大数据时代存储相关技术研究(一)*
2020-03-10
内容提要:
1 大数据时代存储系统的背景及现状
1.1 背景
首先,数据爆炸性增长使当今的存储系统面临严峻挑战。图灵奖获得者Gim Gray曾提出“数据摩尔定律”,即“人类每18个月产生的信息量,是人类之前全部信息量的总和”。随着大数据和云计算的发展,我们对存储的需求量也非常之大。根据统计,2019年全球产生的数据量已经达到了41ZB,2025年预计将达到175ZB(1ZB=1百万PB=10亿TB=1021字节)。如此多的数据,如何存储以及快速访问是数据存储领域亟待解决的问题。
其次,从国家需求来看,数据存储也需要自主创新。作为数据的载体,数据存储是新基建中最为基本的组成部分,也是关系国计民生和国家战略安全的关键基础设施。但目前国内的存储系统98%以上都是采用国外的存储芯片和硬盘,如Seagate,Western Digital的硬盘和Samsung,Micron的存储芯片。最近几年,包括长江存储等国内企业都在部署存储芯片,如长江存储今年推出了128层的闪存等。这些产业化发展的突破和进展,也让我们看到了我国数据存储领域自主可控的希望。
第三,从全球存储市场来看,数据存储产业市场庞大。根据Gartner发布的相关统计数据,如图1所示为全球半导体存储器的市场营收状况。图2所示为全球半导体细分市场状况。
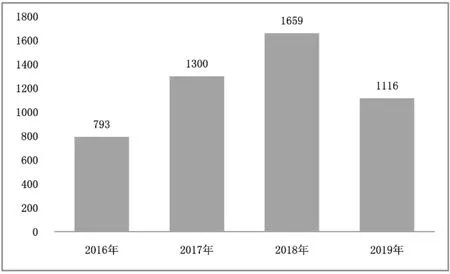
图1 全球半导体存储器市场营收状况(单位:亿美元)Figure 1 Revenue of the global semiconductor memory market(unit:US$100 million)
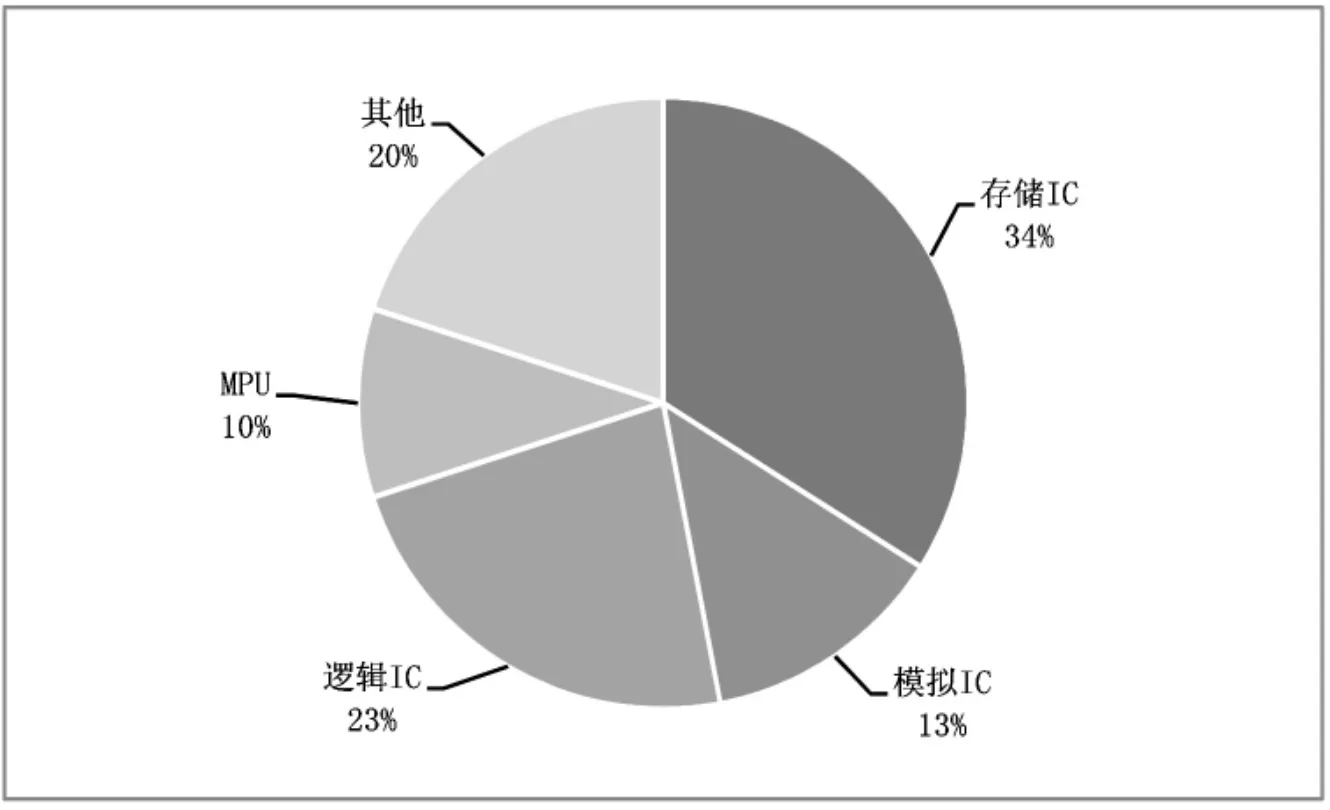
图2 全球半导体市场细分状况Figure 2 Segmentation of the global semiconductor market
可以看出,存储器是全球最大的半导体细分市场。2016年~2018年全球半导体存储器市场营收的年均复合增长率为40%。2018年市场营收超过1500亿美元,其中中国的市场规模超过4000亿人民币(进口)。受中美贸易争端及存储器价格下降影响,2019年全球半导体市场营收出现暂时萎缩。根据统计,中国占有全球超过40%的半导体存储器市场,但存储芯片的自给率只有8%。2020年长江存储的64层256Gb 3D NAND已经开始量产,未来希望有更多的自主芯片。
1.2 现状
大数据时代,对存储的要求是高性能、可扩展、低能耗、低延迟、高安全、高可靠以及数据长久保存。大数据时代对存储的需求推动了存储技术发展。
1.2.1 专用大数据存储系统
如谷歌的GFS(Google File System)系统,容量达1EB,客户端超10亿;国内如腾讯的TFS(Tencent File System)系统,容量达800PB,有8亿QQ用户和6亿微信用户。还有Facebook的专用对象存储系统HayStack,用于保存图片视频等,支持海量小文件。
1.2.2 通用大数据存储系统
由于目前做研究主要针对开源系统,所以在此仅列举一些典型的开源大数据存储系统。如充分利用集群的能力进行高速运算和存储(Map Reduce)的HDFS(Hadoop Distribute File System)系统。
