国家作物种质资源观测鉴定站点体系布局方法研究
2020-03-16陈彦清曹永生林雨楠
陈彦清 曹永生 林雨楠 方 沩*
(1.中国农业科学院作物科学研究所,北京 100081;2.国家作物种质资源数据中心,北京 100081)
1 引言
作物种质资源是保障国家粮食安全与重要农产品供给的战略性资源,是农业科技原始创新与现代种业发展的物质基础[1]。我国是作物种质资源大国,但还不是种质资源保护与研究利用的强国。我国作物种质资源保护和利用研究虽然取得显著成绩,但在资源利用的前期基础研究,尤其是资源评价鉴定方面仍然存在鉴定比例小、无系统的鉴定体系、鉴定环境单一等问题。建立全国多环境的作物种质资源评价鉴定体系是解决以上问题的关键,为此,中华人民共和国农业农村部于2017 年启动的农业基础性长期性科技工作将作物种质资源评价鉴定纳入其中[2],为评价体系的建立提供了良好的契机,但如何在全国合理的设置评价站点,布局网络体系则是需要深入研究的科学问题。
评价鉴定与环境密切相关,而气候生产潜力可以反映在不同自然环境下作物理想生长情况,可以利用气候生产潜力的差异性来反映作物生长的差异性,所以,本研究以气候生产潜力为切入点,通过研究气候生产潜力的环境因素,确定影响作物生长的主要环境因素。作物气候生产潜力是指一个地区当土壤肥力和农业技术措施等指标都在最适宜条件下,由太阳辐射、温度和水分等因素共同决定的单位面积的可能作物产量。针对气候生产潜力的研究,可追溯到20 世纪50 年代以前,但大规模的研究工作始于20 世纪60年代[3]。作物气候生产潜力计算模型大致归为两类[4],其中经验概念逐级计算模型是从能量转化、气候影响和作物生理的角度,定义作物光合生产潜力、光温生产潜力和气候生产潜力,气候生产潜力是通过利用温度和水分对光合生产潜力的逐级修正而得到的[5-7]。
对于相似环境下的站点,在布局时需要进行聚类处理。空间聚类作为聚类的一个研究分支,其过程是一个寻找最优划分的过程,即根据聚类终止条件不断对划分进行优化,最终得到最优解。与普通的聚类相比较,空间聚类加入了空间约束,不仅考虑了属性上的相似性,而且顾及了空间数据的复杂性。评价聚类最优组数的方法有多种,如聚类中心的距离矩阵评价方法,该方法通过聚类中心之间的距离大小判定聚类质量的高低,强调类与类之间的分离度[8];距离方差评价算法则是计算各聚类域中的样本与聚类中心的距离方差,方差越小聚类效果越好,强调类内的紧凑度[8];Davies-Bouldin 指数可反映集群内部分散度和集群间的相异度,DB 指数越小,聚类效果越好[9-10],与其类似的方法还有DCSCV 算法,该方法是用各簇中心点之间的距离的平均值与各簇簇内各点到各簇心距离的平均值的比值来度量聚类的有效性,评价结果随着簇数的增加而增大,在增大过程中存在拐点,拐点处为最佳聚类数[11]。此外还有Calinski-Harabasz指数[12]、基于信息论的评价方法[13]、Dunn 指数[14]、RMSSDT 和RS 指数[15]、SD 指数[16]等。以上方法大多是通过聚类样本的距离进行指数计算,判定类内相似性或类间相异性,寻找指数最大或最小值的方式确定聚类的最优组数。
