个性化(p,α,k)-匿名隐私保护算法
2020-03-11蒲东方睿
蒲 东 方 睿
(成都信息工程大学 四川 成都 610225)
0 引 言
我们在享受信息技术发展给我们带来便捷的同时,也暴露了大量与个体相关的数据, 而这些数据被政府、商业机构等存储、发布[1]。这些数据往往隐含大量的个人信息,因此,很容易造成个人隐私信息泄露[2-3]。例如, 公开的医疗记录,可能对某位病人的隐私构成威胁。因此,如何高效地保护个人隐私数据不被泄露, 同时减少数据的损失成为了当下研究的热点问题之一。
目前,保护个人隐私信息主要有三种技术方式[4]:数据加密技术、数据失真技术和数据匿名化技术。其中数据加密技术利用加密函数将原数据转换为加密数据,提高了数据安全性,但是也极大地破坏了数据的可用性;数据失真技术是通过添加噪声的方式给数据并保持数据特性,该方法虽然保持了数据的原有的特性,但是不能保证数据安全性,还降低了可用信息数据的占比;数据匿名化技术采用不同匿名策略对数据进行压缩或者抽象,并保证隐私不被泄露的同时,又使得数据可用性最大化。因此,通常采用数据匿名化的技术实现个人隐私保护[5]。
1998年Samarati等首次提出了匿名化的概念,国内外专家对其展开了广泛深入的研究,找到防止或者减少隐私泄露同时使最大化数据可用性的方法。2002年Sweeney等匿名化概念首次提出了一种匿名的k-匿名模型[6],对发布数据划分成多个等价类且使每个等价类中至少有k个元组在准标识符属性上相同,使攻击者不能判别隐私信息所属的个体。虽然k-匿名模型方法能有效减少准标识符属性泄露风险,但是没有保护机制减少敏感属性泄露的风险,不能达到有效的保护隐私的目的[7-8]。2007年,针对敏感属性泄露问题Machanavajjhala等[9]在k-匿名的基础上提出了l多样性-匿名模型,要求等价类中敏感属性的敏感属性值至少有l个“良性”值;Li等[10]提出了t-接近模型,要求等价类中敏感属性值的分布和原数据表的分布间距不大于阈值t。之后文献[11]基于k匿名模型提出了(α,k)-匿名模型,在满足看匿名模型的前提,同时要求敏感属性值出现频率小于等于α。文献[12]在防止同质攻击思想提出了p-sensitive k-匿名模型,对等价类中每个敏感属性值出现的种类数进行限制:每个等价类中每个敏感属性值至少出现p个不同敏感属性值。这些模型提供了表级别的保护粒度,都能在一定程度上防止或者减少隐私泄露风险,但是没有考虑个人需求,造成了一些不必要的信息损失。
