异构集群中CPU与GPU协同调度算法的设计与实现
2020-03-07顾文杰丁雨恒陈泊宇顾雯轩
高 原,顾文杰,丁雨恒,彭 晖,陈泊宇,顾雯轩
(1.南瑞集团(国网电力科学院)有限公司 南瑞研究院,江苏 南京 211106;2.国电 南瑞科技股份有限公司 系统研发中心,江苏 南京 211106;3.南瑞集团有限公司 智能电网保护和运行控制国家重点实验室,江苏 南京 211106)
0 引 言
近年来,大规模CPU/GPU异构混合并行系统在云计算、大数据、人工智能等科学计算领域获得了广泛应用,但其复杂体系结构为并行计算的研究提出了巨大挑战[1]。
文献[2-6]研究实现的CPU/GPU并行计算模型仅支持节点内调度,且执行效率受限于节点计算性能。文献[7,8]讨论了同构集群环境下的并行计算,未考虑异构环境中各节点间不同计算能力下的差异化任务数据分发及计算节点内CPU/GPU二次协同调度问题。文献[9,10]讨论了异构集群环境下的编程框架,但任务的分配需要预先规划,不适合大量离散任务动态产生的场景。文献[11]设计的系统解除了GPU应用程序和MPI通信程序的耦合,未考虑异构集群系统中差异化计算资源条件下的数据动态调度及精确化通信控制问题。综上所述,研究文献存在以下不足:①CPU和GPU计算任务的分配相对的割裂开来,未考虑协同并行计算的问题;②未讨论异构集群系统中差异化计算资源情况下,动态调度计算任务的问题;③MPI通信未考虑计算任务的细粒度划分和多次精确化通信控制。
本文研究了基于异构集群系统的节点间调度和节点内CPU与GPU协同并行计算的问题,设计并实现了基于两级调度的CPU与GPU协同计算的动态调度算法。算法解决了节点资源异构情况下差异化任务数据调度分发及节点内CPU/GPU动态调度协同并发计算的问题,避免了单节点木桶短板效应造成系统级任务长尾现象。实验测试结果表明,使用本文算法的效率比MPI框架效率提高了11倍。
1 MPI框架下的多节点GPU并行计算特征
MPI(message passing interface)是分布式并行计算环境下消息传递的标准接口,Open MPI是一个开源高效的MPI实现,提供了并发和多线程应用服务[12,13]。
本文研究时使用了openmpi的最新版本3.1.2对MPI并发任务进行了计算任务数据的分发测试,以适合GPU高并发处理的矩阵相加作为计算用例来测试计算时间。本文计算任务数据均以流式数据作为源数据,采用分批方式处理,单批次处理的数据量大小以矩阵块单元(大小为16 M)为单位进行设定。系统配置4个节点,并发进程数设置为4。主进程(rank=0)所在的节点担任分发任务,同时也作为计算节点。其它3个节点均担任计算任务,为计算节点。计算任务数据分发采用MPI Scatter一对多通信方式。本批次处理计算任务数据量设置为1600 M(100矩阵块),4个节点均承担数据接收任务和并行计算任务,每个节点默认接收到的并行计算任务数据量为400 M(25矩阵块)。数据分发过程中对每个计算节点的网卡I/O情况进行监视。得到每个节点的网络IO特征如图1所示。图1中横坐标是时间,单位是s;纵坐标是网卡流量,单位是KB/s。实线是网卡输入流量,虚线是网卡输出流量。
