基于指数平滑的云服务器请求量集成预测模型
2020-03-07石瑾挺孙洁香邬惠峰
石瑾挺,孙洁香,邬惠峰
(1.杭州电子科技大学 计算机学院,浙江 杭州 310018; 2.北京机械工业自动化研究所有限公司,北京 100120)
0 引 言
弹性云服务器[1,2](elastic cloud server,ECS)需要表现出快速按需服务的能力[3]。在需求不确定的情况下进行预测未来云服务器的负载情况,将是有效地配置服务器资源以提供高质量服务的关键所在[4]。传统的统计模型如自回归(AR)、移动平均(MA)、AR和MA(ARMA)的组合,目前已广泛应用于服务器的负载预测问题中[5,6],而线性模型无法捕捉云服务器预测问题中的非线性关系。马自堂等[7]使用了HoltWinters预测模型对服务器任务请求量进行预测,该机制适用于预测无跳跃性且具有周期性的时间序列。Tarek Mahdhi等[8]提出的虚拟机整合框架中使用内核密度估计技术对虚拟机未来资源使用率进行预测。Chunhong Liu等[9]通过建立0-1混合整数规划模型对服务器负载状况进行分类,并分配不同模型进行预测未来资源利用率。Carlos Vazquez等[10]将一次、二次指数平滑,神经网络回归等方法对服务器未来资源需求值进行预测,其建立的模型无法表现出很好的稳定性。王天泽[11]提出一种灰色预测模型动态预测云服务负载,在波动性较大的情况下该模型精准度欠佳。
本文针对弹性云服务器的历史请求数据序列预测问题,提出了基于指数平滑的Stacking集成预测模型,在预测过程中,对各组指数平滑模型加入动态参数优化,该模型在结构上更具灵活性,且易于实现。最后采用对比实验验证预测模型的有效性。
1 问题定义
1.1 问题描述
租户对云平台虚拟机进行请求后都将在后台数据库产生对应的请求数据,每条数据由虚拟机ID、虚拟机规格以及创建时间等信息组成。获取云平台在过去一段时间内的所有虚拟机请求数据,并构造数据特征进行训练预测模型,从而利用模型与数据预测下一个时间段可能到来的虚拟机请求分布。
