不同统计模型在冬小麦产量预报中的预报能力评估*——以江苏麦区为例
2020-03-12徐经纬宋迎波
徐 敏, 徐经纬, 高 苹, 宋迎波
(1.江苏省气候中心 南京 210008; 2.南京信息工程大学气象灾害教育部重点实验室/南京信息工程大学 气象灾害预报预警与评估协同创新中心 南京 210044; 3.国家气象中心 北京 100081)
产量预报一直备受农业部门、粮食部门和政府决策部门的关注[1], 准确的产量预报可大大提升国家战略决策服务的水平和质量, 使决策部门能够及时了解和掌握作物产量动态, 制定科学的宏观调控政策, 合理安排调拨、贮运、进出口贸易及生产等, 对保障国家粮食安全具有重要意义。另外, 随着粮食贸易的发展和农业政策的调整, 农业也逐渐受到资本市场的青睐, 尤其农产品期货贸易、农作物保险等机构急需产量预报信息[2]。
从20 世纪70年代开始, 中国开始研究作物产量预报方法, 经过40 多年的研究, 目前主要形成了4 种方法: 基于农学的产量预报方法[3]、基于统计学的产量预报方法[4]、遥感估产法[5]、基于作物生长模型的产量预报法[6]。其中农学方法具有直观、机理性强的优势, 但农学模式需要穗数、穗粒数、千粒重, 而这些要素的获取依赖人工观测, 成本高且观测点偏少, 在实际应用中具有较大的限制; 遥感技术可以大范围地估产, 但存在作物信息提取受云层覆盖影响大, 以及作物种类识别精度有限等困难; 作物模型对作物生长机理考虑较全, 但参数校正难度大, 业务成熟应用的调试时间长[7]。有些学者为了充分利用作物模型和遥感技术各自的优势, 尝试将两种方法相结合进行产量预测, 但同样存在业务成熟应用调试时间长的问题[8]。目前在气象部门应用较为成熟的主要还是基于统计学的产量预报法, 作物产量的形成除了受品种、生产力水平等影响外, 与外界生态环境因子有着密切关系, 气象条件是外界生态环境中最主要的因素, 因此充分应用近几十年气象条件与产量之间的关系, 通过数理统计方法建立产量预测模型, 具体为基于作物历史丰歉相似年、关键气象因子、气候适宜度的统计学预报方法, 这些方法已应用于黑龙江[9]、吉林[10]、河南[11]等省的作物产量预报中。这3 种方法具有不同的优缺点[12], 历史丰歉相似年法计算相对比较简单, 能够客观定量地预报出气象条件对作物产量丰歉的影响, 并且解决了传统统计方法在短时间内筛选因子困难的问题, 缺点是没有考虑冬小麦生长发育过程中的生理生态过程, 同时也很难找到真正相似的年份, 所以预报结果有一定的局限性和不稳定性; 关键气象因子法的优点是考虑了冬小麦生长发育期内关键时段气象因子对气象产量的影响, 但也只考虑了温度、降水、日照的影响, 并未考虑土壤水分等因子的影响; 气候适宜度法充分考虑了冬小麦的生物学特性, 从生长发育所需的上下限温度、最适温度、需光性、需水量等方面, 建立气候适宜度与气象产量之间的关系模型, 预报准确率普遍较高, 但在趋势预报上具有一定的不稳定性。
