性地记忆先前的时序信息,这就不能更有效地学习全局信息。
针对上述问题,本文以音视频双模态情感识别为对象设计了一种针对特征层融合的情感识别框架,如图1所示。

图1 音视频双模态特征层融合框架流程图
在对语音信号和视频信号分别进行简单预处理之后,采用基于先验知识的特征提取方法对语音信号进行语音特征提取,而在面部表情特征提取方面,本文采用VGGNet-19 网络代替传统的ResNet 网络提取面部表情特征。随后对所得到的音视频特征都进行基于零均值标准化的特征归一化处理以减少训练时间。然后在特征层将经过时序绝对同步之后的音视频特征进行直接级联,完成双模态特征融合。为了避免由于直接级联融合特征可能产生的高维灾难,本文采用PCA 对融合之后的特征进行降维处理。为了在对时序信息建模的同时考虑上下文信息,本文采用BLSTM替代传统的LSTM进行建模,得到最终的情感识别结果。
2 音视频特征的预处理和特征提取
2.1 语音信号预处理及特征提取
首先因为设备采集到的语音信号为模拟信号,所以在特征提取之前要将其转化为数字信号,这样才能继续进行后续处理。其次采集所得语音信号中混杂的环境和录音设备带来的无关噪声会降低情感识别准确率,为提高情感识别准确率以及模型泛化能力,在情感特征提取之前,先对语音信号进行预处理操作,然后再进行特征提取。
步骤1将语音样本下采样到16 kHz,量化位数16 bit。这样使得降低噪音干扰和保留有效情感信息两方面要求都得到了满足。
步骤2通过高通滤波器中一阶数字滤波器进行语音预加重处理达到抑制低频信号提升高频信号的目的。传递函数及滤波函数如式(1)和式(2)所示:

其中,α 为预加重系数(0.9 ≤α ≤1),本文设置α 为0.94。X(n)为第n时刻的语音采样值,Y(n)为处理后的信号。
步骤3为了保障信号的平稳性,使用窗口函数对语音信号进行分割,分割后的片段为语音帧。为了保证语音信号的平滑过渡,相邻语音帧之间有一定的重叠。这里采用avec2014竞赛[10]中的标准,帧长为3 s,帧移为1 s。
语音信号使用滑动窗口与窗口函数加权的方式进行分帧,常用的滑动窗口函数有矩形窗和汉明窗两种,矩形窗和汉明窗的窗函数的表达式如式(3)和式(4)所示:

在窗函数的表达式中,n代表第n个采样点,N 为语音帧内采样点的数量。通过对两个窗函数进行对比,发现汉明窗的主瓣宽度比矩形窗更宽。而主瓣较宽,语音信号起始和结束端的坡度较缓,窗口里信号将更加平稳,故选取汉明窗口函数进行语音信号的分帧操作。
步骤4为避免受语音样本中无声片段影响而训练时间增长,使用双门限端点检测法对语音信号的起点与终点进行判断,从而对语音样本无声片段进行剥离。其中使用基于短时能量的端点检测法用来确定语音的起止点,其表达式如式(5):
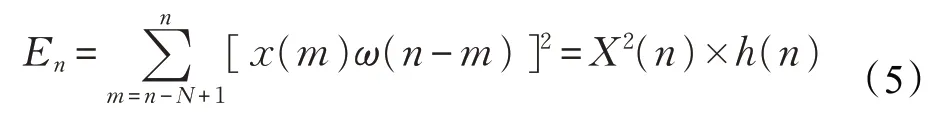
其中,X(n为)语音信号,h(n)=ω2(n),ω(n)为窗函数。
使用基于过零率的端点检测法[25]用来确定清辅音与无声信号的分界点,其表达式如式(6):

