流量的集成学习与重采样均衡分类方法
2020-03-19顾兆军赵春迪周景贤
顾兆军,吴 优,2,赵春迪,3,周景贤
1.中国民航大学 信息安全测评中心,天津300300
2.中国民航大学 中欧航空工程师学院,天津300300
3.中国民航大学 计算机科学与技术学院,天津300300
1 引言
网络流量分类是网络监管的基础工作,随着网络环境的不断扩张发展,网络信息监管、服务质量控制以及异常检测等工作都需要基于流量分类来提高效率、降低成本。传统的流量分类方法基于深度包检测(Deep Packet Inspection,DPI),通过人工提取数据包中的特征序列并形成特征库,而随着流量种类和数量的增加,特征库的维护成本不断提高,同时这种方法无法应对未知和加密流量[1],因此,基于机器学习的流量分类方法开始受到关注。机器学习是一类分类回归算法的总称,其核心思想是通过现有数据形成一个模型,从而实现后续数据识别。机器学习算法已经在多个领域得到了应用,并取得了卓越的成果[2]。

图1 RES-LGBM流量分类过程
基于机器学习的网络流量分类研究起步于2005年,Moore 等人[3]完成了网络流量的收集处理,从流量数据包中提取出了248 种用于训练的数据特征,并使用改进核函数的朴素贝叶斯算法(NBKE)对流量进行了分类,这一系列工作为此后的很多流量分类研究提供了参考。之后的研究中更多着眼于解决流量分类中特定的的问题,如算法提速[4]、新型协议的识别[5],以及分类机制的改进[6]等,还包含了流量数据的不平衡问题。
数据不平衡即样本中不同类别的数量差距较大,该问题于各类应用场景中普遍存在,是机器学习领域的十大问题之一[7]。由于某类样本占比较大,在训练过程中算法会更偏重该类的分类效果,进而导致模型产生偏向性,即对多数类的分类效果较好,但对少数类效果较差。在网络流量数据中,正常样本较多,异常和恶意样本较少,数据不平衡的问题十分突出,故需针对该问题进行优化,以提高少数类样本识别率。
目前在机器学习领域中主要使用特征选择的方法,基于代价敏感的方法以及重抽样的方法来处理样本不均衡问题[8]。Zhong 等人[9]于2009 年将重采样同决策树和神经网络结合,对P2P流量进行了分类,研究结果证明了重采样方法在网络流量分类问题中的有效性。Liu等人[10]则于2012 年利用BFS 特征选择方法结合各种机器学习算法进行了流量分类,其中决策树算法和BFS结合(BFS+DT)可以取得良好的分类效果,之后还于2014年[11]对三种数据不平衡的修正方法进行了对比,并以此说明了重采样相对于另外两种方法的优势。Dong 等人[12]于2016 年研究了基于多层概率神经网络(MPNN)的流量分类,取得了较好的效果。孙兴斌等人[13]于2017年使用基于不确定性的混合型特征选择(FSMID)方法,在一定程度上消除了数据不均衡带来的影响。王勇等人[14]在2018年基于卷积神经网络算法(MMN-CNN),提出了一种无需进行特征提取的流量分类方法。上述研究由于机器学习算法本身存在一定缺陷,无法取得理想的分类效果,特别是对于少数类的分类效果较差。针对该问题,本文提出结合重采样的梯度增强树算法RESLGBM(Resampling in Light Gradient Boosting Ma‐chine),利用二者的优势互补,实现了更加精确的流量分类。
2 基于集成机器学习的流量分类方法
集成学习算法的原理是将多个弱分类器进行结合,即使每个分类器的准确率不高,也能形成一个效果较强的分类器。集成学习算法的决策结果由多个分类器共同形成,因此能够有效避免传统算法存在的过拟合问题,该决策机制也有效地削弱了噪声的影响[15]。
采用RES-LGBM 对网络流量进行分类的核心是对数据进行预处理,并采用重采样算法修正数据的不平衡性,再利用LightGBM 算法对处理后的数据进行训练,实现更准确的流量分类,其过程如图1 所示。为进行本次实验研究,需要使用从真实网络环境中采集,并且已标注类别的不均衡流量样本。
2.1 机器学习在流量分类中的应用
机器学习方法通常使用样本的特征向量作为输入,并以样本类别作为输出,而在流量分类中,可用数据均为流量数据包,该数据无法直接作为算法的输入,因此需对其进行一定的加工处理。流量分类问题中最有价值的信息为几乎包含于IP数据包的报头中,其格式如图2所示。根据传输协议的工作方式,可以确定源IP 地址、目的IP 地址、源端口号、目的端口号以及传输层协议均相同的数据包属于同一个流,通过将同一个流中的数据包头信息进行提取、整合和计算,便能得到一系列数据特征,作为机器学习算法的输入。使用这类特征的优点在于,在数据处理过程中只涉及数据包头,没有利用数据包本身的内容,从而避免了侵犯用户隐私。