在高性能计算中用得比较多的Lustre系统,是第一个基于对象存储设备的、开源并行文件系统,提供POSIX文件接口。目前该系统已被Intel收购,由Intel进行维护,并作为Intel在2020年前达成百亿亿次计算工程的一部分。目前,全球TOP100的高性能计算机70%都是采用Lustre系统,基于其开源文件系统,再加入自己的特色,如国内的“天河”超级计算机等。
还有一类就是我们通常所说的云存储,运用最广泛的就是Ceph系统,它是一个高可靠、可扩展的分布式文件系统,提供Object、Block和File三种接口方式。该存储系统是博士生Sage Weil在圣塔克鲁兹加利福尼亚大学(University of California,Santa Cruz,UCSC)实施开发的。雅虎的PB级云对象存储COS就选择了Ceph系统。
最后一个就是OpenStack系统,这是国际上的一个开源组织,最早是由美国国家航空航天局(National Aeronautics and Space Administration,NASA)和Rackspace(一家托管服务器及云计算提供商)合作研发、并联合全球的计算机厂商共同发起,是一个开源的云计算管理平台,它的底层采用Ceph的架构。
近几年,存储系统在国内蓬勃发展,对存储系统的相关研究比较多,这也是因为有比较多的开源系统可以利用,包括不少计算机厂商也在用开源存储系统进行研发。
新型存储器件的出现给大数据存储系统带来了新的发展机遇。特别是新型非易失存储技术,如PCM(Phase-Change Memory)、MRAM(Magnetoresistive Random Access Memory)、STT-MRAM(Spin-Transfer Torque-Magnetoresistive Random-Access Memory)、3D NAND Flash、3D XPoint等存储技术。但如何形成与之相适应的新的器件、芯片和设备,最后运用到大数据存储系统中,使之发挥作用,满足大数据存储高性能、高可靠、高安全、低能耗和数据长期保存等方面的需要,是未来研究和发展的趋势。所以本次讲座也将围绕非易失存储器以及怎样构成存储系统展开。
2 闪存技术
Wikibon公司在2015年就做过一个统计和预测,认为未来闪存将会逐步取代硬盘。目前,SSD(Solid State Disk)的应用也越来越多。主流的闪存单元分为浮栅单元和电荷俘获单元,通过一定外加电场作用,使闪存单元俘获/排出电荷,改变存储单元阈值电压的高低,表示逻辑0和1。其存储过程先是进行擦除,以块为单位;然后再进行读写,读写过程中以Page为单位,由若干个Page构成块。
当前,闪存技术正处于2D阵列转向3D堆叠阵列的阶段。其工艺尺寸缩小到达物理极限后,通过垂直堆叠进一步增加了存储密度,堆叠层数也逐年增加。比如长江存储,2019年推出了64层的闪存,今年则推出了128层闪存,就是通过堆叠进一步提高存储容量。除了工艺和堆叠提高存储容量,还有一个途径是使单元存储更多逻辑比特,存储密度进一步提高:使1个单元存储(Cell)从存储单个逻辑比特到存储多个逻辑比特,从SLC(Single-Level Cell)发 展 到MLC(Multi-Level Cell)、TLC(Trinary-Level Cell)和QLC(Quad-Level Cell)。但工艺上的3D堆叠阵列,以及由于存储密度提高,阈值电压区间被压缩,可靠性和编程速度都需要进一步研究和优化。
2.1 国外对闪存的研究
