基于K-Means和CNN的用户短期电力负荷预测①
2020-03-18吕志星王沈征程思瑾秦承龙
吕志星,张 虓,王沈征,王 一,程思瑾,秦承龙
(国网山东省电力公司 泰安供电公司,泰安 271000)
1 引言
智能电网的发展推动了用户侧智能电表的普及,同时各种监控系统的大规模部署使得电网公司能够获得多尺度、全方位的用户用电信息[1],这些大量、高分辨率的用户负荷数据不但可以用于刻画用户用电习惯,还可以对用户的用电负荷进行预测,因此,挖掘用户负荷数据对于电网系统的调度优化、精细化经营管理以及服务于市场用户等方面具有重要价值[2].
长期以来,负荷预测是电力系统的研究热点之一.按照时间期限分类,电力负荷预测可以划分为长期负荷预测(10 年及以上)、中期负荷预测(5 年左右)和短期负荷预测.其中,长期负荷预测主要用于电力系统未来规划,短期负荷预测主要是为了合理安排发电机组的启停、减少旋转备用容量,从而降低发电成本、保障电网的安全稳定性.根据电力负荷数据时序性和非线性的特点,短期负荷预测模型一般可以分为两类,一类是时间序列方法,通常是将电力负荷看成一种时间序列的集合,根据电力负荷的历史数据、相关影响因素构建预测模型,从而实现预测未来负荷值.常用的方法包括:傅里叶展开法[3],指数平滑模型[4],自回归积分滑动平均模型[5].这些传统的时间序列方法对历史数据随时间的平稳性要求比较高,在一定程度上过于强调对历史数据的拟合,导致预测精度不高.另一类是以机器学习为代表的人工智能方法,主要包括:统计机器学习方法中的随机森林算法(Random Forest,RF),支持向量机,以及深度学习方法中的长短期记忆网络(Long Short Term Memory,LSTM)等.邹云峰等[6]将数据类进行K-means 聚类后分别进行线性回归,在线损率预测上取得较好结果,但由于其采用线性回归,对非线性数据建模能力有限.黄晗等[7]提出了基于随机森林的方法,针对历史负荷数据和天气信息对某地区进行预测.文献[8]将小波变化与极限学习机组合,提出了一种集成学习预测模型.以上方法相较于传统的预测方法有了很大的提升,但难以兼顾到时序数据时间相关性.文献[9,10]利用了LSTM 的时间序列性,可以更好地预测非稳定状态的负荷数据.虽然这些方法可以在系统级负荷预测上取得很好的效果,但由于单个用户用电的波动性和随机性较大,系统级负荷预测方法在单个用户的负荷预测上的预测性能较差,无法满足电网精益化管理的需求.
当前短期负荷预测多以电网系统级负荷为研究对象,而对于用户级对象的研究工作较少.文献[11]研究了不同内核的支持向量回归(Support Vactor Regerssion,SVR)模型对单个家庭用电负荷的预测效果.文献[12]针对呈指数级增长的电力用户数据提出一种改进的并行化的基于随机森林的负荷预测方法.文献[13]考虑到了用户用电行为的变化,提出了扩展卡尔曼滤波及核函数极限学习机相结合的方法对用户侧短期负荷进行预测.文献[14]提出了一种基于决策树和小波去噪相结合的预测方法,对不同用电模式的用户进行个性化负荷预测.这些模型考虑了用户用电负荷影响因素,对不同用户的用电特性进行分析,但忽略了时间序列相关性对单个用户负荷预测的影响.
从相关工作来看,对于用户电力负荷预测而言,需解决两方面问题:一是如何有效提取与预测目标相关的抽象特征,以便预测模型学习其中规律;二是不同用户负荷特点差异较大,单一预测模型不能对特征差别较大的用户进行负荷预测,建立组合预测模型以提升预测精度是很有必要的.因此,本文从用户负荷数据特性出发,利用K-means 聚类得到不同用户类别,针对每类用户的负荷数据时间相关性,搭建不同的负荷预测模型.为了能够提取与负荷相关的抽象特征,本文利用不同时间序列信息构建不同张量作为卷积神经网络的输入,构建出深层卷积网络来预测单个用户的负荷.最后,本文结合某地23 个用户一年的真实用电负荷数据对本文提出的方法进行验证.
2 基于K-means 聚类算法的用户分类
图1 为随机选择的5 个用户的某周负荷曲线图,不同颜色的曲线表示不同用户的周负荷变化情况.其中,横轴表示时刻点,每15 分钟采样一次负荷数据,纵轴表示负荷数据.通过观察曲线发现,对于单个用户而言,由于生产和经营一般具有较强的周期性和规律性,其日负荷数据也具有规律性,具体可以表现为以下2 个方面:如无重大突发情况,其短时间内负荷曲线波动较小(相邻时刻相关);不同日的相同时刻的负荷波动差异不大(日相关).为此,首先我们利用K-means 聚类算法来研究用户用电行为模式.
K-means 算法是一种无监督学习方法,算法通过设定好的中心点对靠近它们的点进行归类,通过迭代的方式,逐次更新各聚类中心的值,直到得到最好的聚类结果.对处理大数据集而言,K-means 聚类算法保持了较高的可伸缩性和高效性.算法描述如下:
(1)选择合适的k值作为聚类的初始中心点.
(2)计算其他的点到这k个中心点的距离,离哪个中心点的距离最小就被划分到哪个类.距离的具体计算公式如下:

(3)通过求平均值的方法更新该类的中心.
(4)按步骤(2)、(3)迭代更新后,直至各类中心点的值均不再变化,迭代结束.
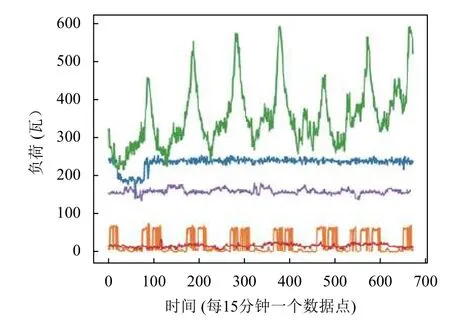
图1 某5 个用户一周的负荷曲线图
本文采用K-means 算法对真实数据集中的23 个用户的历史数据进行聚类分析,然后按照其时间序列的不同的相关性,将不同类别的用户负荷序列转换为张量后输入至不同的卷积神经网络进行抽象特征提取.聚类得到的结果如表1 所示.其中,A 类表示日相关性和相邻时刻相关性均较为明显的用户,B 类表示仅相邻时刻相关性较强的用户.

表1 用户聚类结果
3 基于CNN 特征提取的负荷预测模型
3.1 卷积神经网络
在深度学习的诸多算法中,卷积神经网络(Convolutional Neural Networks,CNN)因其特殊的网络结构,在计算机视觉领域应用广泛.然而,在电力负荷预测方面的应用较少.CNN 的典型网络结构由输入层、卷积层、池化层、全连接层和输出层组成[15].其中,卷积层是CNN 的核心,包括卷积核、卷积层参数和激励函数3 个重要部分.卷积层内部包含多个卷积核,组成卷积核的每个元素都对应一个权重系数和一个偏差量,类似于前馈神经网络的一个神经元.CNN 的优势在于能够通过较少的权重参数训练提取得到特征[16].
本文采用CNN 网络来提取用户历史负荷的特征.对于A 类用户,CNN 模型用相邻的前16 个负荷数据点和待预测点前16 天的相同时刻的数据点分别构造成 4×4的矩阵形式,将这两个矩阵组成的张量作为CNN 模型的输入,如图2 所示.
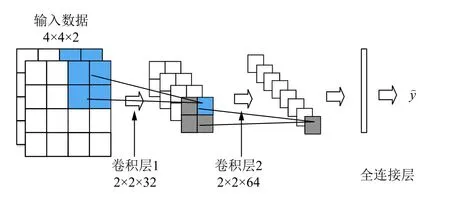
图2 A 类用户卷积神经网络结构图
对于B 类用户,模型仅以相邻的前16 个负荷数据点构建为 4 ×4×1的网络输入,如图3 所示.CNN 模型有两个卷积层,卷积核分别为2 ×2×32和 2 ×2×64.
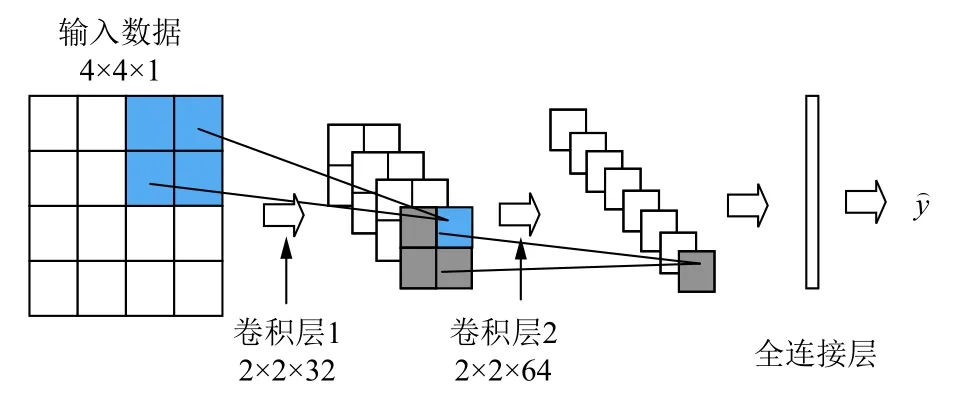
图3 B 类用户卷积神经网络结构图
考虑到输入数据的维度不高,因此本文在卷积层后直接接了两个全连接层,而未使用池化层进行下采样,保证了数据的完整性.模型使用ReLU 作为激活函数,选择均方误差(Mean Square Error,MSE)作为损失函数.
3.2 算法流程
将历史负荷数据经过数据预处理得到用户用电负荷曲线,通过K-means 聚类将用户分为日相关性强和相邻时刻相关性强的两类用户.针对不同用户负荷特性,构建不同张量输入的CNN 模型,具体处理流程如图4 所示.