图2 IP报头格式
本文使用的数据格式如图3,每条数据代表一个网络流,共有248种特征。
2.2 LightGBM算法

图3 处理后数据格式
LightGBM(LGBM)属于梯度增强树算法[16],是集成学习算法的一种,该算法主要优化了运行速度,同时几乎没有降低算法准确率。梯度增强树算法集成了多个回归树,回归树由决策树算法衍生而来,其节点的分裂方式和决策树相同,但对每个叶子节点赋予了分值。LightGBM 的决策机制如图4 所示,每棵树的生成过程中都随机使用部分样本和部分数据特征进行训练以确保树的多样性。通过将集合中多个回归树的分值相加,即可得到最终的分类结果[17]。由于需要对多个子树进行训练,梯度增强树算法的运行速度低于传统的决策树,而LGBM 则通过一系列优化手段,使其运行速度到了很大提升,但当数据样本出现类间不平衡时,仍会导致其产生分类偏差,需要针对该问题进行优化。

图4 LightGBM分类原理
2.3 重抽样算法
重抽样就是利用数据之间的相关性,通过生成或删除样本的方式来改变样本比例,可分为过采样、欠采样以及将二者相结合的方法。欠采样方法是根据某种规则,剔除部分多数类样本,该方法的优点是可以在修正数据分布比例的同时降低运算量。缺陷在于使用欠采样可能丢失部分重要信息。与其相对的过采样方法是指根据原有样本生成数据来增加少数类样本的比例。使用重采样的方法能够使得少数类的比例增加,从而保证该类样本在多数子树的生成过程中得到足够的训练。虽然一些研究者认为这种方法会改变样本的分布,但树算法的理论基础是直接对分类可能性进行建模,而无需对样本分布进行假设,故样本分布的改变并不影响LG‐BM的分类效果。本实验中使用的重采样算法有ROS(随机过采样)、RUS(随机欠采样)以及SMOTE-Tomek 算法。
(1)SMOTE算法
SMOTE 算法[18]利用了样本空间中同类样本距离相近的特点,以现有数据为参考,使用插值的方式生成数据。
假设需要将某类样本的数量提升为原来的N 倍,对其中的每个样本,假设其向量为x,SMOTE 算法寻找与x 距离最近n 个的同类样本并随机选择一个样本xk,k ∈{1,2,…,n},并生成一个随机数ξ,合成新样本:
x′=x+ξ·(xn-x)
重复N-1次,即可使样本量达到目标数量。SMOTE算法多用于解决样本量不足的问题,当生成的数据能够拟合真实分布时,将取得良好的效果。
