基于卷积神经网络的视频流隐藏信息检测方法
2020-03-07罗远焱杜学绘
罗远焱,杜学绘,孙 奕
(1.信息工程大学 密码工程学院,河南 郑州 450001;2.信息工程大学 河南省信息安全重点实验室,河南 郑州 450001)
0 引 言
采用H.264编码算法的视频流因为具有较高的压缩效率和广泛的网络适应性,在网络传输的视频流中被广泛采用。而H.264视频码流中所存在的大量DCT系数可能会被用于隐藏信息[1]。目前基于DCT系数修改的代表性信息隐藏方法有Lin等方法[2]和Ma等方法[3]。这些方法通过修改DCT系数以隐藏信息,但其对DCT系数的修改会不同程度地影响视频中数据的空间相关性,如视频解码后像素的变动等,这些差异为检测视频中隐藏信息提供了可能性。
相关研究者利用视频流中的这种空间相关性,提出一系列针对视频流中隐藏信息的检测方法,典型的有Da等方法[4]、N.Zarmehi等方法[5]和Wang等方法[6]。这些检测方法根据所设计的检测特征判断视频流是否被嵌入信息。其局限性在于,人工所设计的特征对最后检测的结果具有很大影响,并且视频相对于其它多媒体数据(如图像、音频等),结构方面更加复杂,所需检测特征的维度也更高,这也为人工设计视频的相应检测特征带来不小的挑战。而相比于以往基于人工设计特征的检测方法,卷积神经网络可以通过卷积层自动从数据中提取特征。因此本文将卷积神经网络引入到视频隐藏信息检测中,并采用量化截断操作与残差单元对其进行改进,提出一种基于卷积神经网络的视频流隐藏信息检测方法。
1 量化截断操作与残差学习