本研究拟通过寻找与作物生长密切相关的环境因素,利用相关空间分析和基于环境因子的空间聚类方法,研究国家尺度下种质资源观测鉴定站点体系布局方法。通过建立布局合理、规范科学的种质资源长期观测鉴定体系,对资源的重要性状开展综合鉴定评价,整合观测鉴定数据,为作物种质资源大数据体系建设提供重要内容,为农业科学研究和现代种业发展提供坚实的基础数据支撑。
2 数据与方法
2.1 数据
通过前期的自主申报、初步筛选等工作,先后在全国确立了379 个作物种质资源评价鉴定站点,初步形成了全国作物种质资源观测评价站点体系,基本涵盖了全国具有作物种质资源评价鉴定能力的省、地市级农科院所,以此为全国评价鉴定区域划分的基础站点数据。气象数据主要来源于中国气象局网站,计算了1988—2018年近30年的各气象站点每项指标平均值,主要包括地温、气温、降水、相对湿度、日常时长、风速等指标。通过普通克里金插值方法将所有指标数据插值成全国栅格数据,海拔数据分辨率为500m×500m 的栅格数据,来源于中国科学院计算机网络信息中心地理空间数据云平台。最后通过叠加分析、点值提取等方法将各项指标数据赋值给以上379 个站点。
2.2 方法
国家作物种质资源观测鉴定站点体系布局方法整体技术路线可分为主要环境因子选择、空间聚类方法确定、最优聚类组数判定、各组空间控制区域划分、站点布设原则设计等5大步骤,具体如图1所示。
2.2.1 环境因子选择
根据气候生产潜力逐级计算模型,首先对光合生产潜力进行温度修正得到光温生产潜力,在光温生产潜力的基础上进行水分修正,得到气候生产潜力。光合生产潜力的主要环境影响因素为太阳辐射,而太阳辐射与海拔、日照时长、纬度有关,温度修正因子主要取决于温度,水分修正因子的主要影响因素为降水,综合分析,最终确定影响作物生长的重要环境因素有温度、降水、日照时长、纬度和海拔。
2.2.2 空间聚类方法及最优聚类组数判定
空间聚类时需要设定聚类的属性和合适的空间约束,通过环境因素的选择,本研究选择温度、降水、日照时长、纬度和海拔5 个属性作为聚类属性字段;空间约束方法的选择需要根据聚类的目的来确定,本文的最终目的是通过对站点的聚类,从而实现区域的划分,而相互邻近的站点在空间上才可划分到一个区域,基于此,本研究选择最近邻聚类方法(KNN 算法)对站点进行聚类,该方法聚类后同一个组中的要素将相互邻近,每个要素至少是该组中某一其他要素的邻域,即相邻的站点且5 个环境因素变量相似的站点被聚类成一类。
在最优聚类组数判定方法选择方面,结合本研究多因子控制下的最近邻聚类方法的特点,选择伪F统计量方法评价聚类组数。该方法中,伪F统计量的计算主要考虑类内多因子的相似性和类间多因子的差异性,每种分组方案均对应一个伪F 统计量,该统计量越大,组内相似性和组间差异性越大,对应的分组方案越好,对应的分组数最优。与其他聚类评价指数相比较,由于聚类方法选择了最邻近聚类,在聚类时已经考虑了站点的相互邻近性,所以伪F统计量的计算主要由多因子的属性值代替聚类点距离,综合评价多因子在类内相似性和类间差异性。伪F 统计量计算公式如下:
其中,SST代表组间差异性,SSE代表组内相关性。
其中,n 表示所有参与空间聚类的站点数,ni表示第i组中包括的站点数,nc表示分组数,nv表示参与分组的变量数,表示在第i 组中的第j 个站点的变量k 的值,表示变量k 的均值,表示变量k 在组i 中的均值。
