基于神经网络的搜索引擎模型构建研究
2020-03-07
(广东理工学院 广东 526100)
根据资料显示到2015年底我国搜索引擎用户数量达到5.66亿之多,精明的商家在庞大的数字背后找到了巨大商业信息。因此,在学术界和业界,搜索引擎都引起了人们极高的关注。很多学者都希望得到一种适用的关于搜索引擎结果相关度的计算方法,以往的几种大家都常用的方法有:利用互联网群体智慧来改善搜索结果相关度估计的方法、TF 多,精明等统计方法、利用用户与搜索引擎的交互行为出发的建模分析方法等。但是随着交互技术的出现和发展,搜索引擎的界面结果呈现异质化趋势和二维模块展现形式,这些传统的方法都无法完全描述和分析真实的搜索引擎的界面结果的拓扑结构。本文就是希望建立一个多模态结果来弥补这个缺陷,利用神经网络框架,在搜索查询词和文本类型结果之间引入一个多模态的相似性函数,让一个表征形式为矩阵样式的来表达它们之间的相关性。

图1 搜索引擎结果页面异质化结果
本次实验有两个任务,分别是:(1)建立模型,能描述异质展现形式结果和二维排布结果;(2)用户的点击行为能把搜索引擎的图片和文本相关信息放在同一个空间并且能进行相关性比较。
1 前期工作
1.1 行为模型
用户的行为模型是指用户从开始搜索到结束搜索之间检验的行为模型,一般用户是通过点击来实现。这种行为模型是建立在文档被点击需要同时满足两个相互独立的假设之上的,这两个独立的假设是:(1)该文档被用户浏览过,(2)该文档与查询词相关。在实验中我们用,Ci=1 表示第i条结果被用户点击,Ei=1 表示第i条结果被用户浏览检验过,Ri=1 表示第i条结果与查询词相关,符号“→”来表示满足某前提条件,则以上两个假设可以用如下公式进行如下表达:
CI=1→EI=1,Ri=1 Ei=0→Ci=0
Ri=0→CI=0
如果以P(Ri=1)=ru来表示观测相关性的概率,则文档被用户点击的概率可以用下面公式表示:
P(CI=1)=P(Ei=1)P(Ri=1)
级联模型就是基于点击的模型,在使用过程中该模型的有效性有些许欠缺。动态贝叶斯网络模进行了改进,它是把搜索结果摘要造成的展现偏置也包括在里面的点击模型,这个模型考虑了实际相关性和察觉相关性。Wang 等人是把文本信息和用户行为信息结合起来考虑的点击模型,这种模型结果较前几种就更有效。现在部分学者除了考虑结果位置的之外,还把点击的顺序也考虑了进去,这种方法应该比前面就更加精准的预测性能。
1.2 文本处理方法
对于数据文本的处理方法,在以前的研究中具有代表性的有salakhutdi-nov和Hinton 等人的利用深度网络的改进版LSA模型,其原理是使用自动编码
器学习到的瓶颈特征,而且它主要是用在信息检索方面。有Huang和Shen 主张的框架构建系列模型,其原理是把查询词和结果组合放到同一个空间里面,用相关度来衡量它们间的距离。等等这些方法在完成搜索任务时也取得了很好的效果,但由于用户的搜索的复杂多变,想要扩展它们的模型就变得有点困难。后来又有了Liu 等人的广告推广搜索,其原理是通过点击预测把模型中的多种元素的输入样的局部关键特征提取出来,并且把文本信息也加以考虑进去。Zhang 等人采用了递归神经网络的点击预测框架,其原理是通过建模进行为广告推广搜索而设计。Severyn 等人利用深度学习框架,用于对短文本进行排序,对查询词建立一个矩阵。
1.3 图片处理方法
对于图片的处理常用的方法有Krizhevsky 等人的卷积神经网络模型,其原理是利用框架中对神经元使用非饱和、非线性的激活函数使得对图片的处理速度更快。Lin 等人建立了以自然语言问题和图片的卷积神经网络框架,形成一个整体模型卷积神经网络框架。Wan等人建立了深度卷积神经网络框架,它可以直接从大规模的图片数据中提取图片的特征,从而得到高质量的语义信息。本次实验采取了卷积神经网络的点击模型的框架,它把查询词文本信息、结果文本信息、垂直结果图片信息和用户行为结合起来进行了考虑。对比前面的方法,本次采用的方式主要优点有:同时把点击概率,结果的相关度和用户的检验信息结合起来;把文本信息、图片信息和用户的行为信息进行结合起来;能把从搜索返回结果进行排序研究。
2 基于神经网络的点击模型的构建
本次实验采取的模型框架是能够把神经网络与用户行为信息相结合起来,然后再把它们放在连接层和隐层进行聚合的,其模型框架如图2。
2.1 输入层
查阅了很多资料和以前的实验,本次采用了选择词向量来生成句子矩阵的方法。在实验工作中,使用了一个开源工具,在一个知名的商业搜索引擎中进行了实验,把获得的词向量数据集,以100 维位单位词向量的维度。图片矩阵采用了纵向拼接的方法,这样就把图片的由原来的三维降到了两维,灰度图就用一个实数来表示一个像素点。
2.2 卷积层
利用卷积层来对文本和图片进行采样,从中提取一些有用的有效特征。方法是利用宽卷积来计算文本和图片的矩阵,其后还加上了一个非线性的激活函数并且可以计算卷积层输出的元素。为了结果的正确,本次实验计算中还加了修正线性单元f(x)=max(0,x)来激活卷积层输出元素。

