信息安全领域内实体共指消解技术研究
2020-03-05张晗胡永进郭渊博陈吉成
张晗,胡永进,郭渊博,陈吉成
(1.信息工程大学密码工程学院,河南 郑州 450001;2.郑州大学软件学院,河南 郑州 450000;3.信息工程大学信息技术研究所,河南 郑州 450001)
1 引言
实体的共指消解(CR,coreference resolution)旨在解决文档中对实体的重复引用问题,是自然语言处理(NLP,natural language processing)研究的核心内容[1]。它主要用于提高其他NLP 任务中诸如机器翻译[2-4]、情感分析[5-7]、关系提取[8-10]以及摘要自动生成[11-12]等任务的性能。目前,这项研究多集中在通用领域,主要原因在于:1)关于通用领域的共指消解技术有丰富的研究经验[13-25];2)通用领域内的标注语料充足,例如自动内容抽取(ACE,automatic content extraction)语料库[26]、CoNLL-2012[27]、Parcor 语料库[28]等。而关于此项工作在信息安全领域的研究,目前并未找到相关的研究文献。
但是,这并不意味着在信息安全领域内不需要此项工作。例如“As the world’s first cyber ‘super destructive weapon’,Stuxnet has infected more than 45 000 networks around the world.Computer security experts believe the virus is the highest level ‘worm’ever.The new virus uses a variety of advanced technologies,so it is extremely stealthy and destructive.”,在这句话中,“Stuxnet”“the virus”“the new virus”和“it”代表的都是同一个实体“Stunxnet”。通过共指消解,可以获得“Stunxnet”与“the highest level worm”之间是“is-a”的关系,这将提高从文本中提取实体属性关系的准确性,从而使信息安全领域内知识图谱更加完善,而知识图谱的完善也会使其对威胁的预警更加精确。
常用的共指消解技术有3 种:第一种是基于规则的方法[13-16],第二种是基于统计的方法[17-20],第三种是基于深度学习的方法[21-25]。其中,第一种方法依赖于手工定制的规则,覆盖面较窄,灵活性较差,不能很好地处理丰富的词汇信息;第二种方法虽然可以处理丰富的词汇特征,但是有学者认为从准确性上第二种方法的表现弱于第一种方法[29];第三种方法更适用于包含大规模标注数据的领域,而信息安全领域缺乏大规模的可用于共指消解的标注数据,因此该方法并不适用于信息安全领域。文献[19]采用将规则与统计相结合的方法来解决共指消解的问题,虽然该文献提出的方法在通用领域达到了比较理想的效果,但是信息安全领域由于其特殊性与通用实体共指消解有所不同,归纳如下。
1)处理实体类型不同,所以提取候选词的词类不同。在通用领域内,进行提取和消解的实体类型为人名、地名、组织名等;信息安全领域内的实体类型多与“产品”“漏洞”“攻击”相关,因此实体的组合形式通常是以短语的形式出现,例如“Advanced Persistent Threat”。而且,这些实体通常为物体,文本中经常会出现类似于“damage of the virus”形式的短语,其中的“the virus”也是需要提取的待消解词,因此对于信息安全领域中的文本,待提取词除了简单的名词、代词、专有名词之外,还包括名词短语以及一些名词短语中包含的嵌套短语。
2)待提取的词类不同,所以提取方法不同。例如,文献[19]中提取的候选词包括文本中所有的普通名词、专有名词以及代词,提取时用到的是诸如同位语、谓语主格以及角色同位语之类的句法模式。而对于信息安全领域中的文本来说,根据句法模式提取出的候选词并不能满足需要,因此要用到的提取方法也与文献[19]不同。