1.2 数学定义
服务商提供的云服务器有多种规格,任一规格云服务器的历史请求数据可以表示为一组非负序列。
假设自变量X表示某一规格云服务器的历史请求数据,是由n个正整数组成的一组序列。目标变量Y表示未来一期的预测值,通过目标函数f()便可以得到X到Y的映射
X=[x1,x2,x3,…,xn-1,xn]
(1)
Y=f(x1,x2,x3,…,xn-1,xn)
(2)
其中,xi表示第i期的云服务器请求数,n代表历史请求数据的总期数,f()为目标函数。对于云服务器请求数预测问题,目标函数即为预测模型,构建高性能的模型,可以极大提高预测准确率。
2 算法设计
2.1 算法描述
基于指数平滑的Stacking集成预测模型是本文提出的一个预测算法模型,相对于传统的单模型预测,多模型集成融合的主要特征是将多个基础模型预测结果进行结合,达到降低泛化误差的目的,保证高精度的预测能力,同时也提升了模型防止过拟合的能力。
2.1.1 一次指数平滑法
一次指数平滑法(single exponential smoothing)又称为单一指数平滑法。其计算公式如下
yt+1=αxt+(1-α)yt
(3)
式中:xt代表的是第t期的实际值,而yt代表的是第t期的预测值,yt+1代表的是第t+1期的预测值,α代表的是平滑系数,又称加权因子,并且0≤α≤1。 一次指数平滑法通过将某期实际值、预测值以及加权因子进行线性加权计算从而得到下期值。在预测过程中,若观察值离预测时期间隔越久远,则该期观测值的权重变得越小。利用一次指数平滑法进行预测得到的结果中,其趋势与实际趋势基本一致。然而使用一次指数平滑法具有滞后性,因此引入二次指数平滑法。
2.1.2 二次指数平滑法
二次指数平滑法(second exponential smoothing me-thod) 是在一次指数平滑值的基础上再进行一次指数平滑的方法。该方法无法单独运行,必须与一次指数平滑法进行组合搭配。其计算公式如下