1.1 H.264的帧内编码
为减少视频传输所消耗的带宽,需要在编码时提高视频的压缩率。而帧内编码是利用视频帧内空间相关性提高视频压缩率的方式之一。视频的帧内编码主要分为宏块划分,帧内预测,DCT变换、量化等几个步骤[7],如图1所示。
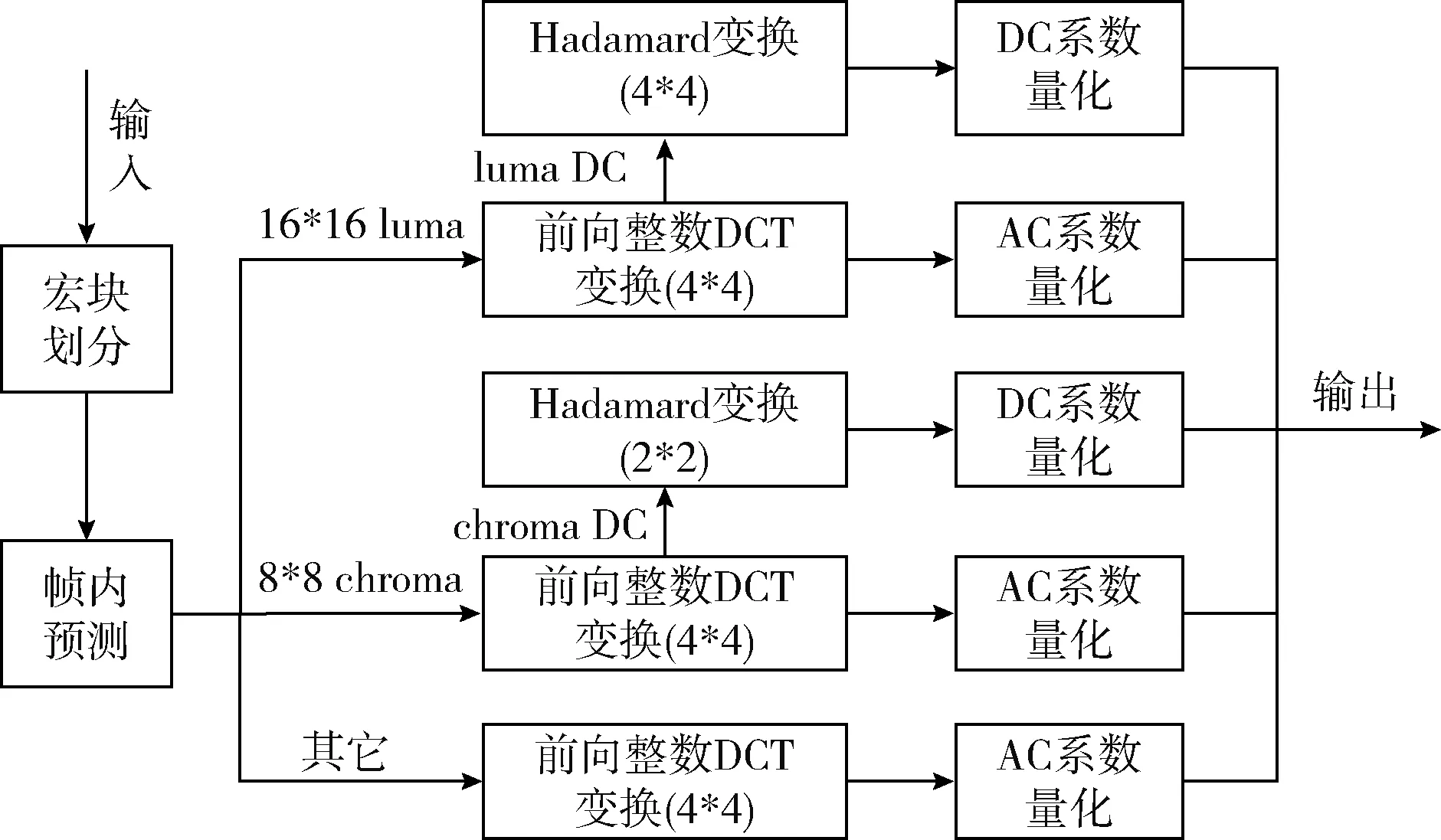
图1 视频的帧内编码流程
帧内编码的宏块划分有4*4与16*16两种类型。16*16 的亮度块在亮度的变化过程中是相对平滑的,如果进行修改会引起此区域视频亮度的明显变化,而人眼对于亮度的变化是较为敏感的,并且在编码过程中16*16的亮度块也是采用16个4*4的前向DCT变换进行处理,所以现有信息隐藏方法主要是针对帧内4*4亮度块的DCT变换系数进行修改。
在H.264编码算法中,4*4的亮度块有9种帧内预测模式,不同预测模式使用不同计算公式预测出相邻4*4亮度块的亮度值。在帧内编码中,除第一个宏块外其余宏块都是基于相邻宏块的预测值计算出的。将宏块实际的亮度值与预测出的亮度值相减得到残差矩阵,该矩阵经过DCT变换后量化为最后存储的编码数据。
对图像进行DCT变换的过程实质是将图像所具有的信号由空域变换到频域。在频域中,人类视觉系统对于低频的信号比较敏感,而对于高频的信号不敏感[8]。所以许多信息隐藏方法将信息隐藏在这部分人类视觉系统并不敏感的高频分量系数中。在DCT变换后,H.264编码器会对DCT变换系数进行量化以减少编码长度。下面是DCT变换及量化所采用的公式
(1)
此处的
(2)
(3)