3)对待消解词进行消解时用到的特征不同。例如,在通用领域对实体类型“人名”进行消解时,可以将性别作为一个重要特征进行考量;而信息安全领域的实体类型多为第三人称形式表示,没有性别特征。
4)相较于通用领域,信息安全领域文本中含有大量的术语和专有名词以及缩写。虽然通用领域中也有一些关于国家或者地名的缩写,但是文献[19]以OntoNotes[30]作为参考并没有对此类缩写进行专门处理。
针对以上问题,本文提出了一种混合的方法来解决信息安全领域内的共指消解问题。本文工作主要分为2 个部分:1)从给定文档中提取出所有的候选词语(包括名词性短语、代词、实体以及嵌套短语)并进行分类;2)对待消解项进行共指消解。本文研究团队在之前的工作中[31],提出了一种BiLSTM+attention+CRF 模型来进行文档中的命名实体识别,解决了文档中存在的同一实体标注不一致的问题,例如Advanced Persistent Threat 和APT。该模型是在经典BiLSTM-CRF 模型的基础上加入Attention 机制来关注当前实体与文档中其他所有单词的相关性,得到该单词在文档层面的特征表示,再进行实体的抽取和分类。但是通过实验发现,该模型对训练集中没有出现过的稀有实体以及长度较长的实体识别能力稍弱,因此本文对该模型进行了改进,提出了一种改进之后的模型BiLSTM+dic_attention+CRF。该模型引入了领域词典匹配机制,将其与文档层面的注意力机制相结合,作为一种新的基于字典的注意力机制来计算单词特征。此外,由于要提取的候选词除了实体之外还包括一些名词性短语、代词以及嵌套短语。如果只使用BiLSTM+dic_attention+CRF 模型来提取名词性短语和嵌套短语,需要浪费大量的人力物力来标注数据,而名词短语和嵌套短语具有一定的语法规则可以进行归纳总结,因此,本文采用规则+BiLSTM+dic_attention+CRF 模型的方式来进行候选词的抽取和分类。本文所做贡献如下。
1)提出一种将规则与深度学习模型(BiLSTM+dic_attention+CRF)相结合的方法来解决信息安全领域内从文本中提取候选词及分类的问题。
2)提出一种将规则与机器学习相结合的混合型方法来解决信息安全领域内的共指消解问题。
与现有方法相比,本文所提出的方法在信息安全领域的数据集上达到了更好的性能。
2 相关工作
关于共指消解的研究由来已久,早期主要集中在基于规则的方法,包括基于语法的Hobbs 理论[13]、基于对话的Centering 理论[14]和基于语法的RAP 算法[15]。在21 世纪早期,一部分学者认为这种基于规则的方法在表现性能上要优于机器学习的方法[29],但是,基于规则的方法的缺点也非常明显,它过于依赖人们手工制定规则的能力,规则制定的好坏将直接影响方法的性能,并且基于规则的方法灵活性较差,耗费人力过多。共指消解中关于机器学习的研究主要集中在训练分类器[1],其中决策树和随机森林是最常用的分类器[17-19]。文献[19]提出了一种将规则与统计分类器相结合的方法来进行共指消解,该方法针对每一种要进行共指消解的类型都训练了一个统计分类器,通过实验不仅证明了这种混合型方法优于基于规则的共指消解方法,还证明了随机森林作为共指消解分类器的优越性。但是该方法仅针对通用领域内的共指消解,因此在选择特征时也是根据通用领域内的文本数据进行选择的。随着深度学习模型在自然语言处理领域的应用,它们也逐渐被应用于共指消解任务[21-25]。文献[21]提出了第一个关于共指消解的深度学习模型,它通过对2 个单独的子任务(回指检测和先行词排序)进行预训练,以学习不同的特征表示。该模型也证明了从实体类群中获取全局特征有利于提高共指消解的性能,但该文献的前提是实体类群是已经事先分类完成的,而本文的工作是首先从文本中提取相关的候选词,因此本文将文献[21]中的实体类群中的全局特征转换成了文档中的全局特征。文献[22]将检测候选词与共指消解相结合,它首先使用卷积神经网络(CNN,convolutional neural network)学习字符的特征,通过LSTM 学习单词的特征,然后通过Attention 机制学习候选词的特征表示,并通过一个前馈神经网络对候选词对应的先行词进行排序。该模型所使用的深度神经网络非常庞大,因此很难维护。