(4)
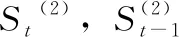
(5)
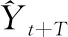
在指数平滑模型中,通常都将固定平滑系数,这将会给模型带来一定的局限性[12],本文采用梯度下降法对平滑系数进行优化。损失函数Loss与迭代更新公式如下
(8)
式中:δ代表学习率,在本文中取值为0.23可以在实验中获得很好的预测效果。平滑系数的优化是一个递归过程,其中初始梯度公式为
2.1.3 Stacking集成学习算法
集成学习方法本身并不是单独的机器学习算法,而是通过构建并结合多个机器学习器进行学习任务[13]。在传统的机器学习单模型工作过程中,单一模型在多因素的影响下在准确率与稳定性方面往往无法表现出满意的效果,而由多个互有差异的基学习器进行组合的集成学习器可以弥补单一模型的缺陷。
集成学习的数学表达形式可参考文献[14]。在本文中,使用指数平滑作为多个基模型进行预测,属于同构集成。Stacking集成学习的整体结构如图1所示。
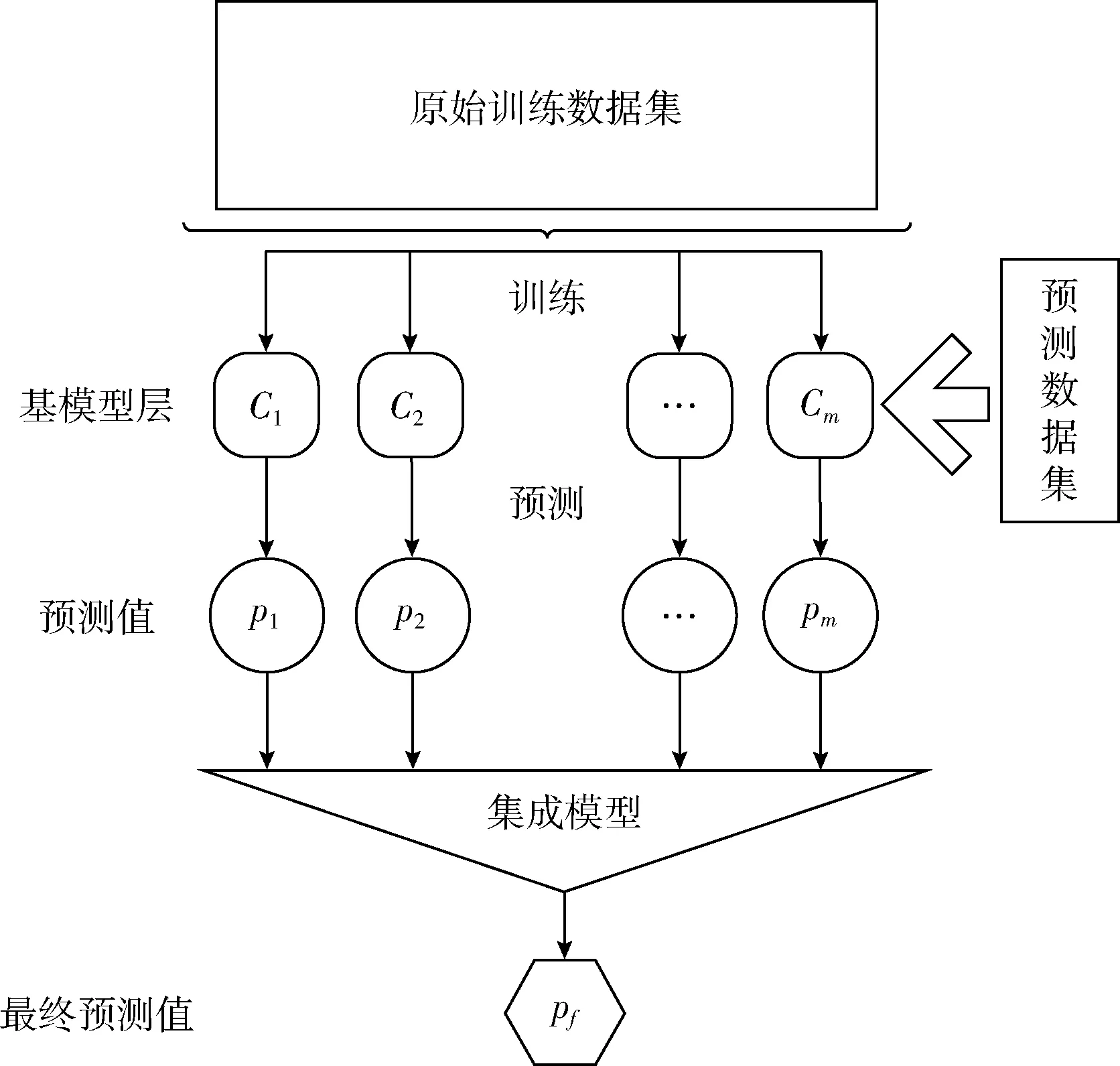
图1 集成学习模型
多个基模型在产生预测结果后,将所有预测结果作为学习样本输入集成模型进行训练。在最后一层集成模型训练结束后,将预测样本输入整体结构中,产生最终预测结果。本文选择使用线性回归模型作为Stacking学习方法的集成模型,用于调整拟合多个指数平滑模型预测值与真实值的残差。
2.1.4 多元线性回归
回归分析是指给出一组具体函数模型进行拟合多组变量间的变动关系,并根据该模型给出预测值,其具体定义可参考文献[15]。
在本文中,多组指数平滑单模型的预测值与真实值之间若存在某种相关关系,我们使用Y表示多个单模型的输出预测值
Y=[y′1,y′2,y′3,…,y′m-1,y′m]
(16)