现有方法在通过修改DCT系数来隐藏信息时,所做修改会改变DCT系数之间的潜在相关性。视频解码过程中,反DCT变换操作会将相关DCT系数转化为空域中像素值,而相应DCT系数的修改会随之扩散到4*4块的所有像素中。基于卷积神经网络的检测方法可以利用这种DCT系数修改所引起的差异检测视频流中的隐藏信息。
1.2 量化截断操作
现有基于人工设计特征的视频流隐藏信息检测方法通常会有以下几个步骤:
(1)解压缩。通过调用相关的解码库,将待检测的视频序列解压缩到空域,从而获得一系列由像素值系数矩阵所组成的空域中的视频帧(需要注意的是,此处的解压缩操作不同于视频播放时的解码操作,此处的解压缩操作不进行解码时的量化和截断等将像素值变换到[0-255]这一范围的操作)。
(2)卷积。将所获得的视频帧与一组预先设定的卷积核进行卷积操作从而获得残差嗓声矩阵。此处卷积操作的目的是减弱帧内图像内容的信号并增强嵌入信息所产生的嗓声信号。
(3)量化截断操作。对残差矩阵中每个残差系数进行不同组合的量化截断操作。此操作可以进一步改善所得特征的多样性,并降低计算复杂度(需要注意的是,此处的量化截断操作不同于编码时的量化截断操作,编码时的量化操作是为了减少编码长度,而此处的量化截断操作是为了便于下一步对特征进行聚合与分析)。
(4)聚合。对上一阶段所得的值进行聚合从而进一步降低最后所选择特征的维度。
下面以最新提出的Wang的方法[6]为例进行说明。对于每一个解压到空域中的视频帧F(大小为M*N), 我们将其与所设计的DCT核(即G(u,v)) 进行卷积操作,如下所示
U(F,G)={U(u,v)|0≤u,v≤3}
(4)
U(u,v)=F*G(u,v)
(5)
此处的U(u,v)∈R(M-3)*(N-3), 卷积操作的步长为1,并对结果不进行填充。所采用的DCT核为
(6)
(7)
U(F,G,Q)=Q(U(F,G)/q)
(8)
此处的q是量化步长,Q是以{0,1,2,…Tr} 作为周期的量化器,Tr是量化周期中的截断阈值。经过以上两步处理过后,将16个量化残差嗓声矩阵按如下公式计算直方图
(9)
最后,将所得直方图中的值作为特征输入支持向量机(SVM)或集成分类器进行分类,得出最终的检测结果。
在上述基于人工设计特征的检测方法中,量化截断操作(Q&T)的引入增加了模型的丰富性并且进一步降低所设计特征的维度,因此其被广泛使用在基于人工设计特征的检测方法中[9]。但如果将量化截断操作(Q&T)引入卷积神经网络(CNN),则会遇到新的问题。因为在训练神经网络的过程中会使用反向传播(BP)方式来寻找合适的参数,而量化截断操作(Q&T)的引入会使得反向传播过程中梯度下降算法中的梯度出现消失的情况。具体描述如下
(10)
式中:rij是经过DCT核卷积所生成的残差嗓声矩阵中的系数,aij是卷积神经网络中与之相关联的非线性激活函数的输出,q是量化步长, [·]是取整操作,T是预定义的阈值。观察此式可知,当rij的取值集合为{(-T+0.5)q,(-T+1.5)q,…,(T-1.5)q,(T-0.5)q} 时其导数f′(rij) 的取值为无穷,而其余情况下rij的导数的值为0。如果偏导数趋近于零,相应的梯度就会饱和;如果没有导数(即导数趋向于无穷),则梯度就会为零,这会使得反向传播过程中的梯度出现消失的情况。因此,不能直接将量化截断操作(Q&T)引入卷积神经网络中。
因为量化截断操作(Q&T)与神经网络中梯度下降算法不相兼容,所以现有引入量化截断操作的视频流隐藏信息检测方法法中,大部分是基于人工设计特征的检测方法。为利用量化截断操作为检测所带来的优势,本文将量化截断操作(Q&T)与神经网络分为两个阶段进行操作,以解决不相容问题。
1.3 残差学习
卷积神经网络越深,理论上的学习效果越好,即理论上训练出来的检测准确率越高[10]。但在实际操作中,过深的网络在训练时会出现梯度消失或者梯度爆炸的情况,导致随着层数加深网络的准确度出现饱和甚至是下降的情况。在Zeng等的论文[9]中,其通过添加一个辅助的梯度值来解决这个问题,但这种技巧并未从根本上解决问题。在本文方法所设计的网络中,通过借鉴He等的论文[10]中的残差学习思想,在不同的卷积层之间添加快速连接构建残差学习单元,通过学习残差传导梯度,从而构建所使用的检测子网络。残差学习的原理如下:
残差单元可以用如下形式表示
yl=h(xl)+F(xl,Wl)
(11)
xl+1=f(yl)
(12)
其中,xl与xl+1分别表示的是第l个残差单元的输入和输出,每个单元包含多个卷积层。F是残差函数,表示所学习到的残差,而h(xl)=xl表示恒等映射,f是ReLU激活函数。所学习的特征为
(13)
利用链式规则得到的反向传播的梯度为
(14)