在日常生活中,对于不同的个体敏感度,相同的敏感属性敏感度也不一定不相同,因此,在进行个性化隐私保护就必须依据个体差异下对敏感属性值的敏感度进行个性化保护[13]。文献[14]采用个人隐私自治原则,局部敏感属性编码思想对敏感属性进行个性化泛化提出了个性化k-匿名算法。文献[15]基于l多样性-匿名模型提出了个性化(α,l)-多样性匿名模型,要求匿名后的数据满足l多样性-匿名模型的同时,多样性表的敏感属性值的频率不大于α。文献[16]提出了基于(α,k)-匿名模型建立了个性化(α,k)-匿名隐私保护模型,通过对准标识符属性进行k匿名隐私保护方法划分等价类,且将敏感属性值敏感度划分成不同的敏感组,然后对不同级别敏感度的敏感组设置不同的阈值α,从而达到个性化隐私保护的目的。文献[17]在对多敏感属性进行保护的情形下,提出了对多敏感值进行保护的个性化隐私保护算法。文献[18]提出了用聚类的方式实现个性化的一种基于变长聚类的个性化匿名保护方法。文献[5]基于p-sensitive k匿名模型建立了个性化(p,k)-匿名模型,通过对敏感属性的敏感度进行分级划分成不同等级的敏感属性值,然后对不同等级的敏感属性值泛化为不同层次的低精度的敏感属性泛化值,达到对敏感属性值个性化匿名隐私保护的目的。由此可见,个性化保护越来越受到关注和重视。
本文基于个性化(p,k)-匿名模型和个性化(α,k)-匿名模型,提出针对匿名后的数据损失度较大,和存在同质攻击的泄露隐私风险的改进的个性化隐私保护算法。根据个体间敏感程度的差异将敏感属性值进行划分成高、中、低不同的敏感级别。根据敏感属性的不同等级采用不同的匿名保护的方法:通过建立敏感属性泛化树,将高敏感度的属性值进行降级泛化,达到降低高敏感属性泄露的风险,然后针对中敏感属性和低敏感属性通过阈值α限制等价类中每个敏感属性值的出现的频率。以此降低匿名后数据的损失和隐私泄露风险,使数据可用性的最大化。
1 匿名模型