除了这些应用于通用领域的研究之外,生物领域内的共指消解研究也有所发展,主要原因在于,生物领域也具有诸如MEDSTRACT[32]和MEDCo[33]这样的大型标注语料库。典型的应用包括文献[34]中提出的一种基于机器学习和规则的混合方法,它的F1 值为60.9%,是目前生物领域内性能最先进的方法。
针对以上方法中存在的各种问题,本文提出了一种混合型的方法来处理信息安全领域内的共指消解,将从文本中提取待消解项也作为工作的一部分。首先,采用一种规则与深度学习模型相结合的方法来提取文本中的待消解项。其次,采用规则和随机森林的方法进行共指消解。与深度学习的方法相比,这种方法结构简单,需要的训练数据较少。并且本文通过对信息安全领域内文本的研究,挖掘出了适用于信息安全领域共指消解的数据特征并制定出一套规则,可用于信息安全领域的共指消解。
3 基于规则与机器学习的共指消解方法
本文提出了一种将规则与机器学习混合的方法来进行共指消解。该方法的工作分为2 个部分:1)从给定文档中提取所有的候选词语(包括名词性短语、代词、实体以及嵌套短语)并进行分类;2)对待消解项进行共指消解。方法框架如图1 所示。
从图1 中可以看出,该方法分为提取候选词和共指消解这2 个部分。其中,提取候选词部分由规则+BiLSTM+dic_ttention+CRF 混合而成,用于提取文本中的待消解词并进行分类,该部分对应3.1 节的内容。共指消解则主要对分类之后的待消解词进行共指消解,该部分对应3.2 节的内容。图1 中,最底层的其他特征代表3.1.2 节中除了单词特征之外的其他特征;顶层中的其他特征代表3.2.2 节中的名词短语共指消解除了类型一致性之外的其他特征;D(wi)表示单词wi在领域词典中的匹配度;Wd表示单词匹配度所占的权重;表示单词wi在文档层面的特征表示;gi表示单词wi基于领域词典的新的文档层面特征表示。
3.1 提取候选词语并分类

图1 方法框架
本文要提取的候选词包括名词性短语、代词、实体以及嵌套短语,可将其分为名词性短语和嵌套短语的提取以及实体的提取。名词性短语和嵌套短语的提取采用规则的形式进行提取,实体的提取采用BiLSTM+dic_ttention+CRF 模型进行提取。具体架构如图1 中的提取候选词部分所示。
3.1.1 名词短语和嵌套短语的提取规则
通常情况下,名词短语是由名词以及它的修饰语组成,中心词为名词。名词的修饰语与名词有2种位置关系:一是放在被修饰名词的前面,叫作前置定语或定语;二是放在被修饰名词的后面,叫作后置定语。通过对信息安全领域内语料的分析发现,需要进行共指消解的名词短语通常为前置定语名词短语,因此这里只考虑第一种位置关系的情况。
一般来说,作为前置定语的词类有2 种:其一是限定词,用来限定名词所指范围,例如these、three、a、the、my 等;其二是形容词,用来表示名词的性质和特征,比如red、close、new、small 等。因此,可以通过如下规则来获取名词性短语。
假设U1表示冠词集合,U2表示形容词性物主代词集合,U3表示名词性物主代词集合,U4表示指示限定词集合,U5表示数量词集合,U6表示基数词集合,N表示名词集合,NP 表示名词短语集合,AD 表示形容词集合,集合U=U1∪U2∪U3∪U4∪U5∪U6。
1)如果单词a属于冠词、形容词性物主代词、名词性物主代词、指示限定词、数词、量词、基数词等集合中的任意一个单词,单词b属于名词集合,则ab构成名词性短语。
2)如果单词c属于形容词,单词b属于名词集合,则cb构成名词短语。
3)acb属于名词短语。
可表示为