当分别计算每个变量的SST和SSE值时,可得到每个变量对应的R2值,即:
其中,表示变量k 的R2值,SSTk表示变量k 的组间差异性,SSEk表示变量k 的组内相似性,其他符号定义同上。的大小可以反映变量k 对于聚类的贡献程度,该值越大,表明对应的变量越能更好地对站点进行分组。
2.2.3 空间区域划分
通过空间聚类后,每个站点拥有了对应的分组类别,且组内的站点具有相互邻近的特点,但在空间上无法确定每组站点对应的区域边界,不能完成面域的划分,为了解决该问题,本研究引入泰森多边形进行各组区域边界的界定。泰森多边形可对空间平面进行剖分,其特点是多边形内的任何位置离该多边形的样点(即本文的站点)的距离最近,且每个多边形内含且仅包含一个样点,位于泰森多边形边上的点到其两边的样点的距离相等。基于以上特点,首先构建每个站点对应的泰森多边形,由于组内站点的相互邻近性,构建后的泰森多边形在组内将相互邻接,通过合并这些邻接的泰森多边形,就可形成该组站点对应的区域,该区域内的任何一点均能找到距离该点最近的站点,基于空间上越临近各方面因素越相似的一般性原则,这种区域划分方法能够将空间上每个点划分到合理的区域范围内。
2.3 站点体系布局原则设计
理论上,站点布设越多,观测的数据越具有区域代表性,但同时意味着成本投入越大。利用环境因素进行聚类分区后,属于同一个聚类区域内的站点证明具有相似的环境条件,不同区域环境差异明显,所以在考虑成本投入最小化和观测数据代表性的情况下,每个区域内至少布设1 个站点,再根据站点的实际观测能力和区域作物特点等多方面因素确定是否需要增加额外站点。国家农作物种质资源保护体系中具有10 个国家作物中期库及43 个国家种质资源圃[17],这些单位均具有较强的种质资源工作基础、丰富的种质资源及稳定的科研队伍,可作为站点体系的首选单位,另外,农业农村部于2018年和2019年分两批确定了100 个国家农业科学观测实验站[18-19],其中作物种质资源领域站点9 个,可作为站点体系的备选单位,还可在其它具有条件的单位中进行选择。
综上所述,国家作物种质资源观测鉴定站点体系布局原则为:
(1)每个区域内至少布设一个站点;
(2)区域站点布局数量需根据区域特点、站点能力等条件综合判定;
(3)综合考虑国家农业科学观测实验站依托单位的工作基础、作物种质资源持有条件、科研队伍和区位等因素进行站点选择;
(4)正式挂牌的国家作物种质资源观测实验站作为体系的首选单位;
(5)国家农作物种质资源保护体系中的国家作物中期库及种质资源圃作为站点体系的第二选择单位;
(6)其他未纳入国家体系但满足条件的站点作为第三选择单位。
3 结果
对于全国的分区研究中,大部分选择分级区划,如综合农业分区,分为10 个一级区和38 个二级区,《农用地质量分等规程》[20]中将标准耕作制度分为12个一级区和51 个二级区,种植业区划分为11 个一级区和31 个二级区。这是由于随着区域尺度的变化,分区的主导因素会发生变化,所以,针对本研究的分区同样采用分级分区的方法进行。
3.1 一级站点分组