(2)Tomek-Link
Tomek-Link 描述了一种样本间关系[19],其定义如下。
定义1假设样本空间为X,样本间距离为d,对于任意的xi,xj∈X,若不属于同一类别,且对于任意的xk∈X,都有d(xi,xk)>d(xi,xj)且d(xj,xk)>d(xi,xj),则称(xi,xj)为一个Tomek-link对。
可以认为一个Tomek-link 对中的两个样本中存在噪声,会对模型的训练过程产生干扰,可以选择剔除其中的多数类样本。相对于单独使用Tomek-link 欠采样,将SMOTE 与Tomek-link 结合,可以在删除更少样本的条件下达成样本量平衡,降低信息损失。
LGBM 在与重抽样结合时分类效果能够得到显著的提升。如图5 所示,LGBM 算法中为了保证子树的多样性,在每个子树的训练过程中会随机抽取样本。当数据存在类间不平衡时,直接进行训练时,由于少数类样本在每次的训练中被抽取的概率较低,会使得大部分子树无法对少数类样本进行有效学习,使得子树的结构单一,缺乏对少数类的准确分类能力。而使用重抽样算法后,不同类样本会以相当的概率被抽取到,子树可以生成更多分支,有效提高分类效果。
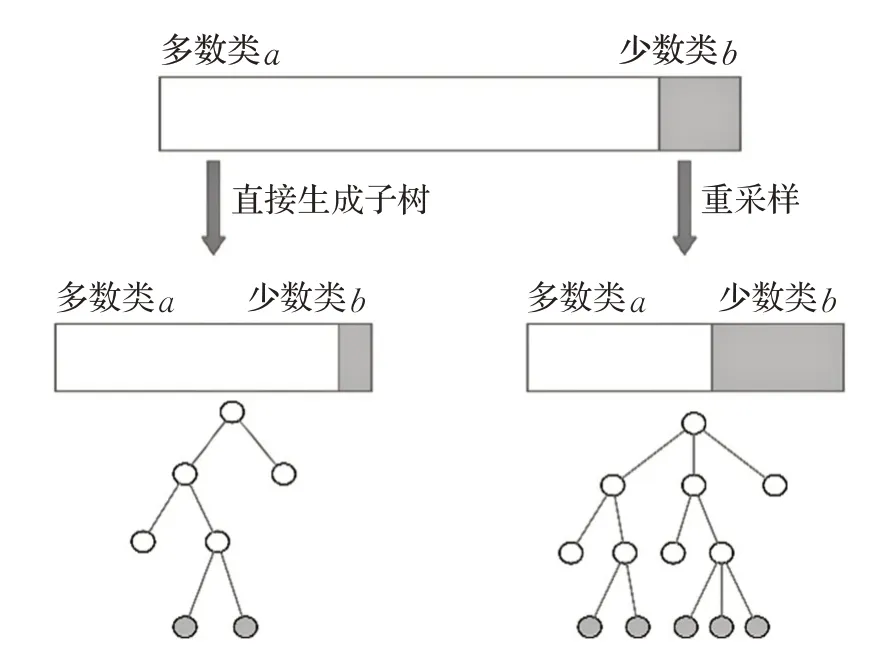
图5 重抽样对LGBM的改进作用
3 实验结果分析
本文中实验利用Python编程实现,实验程序运行平台为DELL台式机,系统为Ubuntu 64 bit,CPU为2.9 GHz Intel Core i5,内存为8 Gb 1 867 MHz DDR3。实验比较了LGBM与其他算法各自的特点,后确定了模型参数和最优特征集合,将最终分类结果与现有流量分类方法进行对比讨论。
3.1 网络流量数据集
本文使用的是于2005 年由剑桥大学的Moore 等人采集的流量数据[19],该数据分为两部分。第一部分为1 000 个用户在24 小时内的流量数据,对每条TCP 双向流进行特征提取,最终得到377 526个数据样本,该部分样本的分布信息如表1 所示。第二部分是一年后以同样方法再次采集的少量数据,可用于检验算法的健壮性。样本共分为12 类,每个样本拥有249 个属性[20],最后一项属性为样本的类别。该数据为多项研究工作提供了支持,并且由真实环境采集,数据样本间存在较大数量差,符合本实验要求。