其中,sgn[]为符号函数。
步骤5语音信号预处理之后,通过对预处理之后的语音信号中的特征参数进行提取和分析,得到语音信号特征。特征提取时,采用基于先验知识的特征提取方法提取特征需要借助专家先验知识经验选取含有情感信息的韵律学、谱和声音质量等声学情感特征集合[26]。本文首先采用基于先验知识的特征提取方法对韵律学、谱和声音质量等低层次特征进行特征提取,再借助openS‐MILE[27]进行全特征提取。参照avec2014 竞赛[10]中的特征集合作为参考进行情感特征提取,该特征集合具体特征种类参数见表1。
对语音帧序列进行特征提取之后,得到不同维度的语音情感特征。因为当不同特征参数取值范围不同时情感模型训练将花费大量时间,所以对特征进行基于零均值标准化的特征归一化,其表达式如式(7):

其中,X 为样本的特征矩阵,μ为均值向量,σ 为均方误差。

表1 特征种类
2.2 视频帧预处理及特征提取
因为视频中部分图像存在人脸遮挡现象会对模型训练产生一定的干扰,其次因为视频中部分人脸图像转动幅度大会使人脸特征提取速度变慢。针对这些问题,需要在情感特征提取之前,先对视频帧进行预处理操作,然后再进行特征提取。
步骤1对数据库中视频流使用OpenCV[28]工具将其转变为视频帧序列,之后剔除对人脸被遮挡的图像。
步骤2面部表情情感识别需对人脸面部的纹理特征进行特征提取与分析,但是实际采集的视频流不仅包含面部而且包含人肩部以上图像,所以直接对视频帧操作时识别准确率不高而且花费大量训练时间。为解决上述问题,同时也为了方便后续视频帧的特征提取,使用Dlib[29]工具进行面部图像尺寸归一化处理,如图2所示。

图2 视频帧面部图像归一化处理
步骤3对采集过程中人脸位置不正的图片进行人脸对齐操作。这里使用68 个landmark 点(人脸关键特征点)对人脸进行标记,然后利用标记进行人脸对齐操作,如图3所示。

图3 landmark点标记人脸图片
对所有标记landmark 点取均值得到头部标准姿势模板,其他图像以该图像为模板进行对齐操作。这里以两个外眼角点(36,45)和鼻尖点(30)为基准,对所有图像做仿射变换。这样转正后人脸特征点位置相近,方便后续进行特征提取操作。
步骤4预处理之后对面部表情特征进行提取。深度卷积神经网络VGGNet[30]泛化性好常用来提取图像特征,并有使用较小卷积核、增加网络深度可以提升分类与识别效果的特性。这里使用VGGNet-19[30]提取面部表情的情感特征,使用常规参数进行网络结构初始化,其结构如图4所示。
VGGNet-19有5段卷积,每段卷积有2~3个卷积层,每段卷积后边会紧跟最大池化层(maxpool)。其中卷积核也称滤波器,作用是提取局部特征,每个卷积核都会映射出一张新的2D 图像。池化用来保留最显著的特征,具有提升模型畸变容忍的能力。得到不同维度的面部表情情感特征。同样对提取后特征使用零均值标准化的方法进行特征矩阵归一化处理,其表达式同式(7)。
3 音视频特征直接级联并采用PCA 降维以及BLSTM网络建模
步骤1为进行音视频双模态特征层融合,需要满足语音信号和面部表情视频帧时序的绝对同步。对于语音模态,语音信号被使用窗口函数分割后,每个3 s的语音片段对应一个语音特征向量,片段间1 s 的重叠。面部表情视频流30 帧/s,每一帧对应一个面部表情的特征向量。以语音片段的时间窗口为基准,对时间间隔里所有视频帧的特征向量取均值作为时间片段内所有帧的特征向量。这即满足了语音信号和视频帧信号的时序同步,同时也对所有帧的视频帧的信息进行了充分利用。然后对语音信号特征和视频信号特征进行直接级联,级联之后每个3 s 的音视频片段对应3 s 语音片段维度数加上90 帧面部表情维度数的维度总数的特征向量。
步骤2当训练集合的样本不是足够大时,特征参数过多会降低情感识别精度,所以选择对特征进行降维操作[24]。PCA[31]算法将可能相关的特征向量进行正交变换,并将变换后的特征向量按照方差递减的顺序进行排序,选取方差较大的特征向量作为降维后的特征参数。虽然特征降维后特征有一定的数据损失,但特征之间的冗余得到了降低,从而抽取出最有代表性的情感特征。同时,PCA 降维避免了训练集合的样本数量不充足时,增加特征集合可能降低情感识别的准确率的问题。使用PCA 无监督学习的方法进行特征降维,以90%作为特征向量方差的阈值。
步骤3当人类情感发生变化时,脸部的眉毛、鼻子、嘴等器官周围的运动单元也会随之运动,这种变化具有连续性,所以面部表情信号和语音信号具有时序性。而且双模态识别过程中,样本信息既包括先前的语音信号和视频帧又包括后续的语音信号和视频帧,而且使用上下文信息有助于更好地学习全局信息。LSTM 只捕获了上文信息,文献[32]提出的双向RNN模型同时考虑了历史信息和未来信息。文献[33]用LSTM记忆单元替代BRNN 中的隐藏层神经元,构建了BLSTM 模型,该模型有效地利用了序列数据的上文信息和下文信息,因此采用能选择性记忆上下文时序信息的BLSTM进行模型构建。其结构如图5所示。