在实际应用中发现, 不同的预报方法对不同区域作物产量的预报结果存在差异, 如何优选出适合本省的产量预报模型非常关键。邱美娟等[13]对丰歉相似年中加权法与大概率法在吉林春玉米(Zea mays)产量预报中的效果做了比较, 研究表明加权法预报效果好于大概率法; 王贺然等[14]对关键气象因子和气候适宜度两种预报方法在辽宁大豆(Glycine max)产量预报中的预报效果进行了对比分析, 结果表明进行大豆产量趋势预报时, 可以优先考虑关键气象因子预报模型, 在未出现重大气象灾害的正常年份, 可以赋予气候适宜度预报模型更多权重。目前, 对丰歉相似年中加权法和大概率法、关键气象因子法、气候适宜度法同时进行比较的研究还少见报道; 另外, 也未考虑不同气象产量分离方法对产量预报模型精度的影响。
为此, 本研究以江苏省冬小麦(Triticum aestivum)为例, 考虑线性分离、差值百分率、5年滑动平均、3年滑动平均、二次曲线等5 种产量分离法, 利用丰歉相似年法、关键气象因子法、气候适宜度法等3类产量预报方法, 通过不同组合, 建立不同的产量预报模型, 计算各模型的模拟准确率、模拟单产与实际单产的相关系数, 进行拟合检验和试报检验, 筛选出3 类方法中的最优模型, 并通过最优模型加权集成, 拟进一步提高预报准确率。研究结果可为江苏省小麦单产的动态、定量预报和模型优选提供科学依据。
1 资料与方法
1.1 研究区概况
江苏省地处长江三角洲地区, 全省境内除北部边缘、西南边缘为丘陵山地, 地势较高以外, 其余则自北向南为黄淮平原、江淮平原、滨海平原和长江三角洲共同组成的平坦大平原, 是经济大省, 同时也是粮食大省。小麦是江苏省第二大粮食作物, 仅次于水稻(Oryza sativa), 近10年江苏省小麦种植面积维持在2.1×106hm2左右, 播种面积居全国第4 位、产量排第5 位, 对中国小麦产业至关重要。江苏省处于北亚热带与暖温带的过渡气候带, 具有明显的季风特征, 四季分明、雨热同季、雨量集中、光照充足, 其中江苏的沿江、沿海及丘陵地区, 土壤以高沙土为主, 气候湿润, 在小麦灌浆期降雨偏多, 土壤保肥能力差, 有利于小麦低蛋白和弱筋形成。凭借独特的土壤、气候等生态条件, 江苏被列为弱筋小麦优势产区, 是全国最大的弱筋小麦主产省份, 全国50%以上优质弱筋小麦依赖于江苏, 特别受广东、福建、浙江等南方加工企业的青睐。
1.2 数据资料
1)气象资料: 选用1993—2018年江苏省69 个基本气象观测站点逐日最高气温、最低气温、平均气温、降水量、日照时数、高温日数、低温日数、降雨日数、大雨日数、可照时数(根据各站点经纬度计算得出)、20 cm 土壤相对湿度, 来自于江苏省气象局。用于寻找气象条件类似的相似年、确定影响气象产量的关键气象因子和构建综合气候适宜度。
2)小麦产量资料: 选用1993—2018年江苏全省和13 个地级市小麦单产、种植面积, 来自于江苏省统计局。作为单产统计预报模型中的目标因子, 产量资料用于模型的构建和验证。
3)小麦生育期资料: 选用1993—2018年昆山、沭阳、大丰、如皋、兴化、淮安、盱眙、滨海、赣榆、徐州等10 个农业气象观测站的小麦播种、出苗、三叶、分蘖、拔节、孕穗、抽穗、开花、成熟等生育期的普遍期, 来自于江苏省气象局《作物生长发育状况记录年报表》。
1.3 研究方法
1.3.1 气象产量分离法