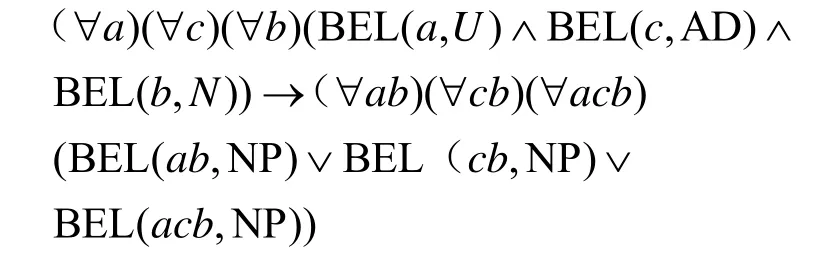
其中,BEL 表示谓语动词“属于”。
除此之外,还要提取嵌套短语。嵌套短语通常存在于所提取出的名词短语中,通过对嵌套短语的语法分析,制定出如下提取规则。
假设NNP 表示嵌套短语集合,ONP 表示所有格名词短语集合,P表示介词集合。
1)嵌套短语来自所有格名词短语。例如,短语“its methods”中的嵌套短语是代词“its”“stuxnet’s damage”中的嵌套短语是专有名词“stuxnet”,可表示为
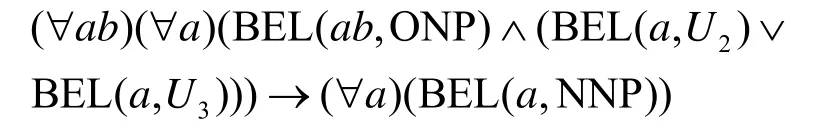
2)嵌套短语是名词性短语中的名词或介词。例如,名词性短语“efficiency reduction”中嵌套短语是“efficiency”,可表示为

如果提取出的名词性短语中包含实体,那么只提取实体部分。
3.1.2 实体提取和分类
1)输入特征
在图1 中,除了使用制定的规则来提取名词短语和嵌套名词短语之外,还要使用模型BiLSTMdic_attention-CRF 对文本中的实体进行提取和分类。此时,模型的输入特征包括以下几个方面。
①单词特征。单词特征又被称为分布式单词表示,可以从一个大型的未标记语料库中获取单词的语义和句法信息。Word2vec 是最常用的单词向量训练工具。为了获得高质量的单词向量表示,本文使用文献[31]中从CVE语料库中收集的94 534条漏洞记录描述进行单词向量训练。
② 词性标注特征(PoS,part of speech)。词性标注特征也被称为语法标注或词类消疑,是语料库语言学中将语料库内单词的词性按其含义和上下文内容进行标记的文本数据处理技术。人们要提取的候选词,特别是名词性短语和嵌套短语,都要用到单词的词性标注信息,因此,词性标注需要作为重要的输入特征。本文使用Stanford CoreNLP 作为词性标注工具。
③字符特征。字符特征包含实体名称的结构信息,可以表示实体名称的特定组成,特别是在信息安全领域。例如,影响Windows 的PE 病毒Backdoor.Win32.Gpigeon.pd 和Backdoor.Win32.Gpigeon2010.pc具有相同的前缀,因此,当模型遇到这些单词时,人们可以根据它的前缀判断出它是Windows 的PE病毒的名称。与传统手工设计的字符特征不同,人们可以通过训练得到单词的字符特征向量。因为英文中的字符个数有限,构造出的字符表远远小于词表,因此本文采用文献[35]中提到的字符训练方法,通过PoS 标记来对字符进行训练,并进行大小写字符及特殊字符的区分。
2)BiLSTM-dic_attention-CRF 模型
BiLSTM-dic_attention-CRF 模型是在BiLSTMattention-CRF 模型的基础上添加了领域词典,将其与原来的文档层面Attention 机制相结合,作为一种新的基于字典的注意力机制来计算单词特征,以解决BiLSTM-attention-CRF模型对训练集中未出现过的稀有实体以及长度较长实体识别稍弱的问题。本文模型中使用到的领域词典是本文研究团队在之前的工作[36]中,通过wikipedia 和信息安全领域的UCO(unified cybersecurity ontology)构造出来的。
假设有文档D={s1,s2,…,sn},其中,si={w1,w2,…,wm}为组成文档D的第i个句子,wi={c1,c2,…,ck}为句子si的第i个单词表示,ci是单词wi的第i个字符特征表示,pi表示单词wi的词性特征表示,则可以得到关于单词wi的新的特征表示hi为
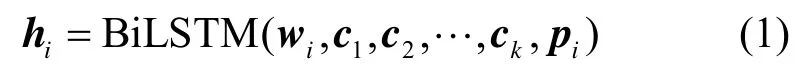
其中,hi作为Attention 层的输入,Attention 层主要用来计算单词wi与文本中其他单词w(jj=1,2,3,…,i-1,i+1,…,mn)的关联度,该权重值aij可表示为式(3)。