表1 Moore数据集样本比例
为了得到更可靠的分类效果,在训练模型时将数据集分为训练集、测试集和验证集三部分,训练集用于训练模型,而验证集则用于优化算法的参数和寻找最优特征集合,测试集则用于最终测试算法的分类效果。之后根据此前的研究成果,确定了30 个候选特征用于初期实验。
3.2 评价指标
对于分类效果的评价需要统一的标准,机器学习中常用的评价指标有准确率、召回率以及精度。通过混淆矩阵,可以计算这些指标,混淆矩阵的形式如图6 所示,四个灰色部分表示了样本数量。

图6 混淆矩阵
(1)准确率
准确率即被正确分类的样本比例,是一种较为直观的评价指标,但在数据不均衡的场景中不能仅依赖准确率进行评价。准确率的计算公式如下:
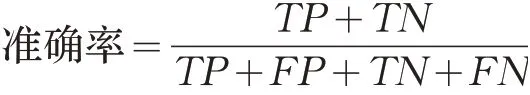
(2)召回率
对某类样本来说,召回率就是其中被分类器识别出的样本比例,反映了算法对该类数据的敏感程度,其计算公式如下:

(3)精度
精度又可以成为可信度,表示分类结果为某一类的样本中,被正确分类的样本比例,精度越高表示被误分为此类的样本越少,其计算方式如下:

对于召回率和精度,可以通过计算几何平均数来评价算法在数据集整体上的分类效果。
3.3 与传统算法对比
本文进行了不同类算法的初步对比,首先利用第一部分数据进行模型训练和测试,对第二部分数据则不进行训练,直接应用得到的模型进行测试以检测算法对于样本变动的健壮性。为了确保对比结果的客观性,没有进行过多的算法参数调整,各算法中数据特征也全部使用预选出的30 个特征,对比的指标为算法的分类准确率,对比结果如图7所示,另外本文对样本量为20万、30万和50万的情况下算法训练时间进行了对比,如图8所示,因各算法运行时间差距较大,图中纵坐标为对数时间。

图7 各类算法准确率对比
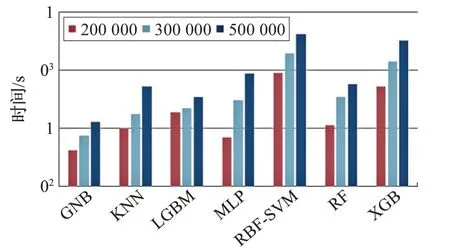
图8 各类算法运行时间对比
可以看出,LGBM 在各类算法中拥有较高的准确率,即使数据发生变化,仍能保持较好的分类效果,拥有良好的健壮性。同时,其运行时间关于样本量的变化较小,当数据量较大时速度将领先其他算法。以上对比结果表明,在网络流量的分类中,LGBM 算法能发挥更好的效果。
生命起源于海洋,海洋生物中的一些即使是微量的物质,也可能是陆生动物生长、发育和繁殖所必须的营养物质或生理活性物质。无论我们是否了解或定量分析出这些物质的种类、化学结构和含量,它们都是客观存在的。这或许就是鱼粉相比于陆生动物蛋白质原料和植物性蛋白质原料,可以成为饲料中重要的动物蛋白质原料所具备的优势,鱼粉的替代物质研究和鱼粉的不可替代性机理研究一直就是动物营养与饲料领域研究的热点[1]。
在实验的过程中,由于数据的类间不平衡,导致算法对少数类的分类效果较差,针对这一点,本文进行了特征集合的优化、算法参数的调整以及数据不平衡性的修正,以达到最佳分类效果。
3.4 重采样算法的对比
本文针对梯度增强树算法进行了特征集合的优化,由于LGBM中的子分类器为回归树算法,其节点分裂方式与决策树相近,故本文在特征优化中使用决策树代替LGBM 以加快优化过程。使用的特征优化算法为加N去R 算法,该算法是一种带回溯性质的搜索算法,其过程如下。
选择一个特征构成初始的特征集合,其余特征构成备选集合,在每次迭代中都会向特征集合中随机加入N个特征,再选择R个特征移出,直至分类效果达到最优,最终得到的特征集合如表2所示。