国际上对闪存的研究主要集中在可靠性、大页问题、垃圾回收优化、Open Channel和系统应用性能优化等几个方面。其中在可靠性问题研究上,包括硬件减少编程干扰、软件优化可靠性,如错误数据分散到无效数据;同时,当单颗芯片容量到达一定程度后,其管理的Page也慢慢从2kB发展到4kB、16kB、32kB甚至更大,也就是大页问题,主要研究如何提升大页使用效率。垃圾回收研究,如分离Flash页基于Buffer中的脏位。还有由闪存构成的Open Channel SSD的管理问题,如light NVM的研究;以及面向应用的系统性能优化问题,如KV(Key Value)SSD的多日志结构和可变大小记录数据等。
2.2 我们对闪存的有关研究
从闪存芯片的技术发展来看,2014年是闪存从2D到3D的一个拐点。从市场来看,2018年以前闪存主要被闪迪、东芝、三星、镁光、西数等国际性大企业所把控;2019年之后,才出现长江存储的闪存芯片。
我们基于闪存也开展了相关研究,但由于前期没有国产闪存芯片支持,所以都是利用国外闪存芯片开展研究。主要包括:PCIe接口SSD,支持NVMe协议;设计多款开发板;Flash子卡(3D NAND Flash,1.5TB,6颗芯片,3通道);Flash控制器,达到芯片理论速度11MB/s写入,45MB/s读取,并支持高级命令Interleave、Multiplane操作和Copyback,采用Interleave、Multiplane后速度可达50MB/s写入以及60MB/s读取;针对Flash大页,运用基于重复编程特性的多次闪存子页写入技术①Feng Y,Feng D,Tong W,et al.Multiple Subpage Writing FTL in MLC by Exploiting Dual Mode operations[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2019,39(3):599-612.;针对垃圾回收,使用SLC块加速3D MLC闪存的垃圾回收②Li S,Tong W,Liu J,et al.Accelerating garbage collection for 3D MLC flash memory with SLC blocks[C]//2019 IEEE/ACM International Conference on Computer-Aided Design(ICCAD).ACM,2019.;针对Open-Channel SSD,提出了QBLK,充分利用开放通道SSD的并行性③Qin H,Feng D,Tong W,et al.QBLK:Towards Fully Exploiting the Parallelism of Open-Channel SSDs[C]//2019 Design,Automation&Test in Europe Conference&Exhibition(DATE).2019.。
2.2.1异构融合存储设备
我们在10年以前就开始研究SSD控制器(Controller)技术,开发的第一款SSDsim到现在还在被全球学界和厂商用来做SSD控制器的模拟仿真。我们的思路就是用FPGA(Field Programmable Gate Array)来做SSD控制器,包括从最早最低端的FPGA芯片,到现在用Kintex 7的芯片,原因是我们做的这个控制器一方面是为SSD,另一方面也是为下一代非易失内存的研发考虑。如图3所示,为异构融合存储设备硬件结构。
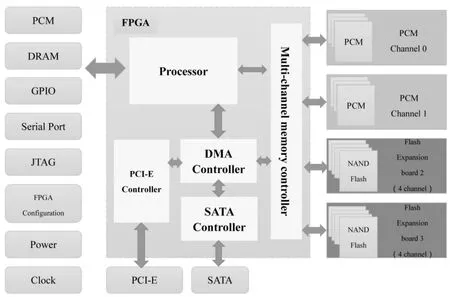