2 基于卷积神经网络的视频流隐藏信息检测方法
本文提出一种基于卷积神经网络的视频流隐藏信息检测方法。该方法核心是使用改进的卷积神经网络结构检测视频流。改进的卷积神经网络整体结构如图2所示,其主要分为两个部分,第一个部分将解码到空域的视频帧与所设计的DCT核进行卷积生成残差嗓声矩阵,并对矩阵中系数进行不同的量化截断操作;第二部分将量化后的矩阵作为子网络的输入,通过训练网络得出最后的检测结果。

图2 改进网络的整体结构
2.1 量化截断操作与DCT卷积核参数寻优
第一部分通过DCT卷积核生成残差矩阵,并将残差矩阵进行量化截断操作。其中的DCT卷积核相当于一个个滤波器,其与视频帧进行卷积操作的目的是抑止视频帧中的内容信号并放大帧中隐藏信息所产生的噪声信号[11]。因此不同的卷积核所生成的残差嗓声矩阵对检测性能具有一定影响。
本文将视频解压缩(不含量化截断操作)所形成的一系列视频帧作为所提出网络结构的输入。随后将视频帧与所设计的DCT核进行卷积操作,并对卷积后生成的残差嗓声矩阵执行量化截断操作。与以往不同,我们采用16个 4*4 的卷积核,而不是文献[9]方法中的64个8*8卷积核或文献[12]方法中的25个5*5的卷积核。这是因为现有针对视频的信息隐藏方法主要是针对4*4的划分子块进行修改,所以采用4*4的DCT核进行卷积可以得出合适的使隐写噪声更易于检测的残差嗓声矩阵。表1中的实验数据也能辅助验证这个观点。在此实验中,我们测试了2*2,3*3,4*4,5*5和8*8尺寸的DCT核,尺寸为4×4时获得最佳检测结果(实验中数据采用Ma等的方法[3]隐藏信息,量化步长QP=36,嵌入率EC=0.05,参数设置将在下文进行详细介绍)。

表1 不同DCT核、量化截断(Q&T)对检测性能影响
注:(10,1)代表截断值T=10、量化值Q=1
DCT核一般按如下形式进行构造[9],其中的N根据具体情况进行取值,在本文中我们取N=4
(15)
(16)
经过DCT核的卷积操作后,视频帧被处理成16个残差嗓声矩阵。随后需要对生成的残差嗓声矩阵进一步进行量化截断操作。如果把量化截断操作看作一个函数,其与卷积神经网络中的激励函数等结构的构造具有较大差异,如图3所示。图3中左边是神经网络中一种典型的激活函数,其连续且可导。右边函数功能上类似于量化截断操作,其不连续且不可导。同时量化截断操作所具有的将特征离散化与多样化的能力是卷积神经网络中相关函数所无法模仿的。因此本文方法中将量化截断操作与神经网络相结合。该操作给模型带来的多样性对于检测方法的性能具有较大影响。本文所进行的实验也能支持相应的观点。

图3 量化截断操作与激活函数区别
如表1所示,通过参考文献[9]方法中的参数设置,本文对不同取值的量化截断操作(Q&T)进行测试,通过实验选择出了较合适的一组参数值(T=8,Q=1、2、4)。
2.2 基于残差学习单元的子网络
经过量化截断操作的处理后,得到48个量化残差嗓声矩阵。这48个模型分3组输入第二部分的网络中进行检测,该网络由3组并行且相同的子网络构成。该子网络的结构与如图4所示。