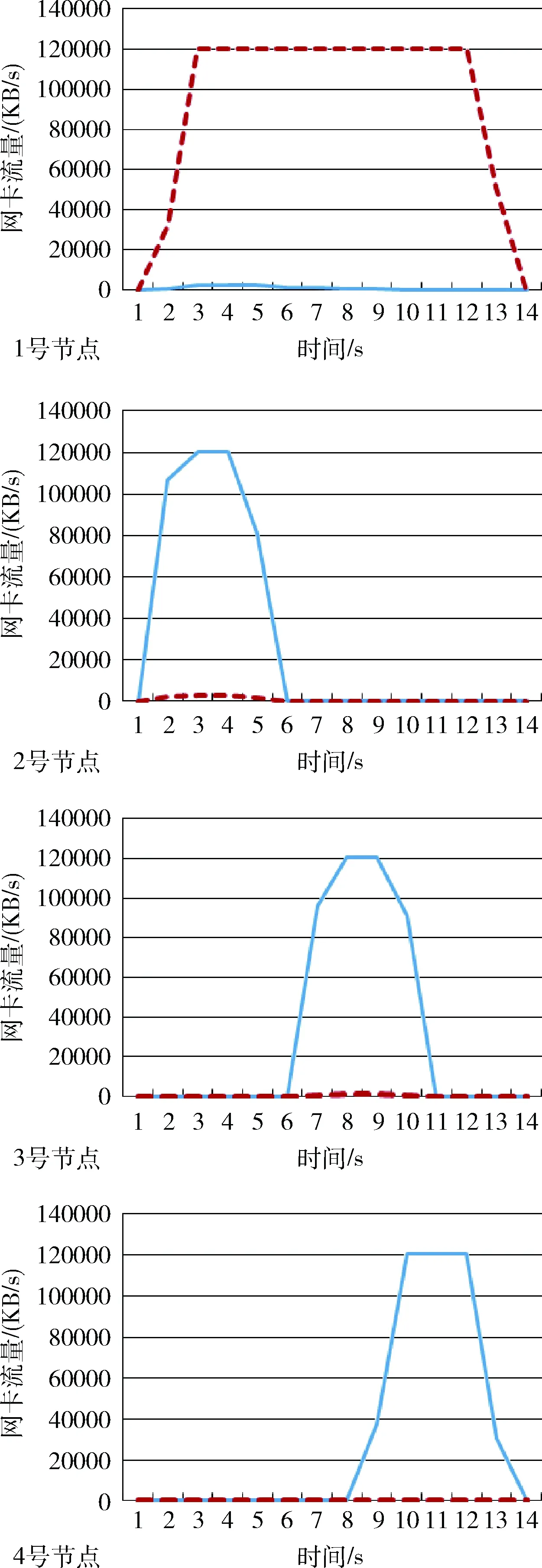
图1 MPI Scatter分发数据的网络I/O特征
从图1中可分析得出以下MPI Scatter分发任务数据的网络I/O特征:
(1)主进程(rank=0)所在的1号节点一直有网络流量输出,说明其持续进行数据分发,此外,其它节点均有网络流量输入,说明其它节点均承担数据接收的任务;
(2)主进程不间断发送数据,各数据接收节点串行接收数据;
(3)各数据接收节点在主进程开始分发数据一段时间后才开始网络数据的接收。
在研究过程中使用多种文件大小进行测试,虽然曲线在每次测试中的开始、结束时间不一样,最大值也不一样,但都符合以上特征。从特征中可分析出MPI框架分发数据的如下几点缺陷:
(1)主进程(rank=0)所在的1号节点顺序分发数据,其它计算节点串行接收数据,未接收数据前,计算节点处于等待接收数据的状态,造成计算资源的闲置和浪费;
(2)没有考虑到系统的异构性,计算性能较强和较弱的节点接收到的计算任务数据量是一致的,即承担了相同的计算任务量,这种情况下,计算性能差的节点将拖慢整个计算任务的执行过程,导致任务长尾现象。
图2是各节点任务数据计算的GPU使用率特征曲线图。图中横坐标是时间,单位是s;纵坐标是GPU使用率,单位是百分比(%)。
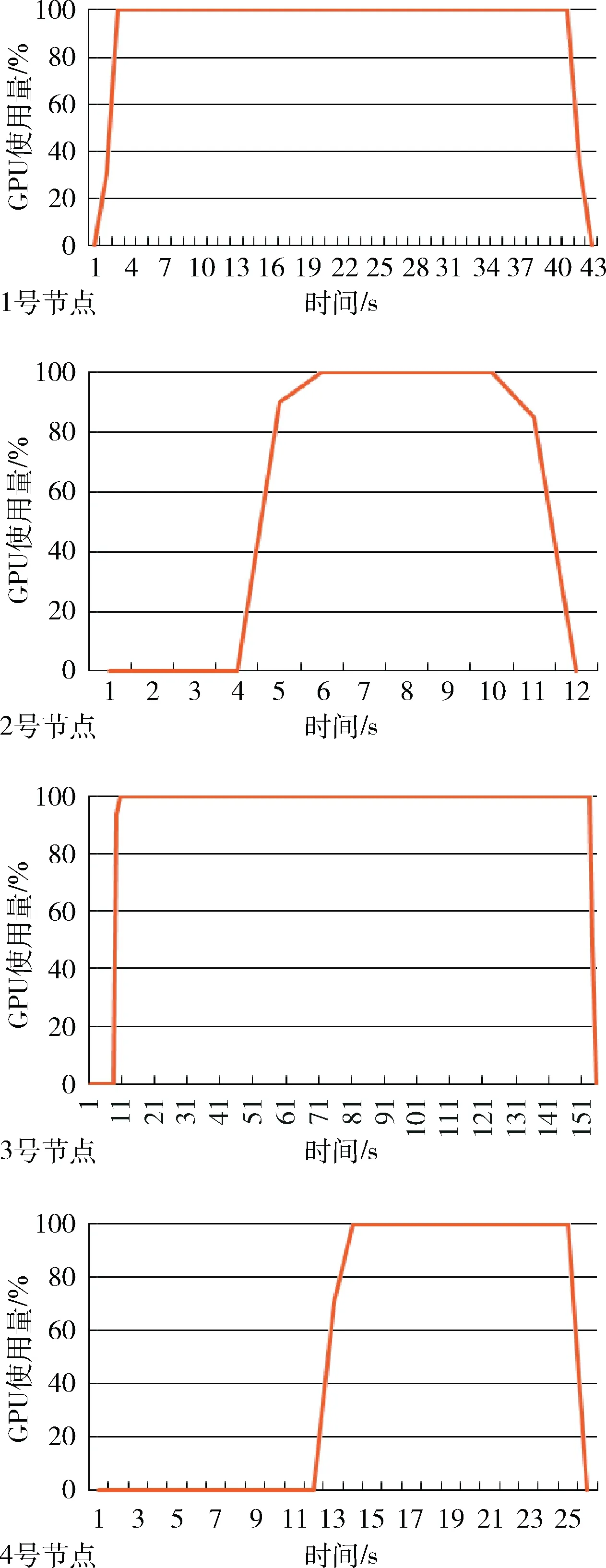
图2 GPU使用率特征
图3是各节点的数据接收等待时间、数据传输时间和GPU并行计算处理时间的特征堆积条形图,该图标识了图1 和图2的数据接收等待、数据传输和任务执行的顺序及持续时间。图中横坐标是时间,单位是s;纵坐标是计算节点;不同的填充图案分别表示等待时间、传输时间、处理时间。
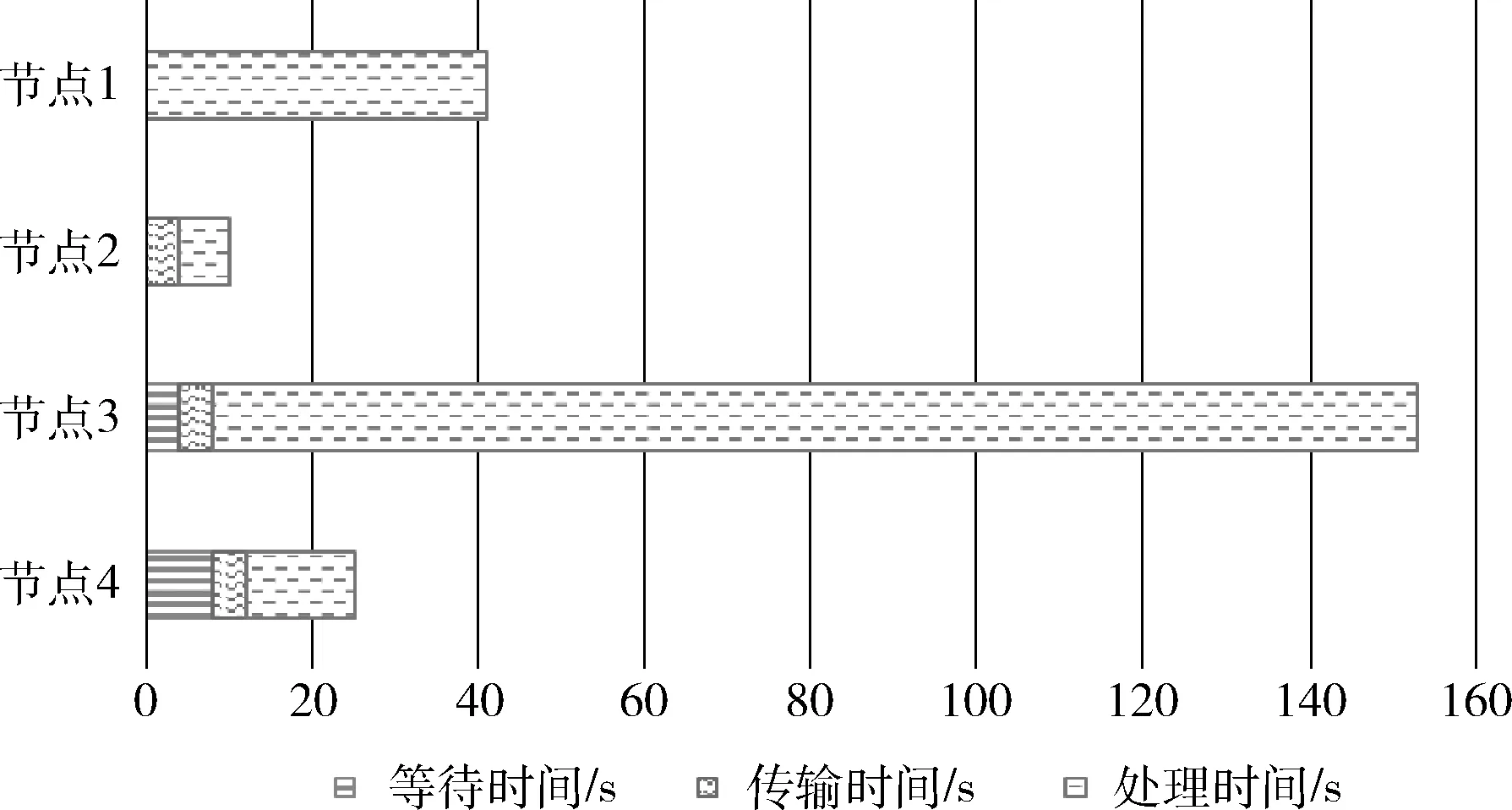
图3 等待时间、传输时间、处理时间概化图
从图2和图3可以看出主进程(rank=0)所在的1号节点在数据读取完成后,立即开始了GPU并行计算。其它计算节点在不同的等待时长后,开始接收网络数据,数据接收完毕后开始GPU并行计算。3号节点和4号节点等待的时间较长。1号节点和3号节点由于GPU计算性能较弱,拖慢了整个计算任务的计算过程,导致任务的长尾现象,其中3号节点的长尾现象比较明显。
从图4可以看出,CPU计算资源没有得到充分的利用,CPU只是完成了简单的数据接收、数据预处理及计算结果整合与反馈,承担的工作量相对不饱满,资源闲置浪费。
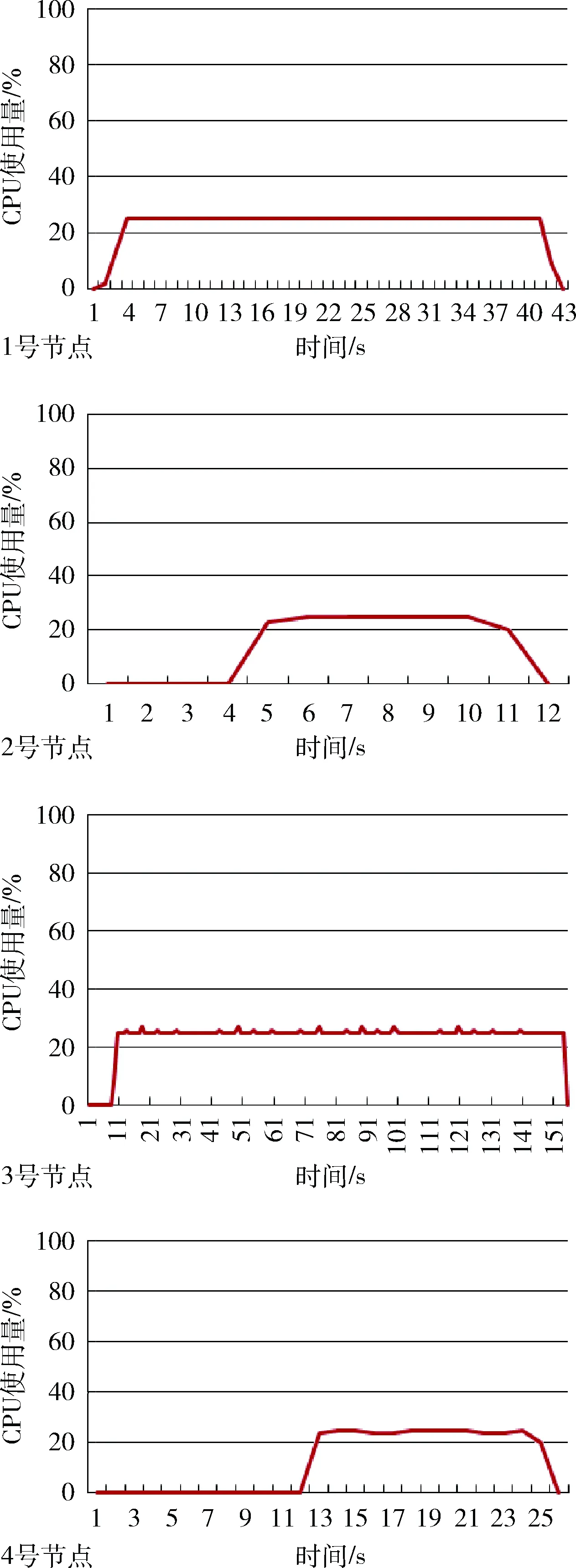
图4 CPU使用率特征
2 支持异构集群的CPU与GPU协同调度算法
2.1 算法的软件框架