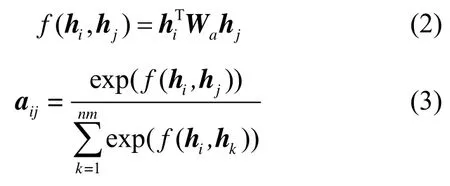
其中,Wa为需要训练的模型参数。

这里引入了领域词典匹配机制,将其与Attention 机制相结合,计算出新的基于领域词典的全局特征表示gi如式(8)所示。
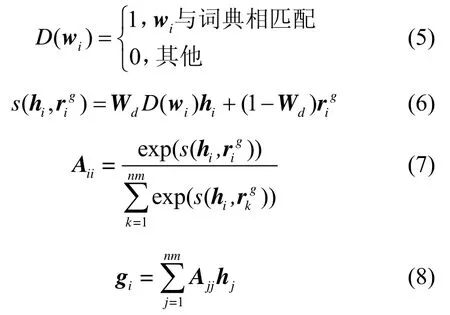
接下来,使用一个tanh 层来获取单词wi与文档中其他单词相关的特征表示。
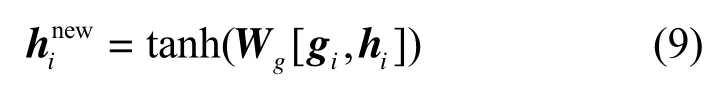

3.2 候选词的共指消解
由于在信息安全领域缺乏大规模的可用于共指消解的标注语料,因此,本文提出一种将规则与机器学习相结合的方法来进行候选词的共指消解。需要进行共指消解的候选词包括代词以及名词短语(本文提取的实体属于名词,也划分进名词短语中)。
其中,最难解决的部分是关于代词的共指消解,它与语句的语法结构有着极大的关系[1],因此这部分工作将采用定制规则的形式完成;关于名词短语的共指消解,则使用机器学习的方法完成。
3.2.1 代词的共指消解
通过对收集来的文本进行分析,需要进行共指消解的代词分为2 种:第一种是关系代词;第二种是人称代词,由于信息安全领域中不存在人物作为实体,因此本文仅对第三人称代词进行消解。
1)关系代词消解
关系代词的先行词通常在同一个句子中。对于关系代词,选择所有位于它前面的名词短语作为它的候选先行词。然后根据句子的句法分析树,提取关系代词与候选词之间的句法分析路径并选择最短路径,将距离最近的名词短语作为关系代词的先行词。举例说明如下。
例1Sentence:(Autoruns)1revealed that there are (two core files)2(Mrxcls.sys)3and (Mrxnet.sys)4in (the Stunex)5(which)? was (the first malicious code)to damage (the industry control system)in the world。
消解例1 分析结果如表1 所示。通过对例句进行句法分析,提取从关系代词到各候选词之间的分析路径,其中最短的一条为“NP-NP-SBARWHNP”,对应的候选词为“the Stunex”,则该候选词即是关系代词“which”的先行词。
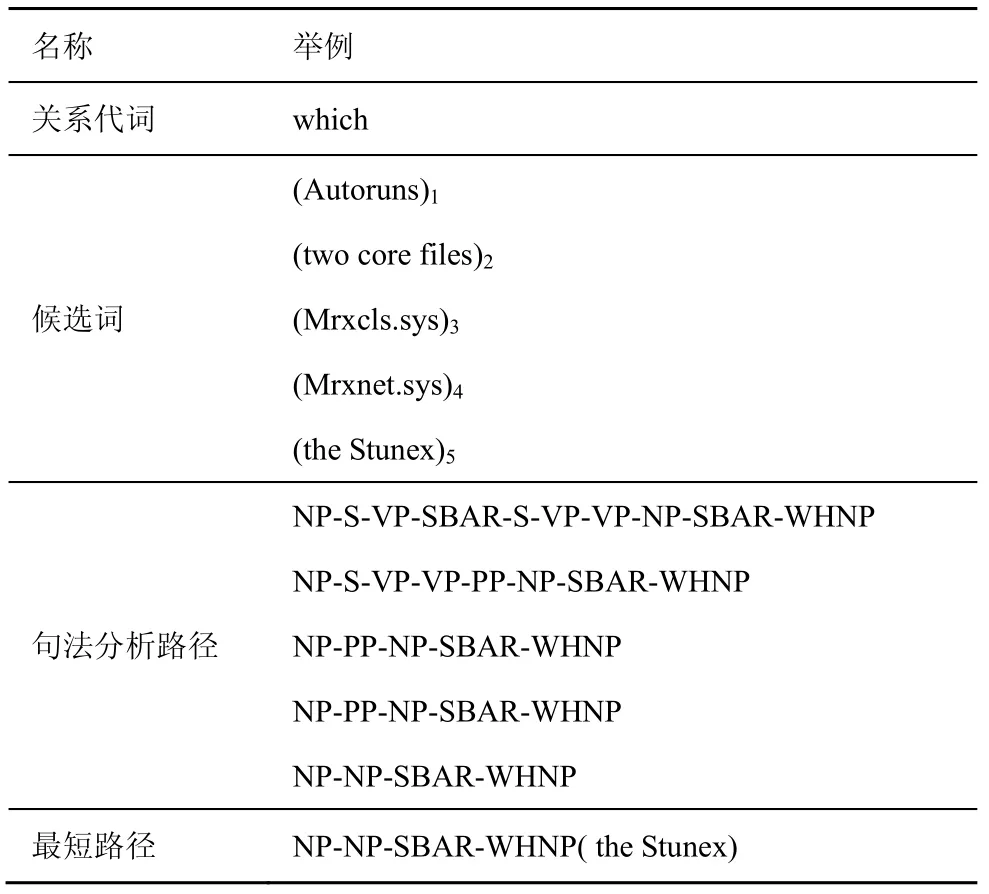
表1 消解例1 分析结果
2)第三人称代词消解
人称代词的先行词最有可能位于同一句或前一句。首先在同一个句子中搜索候选先行词,如果候选集为空,则从前一个句子中重新提取候选词并找到可能的先行词。由于人称代词必须指代实体,因此只保留安全领域实体候选词。如果候选集不为空,则将语法解析树从人称代词节点开始从下往上移动,如果有并列结构(包括并列名词短语、并列动词短语和并列从句),则选取第一段子结构中距离最远的候选词(按词距计算)作为人称代词的先行词;否则,从语法解析树中找到最近的子句或句子,选择其中距离最远的候选词作为先行词。举例说明如下。
例2Sentence:(Stuxnet)1searches for (specific programs)2,accesses (industrial control systems)3,((its)?attack object)is the target program development tool。
消解例2 分析结果如表2 所示。“its”的实体候选词为“Stuxnet”“specific programs”和“industrial control systems”,其中,有2 个并列结构作为候选,分别是“(Stuxnet)1searches for (specific programs)2”和“accesses (industrial control systems)3”,这里,“(Stuxnet)1searches for (specific programs)2”为句子中的第一段并列结构,里面包含了2 个实体候选词“(Stuxnet)1”和“(specific programs)2”,“(Stuxnet)1”距离“its”最远,即为先行词。