图3 异构融合存储设备硬件结构Figure 3 Hardware structure of heterogeneous converged storage devices
该平台与主机通过PCI-E接口连接,采用NVMe协议,中间是一块FPGA芯片,用子母卡方式,子卡可以是PCM、闪存、MRAM等子卡。如图3左边所示,有一系列调试接口,PCM板也可以做内存访问方式,测试其访问速度。该异构融合存储平台可支持Flash和PCM,我们利用其开展了基于闪存的SSD研究、基于PCM的内存研究以及相变存储器与闪存的混合存储研究。
如图4所示是融合存储设备原型。之所以将其称之为融合存储设备,是因为我们可以对其进行配置,如在FPGA中配置SSD的控制器(Controller),那么它就可以成为一个PCI-E的SSD;如果我们将其作为一个高速扩展内存,那么就可以将PCM或者MRAM作为扩展内存方式进行访问。设备中的子卡看起来像内存条,实际上物理接口是类似内存的自定义接口,同时FPGA里面也有CPU和微内核,可以以内存方式访问子卡。但Flash控制不是用内存访问方式。Flash子卡不支持原地修改及字节操作,磨损次数有限;而PCM或MRAM的子卡支持原地修改和字节操作,同时就有耐磨损和低能耗的特点。

图4 融合存储设备原型Figure 4 Prototype of converged storage device
融合存储控制器采用的FPGA芯片是Kintex 7系列,处理器是ARM CortexTM-A9双核处理器;PCIe接口使用gen2.0×8,理论带宽可达5Gbps×8=40Gbps;有4个DDR3 DIMM(Dual Inline Memory Module,双列直插内存模块),采用了镁光的LPDDR2-PCM芯片,直接用内存方式访问,Flash与PCM配置更加灵活。
该设备具有停电数据不丢失,支持系统快速启动、关机、恢复,可作为固态盘或扩展内存使用;低能耗,可以降低存储系统能耗;大容量,融合存储容量最高达TB级;高性能,支持NVMe协议。
2.2.2 异构混合内存体系结构研究与开发
我们和浪潮合作,利用Intel主板做了一个TB级的异构混合主存硬件,提出了TB级NVM和DRAM融合主存体系结构;用Intel的QPI(Quick Path Interconnect)总线实现多核共享,采用高速FPGA硬件控制互连逻辑;同时具有灵活可扩展NVM架构;实现多粒度、并行访问的PCM控制器以及实现支持高级命令的3D NAND Flash读写优化控制器。
在TB级异构混合主存软件调度方面,提出了异构混合主存系统地址映射方案,动态内存分区调整方案,面积优化的BCH(Bose,Ray-Chaudhuri,Hocquenghem)编译码器纠错方案及并行流水线LDPC码(Low-Density Parity-Check Codes)编译码器方案,自适应负载的垃圾回收方案及磨损均衡、坏块管理,提出了异构混合主存缓存数据一致性方案,并在ISCA(The International Symposium on Computer Architecture)、ICCD(International Conference on Computer Design)、DAC(Design Automation Conference)、DATE(Design,Automation and Test in Europe)、ICPP(International Conference on Parallel Processing)、TACO(Transactions on Architecture and Code Optimization)、TOC(Transactions on Computer)、JSA(Journal of Systems Architecture)等会议和期刊发表12篇论文和申请发明专利16项。