数据集中的属性根据功能可以划分为三种类别[1],第一类是标识符属性I,可以根据其属性的值唯一确定标识某一个个体的属性,例如居民身份证号属性、姓名属性等。因此,如果要进行数据发布时,就必须用某种隐藏方式保证其隐私,通常我们都会采用直接删除其属性的方式;第二类是可以通过链接其他数据表识别个体的属性或属性集合的准标识符属性QI,例如性别属性、邮编属性、年龄属性等;最后一类是可以带表个体隐私的属性我们称为敏感属性S,例如健康状况属性、收入情况属性等,不同的个体对隐私定义也不一样,因此,敏感属性的选择可能也不同。
例如,表1所示为病历的原数据表,表中属性Name的属性值是可以唯一标识个体,因此,NAME为标识符属性,发布数据时应该删除其属性避免隐私泄露;Sex、Age、Zipcode是准标识符属性,对表操作时应该匿名化操作;Disease是敏感属性。
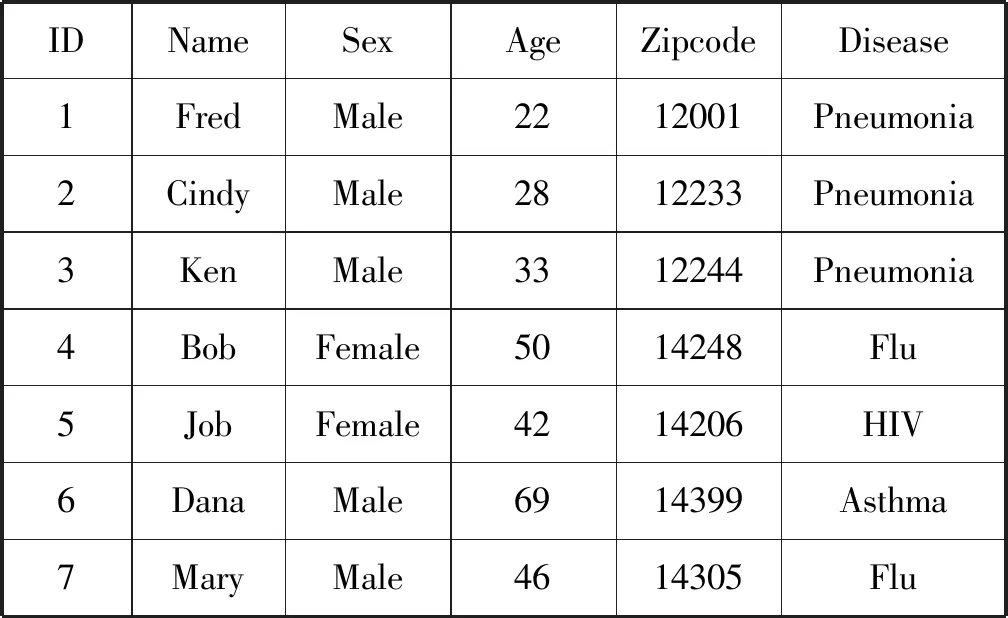
表1 原始数据表
定义1(k匿名[19])假设数据表T{A1,A2,…,An},QI是T中可以通过链接的其他数据表识别个体的准标识符属性,T在QI上的投影为T[QI],如果每组值在QI投影T[QI]至少重复出现k次,则称T满足k匿名。
定义2(等价类[19])假设数据表T{A1,A2,…,An},数据表子集取元组中准标识符属性值相同的集合,则称该集合为一个等价类。
因此,如果数据表满足k匿名,则任意一个等价类中准标识符属性上相等的元组数至少为k。
表2为2-匿名数据表,将表1中的标识符隐藏,将准标识符属性通过泛化操作输出精度较低的值。
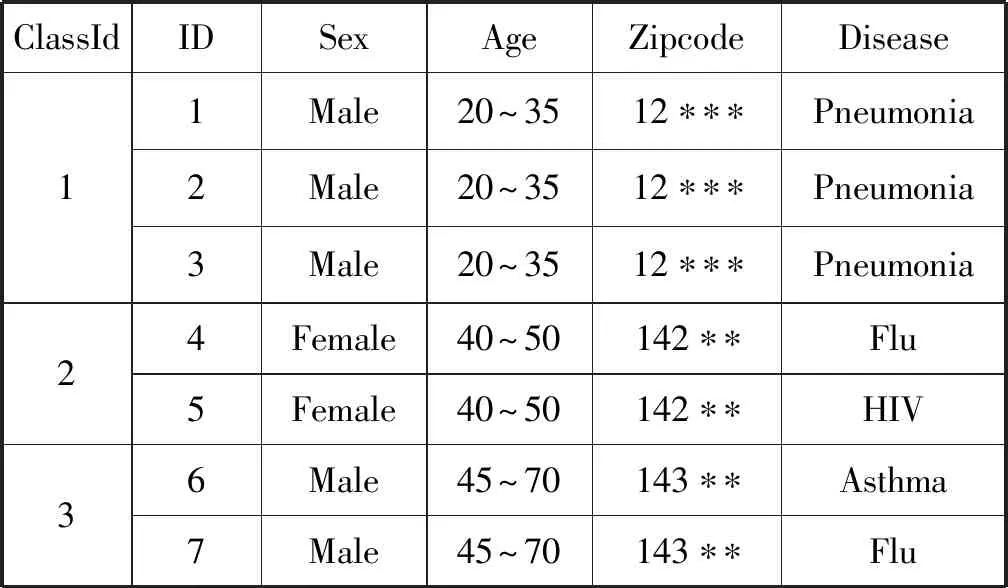
表2 2-匿名数据表
定义3((α,k)-匿名模型[16])数据表T{A1,A2,…,An},匿名后数据表T′,如果T′满足k匿名,每个等价类元组数至少为k,在准标识符属性上取值一致,且在敏感属性的取值相同取值重复出现的频率不大于α,则称匿名后的数据表T′满足(α,k)-匿名模型。
表3为(0.5,2)-匿名数据表,将表1中的标识符隐藏,将准标识符属性通过泛化操作输出精度较低的值。敏感属性使其满足每个等价类中同一敏感属性的频率大于0.5。

表3 (0.5,2)-匿名数据表