在国家级尺度上,利用最近邻聚类方法,结合以往类似分区数量,本研究将全国分为2—15 组,通过判定每次分组中对应的伪F 值判定最优组数。各组数对应的伪F 值如表1 所示,从伪F 值的变化趋势可见(图2),前9 组的F 值无规律变化,从第10 组开始,呈现逐渐增加的趋势,但增幅不显著,当分成2 组时,伪F 值明显高于其它组数对应的F 值,所以,首先将全国379个站点分成2组。
针对国家尺度上分出的两组再进行区域尺度的分组,第一小组182个站点,第二小组197个站点。根据分组结果,两组站点基本上以长江为界进行了划分,除了四川盆地的部分站点外,长江中下游的站点基本上沿长江两岸分组分布,第一小组的绝大部分站点位于长江以南,第二小组的绝大部分站点位于长江以北。
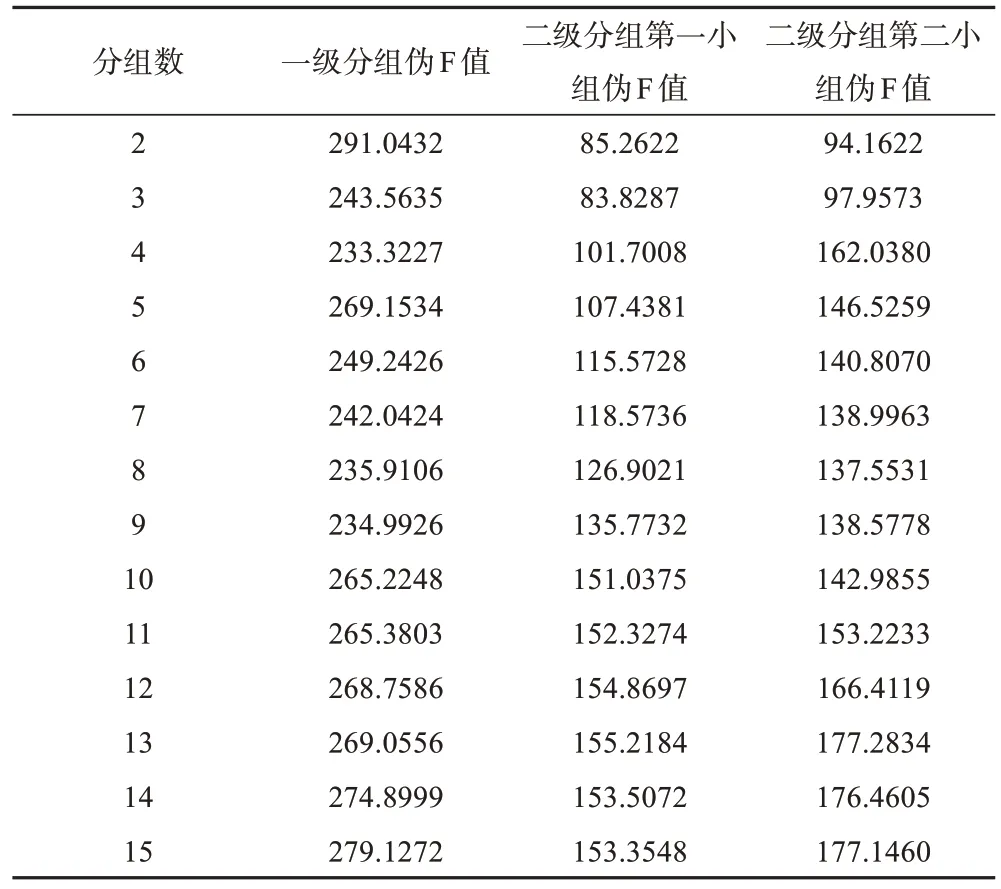
表1 各级分组对应的伪F值Table 1 Pseudo F-value of each level group
根据各因素的R2值可判定因素对分组的贡献程度,R2越大,因素与分组结果关联性越强。从表2 可以看出,一级分组中,关联性最强的两个因素为纬度和降水,其次为气温和日照时长,海拔与分组结果关联性最小,仅为0.001。说明在一级分组中,起决定性左右的分组因素主要为纬度、降水、气温和日照时长,海拔则对一级分组几乎无影响。

表2 各级最优分组中各因素对应的R2值Table 2 R2 value of each factor in each level of optimal group
3.2 二级站点分组
在二级分组中,同样利用最近邻聚类方法对第一小组和第二小组的站点进行空间聚类,对每个小组进行最多15 组的聚类,计算不同分组数对应的伪F 值,如表1 中数据所示。从第一小组中不同组数对应的伪F值折线图(图3)可知,分组数小于10时,伪F值呈快速增加趋势,10 组后趋于平缓,呈缓慢增加趋势,当分组数为13 时,伪F 值达到最大,随后降低,由此判定,当第一小组分为13组时分组方案最优。
从表2 的第一小组最优分组后各因素的R2值可知,5 个因素对应的R2值均较高,说明5 个因素与分组结果均具有极显著的相关性。其中,海拔对应的R2 值最高,降水对应的R2 值最低。说明在第一小组分组中,海拔对分组影响最大,降水影响相对最小。这与一级分组中海拔和降水对分组的影响程度恰好相反,这也验证了不同尺度下分区主导因素有可能不同的说法,同时说明了本研究分级分组策略的正确性。
从第二小组中不同分组数对应的伪F 值的折线图(图4)可知,伪F值可分为三个阶段:2—4组,5—12组,13—15组。2—4组时伪F值随着分组数增加而增大,5—12组时伪F值呈曲线先降低后升高,到13组时伪F 值达到最大,随后稍有降低并趋于平缓。所以,在第二小组中,同样分成13组时分组方案最优。
从表2的第二小组最优分组后各因素的R2值可知,5个因素对应的R2值均较高,说明5个因素与分组结果均具有极显著的相关性。其中,纬度对应的R2值最高,日照时长对应的R2值最低。说明在第二小组分组中,纬度对分组影响最大,日照时长影响相对最小。
3.3 空间控制区划分