2.2.3 面向3D闪存的性能优化
闪存芯片的容量随着工艺进步成倍增长,闪存块容量也随之成倍增长,页大小从2kB不断增长到16kB,甚至更大。但在文件系统层,文件系统块大小仍然以4kB为主。这样的优势是降低了存储成本和具有更大吞吐量,但劣势是会造成上下层存储单元大小不匹配、存储空间与传输时间浪费。上下层存储单元大小不匹配问题,比如进行一个4kB的数据修改(update),首先要读闪存一页16kB,然后对其修改;修改完成后,再将其异地写回去,并将原页面作废,才完成1次update的操作。在此过程中,传输放大倍数为(16kB+16kB)/4kB×100%=800%,传输放大了8倍;而写放大为16kB/4kB×100%=400%,写放大了4倍。除了性能下降、存储空间浪费外,还要考虑闪存的寿命问题,因此需要减少写放大和写的次数,才能更好地利用于大容量闪存。
为了解决这个问题,现有的工作主要从优化缓存角度出发,如利用缓存进行小写合并,合并成闪存页大小后再写入闪存中,需要额外子页映射表存储这部分元数据信息,并且引入额外数据整理开销;优化传统LRU(Least Recently Used)算法,以闪存块为粒度将数据刷回介质,并且在刷回时进行页合并,最后采用LRU补偿方案提升顺序写入时LRU的效率等。
但是由于负载的时间、空间局部性不同,设备DRAM容量限制,引入的额外管理和数据迁移开销等原因,优化的程度会受限。而基于闪存重复编程特性来解决不匹配的问题,则可以避免额外写放大和对缓存大小的依赖。但同时也存在对子页管理的问题:在SLC模式时,可以很好地去写;但当MLC模式时,有些模式不能转换过去,是不能写的。考虑到SLC模式很好地支持单元状态单向从“1”到“0”的转化,绕开了随机化模块、用户写入的数据即是存储到阵列的数据,有性能和可靠性的优势,我们设计了MLC闪存的重复编程方法,利用闪存的双模特性,即闪存芯片可以在默认模式(MLC/TLC模式)和SLC模式之间进行切换。而双模式转换不当会导致数据崩溃,且带来数据碎片化的问题和降低读性能。对此,我们采取了以下技术。
(1)采用面向SLC闪存的映射粒度自适应FTL(MGA-FTL)技术
核心思想是:采用更细粒度的子页响应小写请求,擦除之前写多次的页。FTL模块采用两级映射表,对闪存页状态进行转化和采取相应的分配策略。
第一,两级映射表。由于只使用子页级映射表会成倍增加映射表占用DRAM的开销,因此采用页级和子页级混合的两级映射表方案,初始只创建页映射表,只在进行了子页小写时才创建对应子页表项。
第二,闪存页状态转换。由于已有的3种闪存页状态(free/valid/invalid)不能表示一个闪存页中部分子页被写入的情况,因此增加一个新的页状态,即部分有效(Partially Valid,PV),原先3种状态随之变化为:完全空闲(Fully Free,FF)、完全有效(Fully Valid,FV)、完全无效(Fully Invalid,FI)以及新添加的部分有效PV。
第三,分配策略。根据状态采用相应的分配策略。由于一个物理页中的数据并不是逻辑连续的,为了减少冗余数据传输,分配策略的主要思想是使用子页响应小写请求。具体策略包括:独占式分配,即一个物理页只能存储属于相同逻辑页的数据,实现更少的数据碎片化;共享式分配,即一个物理页可以存储不同逻辑页的数据,获得更高的空间利用率。