定义4((p,k)-匿名模型[5])数据表T{A1,A2,…,An},匿名后数据表T′,如果T′满足k匿名,每个等价类元组数至少为k,在准标识符属性上取值一致,且在敏感属性上不同取值个数不小于p,则称匿名后的数据表T′满足(p,k)-匿名模型。
表4为(2,2)-匿名数据表,将表1中的标识符隐藏,将准标识符属性通过泛化操作输出精度较低的值,将敏感属性泛化,并使其满足每个等价类中不同敏感属性值至少有2个。
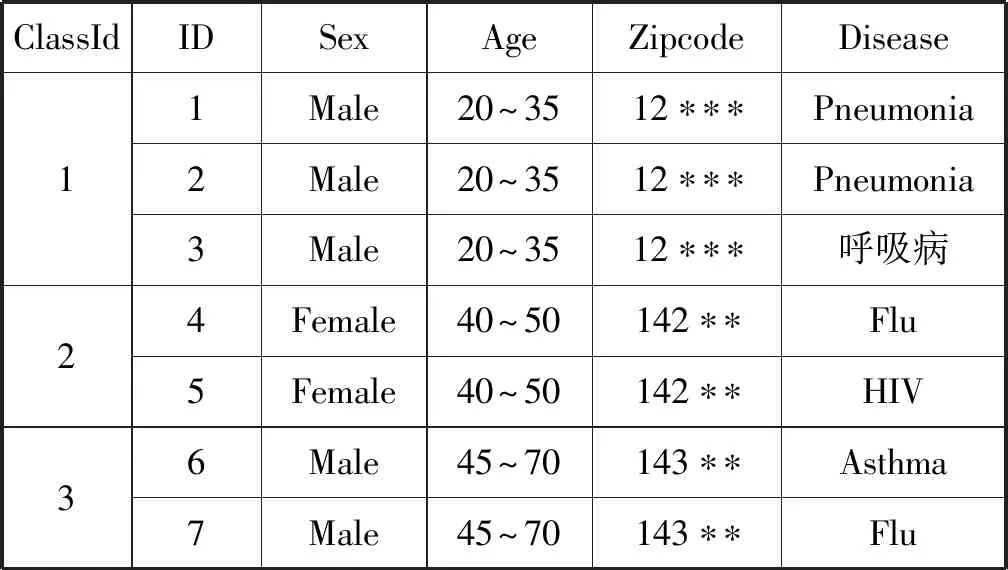
表4 (2,2)-匿名数据表
2 个性化(p,α,k)-匿名隐私保护模型
由于k匿名模型对除了标识符属性的取值进行了匿名化,虽然可以有效地防止攻击者通过链接攻击的方式泄露隐私,但存在等价类中敏感属性取值一致的情况,攻击者可以通过同质攻击的方式窃取个人隐私,造成隐私泄露,因此要对敏感属性进行保护防止泄露隐私问题。由于不同的个体的敏感属性不同且不同的敏感个体敏感度的不同,因此需要对敏感属性进行个性化隐私保护[13]。个性化(α,k)-匿名模型是基于(α,k)-匿名模型,对不同等级的敏感属性设置不同的阈值α,虽然考虑了根据敏感度进行分级保护,但是存在高敏感属性泄露的风险,例如对表1进行个性化(0.5,2)-匿名,发布的数据依然存在高敏感属性值HIV,存在背景知识攻击泄露的风险。个性化(p,k)-匿名模型基于(p,k)-匿名模型,根据不同等级的敏感属性采用不同的泛化策略:将高敏感度的属性值泛化到对应树的根节点的值;将中敏感度的属性值泛化到对应的父节点的值。其次,采用值的限定方法,使得泛化后的等价类中至少存在p个不同的属性值。这种策略虽然提供了一种对不同敏感度的敏感属性值的个性化隐私保护方法,但是也造成了巨大的数据损失,且如果数据分布相似度很高,则会有很大几率泄露隐私。例如原始表中的敏感属性取值HIV,经过个性化(p,k)-匿名后属性取值为疾病,假设HIV泛化后取值为内科疾病,保护了个人隐私。因此在对敏感属性的个性化保护的同时保证数据的可用性也同样重要,本文主要使针对高敏感属性值进行泛化,然后针对中敏感属性和低敏感属性通过阈值α限制等价类中每个敏感属性值的出现的频率,使泛化后等价类中敏感属性值分布均匀,以此降低匿名后数据的损失和隐私泄露风险。
2.1 敏感属性的敏感度划分
本文根据用户对敏感属性值的敏感度划分敏感级别,针对个体敏感性的敏感度实施分级保护。