图2 基于神经网络的点击模型框架
2.3 池化层和相似度计算层
本次实验采用了常用的效果较好的最大值池化操作方法,这样做是为了获得更好的点击模型和卷积神经网络结合效果。在输入层中我们把文本信息和图片信息以向量的形式展示出来了,这样就可以计算查询词和文本、图片结果之间的相似度,由Bordes 等人提出的方法公式,就可以得到如下的向量间的相似度和相互影响程度公式:
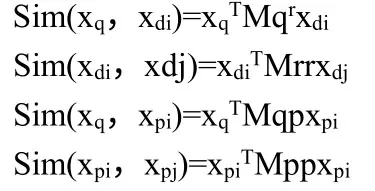
其中xq为搜索查询词对应的向量,xdi为搜索引擎结果页面第i条结果标题内容对应的向量,xpi为图片垂直结果中的第i 张图片内容对应的向量,M是相关性矩阵(计算过程中会不断更新)。
2.4 全连接层和隐层
全连接层把所有的中间向量(包括点击模型得到的加入模型的框架中用户行为信息、查询词与图片对应的向量和两者之间的相似度分数)都串联了起来。在隐层里面把全连接层得出的向量进行交互,其计算公式为:
α(ωh×xjoint+b)
其中ωh是隐层的权重向量,α()是非线性变换。经过这一步后,向量就传递给点击模型层,在点击模型层生成最终的点击预测概率[3]。
2.5 点击模型层
点击模型层由两部分节点组成,一部分可以用于检验,另一部分为相关度。检验概率和相关度通过函数sigmod 得到,把特征输入如下公式通过计算得到:

公式中,xc表示查询词、结果标题文本、图片的信息特征,xm表示由传统点击模型得到的特征,θc,',θm,'是为了结合所有特征值的权重参数,λ与λ′是为了平衡内容影响和点击模型特征影响的权重参数。
3 实验过程及结果与讨论
3.1 实验过程
本次实验采用了概率图来模拟点击模型框架,通过点击概率预测得分来评估点击模型的性能。该值越低就表示该概率分布对于预测结果越准确,本次用到的公式如下:
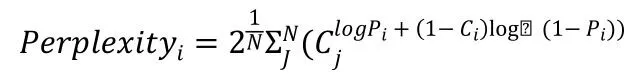
公式中,Perplexityi是第i个结果位置的预测点击概率分数,N是所有的会话数量,Ci是实际用户在这个位置的点击情况,Pi是模型预测的这个位置的点击情况。我们的取值为实验数据的平均值。实验数据如表1。

表1 实验数据
3.2 结果与讨论
本次实验,文本类信息结果的向量用100 维为基本维数,对于一些大规格的图片进行了技术性的压缩,输入采用三原色表示法。从实验数据可以得到,在性能上只有文本信息的模型比包含文本和图片结果两种信息的模型要高,使用全零图片比使用实际图片预测结果要好,实验还表明用不同的表示方法也能得出不同的结果,部分实验结果如图3。
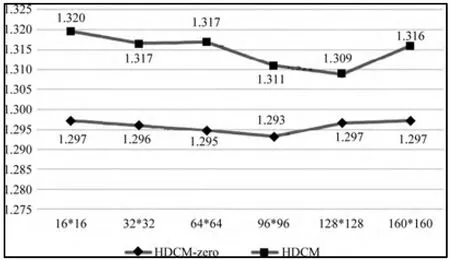
图3 实际图片输入与全零操作模型性能对比
4 总结与未来工作
本次实验是利用深度神经网络和点击模型信息的框架对现在常用的搜索引擎进行研究,找出它们之间的相关性。我们实验结果也表明框架比点击模型在各方面都有所提高。但是由于信息的复杂多变性,即便是深度神经网络的框架也很难把文本信息间建立起十分强的相关性关系。
在未来实验中,一定要对图片采取更加灵活更加适合的特征提取方法,像现在刚发现的白化操作降低输入数据的冗余信息。对于图片将会再进行二维模块浏览点击行为实验,以寻求它们之间的相关性。