实验表明,通过此技术的优化,真实负载可以降低8%~53%的平均响应时间,合成负载降低72%的平均响应时间且小请求为主的负载效果更加显著;对于8kB大小的闪存页,减少了7.42%的写放大,对于16kB大小的闪存页,减少了30.83%的写放大,有利于提高闪存寿命。④Feng Y,Feng D,Yu C,et al.Mapping granularity adaptive FTL based on flash page re-programming[C]//Design,Automation&Test in Europe Conference&Exhibition(DATE),2017.IEEE,2017.
(2)面向MLC闪存的多次子页写入(MSPWFTL)技术
核心是想是:使用SLC模式块响应小请求,进行多次子页写入;使用MLC模式响应连续的大块请求。仍沿用两级映射表等对子页元数据进行管理,并采用SLC模式管理模块和碎片化管理模块。
1)SLC模式管理模块设计
首先,为闪存控制器添加2种模式转换接口:Erase to SLCMode(E2S),以块为转换粒度,但开销大;set Feature SLC enable(sFSe),以晶圆为转换粒度,开销小。
其次是元数据管理,记录每个闪存块当前模式以及存储的数据模式,防止SLC/MLC混用导致数据崩溃。系统断电重启后,原本SLC模式块会恢复到默认MLC模式,但其内存储的是SLC数据,因此:
第一步:判定当前闪存块模式与数据模式是否一致;若不一致,使用sFSe转换闪存块工作模式;
第二步:进行子页数据读写;
第三步:为避免影响晶圆其他数据,使用sFSe转回原工作模式。
以上通过原子操作,可以防止数据丢失。
2)碎片化管理模块设计
碎片化产生的原因是:使用子页响应小写请求,相同逻辑页数据写入不同物理页中,或者原本是整页写入,但发生小写更新,数据存储在不同物理页中。子页分配引起的数据碎片化,会导致实际读取的闪存页数目大于逻辑页数,影响读性能。因此需要对读密集型应用进行碎片化数据管理,提高设备性能。
在具体设计时,首先根据碎片整理收益临界值和平均读间隔判断是否属于读密集的数据。
第一,碎片整理收益临界值判断。根据所使用的闪存参数以及划分的子页数目,计算整理碎片收益,当逻辑页读次数大于n时进行碎片整理将获得优势:
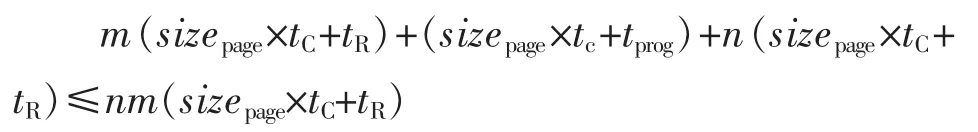
第二,平均读间隔判断。在某一负载中,读密集的数据(读次数大于n)其平均读间隔较小,读松弛的数据读间隔较大,两者差距明显。
其次对读密集的碎片数据进行整理,针对以上两个方面分别采用读密集感知的更新方法和子页合并方法,将逻辑页迁移至同一个物理页中。
实验验证表明,对于读密集型负载,读服务时间可以降低35%,有效降低了平均响应时间。对比其他方案性能,也有明显优势,响应时间平均减少了57%;划分更多子页可以获得更好的性能,但也要考虑到碎片化问题对平均响应时间的影响。擦除次数则平均减少了34.1%,写放大平均减少了52.1%。⑤Feng Y,Feng D,Tong W,et al.Multiple Subpage Writing FTL in MLC by Exploiting Dual Mode operations[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2019.