其中,y′i表示第i个指数平滑单模型的预测值,其中i=(1,2,…,n), 则可以建立多组指数平滑单模型预测值与真实值之间的相关模型
W=[ω1,ω2,…,ωm-1,ωm]
(17)
(18)
式中:ωi表示回归系数,同时也代表单模型在集成模型中对应的协调参数,其中i=(1,2,…,m),W代表该组系数,h(Y) 由所有单模型输出与对应回归系数的乘积与偏置项b累加组成,即W的转置与Y的乘积再加上偏置项,如式(18)形式的线性方程即表示本文的线性回归集成模型。
在建立多个单模型到真实值之间的相关模型中,回归系数对于整个集成模型的性能起了决定性作用。假设目前有l个数据样本,yj与h(Yj) 分别表示第j个样本对应的真实值与集成模型对应的预测值,其中j=(1,2,…,l), 为了评判模型的性能,引入损失函数J(W)
(19)
若损失函数J(W)越接近于零,代表每例的预测值与真实值越为接近,则模型的预测效果越优。为得到更优性能的模型,需要训练出更好的回归系数,采用梯度下降法搜寻最优回归系数。训练过程中各回归系数的迭代公式如下
式中:α为学习速率,α过大可能导致无法取得最优值,α过小则容易造成迭代次数过多,收敛速度变慢,本文中对于α取值为0.13时,在训练效果以及收敛速度上都可得到满意的效果。
2.2 基于指数平滑的云服务器请求数集成预测模型建模方法
本文提出的基于指数平滑的集成预测模型在层次上包括特征构造层,单预测模型层,集成学习模型层。在对集成学习模型层进行训练的过程中需要使用原始数据集进行集成模型的训练数据构造。
2.2.1 特征构造
服务商会提供给租户多种规格的云服务器,在得到某种规格的云服务器一段时间内的请求序列后,可表示为序列X=[x1,x2,…,xn], 通过对原始序列数据的加工可以得到多组属性特征,属性是数据本身具有的维度,特征是数据中所呈现出来的某一种重要的特性,通常是通过属性的计算,组合或转换得到的。
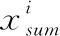
(22)