CPU从单核发展为多核,大幅度提高了处理器性能,擅长处理控制密集型任务。本文中CPU参与并行计算任务均采用多线程方式。GPU是显卡的核心,天生众核,适合运行密集型并行计算的程序。CPU和GPU的功能互补性使CPU+GPU的异构并行计算构架得到了迅速的发展[14]。
本文算法的设计思想是考虑系统资源的异构性,实现了基于两级调度的CPU与GPU协同计算的动态调度算法,让性能弱的节点处理较少的计算任务,性能强的节点处理更多的计算任务,有效提高CPU/GPU异构混合并行系统的整体并发度,减少任务执行时间。算法的主要内容分为3个步骤:①节点计算能力综合测评,算法在各计算节点的CPU和GPU上分别处理单位矩阵测试任务,根据各节点返回的CPU和GPU计算耗时进行分析,获得节点内 CPU/GPU 计算能力比值、各节点综合计算能力比值、各节点处理单位矩阵任务综合耗时(以下简称节点处理能力)以及集群单位时间内综合计算能力;②计算任务全局动态调度,算法将当前计算任务以单位矩阵为单元进行细粒度划分,再根据节点计算能力测评信息在集群内实时动态调度,实现计算节点“能者多劳”,保证整个系统并发运行和负载均衡;③计算任务节点内协同调度,一方面算法在各计算节点上建立数据缓存队列和数据处理队列,数据缓存队列主要向全局调度模块请求数据,数据处理队列主要负责向CPU和GPU输送数据进行处理,在数据处理队列为空的情况下,队列角色动态切换,保障数据传输和数据处理并发性,避免节点资源的闲置;另一方面算法根据节点综合计算能力测评中CPU和GPU处理能力进行动态任务调度,完成节点级的协同调度。
本文调度算法的软件框架如图5所示。
图5中的全局调度模块可独立部署,也可部署在计算节点上,节点调度模块分别部署在每个计算节点上。全局调度模块负责各计算节点资源和工作状态监视信息的收集工作,并完成系统内工作任务的动态调度。节点调度模块使用两个数据队列,分别完成向全局调度模块实时请求数据并缓存,和向CPU、GPU输送待处理数据的工作。与此同时,节点调度模块完成节点上CPU和GPU计算任务的协同调度工作。
2.2 算法设计思想
现有技术中CPU/GPU异构混合并行系统进行任务调度方面的研究一般是采取对各种类型硬件的计算能力或者是任务在各类处理器上的运行时间进行预测,然后进行一次性任务分配。这种方法缺项明显,因此预测可能不够准确,会造成各个计算节点的结束时间不一致,造成有些节点有长尾现象,其它节点可能在最后阶段空闲,没有充分发挥集群的计算能力,任务完成时间没有达到最短。针对这些问题,本文算法设计思想如下:
(1)在全局模块调度中,进行硬件计算资源CPU和GPU的状态监视,在任务执行之前运行单元矩阵测试任务,保证对集群整体和各节点进行精确化的计算能力测评,为计算任务数据在全局和节点内调度提供可靠的任务分配权重;
(2)在全局模块调度中,计算任务数据以单位矩阵为单元进行细粒度划分。各节点单次计算任务的矩阵块数依据节点处理能力进行不均等动态划分;
(3)在节点调度模块中,设置数据缓存队列和数据处理队列,并发完成数据缓存和数据处理任务,避免节点资源的闲置;