根据以上站点分组策略,共将379个站点分为26组,利用ARCGIS 软件构建每个站点的泰森多边形,图5(a)中分别为第14 组站点和第20 组站点的泰森多边形。每个站点对应一个泰森多边形,该区域内任意一点距离该站点最近,将属于同一分组的泰森多边形进行融合形成各组的空间控制范围,如图5(b)。
26组中,站点最多的一组中有35个站点,站点最少的一组有4 个站点,标准差达到8.09,站点数量在不同分组中差异明显,说明目前站点布局在站点数量上存在区域不均衡的特点;从平均每个站点控制的面积来看,最小6 156平方公里,最大214 991平方公里,标准差为55 321,在站点布局理想状态下分区后每个区域内站点的平均控制面积应相对一致,而目前不同分区间站点平均控制面积差异显著,说明目前站点布局在区域间站点密集程度上存在不均衡的特点。所以,从目前的站点布局来看,区域间整体布局差异明显,水平不一,对于布局过密的地区,应结合实际情况进行适当删减,对于布局过少的地区,若不能满足观测需求,还需继续新增站点。
根据站点筛选原则对第20 组分区进行站点初筛,第20组分区主要位于湖北省中部和南部,共12个站点,无已认定为国家作物种质资源观测实验站的站点,但该区域内具有国家油料作物种质资源中期库、国家野生花生种质圃、国家果树种质砂梨圃和国家水生蔬菜种质圃等国家库圃。前两者依托单位为中国农业科学院油料作物研究所,砂梨圃依托单位为湖北省农科院果树茶叶研究所,水生蔬菜圃依托单位为武汉市蔬菜科学研究所,以上三家单位虽均位于武汉市,但主要观测作物类型差异明显,各具特色,均具有扎实的作物种质资源相关工作基础和经验,可作为该区域观测站点的选择对象。
4 总结与展望
本研究以气候生产潜力为切入点,确定了影响作物生长的主要自然因素,并通过空间聚类方法进行区域最优分组,最后利用泰森多边形的特点完成了各区域的划分,在此基础上根据站点布设原则进行布局,为站点的科学布局提供了理论依据。
根据以上研究,得出结论如下:
(1)根据气候生产潜力的逐级修正算法,确定了温度、降水、日照时长、纬度和海拔5 大影响作物生长的自然因素作为站点空间聚类的聚类因子;
(2)以能够判定组间差异性和组内相似性的伪F值判定最优聚类组数,将全国379个站点划分成26个组别;
(3)通过构建站点泰森多边形的方法划定各组站点控制区域,完成全国26 个区域的边界划定,为站点体系布局提供了分区布设的条件。
站点体系布局关系到未来观测评价结果的代表性和科学性,站点的选择是一个非常复杂的过程。另外,作物种质资源观测鉴定与其他领域观测相比较具有鲜明的特点,资源的保护、评价和利用等各环节是密不可分的,只有在具有可观测和值得观测的资源的前提下,才能够开展资源的观测评价工作,通过观测评价掌握资源特征特性,了解资源的可利用性和利用范畴,提高利用效率。所以,种质资源观测站点的选择必须结合站点依托单位的资源持有情况和工作基础,从现有的国家作物种质资源保护与利用体系中选择是合理有效的途径,但具体哪些站点能够被纳入国家体系开展作物种质资源观测工作还需进行深入的大量的调查研究,通过理论与实际相结合综合多方面因素进行考虑。因时间和精力有限,文章仅对分区站点布设的原则进行了探讨,未对各区的具体站点进行筛选。在未来的研究中,作者将根据需求逐区开展实地调研,选择最适合的站点进行区域观测。