产量主要受社会因素和气象条件的影响, 因此可分解为随生产力变化的趋势产量和随气象条件变化的气象产量。社会因素主要表现为农业技术的进步、生产资料的投入、惠农政策的实施、农药施肥灌溉方法的改进等, 由生产力提升引起的小麦产量变化称之为趋势产量。气象条件存在年际差异且年内若出现明显的农业气象灾害则气象产量波动会比较大。文中为了比较不同产量分离方法对预报模型准确率的影响, 采用了5 种产量分离方法[15-17]: 线性分离法(简称为L)、差值百分率分离法(简称为D)、5年滑动平均分离法(简称为M5)、3年滑动平均分离法(简称为M3)和二次曲线分离法(简称为Q)。
1.3.2 单产预报方法
1)基于丰歉相似年的单产预报法: 计算作物播种后的积温(≥0 ℃)、标准化降水量、累积日照时数, 通过找寻预报年气象要素与历史年气象要素最相似的年份, 预测预报年的单产变化情况。相似年的确定方法见公式(1)-(2):

式中:ikr 、ikd 分别为某气象要素预报年和历史上任意一年的相关系数与欧氏距离; k 为预报年, i 为历史上的任意年;ikX 为判定相似年的指标, 该值越大表明预报年与这一年的气象条件越相似, 单产变化也越接近;kjx 为预报年冬小麦播种至发布预报时的第j 个气象要素;ijx 为历史上任意一年同一时段同类气象要素; j 为某气象要素序号, N 为样本长度。为了减小预报误差, 在积温、标准化降水量、累积日照时数3 个因子中分别选取排在前3 位的历史相似年, 共得到9 个相似年, 分别采用大概率法和加权法[13]最终确定预报年的单产变化。
2)基于关键气象因子的单产预报法: 根据冬小麦生长期内各时段不同气象因子(归一化处理后的平均气温、日平均气温≥0 ℃的积温、日最高气温≥30 ℃的日数、日最低气温≤0 ℃的日数、降水量、降雨日数、日降水量为25.0~49.9 mm 的大雨日数、可照时数)与气象产量(5 种分离方法下的气象产量)之间的相关系数, 并结合冬小麦的生物学特性, 确定影响产量形成的关键气象因子, 并将温度类、降水类、日照类3 类因子进行加权综合, 通过综合关键气象因子与气象产量的关系, 建立线性回归模型。综合关键气象因子计算公式为:

式中: M 为选定时段内同类关键气象因子的综合值, R 为选定时段内某个关键气象因子与气象产量的相关系数, E 为选定时段内同类关键气象因子进行归一化后的要素值。
3)基于气候适宜度的单产预报法: 利用冬小麦生育期内气温、日照时数、降水量和20 cm 土壤相对湿度, 从江苏省冬小麦生长发育的上限温度、最适温度、下限温度、需水量、需光性等生物学特性出发, 建立不同生育阶段的旬温度适宜度、降水适宜度、日照适宜度, 并将三者进行综合, 建立综合气候适宜度[18-19], 利用综合气候适宜度分别与5 种分离方法下的气象产量之间的关系, 建立线性回归方程。综合气候适宜度的计算公式如下:

式中: S 为旬综合气候适宜度,tS 、pS 、sS 分别为温度适宜度、降水适宜度和日照适宜度, 具体计算公式见文献[20]。
1.3.3 不同单产预报模型模拟能力评估思路
首先利用1993—2013年的样本资料, 对3 类单产预报模型进行拟合对比检验, 由于采用了5 种产量分离方法以及丰歉相似年法中又分为加权法(W)和大概率法(A), 因此一共有12 种预报模型, 分别为: 丰歉相似年加权法、丰歉相似年大概率法、关键气象因子-线性法(简称为关键L, 以下同)、关键气象因子-差值百分率法(关键D)、关键气象因子-5年滑动平均法(关键M5)、关键气象因子-3年滑动平均法(关键M3)、关键气象因子-二次曲线法(关键Q)、气候适宜度-线性法(气候适宜L)、气候适宜度-差值百分率法(气候适宜D)、气候适宜度-5年滑动平均法(气候适宜M5)、气候适宜度-3年滑动平均法(气候适宜M3)、气候适宜度-二次曲线法(气候适宜Q)。