图4 子网络结构
在每一个子网络中,包含16个卷积层和全局平均池化层。这一部分是卷积神经网络的核心,通过学习和优化相关参数以自动提取相关特征,从而得到256维的输出向量。在每一个卷积层后面采用了一个BN(批量归一化)层和非线性激励函数(ReLU),BN层的引入是为了解决反向传播过程中的“梯度弥散”问题,而激励函数的引入是为了增加非线性因素以提升模型的表达能力[13]。使用的卷积核大小统一为 3*3。在所提出的子网模型中,部分卷积操作的步长为2,使得在输入数据空间大小减半时增加卷积核数量以使输出数据信道数目翻倍,从而保持网络结构的复杂性。而其余卷积操作步长为1,此时输入数据与输出数据的空间大小相等,作用是通过卷积层自动提取特征。
为进行残差计算,会在不同的卷积层之间进行快捷连接。所添加的快捷连接分为两种情况,当快捷连接两端输入与输出数据维度一致时,直接将输入添加至输出;如果快捷连接两端的输入与输出数据大小不一致,则在快捷连接中添加一层新的卷积,如图5所示,使得输入与输出维度一致。

图5 残差学习单元结构
经过上述处理,3个子网络输出3个256维的特征向量。在其后采用2个全连接层与softmax层从而得出最后的检测结果。
虽然在理论上网络结构越深效果越好,但在实际中太深的网络结构我们无法训练。因为所设计卷积神经网络的宽度受GPU内存的限制,目前实验时采用12 GB内存的GPU能支持所提出的16层网络。同时更深的网络,需要比现有更多的实验数据。这也是下一步的研究方向。
3 实验分析
3.1 实验设置
在实验中,本文使用由1000个标准CIF视频序列组成的数据集。所有视频采用YUV 4∶2∶0抽样格式,视频序列中视频帧的数量从500到15 000不等。本文在FFmpeg[14]中引入x264编码器[15]将标准CIF序列编码成H.264码流,编码过程中的帧率设置为30 fps,并用该编码器实现实验中所需的信息隐藏与隐藏信息检测方法。为比较各隐藏信息检测方法对于基于DCT系数信息隐藏方法的分析能力,本文使用Ma等的方法[3]与Lin等的方法[2]进行隐藏信息的嵌入。信息嵌入量由嵌入率表示,嵌入率(embedding rate,ER)代表非零系数所嵌入的比特数(the number of bits embedded per non-zero coefficient,bpnc)。具体视频中的最大嵌入率受视频编码时所选择的量化参数QP影响,最大嵌入率随着量化参数QP的增加逐渐降低,Lin方法的嵌入容量大于Ma等方法的嵌入容量[6]。在实验中,本文在选择常用的QP参数(32,36)与不同嵌入率(0.05 bpnc,0.1 bpnc)的基础上,将所提出方法与Da等的方法[4]、DCTR 方法[16]和Wang等的方法[6]进行比较。
同时,为使视频帧满足神经网络的输入格式,将解码后的视频帧统一剪裁为256*256的大小。使用现有的Caffe框架[17]构建所需的神经网络结构,将所设计的4*4DCT核与量化截断操作层加入Caffe框架之中。使用小批量随机梯度下降法对所提出的模型进行训练,学习率从0.001开始,动量momentum固定为0.9。卷积核中的参数由均值为0标准差为0.01的高斯分布进行随机初始化。最后全连接层中的参数使用Xavier方法进行初始化。每5000次迭代之后,卷积神经网络中的参数都会被保存。从视频数据集中随机选取50%的原始未隐藏信息的视频文件,随后选择信息隐藏方法生成相应隐藏信息的视频组成训练集。数据集中剩下的50% 视频文件用于测试。
3.2 结果及其分析
(1)与现有方法对比
各方法对于DCT系数中隐藏信息检测的实验结果见表2与表3。本文在表2中采用Ma等的方法[3]嵌入信息,而在表3中采用Lin等的方法[2]嵌入信息,信息的嵌入率分为0.05与0.1两种情况,视频的量化参数分为32与36两种情况,所对比的方法为Da等的方法[4]、DCTR方法[16]与Wang等的方法[6]。从表中可以看出,在相同条件下,相比于以往方法,所提出的方法具有更高的检测率。同时检测准确率随着量化参数QP的降低而提高,这是因为用较低的QP值压缩的高质量视频损耗较小,检测方法更易从这些视频数据中获得更有效的隐藏信息的特征。