本文中,滑窗特征的窗口大小设定为3。在实际预测过程中,不同的单指数平滑模型所需输入的数据序列长度必须一致,故在得到原始、累积特征数据序列后,将舍弃前几期数据,使其长度与滑窗数据序列长度保持一致。在预测结束之后,需要对使用累积特征和滑窗特征的预测值进行上述公式的逆操作作为最终预测值,其公式如下
其中,在得到第n+1期的累积特征预测值与滑窗特征预测值后,x′sum与x′slide为使用预测值进行逆操作之后的最终数据。在下文中的数据划分以及预测过程中,都将使用以上操作得出的数值加入数据集或者输入集成模型进行预测。
2.2.2 单预测模型层及数据划分
本文中使用多个指数平滑预测模型作为单预测模型层,且各个模型相互的平滑系数互不相同,将单预测模型层表示为
{SmoothModel1(α1),SmoothModel2(α2),…,SmoothModelm(αm)}
对于指数平滑模型SmoothModeli(αi), 其输入为对应的映射特征ci(X)。
在下一步的集成学习器中,实际拟合的是各单模型的预测值与实际值的映射关系,因此单预测模型层将输出如式(17)形式的向量作为集成模型层的输入。原始数据集中并不包括集成学习器的训练数据,因此在训练集成学习器之前,需要在原始数据中构造集成学习器的训练数据。
对于某种规格服务器的请求序列X,组成序列为 [x1,x2,…,xn], 在本文中首先取前二分之一长度的序列 [x1,x2,…,x(n/2)], 在经过特征构造层之后得到映射特征作为单预测模型层输入。
如指数平滑预测模型SmoothModeli(αi) 接收序列之后,输出x′i((n/2)+1), 该数值作为集成模型的第i个输入参数。在m个单模型输出X′((n/2)+1)=[x′1((n/2)+1),x′2((n/2)+1),…,x′m((n/2)+1)], 将该组数值作为特征,而原始序列中第 ((n/2)+1) 期的数据x((n/2)+1)作为标签,这两部分数据一起组成第 ((n/2)+1) 期的训练数据加入集成学习器的训练数据集。