通过对比这12 种冬小麦单产预报模型模拟值的准确率、正确率及与实际单产的相关系数, 筛选出3 类预报方法中3 个相对最优预报模型; 其次按照预报性能确定这3 个最优模型的权重, 按权重对3个最优模型的预报结果进行相加, 得到最终的最优模型综合集成预报结果; 最后利用2014—2018年的资料进行试报检验, 主要是对拟合检验中得出的3种最优预报模型和综合集成模型进行试报。另外, 所建立的统计预报模型均为动态预报模型, 因此为了比较不同起报时间对模型模拟性能的影响差异, 在拟合检验和试报检验时均选取了不同的起报时间, 考虑到江苏省冬小麦通常5月下旬开始收获, 因此选取4月10日和5月10日两种起报时间。
预报模型的平均准确率计算公式为:
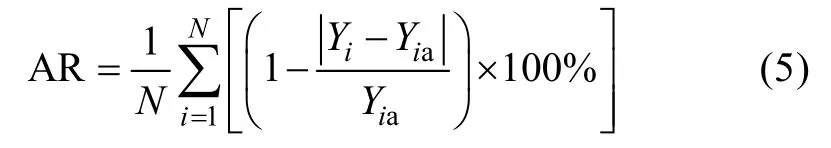
式中: AR 是平均准确率, Yi是某年的单产模拟值, Yia是某年的单产实际值, i 为拟合年中的年份序号, N 为拟合检验的样本长度(1993—2013年的样本长度为21年)。
预报模型的正确率是指预报年和上年实际单产的增减符号与实际单产和上年实际单产的增减符号一致, 则为正确, 反之错误。正确率计算公式为:
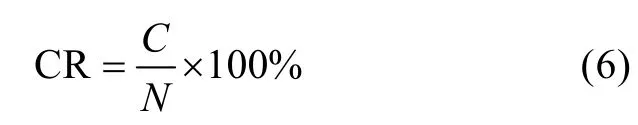
式中: CR 为正确率, C 为1993—2013年中预报年单产增减符号与实际单产增减符号一致的总次数, N 为21。
综合模型(即最优模型集成)计算公式为:

式中: Z 是综合集成模型某年单产预报值,1Y 、2Y 、3Y 分别为基于丰歉相似年预报模型的最优预报值、基于关键气象因子预报模型的最优预报值和基于气候适宜度预报模型的最优预报值, a、b、c 分别为该 3 类模型最优预报值的权重, 权重通过准确率、正确率及与实际单产相关系数进行综合排序确定, 文中按照专家经验, 排在第1 位权重赋值0.5、第2 位赋值0.3、第3 位赋值0.2。
2 结果与分析
2.1 拟合检验与模型优选
12 种冬小麦单产预报模型拟合结果表明(图1): 1993—2013年4月10日和5月10日两种起报时间下, 12 种单产预报模型均模拟出江苏全省冬小麦单产的年际总体变化特征, 2003年之前单产呈波动变化, 2003年之后单产稳步上升。各预报模型的模拟值与实际值存在不同程度的数值差异, 尤其对于异常高值年或低值年的模拟, 各模型间的差异较大, 1998年为近21年单产最低值, 除丰歉相似年加权和丰歉相似年大概率模型以外, 其余10 种模型均准确模拟出了1997—1999年间的“漏斗”型变化特征, 而丰歉相似年加权和大概率模型模拟出的最低值年出现在1999年, 2000年为高值年, 均比实际年份向后“漂移”了1年, 这种误差与该预报方法本身有关。对比不同起报时间的模拟差异发现, 4月10日(图1a)和5月10日(图1b)起报的模拟值年际变化基本一致, 仅变化幅度存在一定差异。