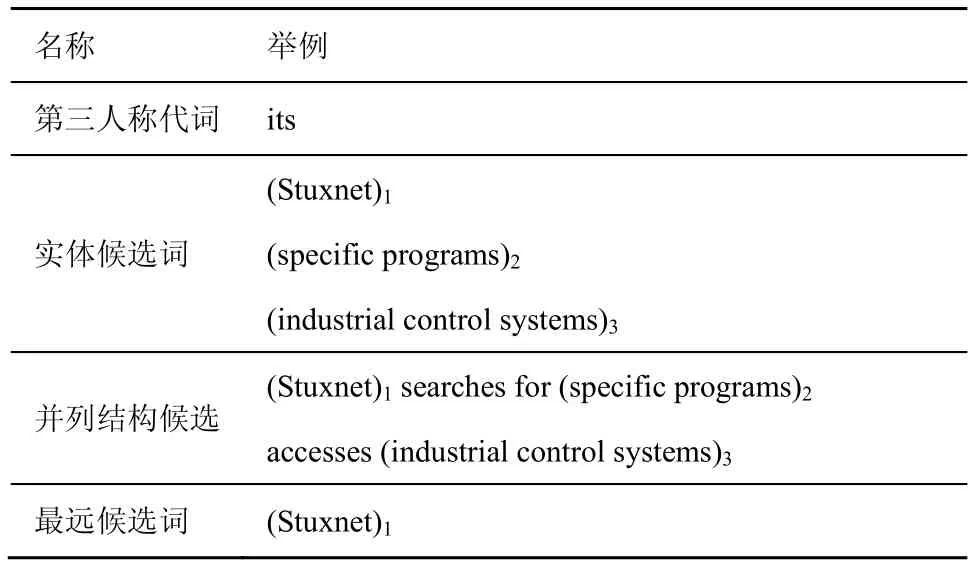
表2 消解例2 分析结果
3.2.2 名词短语的共指消解
首先,介绍进行机器学习时需要使用到的特征向量,每个特征是通过比较2 个待消解项之间相应的属性得来的,如下所示。
1)所属类别是否一致。在3.1 节抽取候选词的同时对其进行了分类,直接比较2 个待消解项的类型是否一致,为二值属性,一致为真,不一致为假。
2)别名和简称是否一致。如果2 个待消解项其中一个是另外一个的别名或者简称,则值为真,反之则为假。
3)单复数是否一致。分析2 个待消解项后所跟动词或者系动词的形式,判断单复数是否一致,一致为真,不一致为假。
4)2 个待消解项在文本中的距离。用2 个待消解项在文本中所间隔的句子条数表示。
5)名称相似性。例如短语“the virus”通常与某个病毒的名称具有相同的指代,与含有“product”“company”等词语的短语则不会。
6)同位语。通过句法分析器可以判断出2 个待消解项中的一个是否为另外一个的同位语,同时获取这2 个待消解项的同位语成分。
7)中心词的相似性。通常情况下,认为名词短语中的中心词是名词,本文通过余弦相似度来比较2 个名词短语的中心词的相似性。
8)结尾词的相似性。使用余弦相似度比较2个名词短语的最后一个单词的相似性。
接下来,进行构造训练集。假设文档中含有一条指代链A1-A2-A3-A4,在这条链中直接相邻的指代项对(如A1-A2,A2-A3,A3-A4)生成正训练样本。在这样的指代项对中,第一个名词短语通常被认为是先行词,而第二个名词短语则是后置词。负训练样本的提取如下。例如,有 B1和 B2是出现在 A1和A2之间的其他对象,那么可以得出负训练样本为A1-B1,A1-B2,B1-A2,B2-A2。举例说明如下。
例3Sentence:As the world’s first cyber“super destructive weapon”,has infected more than 45,000 networks around the world.believeisever.uses a variety of advanced technologies,so it is extremely stealthy and destructive。
共指消解的问题事实上就是一个对候选词进行分类的问题,因此,本文采用随机森林算法来解决此问题。随机森林算法是一个包含多棵决策树的分类器,易于实现,计算开销也很少。
图2 举例说明了使用随机森林算法进行共指消解的过程。假设此时要对候选词“the virus”进行消解,算法首先根据该候选词找出某个范围内的所有可能的先行词(一般情况下选择前后相邻的2 个句子中的所有名词短语)。选择具有最高置信度的指代链中的先行词作为该候选词的先行词。通过设置一个最小的置信阈值ti来控制指代链过度生成,如果不存在置信度值大于ti的指代链,则该候选词没有共指先行词(此状态可能会在后续消解过程中更改)。其中,ti的值可通过训练得出。
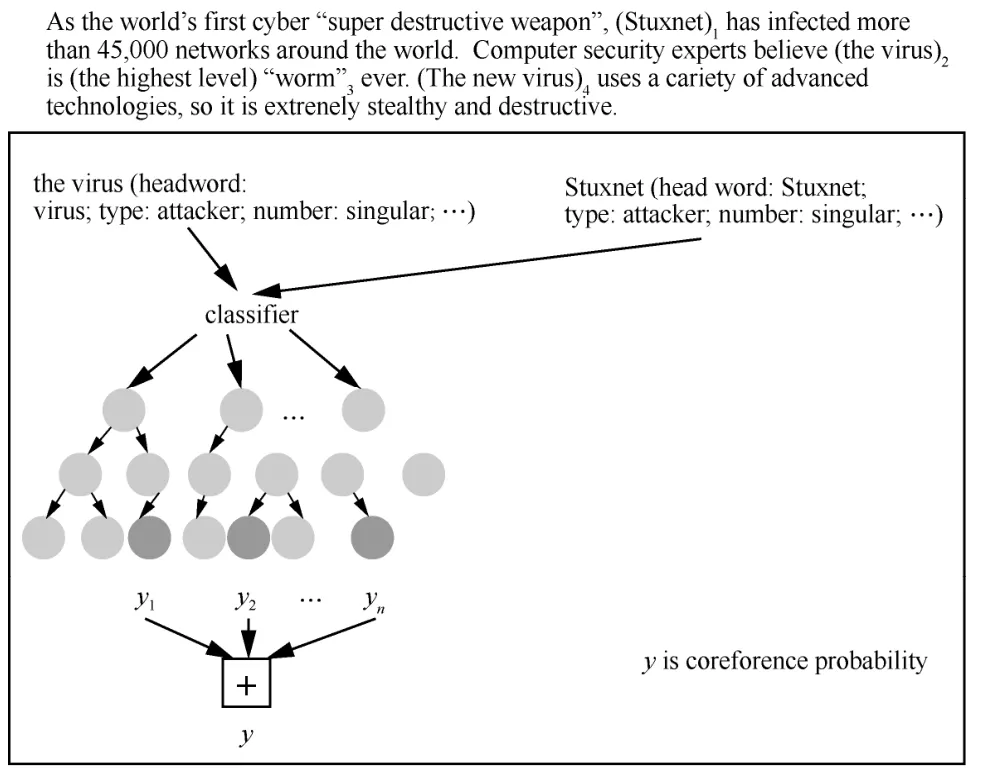
图2 共指消解示例
4 实验及结果分析
本文验证部分进行了4 个实验。实验1 获取了所提方法在领域词典匹配度权重dW的最佳取值;实验2 通过与其他基准模型的比较,验证了所提方法在信息安全领域语料上进行共指消解的优越性能;实验3 证明了单个特征对名词短语共指消解的影响程度;实验4 验证了所提方法与其他基准模型相比在候选词提取时的优越表现,并验证了领域词典匹配机制的加入对之前工作[31]在实体提取和分类时的改进。
4.1 数据来源