2.2.4 面向3D闪存的可靠性技术
三维堆叠结构闪存阵列被认为是闪存持续发展的可行方案,其优势是存储容量提升、更好的耐久性等,但也存在更大的单元间干扰、大页问题等。
单元间编程干扰是由于单元间的耦合作用所产生。对于2D结构来说,邻位之间的影响,只需要考虑相邻位线(X-direction)以及相同层中的相邻字线(Y-direction);但对3D结构来说,还需要考虑相邻层中的字线(Z-direction)以及相邻层中的对角线方向的干扰。
分析一款镁光的3D闪存,发现它在边界用的是SLC模式,在中间用的是MLC模式,已经考虑了可靠性的问题,但我们发现仍存在邻位之间的影响。通过抽象Y-Z视图和闪存高低页关系,得到三维阵列中的闪存页排布,如图5所示是其闪存页的排布情况。
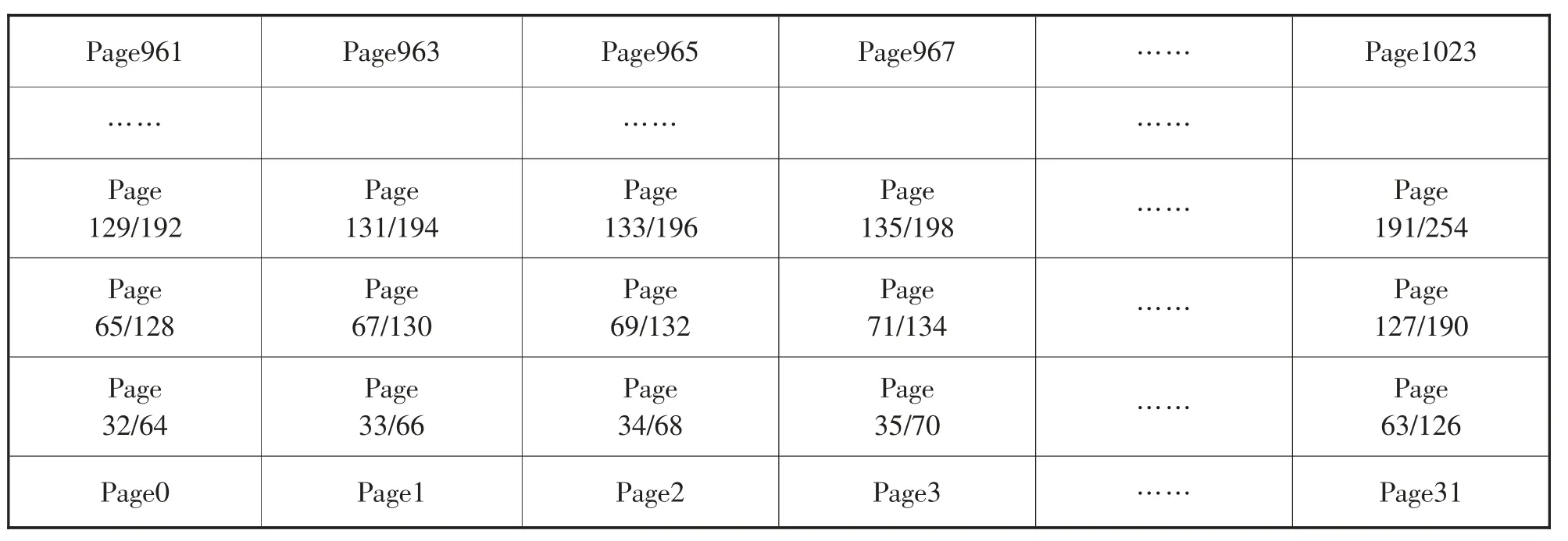
图5 三维阵列结构中闪存页排布(Y-Z方向)Figure 5 Flash memory page layout in three-dimensional array structure(Y-Z direction)
从Page1,Page2,Page3,Page4一直写到Page31。到Page32之后,先写低页再写高页,以Page33为例,当对Page34进行写入时,电压加强,产生漂移;继续往下写,写到Page67的时候也会对Page33有影响。而从高页来看,Page68和Page67、Page130都会对Page66产生影响。也就是说,低页受到2次干扰,而高页会受到3次干扰。而单元间耦合次数的增加,会产生更加严重的干扰,导致更高的比特出错率。
为了解决这个问题,可以利用单元间编程干扰与写入操作都对单元阈值电压起到增加的一致效果,缓解编程干扰带来的可靠性问题。因此我们设计了干扰补偿编程方法。根据低页、高页分别受到2次和3次干扰,列出高低页受到总干扰量的公式如下。单元受到干扰量F(n,m)=
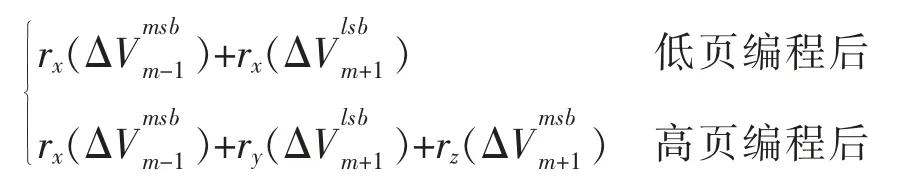
(1)干扰补偿的编程方法