表2 数据特征集合
参数优化过程中,在大范围对每个参数进行搜索,再根据搜索结果,在最佳参数附近进行网格搜索,并进行交叉验证,最终取得一组最优参数,本实验中参数对算法各项指标的影响在0.1%以内。
确定算法和数据特征后,本文使用不同的算法对数据进行重采样,并对比了各类别数据的分类精度、召回率,以及其集合平均值。本实验使用的算法包含RUS(Random Under Sampling)、ROS(Random Over Sam‐pling)以及结合过采样与欠采样的SMOTE-Tomek 算法,对比结果如表3、表4所示。
根据以上结果可以看出,三种重采样方法对于对分类效果均有所提升。虽然对WWW 类样本的分类效果提升较小,但ROS和SMOTE-Tomek算法使LGBM 算法对于少数类的分类效果均得到了明显改善,特别是P2P、ATTACK、MULTIMEDIA 以及INTERACTIVE 类,召回率和精度均提升了10%以上,整体准确率也因此从95%提高到了99.8%。这两种算法都提高了少数类样本的比例,使其得到了充分学习,故将过采样与LGBM结合可以取得良好的效果。而相对地,应用RUS 则无法带来较明显的提升,因为欠采样算法仅降低了多数类样本的比例,无法解决少数类数据不充足的问题。
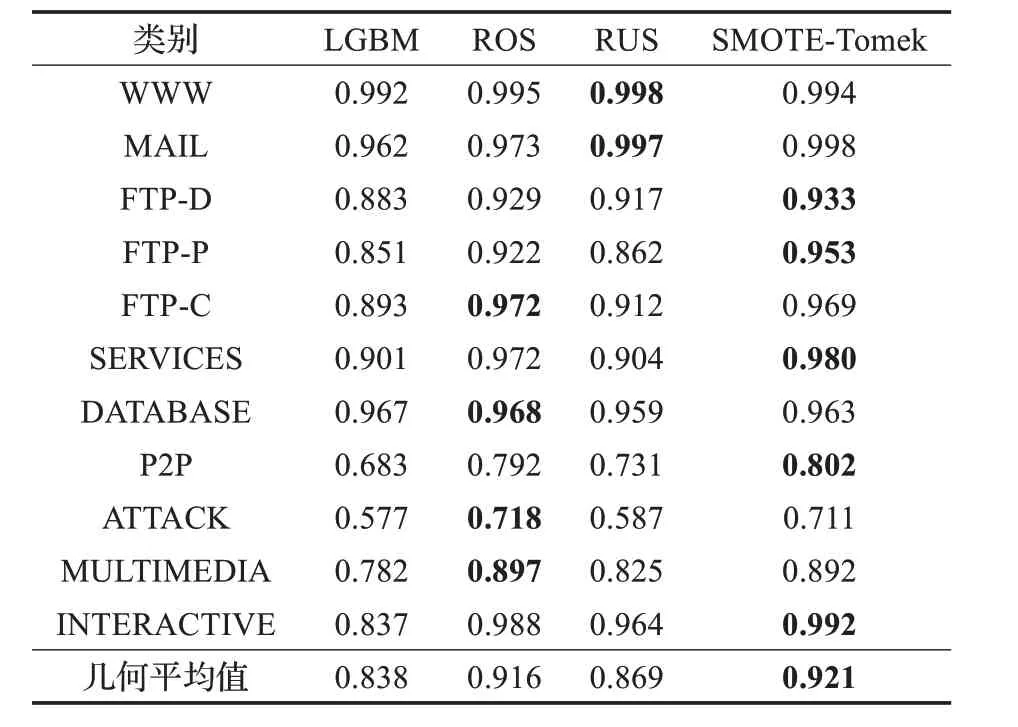