在预测序列中每加入新一期的数据通过单预测模型层得到预测值加入集成学习器的特征数据集的同时,将后一期的真实值加入集成学习器的标签数据集,重复执行上述过程直到将最后一期的数据加入序列得到特征数据集和标签数据集。使用单预测模型层构造集成学习器训练数据集的过程如图2所示。

图2 单预测模型层构造训练数据集
2.2.3 集成学习器的训练
通过上述步骤可以得到集成学习器的训练数据集D={(X′i,yi)}, 其中i=((n/2)+1,(n/2)+2,…,n)。 本文的集成学习器选择使用线性回归模型,首先随机初始化模型的回归系数、学习率、迭代次数以及预期损失函数阈值,对于每一组训练数据,可以对线性回归模型输入训练数据后使用梯度下降来优化其回归系数,当损失函数的值小于指定阈值或训练次数达到预设迭代次数,则训练过程完成。训练完成后可以使用该线性回归模型进行预测。
2.2.4 基于指数平滑的Stacking集成模型训练及预测流程
基于前文将基于指数平滑的Stacking集成预测模型的操作步骤描述如下:
步骤1 初始化单预测模型层的模型数量、各单预测模型的平滑系数、集成学习器的回归系数,以及迭代次数与损失函数阈值。
步骤2 对原始数据进行特征构造,构造出组数与单预测模型层模型数量相同的特征组。
步骤3 对每个单预测模型输入对应的特征组,构造出集成学习器的训练数据,在构造过程中,每个单模型同时进行动态优化平滑系数。
步骤4 对集成学习器即线性回归模型使用步骤3构造出的训练数据进行训练,训练完毕后,再次输入原始数据即可得到目标预测值。
上述操作步骤的流程如图3所示。
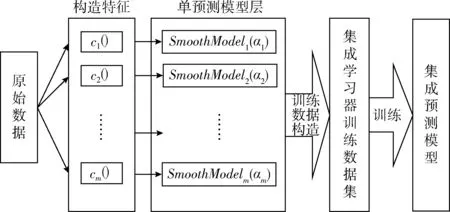
图3 Stacking集成模型训练过程
使用训练完成后的集成模型进行预测的流程如图4所示。
图4 Stacking集成模型预测过程
3 实验仿真
3.1 实验数据及评价指标