首先,通过计算得到高低页随后受到的编程干扰平均大小;然后,在编程写入时判定电压值对应减小编程干扰的大小,经过后续干扰后阈值电压达到预期状态。每页具体补偿多少电压可以通过模拟进行计算。
根据干扰补充编程方法,经过“完全补偿”后的单元Vth状态是预期的理想状态。但只写入部分闪存页的闪存块中,最新写入的若干闪存页还“未完全补偿”,比特出错率高,特别是在3D闪存中未完全补偿的页数目急剧增加,影响设备可靠性。因此,需要提出针对性的可靠性保障方法,对边界页进行补偿。
(2)读电压偏移策略
对于未完全补偿闪存页出错的情况,根据出错页号可知其缺少的补偿类型及补偿次数。因此,可根据出错页号得到其阈值电压缺少量,读操作时对应降低其读判定电压,获得更优的读窗口,然后使用不同read-Retry参数调整读窗口。
(3)人工补偿策略
由于数据模式不同以及read-Retry不能完全匹配缺失的电压量,若仍发生读错误的情况,向可以为出错页进行补偿的空闲闪存页写入随机数据,以牺牲较少空间的方式提升可靠性。
可靠性保障的总体方案如图6所示。
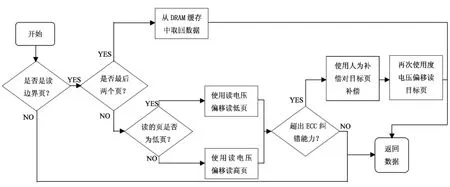
图6 可靠性保障的总体方案Figure 6 Overall scheme of reliability guarantee
经过实验验证,干扰补偿编程(DCPS)方法有效缓解了由于单元间编程干扰对原始比特出错率的影响;由于“未完全补偿”页的可靠性隐患,只使用DCPS方法效果提升有限,整体比特出错率降低了17%;结合可靠性保障方案后,比特出错率至少降低了82%。⑥Feng Y,Feng D,Tong W,et al.Using Disturbance Compensation and Data Clustering(DC)2 to Improve Reliability and Performance of 3D MLC Flash Memory[C]//2017 IEEE 35th International Conference on Computer Design(ICCD).IEEE,2017.
(未完待续)