为筛选出丰歉相似年法、关键气象因子法、气候适宜度法中最优的预报模型, 比较分析了各模型的准确率、正确率、相关系数。图2a 为各模型的拟合准确率, 1993—2013年4月10日和5月10日两种起报时间下, 丰歉相似年法2 种预报模型的准确率范围为87.83%~91.46%(平均89.67%), 关键气象因子法 5 种预报模型的准确率范围为 94.07%~ 95.71%(平均94.86%), 气候适宜度法5 种预报模型的准确率范围为93.06%~96.17%(平均94.96%)。因此, 拟合准确率总体排序为气候适宜度法>关键气象因子法>丰歉相似年法, 关键气象因子法和气候适宜度法的5 种预报模型准确率均明显高于丰歉相似年加权法和丰歉相似年大概率法的预报准确率; 同类方法中不同预报模型进行比较, 丰歉相似年法中加权模型准确率高于大概率模型, 关键气象因子法和气候适宜度法中均是二次曲线分离模型准确率最高、线性分离模型准确率位列第二。对12 种模型准确率全部进行比较, 则是气候适宜度法中二次曲线分离模 型的准确率最高, 丰歉相似年法大概率模型的准确率最低; 4月10日和5月10日起报的12 种预报模型的平均准确率分别为93.98%、94.09%, 说明越接近冬小麦成熟期, 预报因子信息越全面, 预报模型准确率越高。
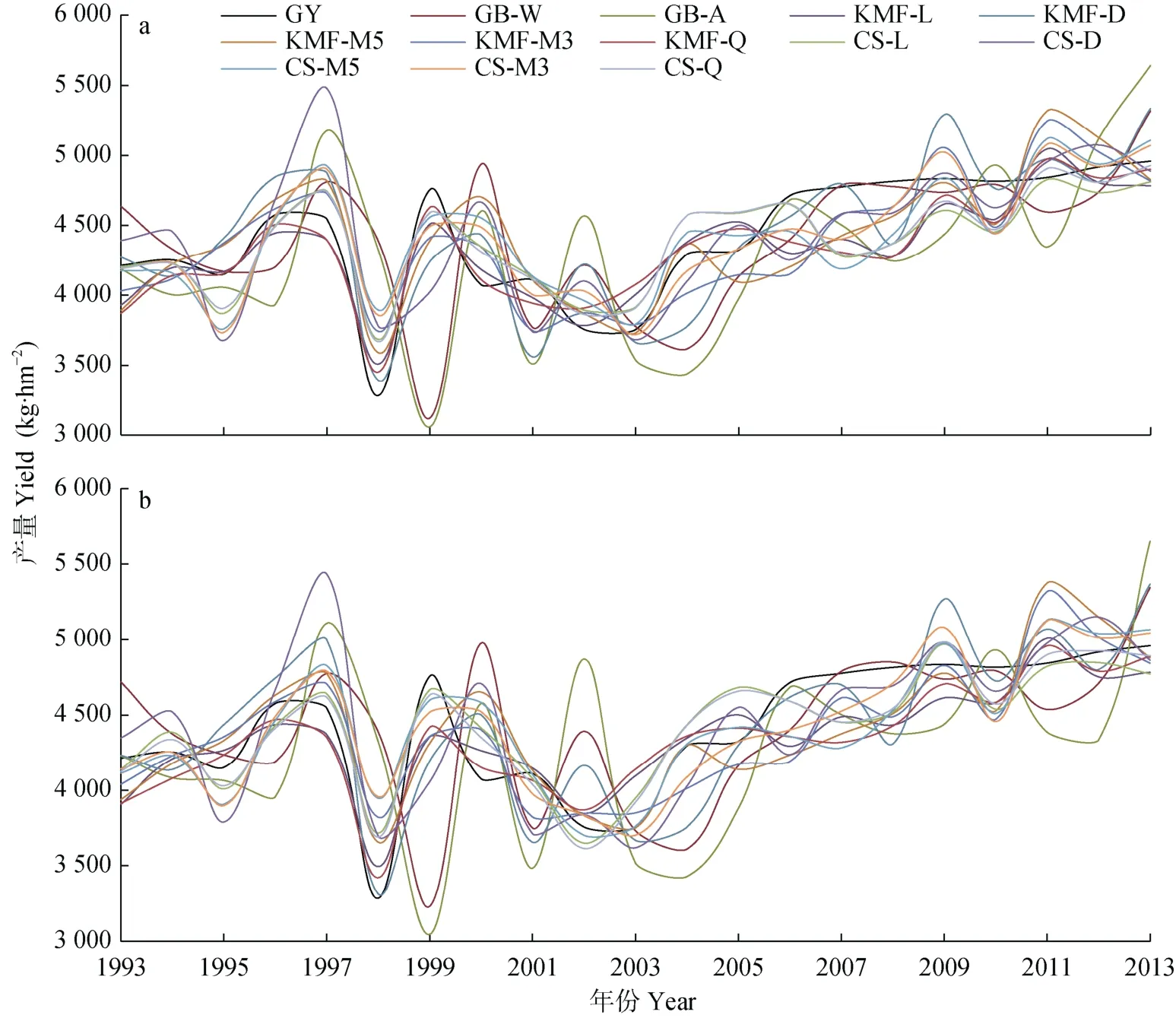
图1 1993—2013年江苏省12 种冬小麦单产预报模型历史模拟值与实际值 (a: 起报时间4月10日; b: 起报时间5月10日)Fig.1 Winter wheat yield simulated by 12 yield prediction models and actual yield in Jiangsu Province from 1993 to 2013(a: starting time is April 10; b: starting time is May 10)
图2b 为各模型的拟合正确率, 1993—2013年4月10日和5月10日两种起报时间下, 丰歉相似年法预报模型的正确率范围为 28.57%~42.86%(平均36.9%), 关键气象因子法5 种预报模型的正确率范围是47.62%~66.67%(平均59.52%), 气候适宜度法5种预报模型的正确率范围是 57.14%~85.71%(平均75.24%), 拟合正确率总体排序为气候适宜度法>关键气象因子法>丰歉相似年法, 关键气象因子法和气候适宜度法的5 种预报模型正确率均明显高于丰歉相似年加权法和丰歉相似年大概率法的预报正确率。同类方法中不同预报模型进行比较, 丰歉相似年法中加权模型正确率高于大概率模型, 关键气象因子法二次曲线分离模型正确率最高、线性分离模型正确率位列第二, 气候适宜度法5年滑动平均模型正确率最高、二次曲线和线性分离模型正确率并列第二。12 种模型正确率全部进行比较, 则是气候适宜度法中5年滑动平均分离模型的正确率最高, 丰歉相似年法大概率模型的正确率最低。两种起报时间下的平均正确率均为62.3%。正确率数值明显小于准确率数值, 说明所建立的预报模型对单产的模拟精度还有待进一步改进。
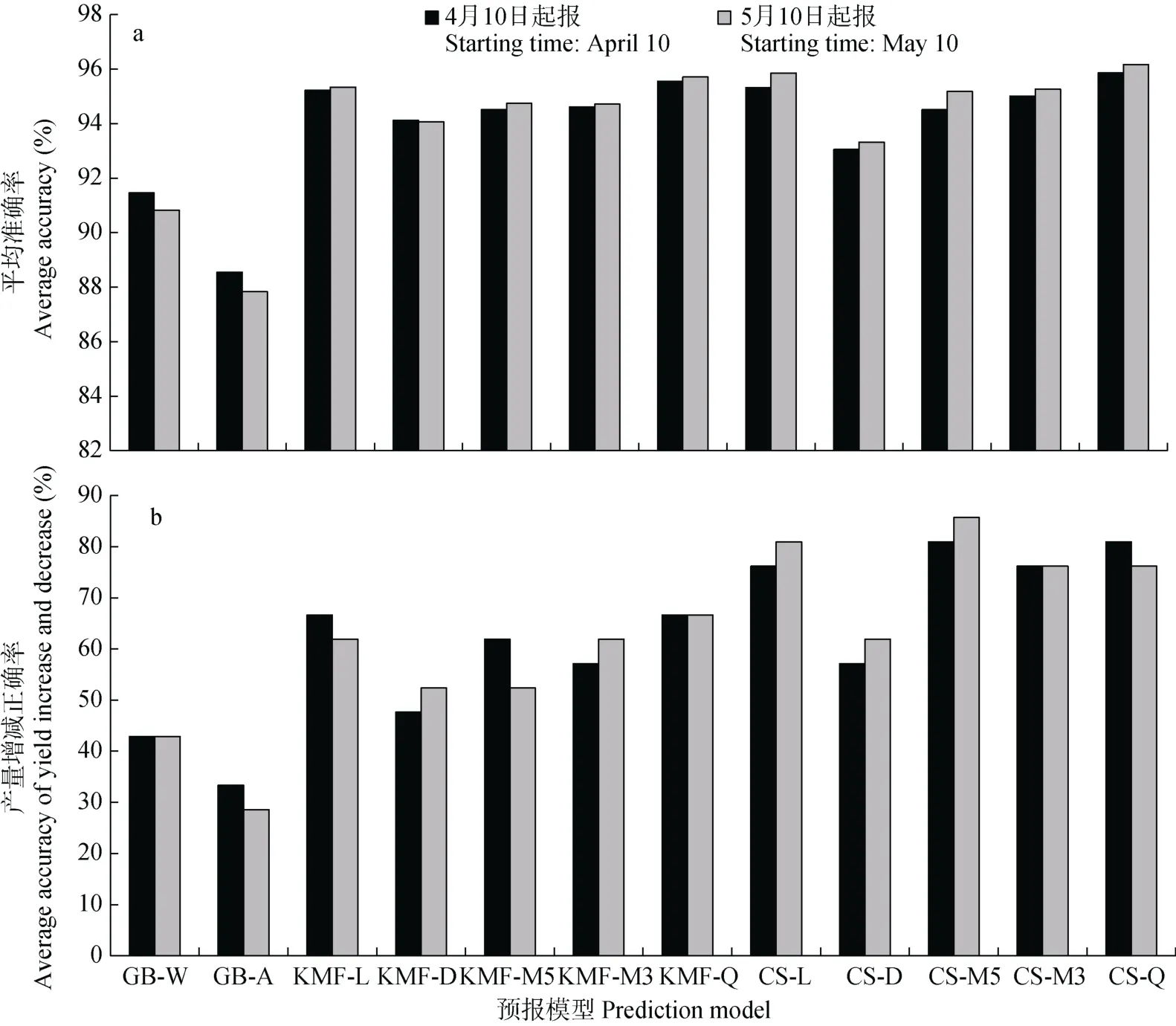