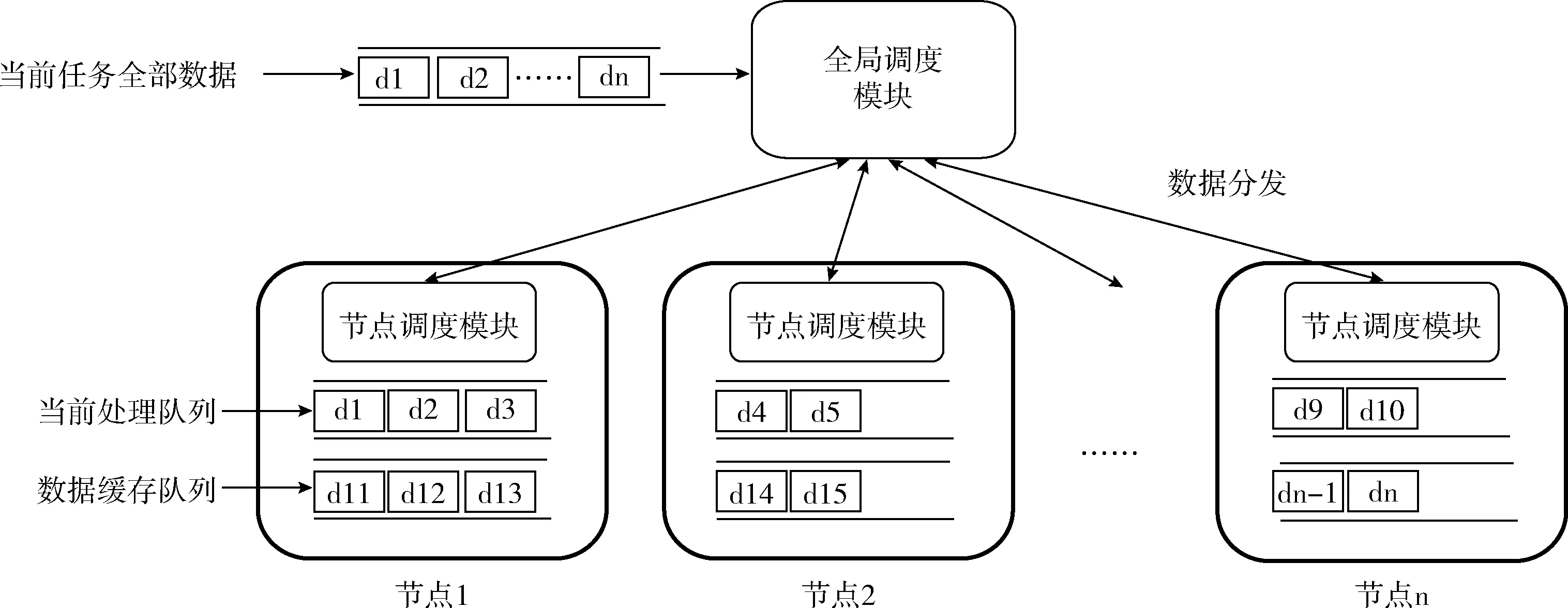
图5 调度算法的软件框架
(4)在节点调度模块中,根据计算节点上CPU和GPU的计算处理能力,按比例分配矩阵块,进行协同调度和并行计算。
2.3 算法描述
算法的执行过程就是各个计算节点从全局调度模块分多批次动态获取数据,并在节点内部的CPU与GPU之间动态调度数据的过程。下面具体描述算法的步骤,假设全局调度模块所在的节点也作为一个计算节点。
步骤1 全局调度模块在调度任务前,先将单位矩阵测试任务数据分发到各计算节点,各计算节点通过节点调度模块,把测试数据分别在的CPU和GPU上执行,获得集群内各节点CPU、GPU计算耗时;
步骤2 全局调度模块根据集群各节点测试矩阵任务的CPU、GPU计算耗时,计算出节点处理能力、各节点综合计算能力比值以及集群综合计算能力,作为全局动态调度依据。节点调度模块根据节点内CPU、GPU计算耗时得出节点内CPU、GPU计算能力比值,作为节点内计算任务调度依据;
步骤3 全局调度模块将计算任务数据以单位矩阵为单元,依据节点处理能力,进行不均等动态划分;
步骤4 节点调度模块所在的各计算节点请求数据时,全局调度模块依据各个节点的处理能力值,按比例分发与其计算能力相匹配的矩阵块数到各计算节点,权值越高的节点分得的越多,等待先完成计算的节点再次进行请求,保证整个系统并发运行和负载均衡,避免一次性分发完毕造成的某些节点的长尾现象;
步骤5 节点调度模块在各计算节点内设置两条节点级数据存储队列,节点调度模块在两条数据存储队列之间动态切换队列角色(数据缓存队列和数据处理队列之间按照调度策略进行角色转换)和向全局调度模块请求计算任务数据,具体伪代码如下所示:
START:while (全局调度模块计算任务数据 > 0) do
if 数据队列1size == 0 && 数据队列2size == 0 then
向全局调度模块请求数据,存入数据队列1,数据队列1角色转变为数据处理队列,数据队列2转为数据缓存队列
开启线程循环监视数据缓存队列,当数据缓存队列为空、网络空闲、全局调度模块计算任务数据>0时,循环请求数据存入数据缓存队列
endif
if 数据处理队列size != 0 then
for i = 0 to 数据处理size/(CPU+GPU处理能力权值) do
根据本节点CPU和GPU处理能力权值按比例分发处理
else
if 数据缓存队列size != 0 then
数据处理和数据缓存队列角色对换
else
goto START
endif
endif
步骤6 步骤5中根据本节点CPU和GPU处理能力权值按比例分发处理,即计算节点的CPU从当前处理队列中获取数据开始处理时,选择一部分数据并根据本节点的CPU和GPU处理能力权值按比例分发到CPU和GPU进行处理;当GPU空闲时继续迁移数据到GPU进行处理,对CPU的调度同理。同时在队列上进行加锁处理,避免两个处理器获得重复的数据,直至当前处理队列中的数据为空。实现了节点上的数据在CPU和GPU间动态调度,保证了一个节点的CPU和GPU的充分并发执行和负载均衡;