图4 VGGNet各级网络图结构

图5 BLSTM结构图
图5 中包含两层隐含层单元,第一层传播方向为从前往后传播,用来学习上文信息;第二层传播方向为从后往前传播,用来学习下文信息。在t 时刻,当前时刻的输入值、上文信息、下文信息共同作为输入值,对三者的信息进行判断可以得到第t 时刻的输出结果。
经过BLSTM建模之后,特征层融合框架构造完毕。
4 实验及结果分析
4.1 情感数据库
情感识别研究要建立在情感数据库之上,情感识别框架性能也要通过情感数据库来体现。为了评估设计的音视频双模态情感识别融合框架的性能,本文在AViD-Corpus 数据库和SEMAINE 数据库上进行实验,并与几种不同的双模态特征层融合框架进行性能对比。
AViD-Corpus 数据库是由PPT 引导的人机交互任务,交互内容包括两部分:Northwind 和Freeform。数据采集设备为网络摄像头和智能手机,总共采集了340 个音视频文件。该库收集自292 个说话人,总时长240 h。其中音视频片段时长20~50 min,平均时长25 min。说话人年龄分布在18~63 周岁,平均年龄31.5 周岁,年龄标准方差12.3。本文使用Northwind 部分进行实验。其中,音视频文件总共150 段,每段时长35~45 s 不等。语音采样频率41 kHz,量化位数16位;视频采样帧率为30帧/s,像素为640×480。avec2013竞赛对该库的Arousal和Valence维度进行了标注,avec2014竞赛对Dominance维度进行了补充标注,标注范围[-1,1]。
SEMAINE数据库是由贝尔法斯特女王大学采集的英文音视频维度情感数据库。该库由四种性格的(温和、外向、生气、悲伤)工作人员模拟机器工作的环境与20位被测者(8男,12女)进行交互的方式收集。SEMAINE数据库在专业录音棚内采集,采集时长约7 h,音视频文件时长为3~5 min。其中,语音信号采样频率48 kHz、量化位数24 bit;视频帧采样频率50帧/s、像素值为580×780。该库含有95 个音视频文件,在avec2011 和avec2012 竞赛中该库Valence、Arousal、Power、Expectation 和Intensity维度被进行了标注,标注范围[-1,1]。
4.2 实验环境
本文实验硬件环境为PC机,有8块8 GB内存,操作系统为Ubuntu14.04.5,搭载Linux 内核,同时借助GeForce GTX 1080 GPU进行加速处理。
将音视频文件按照7∶1∶2 比例划分为训练集合、验证集合、测试集合三部分。其中AViD-Corpus 数据库数据分为训练集合105个,验证集合15个,测试集合30个。SEMAINE 数据库数据随机选取90 个音视频文件分为训练集合63 个,验证集合9 个,测试集合18 个。选取Valence和Arousal维度情感进行识别。
使用设计的音视频双模态情感识别特征层融合框架对AViD-Corpus数据库和SEMAINE数据库的Valence和Arousal 维度情感进行识别,之后使用两个维度情感识别的RMSE和PCC的均值对识别结果进行衡量。
4.3 实验结果分析
为了验证本文提出的基于特征层融合的双模态情感识别框架的有效性,将本文方法(方法(5))与文献[23]提出的双模态情感识别方法(方法(1))进行了对比,并设计了几种不同的对照方法(方法(2)、方法(3)、方法(4)),以下为几种不同方法的具体细节及实验结果分析。
方法(1)ResNet+LSTM:参照文献[23]提出的情感识别框架,面部表情特征采用ResNet 网络提取,而语音特征使用工具包openSMILE 提取,然后对双模态特征进行直接级联,最后使用两层LSTM模型进行时序建模。
方法(2)ResNet+LSTM+PCA:在方法(1)中传统的情感识别框架基础引入PCA 降维,语音和面部表情模态分别使用工具包openSMILE 和ResNet 网络提取情感特征,然后对双模态特征进行直接级联并采用PCA 降维,最后使用两层LSTM模型进行时序建模。
方法(3)VGGNet-19+LSTM+PCA:语音和面部表情模态分别使用工具包openSMILE 和VGGNet-19 网络提取情感特征,然后对双模态特征进行直接级联并采用PCA降维,最后使用两层LSTM模型进行时序建模。
方法(4)ResNet+BLSTM+PCA:语音和面部表情模态分别使用工具包openSMILE 和ResNet 网络提取情感特征,然后对双模态特征进行直接级联并采用PCA 降维,最后使用BLSTM模型进行时序建模。
方法(5)VGGNet-19+BLSTM+PCA:本文方法,即语音和面部表情模态分别使用工具包openSMILE 和VGGNet-19网络提取情感特征,然后对双模态特征进行直接级联并采用PCA 降维,最后使用BLSTM 模型进行时序建模。
不同方案下实验结果如表2和表3所示。