定义5(敏感属等级),若在数据集为T,其中某个敏感属性的值集合为{S1,S2,…,Sd},对敏感属性的敏感度评定。规定当敏感度为[0,30]时为低敏感度,(30,60]为中敏感度,(60,90]为高敏感度。
表5为用户的定义敏感度。

表5 敏感属敏感度评定表
定义6(泛化属性值敏感度)假设某个泛化属性值Y,以其为根的子树其子节点集合为{S1,S2,…,Sm},则泛化属性值的敏感度为:
(1)
2.2 敏感属性泛化树
根据敏感属性的取值对其属性构建属性泛化树G,将每个原始的敏感属性的取值均存放在树的叶子结点中,根据式(1)计算属性泛化树上每个泛化节点值的敏感度。对不同的敏感级别的敏感属性值进行不同方式的泛化,规定将高敏感级别的敏感属性值泛化到中敏感级别的敏感属性值,其他敏感属性的泛化按照等价类中不同敏感属性的个数和每个敏感属性进行相应的泛化。如图1所示,敏感属性为疾病,取值为{Asthma,Pneumonia,Flu,Cancer,HIV,Measles}。若根据评分认为Asthma(哮喘)是高敏感属性泛化到下一级敏感属性值呼吸病,若不能泛化到下一级敏感度则泛化到根节点疾病为止。
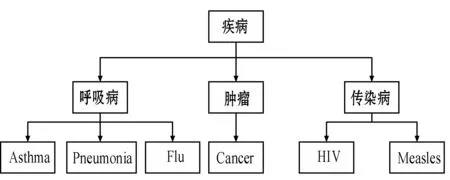
图1 敏感属性泛化树
2.3 精度度量
本文主要采用泛化技术来实现匿名操作,因此一定存在信息的损失。本文参考文献[5]的对分类型属性进行层次泛化的精度测量和数值型属性进行区间泛化的精度测量,并给出以下相关定义。
定义7(分类型属性损失度)假设某一属性值P通过泛化树泛化到节点Q,若Q节点子树的个数记为MQ,则属性值P泛化到节点Q信息损失度为:
(2)
式中:C表示P的父节点。
例如,如果将图1中Asthma泛化到了疾病节点,则P=Asthma,Q=疾病,C=呼吸病,泛化过程中子树个数序列为{M呼吸病=3,M疾病=3},因此从Asthma泛化到了疾病节点信息损失为Loss(Asthma,疾病)=8/9。
定义8(数值型属性损失度)假设某一数值型属性值P通过属性泛化树泛化为Q,泛化的区间为[L,R],则损失度为:
(3)
例如将属性年龄25泛化到25~30,泛化区间为[25,30],则泛化后损失为Loss(25,25~30)=4/5。