步骤7 当数据缓存队列为空,节点调度模块立刻向全局调度模块请求下一批数据,如果全局调度模块返回空数据集则说明全部数据已经分发完成,当前处理队列的数据全部处理完成后,当前计算任务完成。
算法分发测试任务到各计算节点,运行任务并计算CPU和GPU的处理能力比值的计算量和计算节点数量线性相关,即复杂度为O(n)。全局调度模块依据节点处理能力拆分计算数据的计算量和数据量大小线性相关,即复杂度为O(n)。计算节点向全局调度模块请求计算任务数据的复杂度为O(1)。节点调度模块依据CPU和GPU处理能力权值在节点内部动态分发数据的计算量和数据处理队列数据量大小线性相关,即复杂度为O(n)。因此本文算法的总体复杂度为O(n)。
2.4 算法实例分析
下面以4个节点构成的CPU/GPU协同调度集群,单批次处理数据量设置为1.6 G(100矩阵块)进行CPU/GPU混合并行计算的场景举例,具体分析本算法的CPU/GPU协同调度流程,如图6和图7所示。
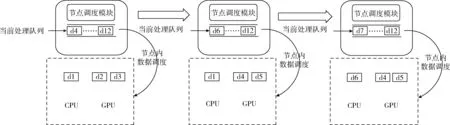
图7 节点级调度模块数据调度
图6是全局调度模块数据分发,图7是节点调度模块数据调度,图8是两种类型数据存储队列角色轮换。为了充分利用计算资源,图6中全局调度模块所在的节点同时部署了节点调度模块,也作为计算节点,承担计算任务,图6中其它节点只部署节点调度模块,作为计算节点,承担计算任务。

图8 两种类型数据存储队列角色轮换
算法开始时全局调度模块和各计算节点的节点调度模块通过心跳保持通信,实时监视集群中各节点的运行状态,同时收集各计算节点的CPU和GPU的状态信息。
四川省出台的《关于加强孤儿保障工作的实施意见》中规定,扶持孤儿成年后就业。按规定落实好社会保险补贴、岗位补贴等扶持政策。积极提供就业服务和就业援助,及时将成年后就业困难且符合条件的孤儿纳入就业援助范围,依托基层公共就业人才服务机构了解就业需求,开展免费就业咨询,提供有针对性的就业帮扶。大力开发公益性岗位,将成年后就业困难的孤儿优先安排到政府开发的公益性岗位就业。鼓励自主创业,对符合条件的成年孤儿,给予场地安排、税费减免、小额担保贷款及贴息、创业服务和培训等方面的优惠政策。按规定落实好职业培训补贴、职业技能鉴定补贴等政策。开展多种形式的职业培训。
第一步计算节点性能耗时评测。全局调度模块将单位矩阵测试任务数据分发到4个计算节点,各计算节点分别把测试任务分发到CPU和GPU中分别执行,获得集群内各节点CPU和GPU计算耗时。4个节点GPU、CPU耗时分别为(1.55、10)、(0.24、6.26)、(5.72、17)和(0.49、17),单位:s。