图2 1993—2013年江苏省冬小麦12 种单产预报模型的历史拟合平均准确率(a)和单产增减正确率(b)Fig.2 Average accuracy of yield fitting (a)and average accuracy of yield increase and decrease (b)calculated by 12 yield prediction models in Jiangsu Province from 1993 to 2013

图3 1993—2013年江苏省冬小麦12 种单产预报模型历史模拟值与实际值的泰勒图 Fig.3 Taylor diagrams for wheat yield between the observations and simulation by 12 yield prediction models in Jiangsu Province from 1993 to 2013
泰勒图能够将实际值和模拟值的相关系数、标准差放在一张极坐标中, 可直观且较全面地评估多个模型的模拟能力和差异[21], 当模拟值与实际值之间的距离越近时, 代表该模型的模拟能力越强。图3给出了江苏省冬小麦单产的泰勒图, 图中黑色五角星为实际单产, 12 种不同颜色的圆点为12 种预报模 型。1993—2013年4月10日和5月10日两种起报时间下, 除了丰歉相似年加权模型和大概率模型离实际值较远外, 其余10 个预报模型相对比较集中, 与观测值的标准差为0.5~0.9, 其中气候适宜度和关键气象因子的二次曲线分离、线性分离法离实际值的距离最近, 与观测值的标准差在0.5 左右, 说明这4 种模型的模拟能力较强。从模拟值与观测值的相关系数来看, 丰歉相似年法预报模型的相关系数范围是0.263~0.348(平均0.322), 关键气象因子法5 种预报模型的相关系数范围是0.778~0.887(平均0.828), 气候适宜度法 5 种预报模型的相关系数范围是0.666~0.901(平均0.807), 关键气象因子法和气候适宜度法的5 种预报模型模拟值与实际值的相关系数均通过了P<0.001 的显著性检验, 明显高于丰歉相似年法2 种预报模型的相关系数。关键气象因子法和气候适宜度法中均是二次曲线分离模型相关系数最高、线性分离模型位列第二; 12 种模型正确率全部进行比较, 则是气候适宜度法中二次曲线分离模型的相关系数最高, 丰歉相似年法大概率模型的相关系数最低。比较4月10日和5月10日两种起报时间下的12 种预报模型与实际值的距离总体相当, 平均相关系数分别是0.732、0.737, 5月10 起报的模拟效果略好于4月10日起报的。
由此可见, 经过21年的历史拟合检验, 综合考虑准确率、正确率的排序与泰勒图, 得到3 类方 法中最优预报模型分别是: 丰歉加权模型、关键气象因子二次曲线分离模型和气候适宜度二次曲线分离模型。
2.2 最优模型集成与试报检验
利用2014—2018年的资料对12 种预报模型进行试报检验, 依旧发现丰歉相似法加权模型、关键气象因子二次曲线分离模型、气候适宜度二次曲线分离模型的准确率总体高于其他模型, 正确率差异较小, 因此采用这3 种最优模型进行集成, 目的是减小各模型的预报随机误差, 增强预报值的稳定性。