3 算法设计
本文提出的一种对敏感属性的个性化保护的匿名隐私保护算法为个性化(p,α,k)-匿名隐私保护算法,算法对不同等级的敏感属性采用不同的隐私方法策略:对高敏感属性进行泛化操作,避免高敏感属性值泄露。针对中敏感等级和低敏感等级的敏感属性采用个性化阈值α方法进行隐私保护。算法的大体思想是:将高敏感属性的值泛化为中敏感属性值,然后限定等价类中等级敏感属性值和低敏感属性值出现的频率不大于α,并保证等价类中不同敏感属性值的个数不小于p。
算法思想步骤:
1) 根据准标识符属性值的相似性分成每组k条记录的若干元组的集合,将每个组泛化成等价类。
2) 将每个等价类中按敏感度由高到低进行排列,并将高敏感属性值向上泛化成下一级敏感属性值。
3) 统计每个等价中的不同敏感属性值的个数是否大于p,若小于p则将相对高的敏感属性值进行泛化并使得泛化后的值的频率小于α,直到等价类中不同的敏感属性值个数大于等于p。
4) 核查每个等价类中每个属性值的频率是否小于等于α,若大于α则进行泛化操作,并使得泛化后值的频率不能大于α。
算法个性化(p,α,k)-匿名隐私保护算法。
输入待发布的原始数据表T,敏感属性敏感度评定表ST,匿名参数k,等价类不同敏感属性值个数最小参数p,每个敏感值在等价类中出现的最大频率α。
输出匿名表T′
(1) 将数据表中的所有属性依次构建属性泛化树,并根据敏感度评定表ST对敏感属性泛化树上的泛化值根据式(1)计算其泛化后的敏感度;
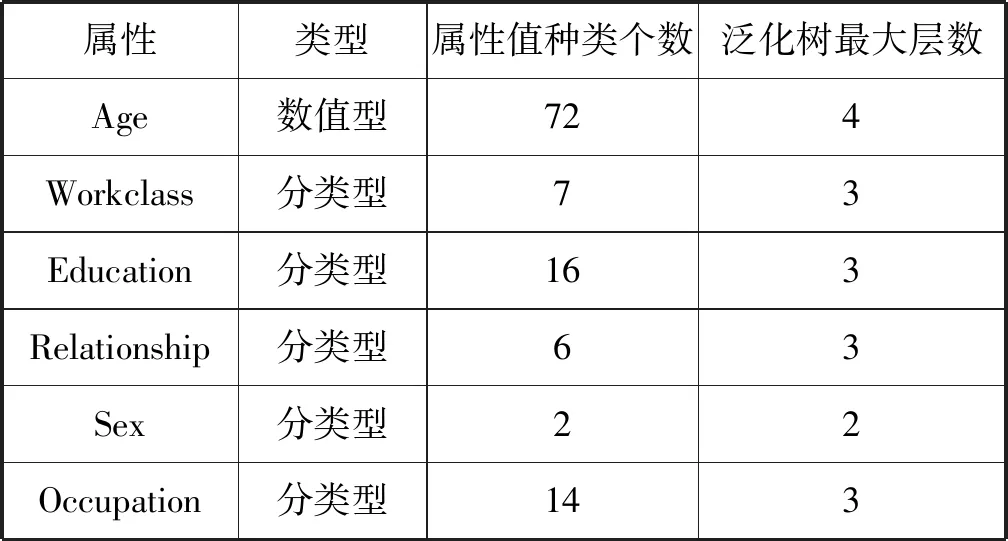
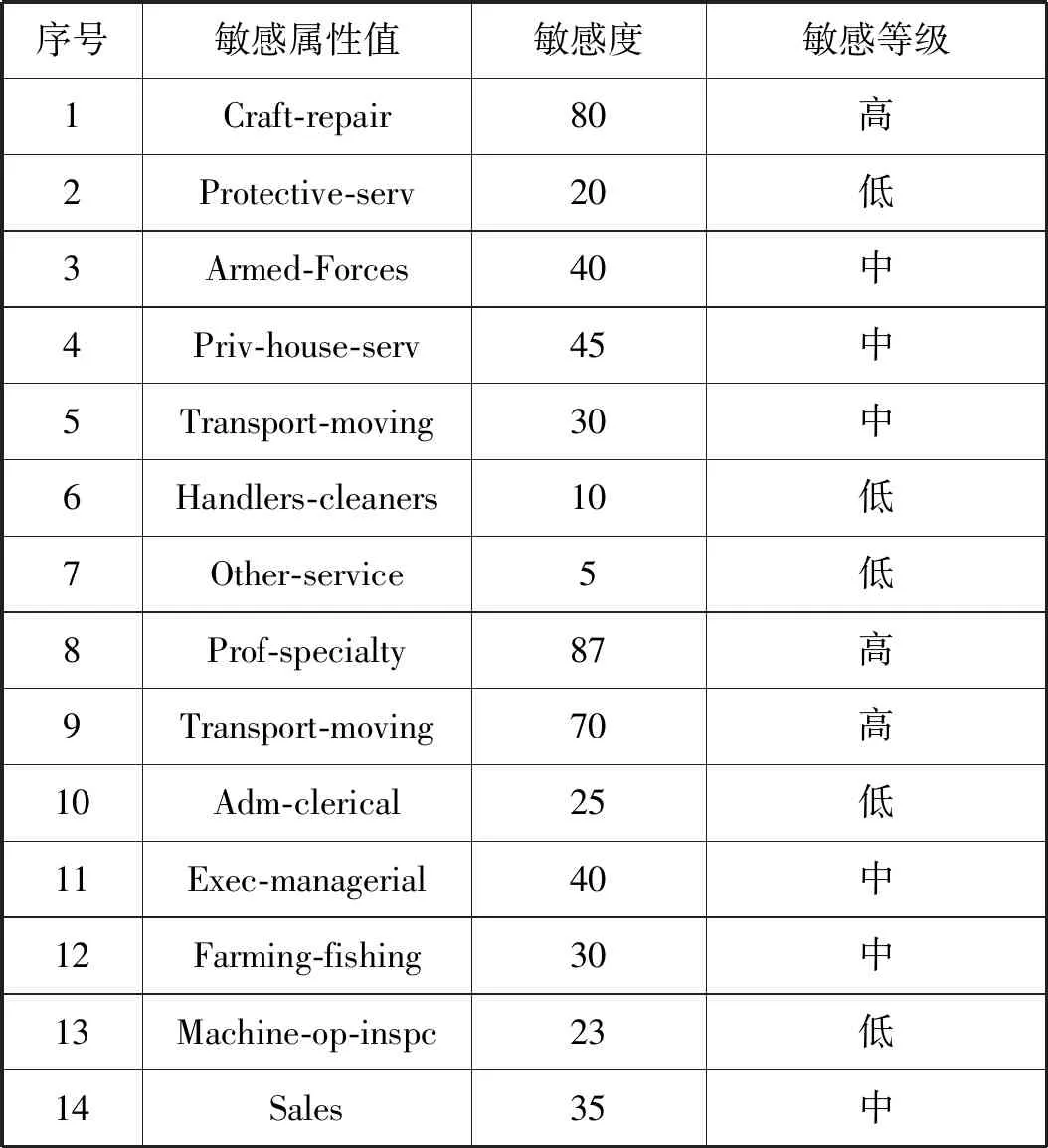
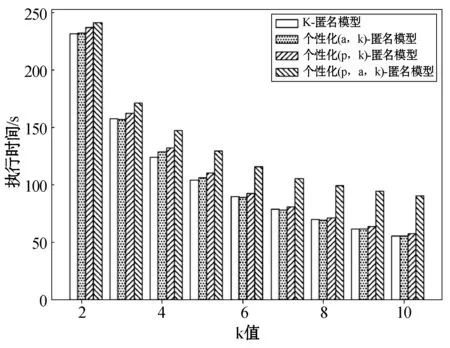
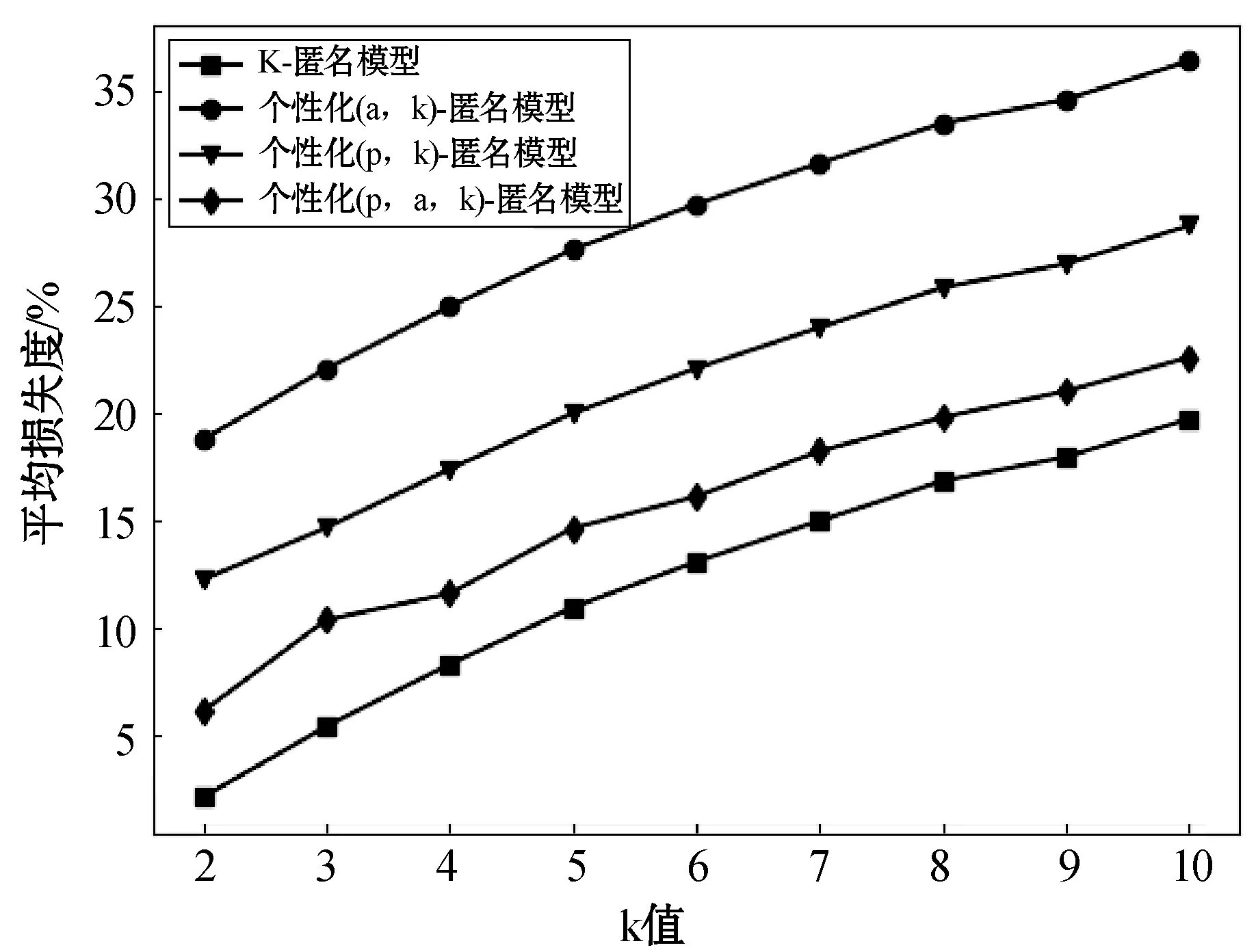
(2) 统计数据表的记录数size,若size (3) 从数据表中取出在准标识符属性值上相似度最高的k条记录元组,并将元组存放到t中,然后返回执行(2); (4) 将数据表剩余的值根据准标识符属性的相似度加入到list中的元组中; (5) 按照i从1~n循环遍历元组t={t1,t2,…,tn}: ① 