第二步集群计算资源综合分析。全局调度模块根据第一步获取的各计算节点CPU和GPU计算耗时,取倒数即为计算效率,以此计算得到节点内CPU和GPU计算效率比值以及集群各计算节点效率比值。4个节点内部GPU∶CPU的计算效率比依次为87∶13、96∶3、75∶25、97∶3。4个节点的综合计算效率比为:10∶59∶3∶28。因此,每次计算节点调度模块向全局调度模块请求数据时,全局调度模块单次下发的数据量以单位矩阵为单元按综合计算效率比例分发。
第三步计算任务数据细粒度拆分与各计算节点及节点内GPU/CPU处理量划分。全局调度模块将计算任务数据以单位矩阵为单元进行拆分,然后依据节点处理能力,进行不均等动态划分。1.6 G任务数据首先依据4个计算节点综合计算效率比进行数据量等比例拆分,然后拆分数据量除以单位矩阵大小并向下取整,得出各计算节点矩阵划分的个数。按综合计算效率比例拆分后,剩余的矩阵依据各节点GPU、CPU单位矩阵耗时情况进行二次试算分配,试算最优目标为总体耗时最短。按照以上策略,各节点矩阵块数(GPU/CPU)分配量分别为9(8/1)、61(59/2)、2(2/0)、28(28/0)。
第四步全局调度模块计算任务数据分发。全局调度模块依据4个计算节点的节点调度模块数据请求和其综合计算效率比10∶59∶3∶28,以单位矩阵为单元,按比例分发计算任务矩阵,并等待下一个完成计算的节点再次进行请求。
第五步计算节点的节点调度模块在两条数据存储队列之间动态切换角色和向全局调度模块请求计算任务数据。图8中左侧是节点调度模块正在从当前处理队列中调度数据块给本节点中的CPU和GPU进行处理,节点中的数据缓存队列为空。图8中间是节点调度模块发现本节点中的数据缓存队列为空,并且本节点中的网络带宽处于空闲状态,则开始向全局调度模块请求数据,存入数据缓存队列。图8右侧是当前处理队列中的数据处理完毕,则数据缓存队列的角色立刻转变为当前处理队列,开始向本节点中的CPU和GPU输送数据进行处理。同时,节点调度模块准备进行下一轮的网络传输。
第六步计算节点内动态调度计算任务数据至CPU和GPU中协同并行计算。计算节点根据第三步计算的各节点及节点内GPU/CPU矩阵块分配量信息,分发处理计算任务矩阵。图7中的计算节点上的CPU的计算能力相对GPU来讲一般比例较小,所以优先满足CPU参与的并行计算需求矩阵块。因此图7中左侧当第一次调度时,节点调度模块检查调度策略计算的CPU/GPU块分配信息,如果有配额则调度一个数据块到CPU上,循环调度多个数据块到GPU上。图7中间表示GPU处理完多个数据块后,节点调度模块根据调度策略块分配信息,如果有配额,则再次调度多个数据块到GPU上,如果无配额,则GPU运算结束。图7右侧表示紧接着CPU处理完一个数据块后,节点调度模块根据调度策略块分配信息,如果有配额,则再次调度一个数据块到CPU上,由于CPU计算性能较弱,在算法执行阶段时刻保持一个块任务在CPU上执行,如果无配额,则CPU运算结束。重复前述的步骤直到当前处理队列为空。
第七步循环请求和处理任务数据。各计算节点循环执行第四步至第六步,直到全局调度模块返回空数据集时,且当前处理队列的数据全部处理完成后,当前计算节点计算任务完成,进而当各计算节点完成计算任务并返回,整个计算任务全部完成。