由表1 可知, 4月10日为起报时间, 3 种模型中, 2014年和2016年气候适宜度二次曲线分离模型准确率排第一位, 2017年和2018年丰歉加权模型准确率排第一位, 2015年关键气象因子二次曲线分离模型准确率排第一位。5月10日为起报时间, 3 种模型中, 2014—2016年和2018年均是气候适宜度二次曲线分离模型准确率排第一位, 2017年丰歉加权模型准确率排第一位。两种起报时间下, 按照权重进行最优模型集成后, 预报准确率均得到提升, 近5年平均准确率排序为: 最优模型集成>气候适宜度二次曲线分离模型>丰歉相似年加权模型>关键气象因子二次曲线分离模型。
3 讨论与结论
3.1 讨论
关键气象因子和气候适宜度产量预报法都是基 于气象条件与产量之间的关系而建立, 而准确掌握气象条件对冬小麦产量的影响必须以气象产量的准确获取为前提, 因此选取合适的方法准确分离出趋势产量和气象产量对最终的预报结果准确与否非常关键。以往针对冬小麦产量预报的研究更注重预报方法差异对预报结果的影响[13-14,19], 忽略了产量分离方法的差异对预报结果的影响。线性分离、差值百分率、5年滑动平均、3年滑动平均、二次曲线等5 种产量分离法是目前应用较为普遍的几种分离方法。赵东妮等[15]和李心怡等[17]对这几种方法的分离效果还专门进行过对比研究, 结果表明这几种方法分离出的趋势产量与粮食产量总体增长特征相一致, 且与实际生产力发展水平较为一致, 分离出的气象产量总体能捕获出典型丰歉年中气象条件带来的产量变化。文中基于这5 种产量分离法, 分别建立了关键气象因子和气候适宜度产量预报模型, 均是二次曲线分离模型预报准确率最高, 准确率分别为95.71%和96.17%。
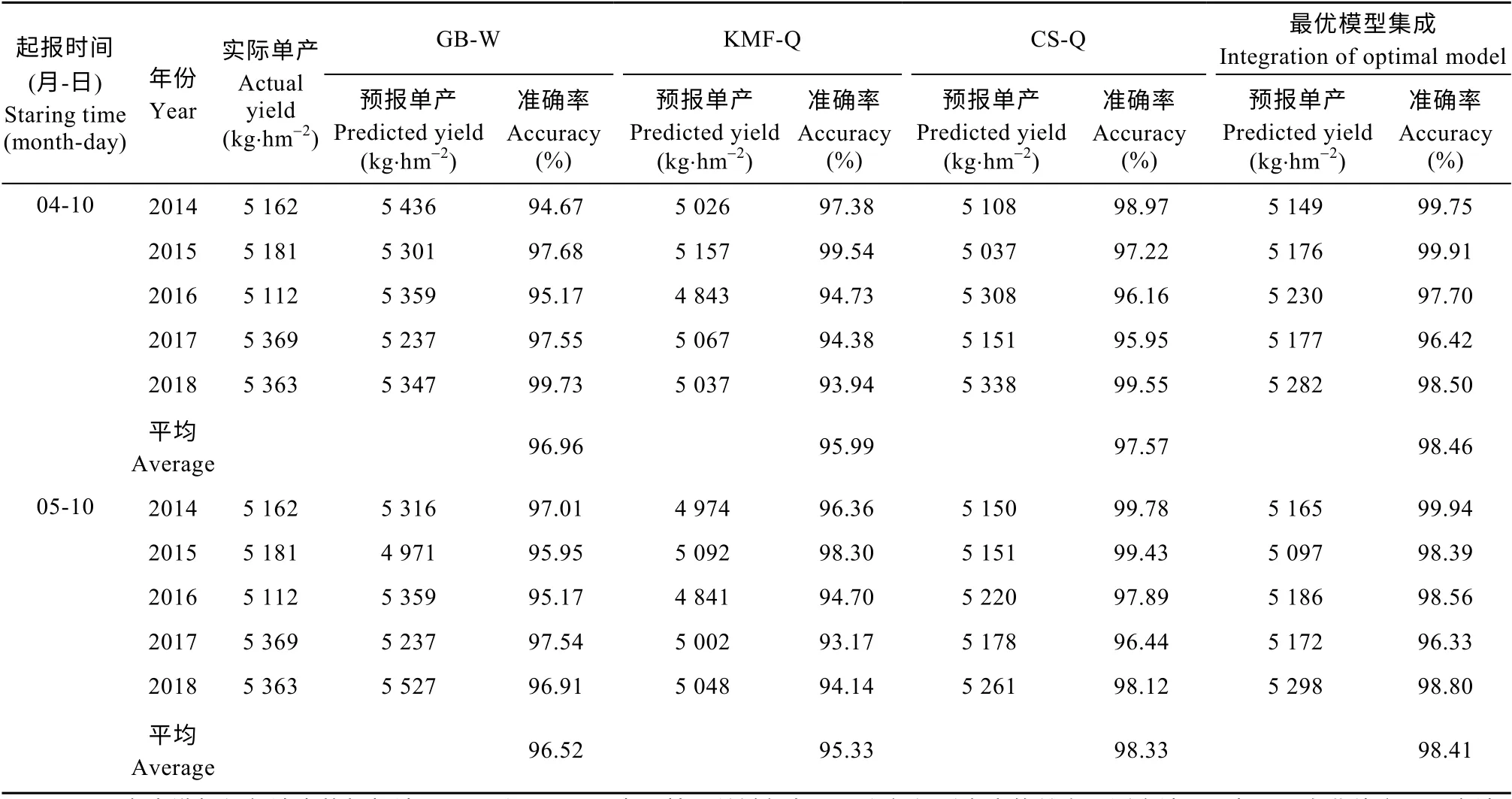
表1 2014—2018年不同起报时间江苏省冬小麦最优模型和多模型集成单产预报值与实际值 Table 1 Winter wheat yield simulated by optimal yield forecasting models and multiple model integration for different forecast starting time and actual yield in Jiangsu Province from 2014 to 2018
不同的预报方法表现出的预报性能差异与各方法的预报思路有关。丰歉相似年法是通过找历史相似年来进行单产的预报, 但要通过气象条件找到与预报年真正相似的年份存在一定困难, 因为历史样本有限, 所以该方法历史拟合准确率低于关键气象因子法和气候适宜度法、且准确率年际变动幅度明显偏大, 该方法历史拟合平均预报准确率为89.67%。关键气象因子法是考虑了冬小麦生长发育时期内关键气象因子对产量的影响, 筛选出的与单产相关性高的气象因子主要是累积降水量、积温、平均气温、累积日照时数。说明这4 个因子对冬小麦单产具有关键影响作用, 而且正负相关性与冬小麦生长过程中的生理需求比较吻合。单产与上年10月份旬动态累积降水量呈正相关, 与上年11月—当年5月的动态累积降水量呈反相关, 这与冬小麦生长过程中的水分需求是一致的, 10月份江苏省冬小麦处于播种期, 适量的降水可以保证土壤墒情适宜, 利于播种出苗, 11月后冬小麦需水量减少, 雨量越多越不利于其生长; 与累积日照时数始终呈正相关, 在生长过程中光照越充足越利于其光合作用; 与部分时段的积温或平均气温呈反相关, 在冬小麦生长前期如果气温过高容易出现旺长苗, 这对于后期产量的形成非常不利。