若ti为非空集合,属性集合A{A1,A2,…,Am},初始化m个size(ti)大小的集合{set1,set2,…,setm},按照j从1~m遍历集合: ② 按照j从1~m遍历,若属性为敏感属性将高敏感属性泛化为下一级敏感属性值并将每个属性值ti,j存放到setj中; ③ 按照从1~m遍历集合set,若Aj为准标识符属性,则执行④,若Aj为敏感属性则执行⑤; ④ 根据setj值的分布泛化到当前属性泛化树中最小泛化的值Vj并将元组ti的当前属性的值全部设置为Vj; ⑤ 将当前敏感属性值ti[:,j]使其满足其不同敏感值的个数不小于p且每个敏感值的频率不大于α; ⑥ 返回元组t合并成匿名表T′。 实验环境:Intel(R) Core(TM) i3-6100 CPU @3.70 GHz,4.00 GB内存, Microsoft Windows10操作系统,编程语言为Python 3.6。实验选用的是UCI机器学习数据库中的Adult数据集,删除其中的缺省值处理得到共计30 162条记录,本文选取其中6个属性{Occupation,Age,Workclass,Education,Relationship,sex},其数据结构见表6。将Occupation作为敏感属性,其他的作为准标识符属性,敏感属性Occupation的属性值设定的敏感度见表7。 表6 原UCI数据集Adult数据表结构 表7 敏感属性值敏感度 实验从信息损失度与执行时间2个方面进行分析比较。主要是比较以下模型: (1) k-匿名模型:通过泛化树最小信息代价泛化构造匿名表,对定义的敏感属性不进行泛化处理。 (2) 个性化(α,k)-匿名模型:通过泛化树最小信息代价泛化构造匿名表,且对不同等级敏感度设定不同的阈值α,实现对敏感属性个性化匿名保护。 (3) 个性化(p,k)-匿名模型:通过泛化树最小信息代价泛化构造匿名表,通过对不同等级敏感度的敏感属性泛化不到不同的层次。高敏感属性泛化为根节点,中敏感属性泛化为父节点,并使等价类中不同敏感值的个数不小于阈值p,从而实现个性化匿名隐私保护。 (4) 个性化(p,α,k)-匿名模型:通过泛化树最小信息代价泛化构造匿名表,通过对不同等级敏感属性采用不同的匿名方式:将高敏感属性值泛化为中敏感属性值,然后将其他等级的敏感属性值采用阈值α进行匿名化,并使等价类中不同敏感值的个数不小于阈值p,从而实现个性化匿名隐私保护。 