图4 基于K-means 和CNN 的用户短期电力负荷预测流程
4 实验及结果分析
4.1 数据说明与数据预处理
本文所用数据集为某市23 个用户2015 年全年的负荷数据,每15 分钟采集一个样本点,每天可获得96 个负荷点数据.通过观察数据,发现原始采集数据存在缺失、数据为负或远大于该用户其他时刻点的负荷数据等失真情况.因此在用于模型训练和测试前,本文首先对采集到的负荷数据进行异常处理.对于缺失或失真的数据,本文利用该数据的前15 个相邻数据点的平均值对其进行填充或修正,得到完整的负荷数据序列.同时,将所有的负荷数据通过归一化映射到[0,1]之间,公式如下:
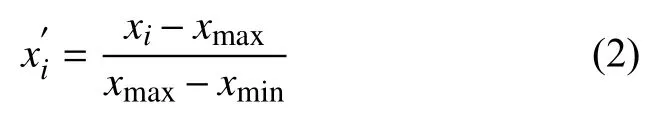
其中,xi为原始负荷数据,为归一化后的负荷数据,xmax为数据集样本中的最大负荷,xmin为数据集样本中的最小负荷.
4.2 评价指标
为了有效评价模型的准确度以及与其他方法进行对比,本文选取平均绝对误差(Mean Absolute Percentage Error,MAPE)作为评价指标,计算公式如下:
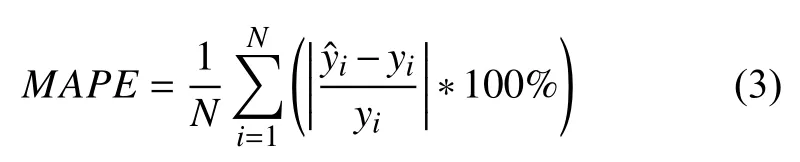
其中,n表示预测点的个数,yi表示第i个预测点的负荷真实值,表示第i个预测点的负荷预测值,即MAPE值越小,预测准确率越高.
4.3 预测结果分析
采用本文提出的CNN 算法对经过K-means 算法分类的电力用户进行负荷预测,训练集与测试集划分比例为8:2.训练集采用的是2015 年1 月1 日至2015 年10 月15 日的数据,共有28 128 条记录;测试集采用的是2015 年10 月15 日至2015 年12 月31 日的数据,共有7007 条记录.
(1)将本文模型与随机森林和支持向量回归机进行比较,结果见表2.

表2 不同电力负荷预测方法MAPE 比较(%)
本文模型对绝大多数用户的预测效果都优于现有算法,平均MAPE为30.91%,相对于现有最好的RF 方法MAPE降低了20%,说明本文模型可有效提高短期负荷的预测准确度.其中user5 的准确度相较其他模型提高得最多,因为user5 的数据波动很大,通过归一化可以增加数据的稳定性,提高预测的准确度.由表2 可见,不同用户的MAPE差距很大,这是因为不同用户的用电行为习惯差异很大.
图5 为user1 和user8 在2015 年1 月1 日至2015 年2 月28 日的负荷曲线.图5 中,user1 历史负荷曲线较平稳,其用电模式较规律,因此可得到较准确的预测结果,而user8 在同段时间的用电行为模式难以捕捉,无法达到较好的预测效果.这说明了针对不同用户采用不同预测模型的有效性和重要性.
(2)为了验证聚类方法的有效性,将本文模型与仅输入相邻时刻相关的CNN 模型、输入相邻时刻序列和日相关特征序列的CNN 模型进行比较,结果如表3所示.

图5 user1 和user8 2015 年1 月1 日至2015 年2 月28 日负荷曲线

表3 聚类效果MAPE 分析(%)
从表3 不难看出,本文模型的MAPE比简单将数据放入CNN 模型的MAPE降低了5%,证明了应用聚类算法可更好区别不同用户的特性,有助于提高预测性能.
5 结论
针对用户负荷差异明显、波动性大的问题,本文利用K-means 算法将用户用电历史负荷曲线进行聚类,针对不同类别的用户利用CNN 构造不同的特征提取网络结构,训练建立预测模型.实验结果表明本文模型均比RF、SVR 及未经聚类的CNN 模型的预测效果优秀,预测MAPE降低了21.22%.由于当前预测模型仅参考了用户的历史负荷作为模型输入,实际上用户负荷与温度、湿度及用户所在行业经济形势等多种因素相关,后续将考虑筛选更多的相关因素输入模型中,进一步提高模型的预测准确度.