3 实验结果与分析
本文算法的实验环境同前文提到的4节点环境,网络带宽均为1000 Mb/s,其它硬件配置如下。
node1配置:
操作系统:CentOS Linux release v7.4
CPU:Intel Core i5-4590
GPU:NVIDIA Quadro 2000
内存:32 G
硬盘:SATA 6.0 Gbps 1 TB
node2配置:
操作系统:CentOS Linux release v7.4
CPU:Intel Xeon E5-2660 v3
GPU:NVIDIA GeForce TITAN Xp
内存:128 G
硬盘:SATA 6.0 Gbps 1 TB
node3配置:
操作系统:CentOS Linux release v7.4
CPU:Intel Xeon CPU E5-1603 v3
GPU:NVIDIA NVS 315
内存:32 G
硬盘:SATA 6.0 Gbps 1 TB
node4配置:
操作系统:CentOS Linux release v7.4
CPU:Intel Xeon CPU E5-1603 v3
GPU:GeForce GTX 1050 Ti
内存:32 G
硬盘:SATA 6.0 Gbps 1 TB
3.1 性能结果对比
在实验环境中,单批次处理流式数据量(数据块数)分别设置为0.64 G(40)、0.96 G(60)、1.28 G(80)、1.6 G(100)、1.92 G(120)、2.24 G(140)、2.56 G(160)共7种工况。本文对各工况单批次计算任务数据进行并行计算,并将使用基于两级调度的CPU与GPU协同计算的动态调度算法与传统的MPI/GPU并行计算性能测试结果进行对比,结果如图9所示。
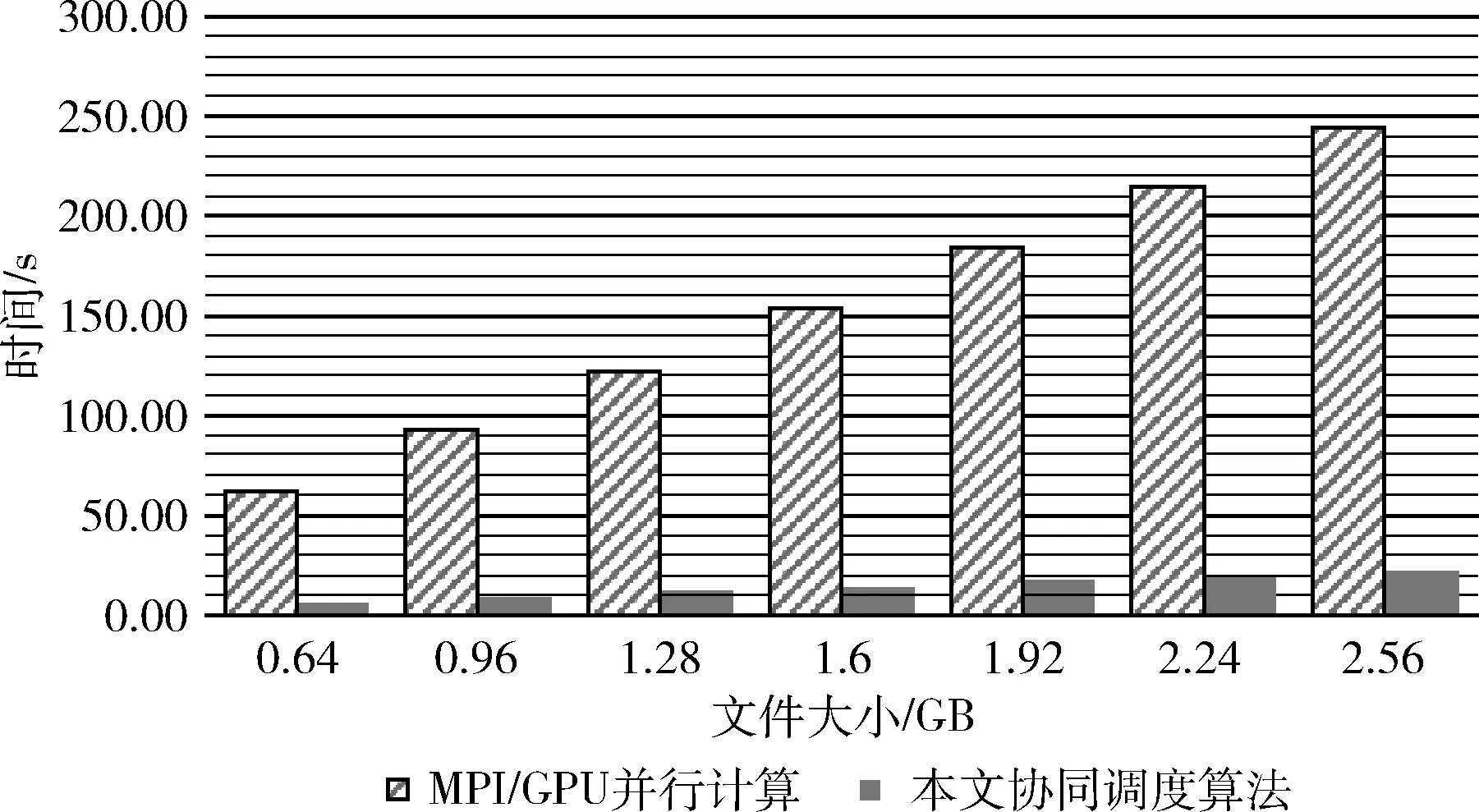
图9 使用本文协同调度算法与传统MPI/GPU 并行计算性能对比
传统的MPI/GPU并行计算在数据分发与综合利用计算资源参与并行计算时,没有考虑各个节点计算资源的异构性,按“能者多劳”原则分配任务,同时未充分利用CPU参与并行计算,造成资源闲置。本文的算法针对以上的问题做出了很大的改进。从图9中可以看出在处理多种单批次流式数据量的情况下,使用本文的协同调度算法效率是传统MPI/GPU并行计算的计算效率的11倍左右,验证了本文算法的有效性。
3.2 网卡I/O、GPU、CPU实时曲线分析
实验中,在使用本文协同调度算法调度处理1.6 G的单批次流式数据,4个节点网络I/O特征、GPU使用率特征和CPU使用率特征分别如图10、图11和图12所示。
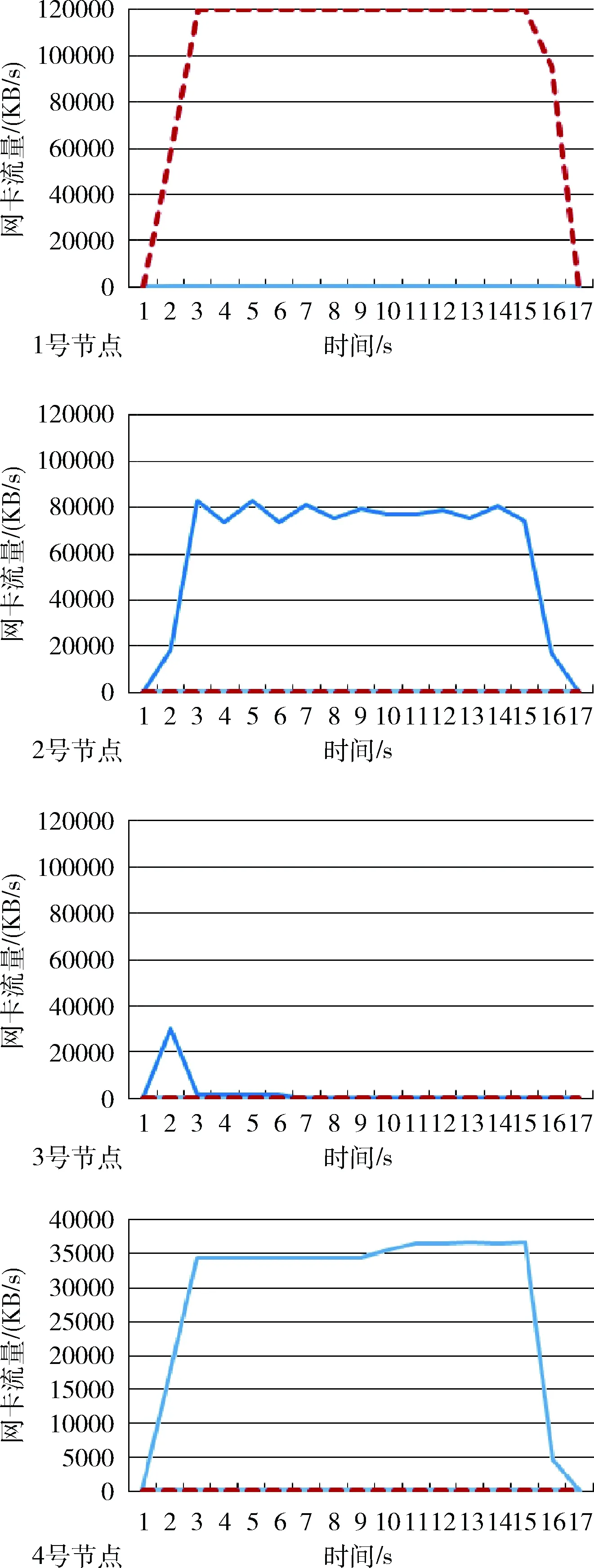
图10 网络I/O特征
网络I/O特征如图10所示。图中横坐标为时间,单位为s。纵坐标是网卡流量,单位为KB/s。实线为输入流量,虚线为输出流量。