设准标识符属性个数为5、数据集大小为30 162,当k值改变时,比较四个匿名算法的执行时间,如图2所示。可知,随着k值的增大,四种算法的执行时间反而减小。这主要因为本文是采用从源数据集中取出准标识符属性上相似度最高的k条记录直到数据集为空为止,当k值增大时,等价类的数量减少,因此执行时间会减小。本文的个性化(p,α,k)匿名算法,因为需要满足的条件根据多样化,进行比较的次数会增加,因此比其他算法的执行时间要高。 图2 执行时间 信息损失度用式(2)、式(3)来度量,设准标识符属性个数为5,数据集大小为30 162,当k值改变时,比较四种匿名算法的平均信息丢失程度,如图3所示。四种算法的平均信息丢失程度随着k值的增加而增加,因为k值越大,每个等价类中元组的数量将增加,等价类中元组的泛化将更高,从而导致更多的信息丢失。其中,k匿名算法的平均信息丢失最小的原因是该算法仅对标识符的属性进行泛化操作,因此信息平均损失度比其他三种匿名算法低;个性化(α,k)-匿名算法对不同的敏感级别的敏感属性值设置不同阈值实现个性化匿名隐私保护,而个性化(p,α,k)-匿名算法只是对中级敏感属性值和低级敏感属性设置不同阈值,其信息损失要比个性化(α,k)-匿名算法低;个性化(p,k)-匿名算法将高敏感度的敏感属性泛化到树的根节点,中敏感度的敏感属性泛化到父节点。而个性化(p,α,k)-匿名算法采用泛化树和阈值α方法共同实现个性化隐私保护,只对高敏感度的敏感属性采用泛化树的方式泛化到父节点,其他敏感级别属性值采用阈值α方法,因此信息损失度地个性化(p,k)-匿名要低。 图3 平均损失度 本文提出了个性化(p,α,k)匿名隐私保护算法,根据敏感属性值的属性度、属性泛化树按照式(1)计算泛化属性值敏感度;通过敏感级别定义建立对敏感属性值分级,然后对高敏感度属性值采用泛化树进行降级泛化,对中级敏感属性值和低级敏感属性值采用不同阈值α限制其在等价类的频率。通过该算法匿名发布数据,虽然从时间上看,花费了比其他算法多一点的时间代价,但是从隐私和信息损失方面,降低了数据隐私泄露风险和信息损失量。4 实验结果与分析
4.1 实验数据及参数
4.2 执行时间分析
4.3 信息损失度分析
5 结 语