本文使用的实验数据由第四届华为软件精英挑战赛提供,以此保证预测模型的客观性和普适性。
算法需要从输入数据提取服务器信息,包括服务器ID,服务器所属类别,以及对应服务器请求时间等。需要对输入数据进行处理,这里以天为时间单位,统计同一种类别的服务器的每天的请求总量。实验数据部分例子见表1。
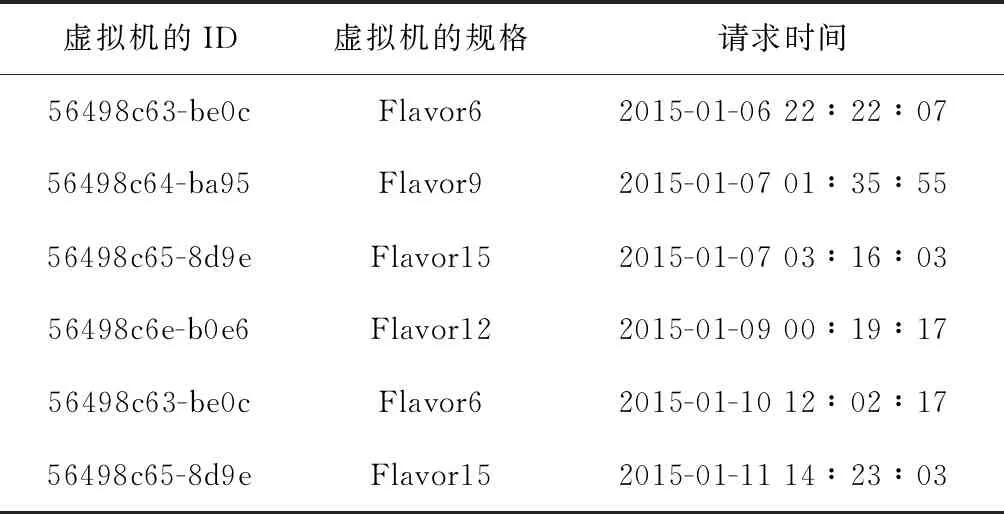
表1 实验数据部分示例
4种服务器自创建时间开始100天内每天的访问量如图5 所示,其中Flavor9与Flavor12服务器波动性较大,而Flavor6与Flavor15服务器的访问量则较为集中和平缓。

图5 各服务器访问量走势
本文采用均方误差作为模型预测准确率的评价指标,其公式为
(27)

3.2 分 析
图6中可见4种服务器在线性回归、ARIMA与Stacking模型下的预测错误率。其中ARIMA对4种服务器时间趋势的预测效果不佳,而对原始时间趋势进行指数平滑,并且加入了累计特征、滑窗特征等数据强化特征后,线性回归得到了较好的拟合度,误差较低。Stacking模型则在此基础上加入多层指数平滑数据后,错误率相较单一模型明显下降,并且Stacking模型具有较高的灵活性,可以不断调整模型的层数以及各学习器的类型参数以达到更好的预测精度。
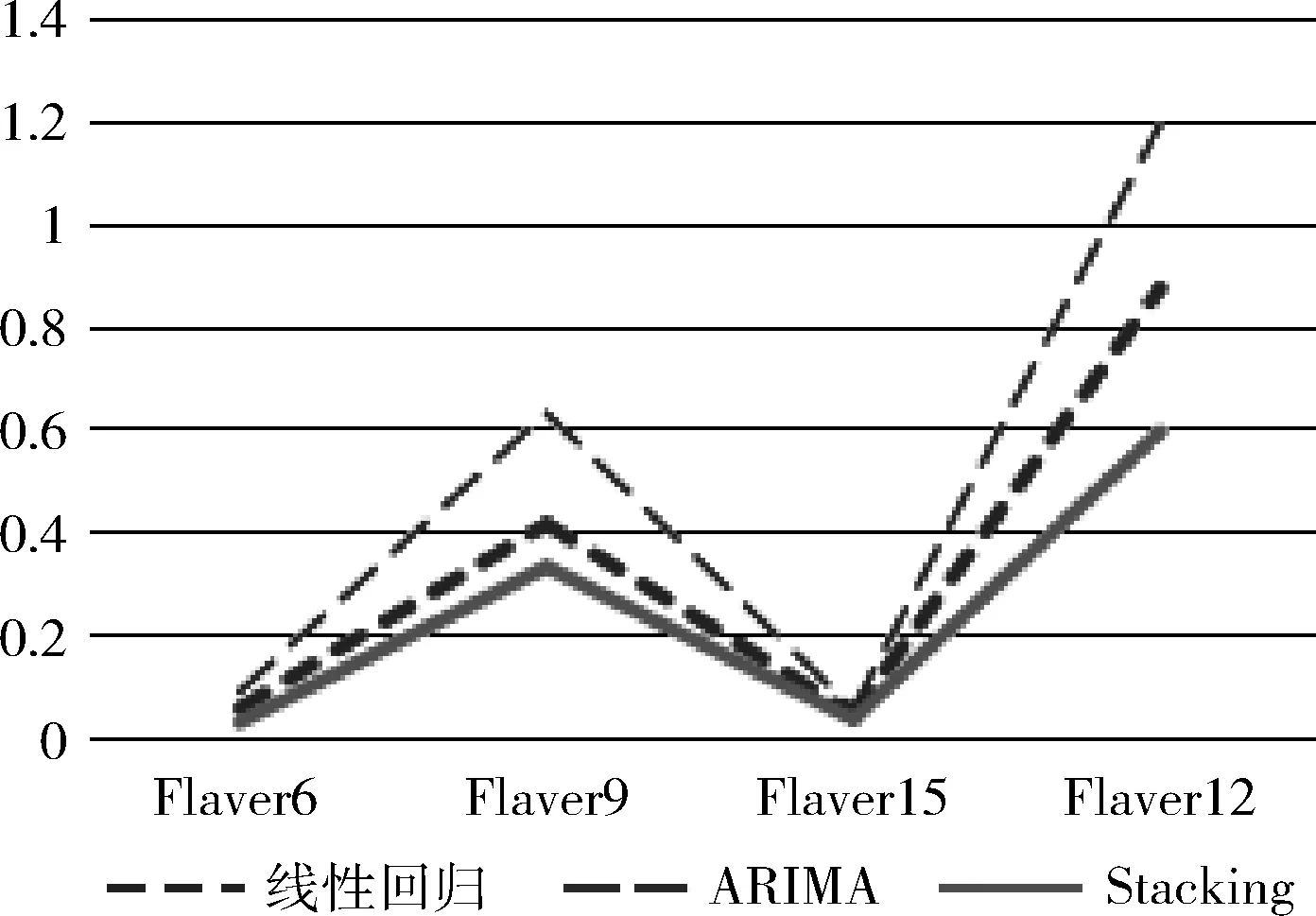
图6 预测误差
表2中可见4种服务器在线性回归、ARIMA与Stacking模型下的预测量化错误率。使用Stacking算法后,错误率相较单一模型在几个服务器上有较高提升,Flavor9服务器相较ARIMA提升了5个误差点,而对于Flavor15服务器也有6个千分点的提升。由于Flavor9与Flavor12波动性较大,模型对这一类服务器的预测误差较大,但采用更加复杂的模型并加入多次平滑的强化特征能够得到较大的准确度提升。而对于波动性较为平稳的时间序列,该模型具有较好的预测效果。

表2 各服务器预测误差