表2 针对Ma等信息隐藏方法检测准确率

表3 针对Lin等信息隐藏方法检测准确率
相比于以往使用传统机器学习的检测方法,本文所提出的基于卷积神经网络的方法,准确率是随着的迭代次数的增加逐渐上升的。所训练的网络总共迭代了20*104次,将经过18*104、18.5*104和19*104次迭代后输出的检测准确率的均值作为最终的输出结果。图6展示了在视频量化参数QP=36,嵌入率EC=0.05的情况下,检测准确率随训练迭代次数增加的变化情况(图6(a)是使用Ma等方法隐藏信息的情况,图6(b)是使用Lin等方法隐藏信息的情况),从中可以看出本文方法中神经网络所具有的学习能力,即随着训练样本的增长检测准确率逐渐提高。同时本文方法的检测性能明显优于传统基于机器学习的检测方法。

图6 检测准确率随训练迭代次数增加的 变化情况(QP=36,EC=0.05)
(2)本文方法的泛化能力
除与现有方法对比外,我们还测试所提出方法的泛化能力,实验结果见表4。泛化能力即在使用一种隐藏方法所处理的视频帧对网络进行训练的情况下,用另一种隐藏方法所处理的视频帧输入网络进行检测。通过得到的检测准确率评估所提出方法的泛化能力。实验中视频数据的量化参数QP=36,嵌入率EC=0.05,结果见表4。

表4 模型的泛化能力
表中的“Ma/Lin”表示在使用Ma等方法隐藏信息的视频训练网络的情况下,用Lin等方法隐藏信息的视频进行测试。通过实验数据可知,当训练与测试所使用的隐藏信息方法不一致时,检测准确率会出现一定程度的降低。因为本文方法中的检测网络对于不同信息隐藏方法所学习到的特征会有一定程度的差别。
(3)网络中不同结构对检测性能影响
本文方法中的检测网络中引入了新的结构(如量化截断、残差单元等),为验证此部分结构对于检测性能所产生的影响,本文对其进行了测试,其结果如图7所示。图7(a)是完整的网络结构,图7(b)是缺少量化截断操作的网络结构,图7(c)是不采用残差单元的网络结构。

图7 不同结构对于网络检测性能的影响
从图7中实验数据可得,在结构完整的网络中,随着迭代次数的增加,网络的检测准确率逐步提高,最后稳定在一个范围区间之中。而中间图的网络,因缺少量化截断操作,卷积神经网络经历了缓慢的收敛,不仅到达最优性能所需的迭代次数更多,而且所训练网络的检测准确率也会出现小幅的降低。而在最右侧图中,因未采用残差单元,网络训练时出现梯度消失的情况,检测准确性大幅度降低。这也进一步印证所引入各结构时所提出的解释。
4 结束语
针对H.264/AVC视频文件,本文提出了一种基于卷积神经网络的视频流隐藏信息检测方法,其主要针对修改DCT系数隐藏信息的视频文件进行检测。该方法将量化截断操作、残差单元引入现有的卷积神经网络,经过实验验证,本文方法相对于现有检测方法在检测性能上具有一定的提升。
下一步的工作如下:①训练更深的神经网络。目前方法中的网络只有16层,在理论上,网络层次越多训练后的检测准确性越高,但更深的网络需要更加大量的数据进行训练且会面临梯度消失等新问题,这是下一步需要解决的问题。②针对其它视频格式进行检测。