本文使用的实验数据来自之前工作[31]所收集的信息安全领域文本,包括 we live security、threatpost 等处的博客文章,CVE(common vulnerabilities and exposures)描述,微软安全公告以及信息安全类文章摘要,从中摘取了20 篇摘要、45篇博客文章、59 段CVE 描述以及50 篇微软安全公告,共包含9 123 条句子。在之前的工作中,已经对这些文本中的实体标注了类型,因此这些标注语料可作为BiLSTM+dic_attention+CRF 模型的训练数据,从中抽取了20 篇安全报告和20 篇博客标注了指代链,共获取指代链45 932条,其中正训练样本为7.5%。这些指代链将作为机器学习的训练数据。
由于负训练样本的数据远多于正训练样本,为了减少训练时间,本文采取了文献[19]的负样本抽取方法,具体步骤如下。
1)使用训练数据集中所有的正训练样本,随机抽取10%的负训练样本,进行分类器的训练。
2)检查所有负训练样本的分类器置信值(即估计概率),只保留前10%最模糊的负训练样本,即与正训练样本相比置信值最高的负训练样本。本文使用这些信息量更大的负训练样本和所有正训练样本来训练最终的分类器。
4.2 实验设置
设置特征向量的维度为300,BiLSTM 中的神经单元数为1 000,最小批次个数为64,最大迭代次数为100。使用文献[37]中提到的方法更新模型参数,并设置学习效率为10-3,l2为10-5。为了避免过拟合,本文采用 dropout 技术。BiLSTM 和Attention 层的dropout 值分别为0.3 和0.5。随机森林中的参数设置主要是对其中单个决策树的参数设置,最小置信阈值为30%,叶子节点最小样本数设置为5,最大深度为默认值,决策树的个数为100。这些参数都是在训练集合中通过10 倍交叉验证得出的。
实验是在2 个NVIDIA GTX 1080Ti GPU 和内存为64 GB 的机器上完成的,模型训练时间约为1 h。
4.3 实验结果与分析
实验1验证BiLSTM-dic_attention-CRF 模型中领域词典匹配度权重dW的取值。在实验1 中,提取的信息安全领域实体包括4 种类型,分别是“product”“vulnerability”“attacker”和“company”,以0.05 的步长将权重值从低到高进行设置,其他参数保持不变,其表现性能如图3 所示。其中,P代表准确率,R代表召回率,F代表F-Measure。
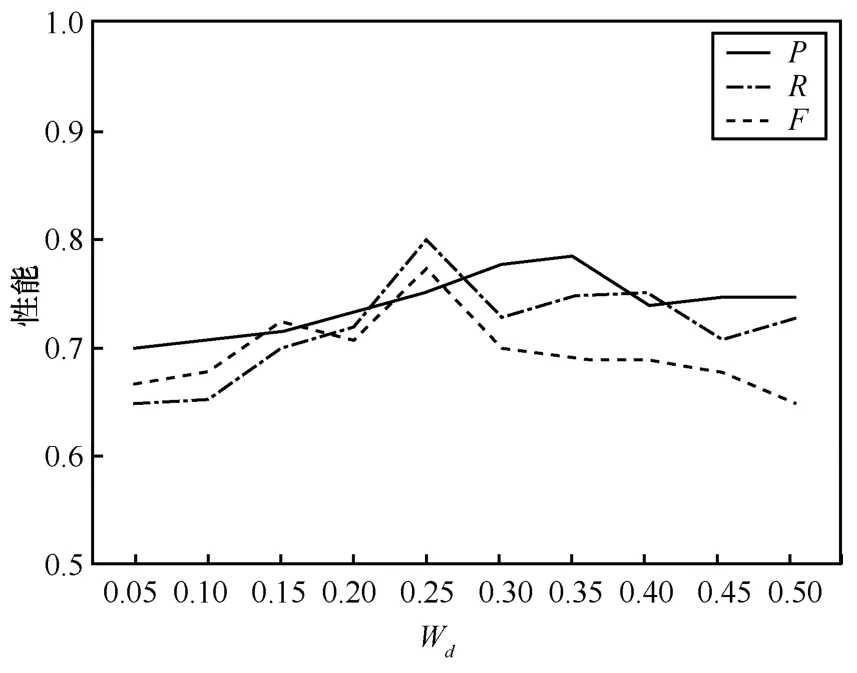
图3 Wd取不同值时模型的性能
从图3 可以看出,Wd=0.25 时模型性能最优,此时F=0.78。
实验2验证本文所提方法在信息安全领域共指消解的优越性。使用的4 个基准模型为文献[19]所提的scaffolding approach、Soon 等[17]方法、Zhang等[23]方法、Wiseman 等[24]方法。将基准模型与本文所提模型一起应用在信息安全领域数据中,实验结果如表3 所示。
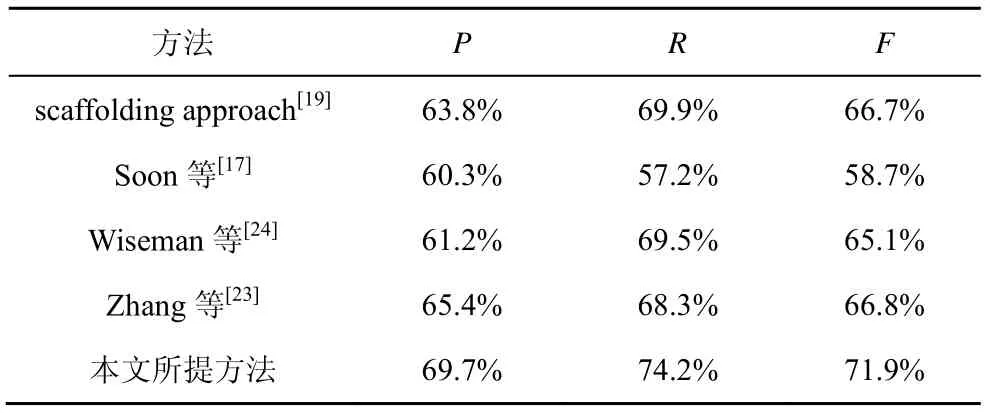
表3 各模型性能
从表3 中可以看出,本文所提模型在信息安全领域数据的表现性能要优于其他4 个模型。通过对错误样本的分析可以看出,Wiseman 等[24]方法的主要核心在于使用RNN 学习实体类群中每一个实体的潜在全局表示,再通过RNN 对这些实体进行共指消解。但是本文模型并没有给出具体的聚类方式,而是默认实体已经聚类完成。于是,先利用本文所提模型将文本中需要进行共指消解的候选词提取出来,然后采用最简单的k-means 聚类法对这些候选词进行聚类,但是实验后的结果并不理想。通过分析得出,在对这些实体聚类时,通常会把不具备领域特征的代词聚在一起,对这些类群学习全局特征表示时,很难学习到领域特征,这无疑会影响后续共指消解的性能。scaffolding approach[19]和Soo 等[17]方法所处理的文本都是通用领域的文本,所制定的特征大都针对“organization”“person”等通用领域内的类型实体,因此在对信息安全领域内数据共指消解时的表现较差。Zhang 等[23]方法通过Biaffine Attention 机制以及优化候选词提取损失函数进行共指消解,需要大量的标注训练数据来训练参数,因此虽然在CoNLL-2012 数据集中取得了优良的表现,但是在标注数据有限的信息安全领域数据集中表现稍弱。