表2 AViD-corpus数据库实验结果

表3 SEMAINE数据库实验结果
在表2 和表3 两个不同数据库的对比实验中,通过对比ResNet+LSTM 和ResNet+LSTM+PCA 的实验结果发现加入PCA 降维之后实验结果中RMSE 得到一定降低,PCC 得到一定提高。这证明了,PCA 降维在此两个数据库上对实验结果有一定改善。
通过对比ResNet+LSTM+PCA和VGGNet-19+LSTM+PCA 以及对比ResNet+BLSTM+PCA 和VGGNet-19+BLSTM+PCA 可以看出使用VGGNet-19 对面部表情进行特征提取的RMSE要低于使用ResNet,使用VGGNet-19 进行面部表情进行特征提取的PCC 要高于使用ResNet。
通过对比ResNet+LSTM+PCA 和ResNet+BLSTM+PCA以及对比VGGNet-19+LSTM+PCA和VGGNet-19+BLSTM+PCA 可以看出使用BLSTM 进行时序建模的RMSE 要低于使用使用两层LSTM,使用BLSTM 进行时序建模的PCC要高于使用两层LSTM。
这证明了,在使用PCA 降维的四个实验中,三种基于VGGNet-19 或者BLSTM 的框架有效性和准确性均优于传统的ResNet+LSTM框架。
综上所述,本文设计的语音和面部表情双模态情感识别融合框架在RMSE 和PCC 两个评估指标上均优于其他对比方法。因此本文实验结果验证了本文提出的音视频双模态情感识别融合框架的有效性和准确性。
5 结束语
为了解决音视频双模态情感识别框架准确率低可靠性差的问题,本文基于传统的情感识别方法,在面部表情特征提取中采用了VGGNet-19 的方法,并在音视频特征级联之后融入PCA 降维,最后结合BLSTM 网络以同时考虑上下文信息,构建情感识别特征层融合框架,使用AViD-Corpus 数据库和SEMAINE 数据库对该算法进行验证。结果显示,本文提出框架对比现有框架,RMSE 得到下降,PCC 得到提升,有效提升了情感识别框架的准确性和可靠性。