图7中可见Stacking模型下利用动态平滑系数优化后服务器的预测错误率。4种服务器相比固定平滑系数均有一定幅度的下降,其中Flavor9服务器的预测错误率下降幅度最大,这主要是基于梯度迭代的平滑系数优化能够根据不同服务器时间序列特点生成最优的指数平滑系数,从而更好地拟合预测曲线,使得预测误差较低。
图8与图9展示Stacking与线性回归下4种服务器的预测拟合度,其中横坐标表示待预测序列的序号,纵坐标表示真实值与预测值的拟合度。可见对于Flavor6与 Flavor15 服务器,Stacking模型的预测拟合程度更好,预测点较为集中并且与真实值处与相同水平上,而在Flavor9与Flavor12服务器的预测上,由于时间序列波动性更大存在了较多的异常点和偏移点,对于某一时间段上的预测值出现了偏离,预测误差也主要由这一部分产生,而对于其它预测点则能够拟合真实值。与Stacking模型相比,线性回归对与4种服务器的拟合度稍差,特别对于波动性较高的序列上,线性回归在异常点的预测上误差较高,主要是由于单一模型缺少更加稳健和强壮的特征刻画。

图7 最优平滑系数误差对比
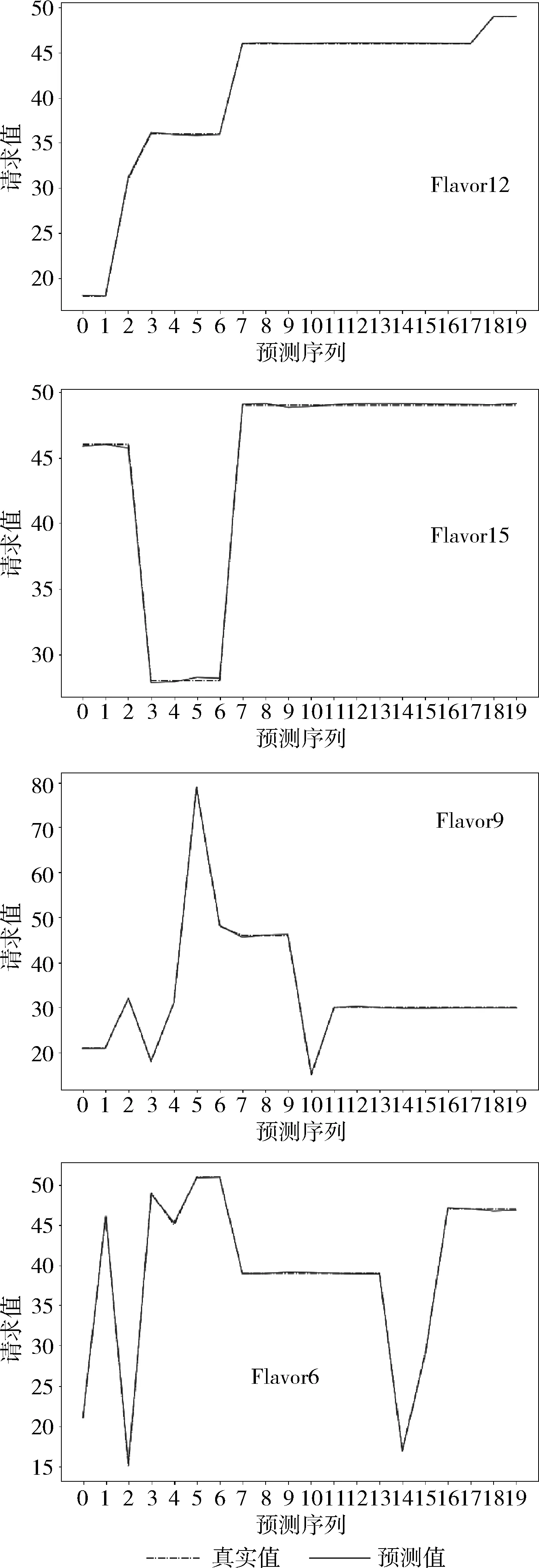
图8 Stacking预测结果
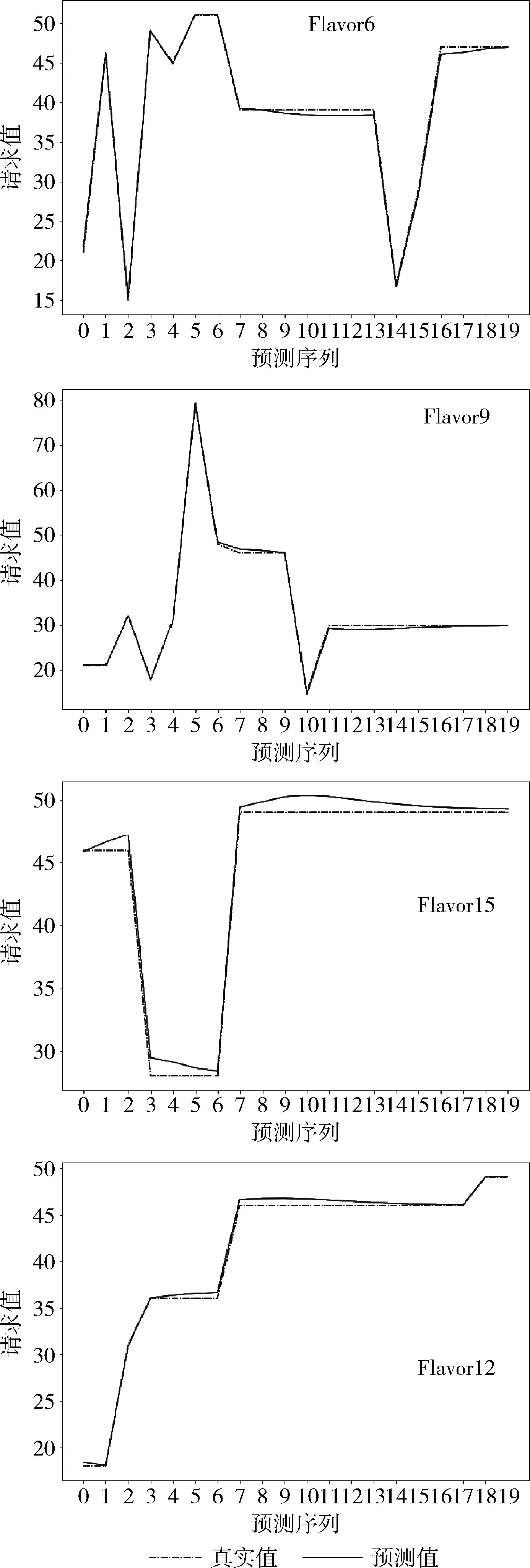
图9 线性回归预测结果
4 结束语
弹性云服务器的请求数据具有复杂的规律性,本文提出基于二次指数平滑的云服务器请求数Stacking集成预测模型在预测此类问题具有一定效果。在预测过程中,为了突破指数平滑的局限性,设计了针对平滑系数的优化方法,提高模型的灵活性。针对云服务器的历史请求数据,本文给出了集成预测模型的建模方法,利用单预测模型为集成模型进行数据划分,并使用划分数据集进行对集成模型的训练。实验结果表明,本文提出的预测模型相较于传统的预测模型有更高的准确性,下一步的工作则是对模型在长期预测方面进行优化。