单产与高温日数、低温日数、降雨日数、大雨日数等因子相关性不明显, 该方法历史拟合平均预报准确率为94.86%。气候适宜度法充分考虑了冬小麦生物学特性, 利用冬小麦不同生育期的上限温度、最适温度、下限温度、需水量、需光性等指标, 采用模糊数学函数计算了气象条件的适宜程度, 通过适宜度与单产之间的统计关系建立预报模型, 而丰歉相似年法和关键气象因子法是从纯统计角度进行模型的构建, 并未考虑冬小麦生长的特性, 所以无论是拟合检验还是试报检验, 总体上均为气候适宜度法的平均准确率更高, 历史拟合平均预报准确率为94.96%, 这与已有结论[22-23]相一致, 但该方法在丰歉趋势预报上具有一定的不稳定性。
经检验, 单一产量预报方法的预报结果存在一定的不稳定性, 这与邱美娟[12]研究得出的结论相一致。为了减小预报不确定性, 文中确定了最优模型集成方法, 即将丰歉相似年加权模型、关键气象因子二次曲线分离模型、气候适宜度二次曲线分离模型的预报结果进行加权集成, 结果表明最优模型集成效果好于单一最优模型, 更重要的是能减小各模型的预报随机误差, 增强预报值的稳定性。
冬小麦单产预报模型的预报性能除了与预报方法本身有关以外, 还与气象产量的分离精度有关, 因为分离出的气象产量与实际情况越吻合, 则越利于寻找气象条件与单产之间的关系, 建立的预报模型准确率则越高。所以今后可以考虑通过提高产量分离精度的方式进一步提升单产预报模型的精度。另外, 目前在进行最优模型集成计算时, 对最优模型的权重赋值是基于经验而设定, 今后可以考虑从预报准确率角度对权重系数进行科学设定。
3.2 结论
本研究在5 种产量分离方法基础上, 通过计算准确率、正确率、相关系数、标准差, 经过拟合检验和试报检验, 评估分析了丰歉相似年法、关键气象因子法、气候适宜度法及集成预报法在江苏冬小麦单产预报中的预报能力。得出如下结论:
1)4月10日和5月10日两种起报时间下, 丰歉相似年法、关键气象因子法、气候适宜度法1993— 2013年历史拟合平均准确率分别为 89.67%、94.86%、94.96%; 丰歉相似年加权法的预报准确率(历史拟合平均准确率91.14%)高于丰歉相似年大概率法(历史拟合平均准确率88.19%); 二次曲线分离法下的关键气象因子和气候适宜度预报模型的预报准确率分别为95.63%、96.02%, 均高于线性分离、差值百分率、5年滑动平均、3年滑动平均分离法下预报模型的预报准确率。
2)12 种单产预报模型均能较好地模拟出江苏全省冬小麦单产的年际总体变化特征; 从12 种单产预报模型中筛选出的3 种最优模型分别是丰歉相似年加权模型、关键气象因子二次曲线分离模型、气候适宜度二次曲线分离模型, 将3 种最优模型的预报结果进行加权集成后的近5年预报准确率在96.33%以上, 预报效果好于单个最优模型。
3)不同起报时间, 模型预报性能存在差异。对于拟合检验, 5月10日起报的准确率总体略高于4月10日起报的准确率, 说明起报时间越接近冬小麦成熟期, 预报因子信息越全面, 则预报模型准确率越高。
本研究的对比分析结果, 可为江苏省进行冬小麦单产预报时采用合理的预报模型提供科学依据, 大幅减少模型筛选时间, 通过最优模型集成可提高预报准确率, 同时模型检验思路也可供外省借鉴。