表3 重采样后精度对比
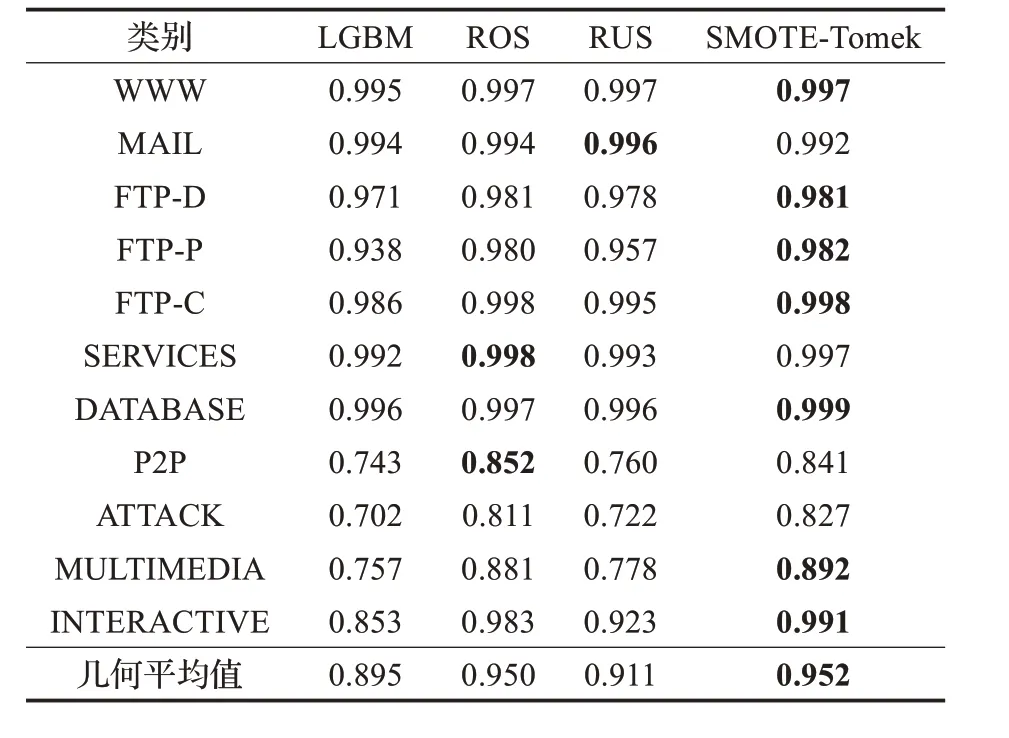
表4 重采样后召回率对比
最后,本文对比了RES-LGBM 与其他算法的分类效果。根据图9 的结果显示,其他算法虽然都有较高的整体准确率,但精度和召回率较低,大多低于90%,相对地,RES-LGBM 则达到了90%以上,也因此使得整体准确率更高。并且RES-LGBM 算法的计算时间也处于合理范围内,综合这两方面,RES-LGBM 在流量分类中可以取得更好的效果。

图9 各改进算法与RES-LGBM分类效果对比
4 结束语
本文介绍了各类网络流量分类方法以及数据不均衡问题的解决方法,并针对流量数据不平衡的问题,在相关研究基础上提出了RES-LGBM 的方法,之后对流量数据特征进行优化,并实现了流量分类。通过对各类机器学习算法进行对比,验证了在网络流量分类中,集成机器学习算法相较于传统算法的优势,提出利用LGBM算法和重采样算法互补的特点,避免过拟合并降低数据不均衡的影响,提高了流量分类效果。但该方法仍存在一定不足,之后将从以下三个方面进行进一步研究:(1)进行多个机器学习算法相结合的流量分类,研究不同算法之间的互补性;(2)将机器学习进一步用于网络安全领域,通过流量分类来进行恶意行为的检测研究;(3)应用分布式计算平台,提高算法的运行速度,提升分类效率。