从图10可以看出,每个节点的网络输入和输出流量相对均衡和稳定,在时间维度上基本呈现出均匀分布,网络带宽得到了有效合理的利用。同时性能较弱的节点会获得较少的数据量,如3号节点。使用本文协同调度算法的网络带宽利用率比传统的MPI/GPU并行计算的要高,是因为前者数据传输和数据处理是并行进行的,大幅度减少了网络传输等待耗时。
GPU使用率特量如图11所示。图11中横坐标是时间,单位是s;纵坐标是GPU使用率,单位是百分比(%)。
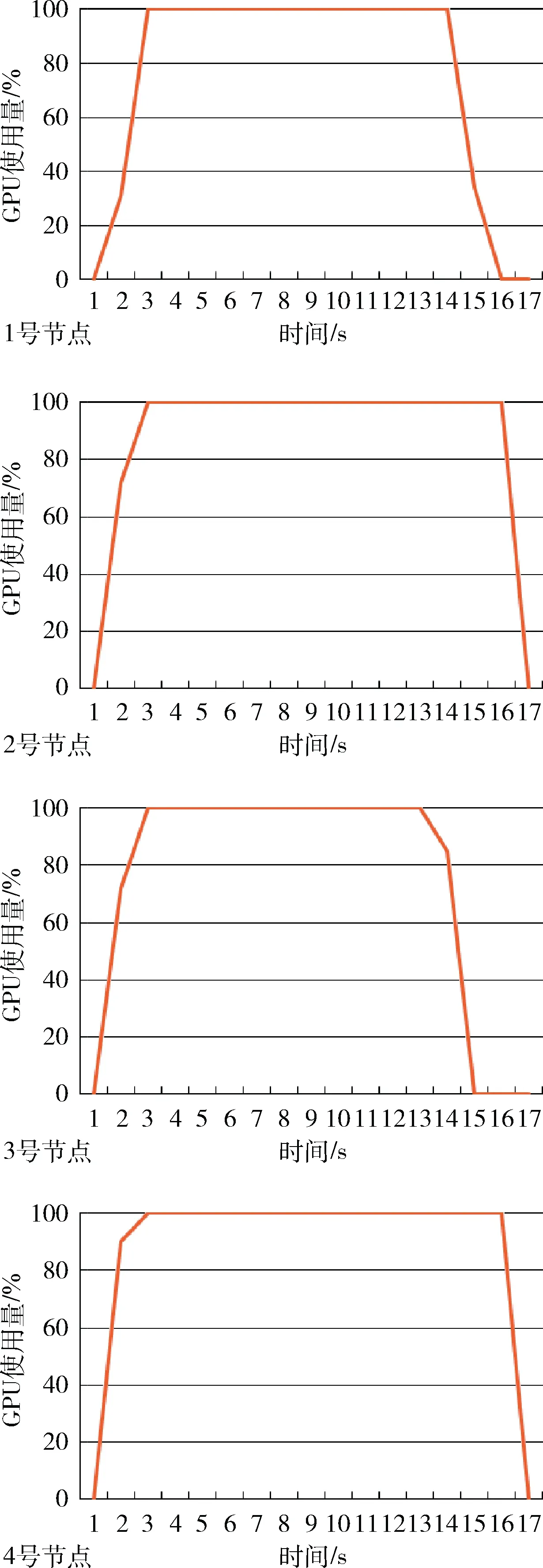
图11 GPU使用率特征
从图11可以看出,每个节点的GPU使用率在整个数据计算任务执行过程中基本满负载。执行计算任务的时间大致相等,没有出现长尾现象,GPU计算性能得到了最大程度的发挥。使用本文协同调度算法的GPU利用率比传统的MPI/GPU并行计算的要高,4个节点几乎同时开始了GPU并行计算,且结束时间趋于一致。
CPU使用率特量如图12所示。图12中横坐标是时间,单位是s;纵坐标是CPU使用率,单位是百分比(%)。
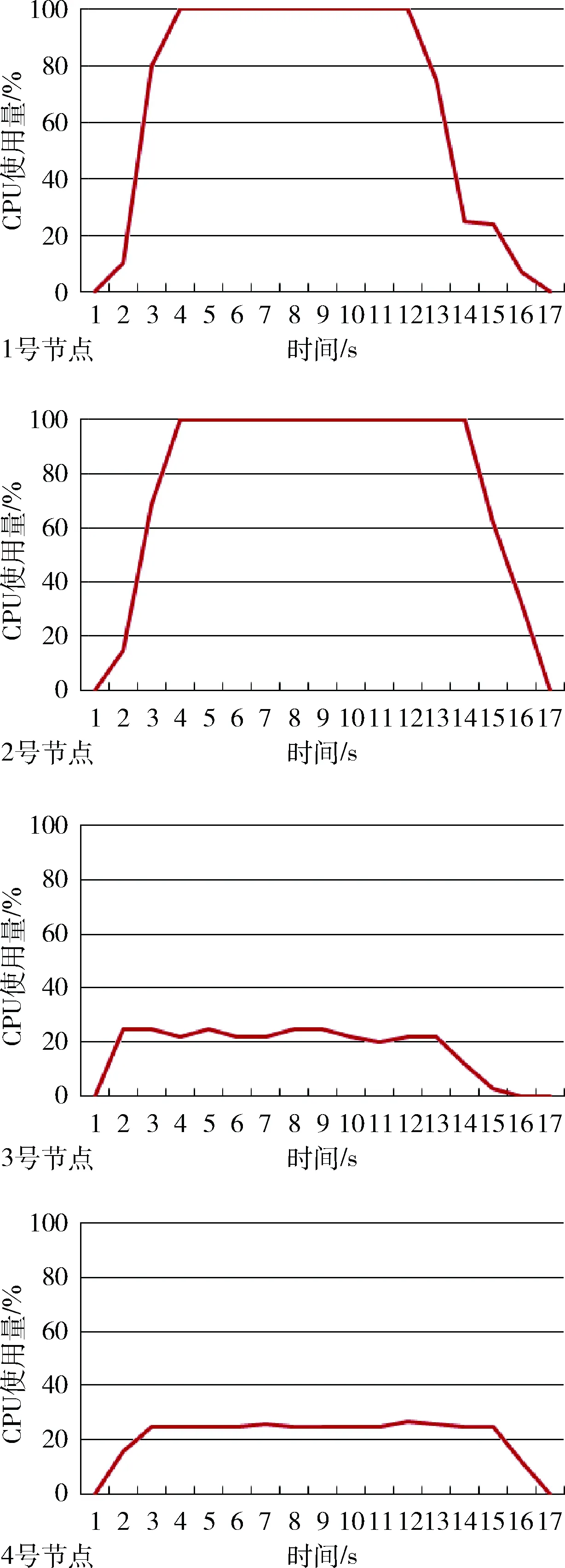
图12 CPU使用率特征
从图12可以看出,节点1和节点2的CPU得到了充分的利用,参与了整个计算任务执行过程。节点3和节点4未参与并行计算,主要是因为全局调度模块根据测试任务评估结果,计算得出节点3和节点4计算性能较弱,如果分配并行计算任务的矩阵块,必然造成整个计算任务执行过程的长尾现象,所以,节点3和节点4CPU的主要任务为数据接收、数据预处理及计算结果整合与反馈。
从图10、图11和图12中可分析得出使用本文支持异构集群的CPU/GPU协同调度算法与传统MPI/GPU并行计算有如下改进:
(1)所有节点在计算任务分发开始时,几乎同时开始了GPU和CPU的并行计算;
(2)所有节点在整个计算任务执行过程中,网络传输负载相对比较均衡;
(3)所有节点的GPU得到了充分的利用;
(4)所有节点的CPU根据计算任务的性能评估,在不会造成计算任务长尾现象的情况下,共同参与了并行计算任务,充分利用了CPU多线程的并行计算性能。
将图10、图11和图12与图1、图2和图4进行对比分析,可以看出本文的CPU/GPU协同调度算法比传统 MPI/GPU 并行计算框架具有更高的资源利用率。
4 结束语
本文介绍了在复杂异构的集群系统中对计算任务数据进行CPU与GPU协同计算的两级动态调度算法。针对传统MPI/GPU并行计算的节点能力预测不准确,任务分配不合理,任务执行耗时出现长尾现象,未考虑集群各节点资源的异构性等问题提出了改进方法。算法利用全局和节点两级调度机制、计算资源性能测评、数据缓存/处理双队列等策略,在集群系统中进行“能者多劳”的全局任务分配,在节点内完成CPU和GPU的二次动态任务调度,有效避免了单节点计算性能的木桶短板效应而造成的任务长尾现象,集群系统的计算资源得到了合理有效的综合利用,保证了系统的整体负载均衡性,有效提高CPU/GPU异构混合并行系统的整体并发度,减少计算任务的整体耗时。