实验3针对单个特征对模型的影响进行实验。8 种特征对应的数字编号如表4 所示。

表4 特征对应的数字编号
单个特征值对模型性能的影响如图4 所示。
从图4 中可以看出,在所有特征中,同位语特征对共指消解性能的影响最小,主要原因是对同位语的认定比较复杂,对于一些语法结构相对比较复杂的语句,仅依靠句法分析工具判定句子中的同位语准确率并不高。此外,中心词相似性及别名和简称特征对共指消解性能的影响最高,主要原因分析发现如下:1)在信息安全领域的文本中含有很多领域内的专业术语及简称,例如,Advanced Persistent Threat 简称APT;2)对名词短语来说,中心词往往决定了该短语的主要含义。
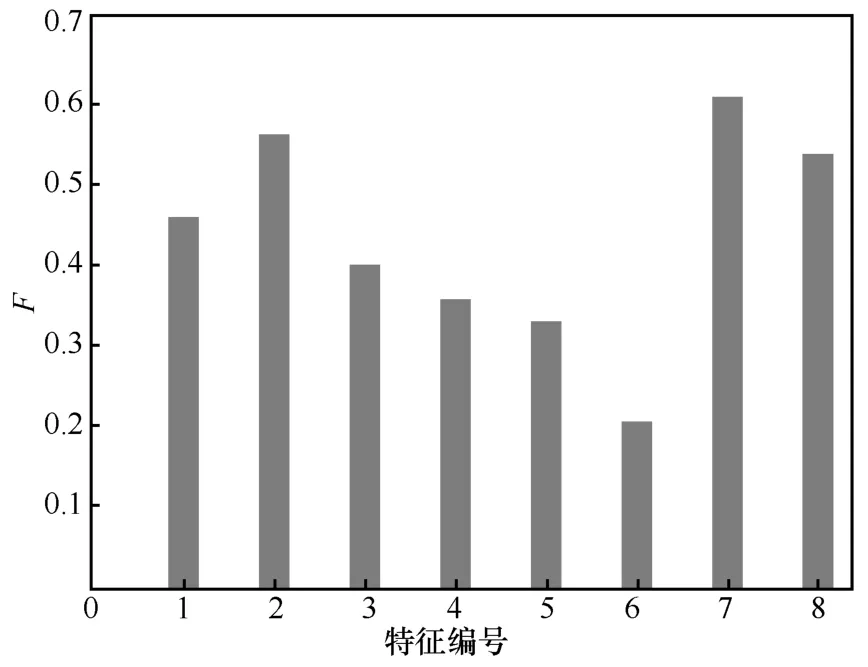
图4 单个特征值对模型性能影响
实验4对文本中候选词提取的效果也会影响共指消解的效果,因此验证本文所提的将规则与神经网络模型(BiLSTM-dic_attention-CRF)相结合进行提取候选词的方法(简称rule-based BiLSTMdic_attention-CRF)的性能。这里使用的基准模型包括实验2 中的3 个基准模型,以及本文之前工作[31]中的方法,此处用previous work 表示。实验4 提取的信息安全领域实体包括 4 种类型,分别是“product”“vulnerability”“attacker”和“company”。实验结果如表5 所示。
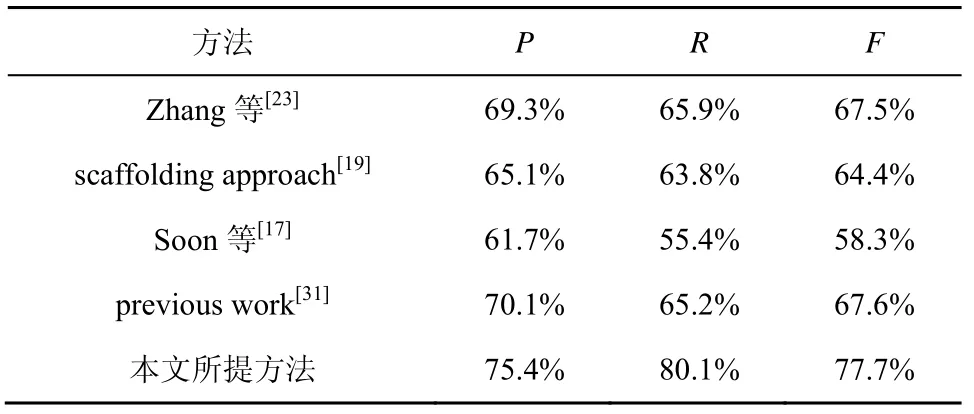
表5 各模型提取候选词的性能表现
从表5 中可以看出,本文所提方法(rule-based BiLSTM-dic_attention-CRF)在信息安全领域数据上的性能优于目前已知的提取候选词方法,主要原因在于,本文所提方法除了依赖深度学习之外,还通过对信息安全领域中的数据文本进行分析,总结出了一套与之相契合的提取规则,两者结合在一起才能达到较好的效果。图5 展示了BiLSTM-dic_ttention-CRF 模型和本文之前的模型(previous work)对例句“Stunex searches for specific programs access industrial controlsystems”的实体提取分类效果。其中,B、I、O 表示的是BIO 标注,如果单词被标注为B,表示该单词为某个片段的开头,同理,I 表示该单词在片段的中间位置,O 表示不属于任何类型。
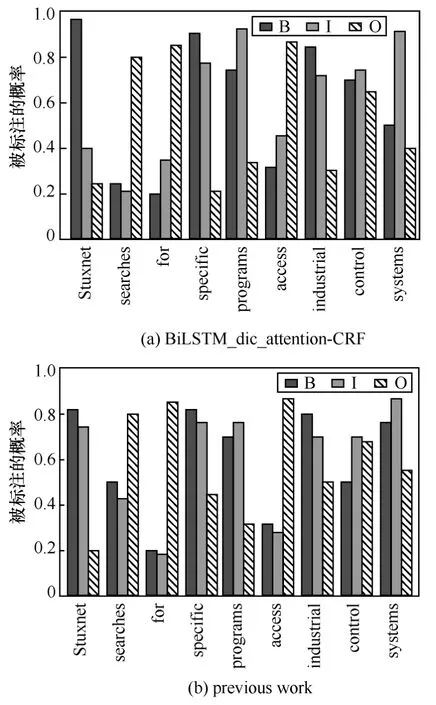
图5 2 种模型对例句的实体提取分类效果
基于文档层面特征向量在进行实体提取工作时的优越性已经在本文之前的工作[31]中进行了验证,此处不再赘述。
通过对rule-based BiLSTM-dic_attention-CRF提取出的错误结果进行分析,本文方法依然存在着候选词提取边界过长、先行词中单词缺失以及候选词为无用候选词(即无共指关系)等问题,有待于进一步解决。
5 结束语
本文提出了一种混合方法来解决信息安全领域内的共指消解任务中的2 个问题:1)从给定文档中提取出所有的候选词语并进行分类;2)筛选出符合条件的待消解项进行共指消解。本文针对信息安全领域内文本的特点制定出一套规则并与深度学习模型(BiLSTM-dic_attention-CRF)相结合来解决对文本中候选词语的提取和分类问题,将共指消解分解成代词的共指消解和名词短语的共指消解,代词消解通过规则完成,而名词短语的共指消解通过机器学习完成。实验证明,本文所提方法相较于其他基于通用领域构造的模型,在信息安全领域上的应用性能更加优越。
