大坝监测数据的时序预测与补全
2020-03-05杜曼玲高嘉欣张礼兵罗明清陈云天胡文波田天
杜曼玲,高嘉欣,张礼兵,罗明清,陈云天,5,胡文波,6,田天,6
(1.中国电建集团国际工程有限公司,北京 100142;2.北京瑞莱智慧科技有限公司,北京 100084;3.中国电建集团昆明勘测设计研究院有限公司,云南 昆明 650051;4.中国电建集团海外投资有限公司,北京 100142;5.鹏城实验室智慧能源工作室,广东 深圳 518055;6.清华大学人工智能研究院,北京 100084)
0 引 言
目前我国拥有水库大坝9.8万余座,是世界上水库大坝最多的国家,水坝在统筹防洪、发电、供水、灌溉等方面发挥了重要作用,是组成国民经济的战略性基础设施之一[1]。目前水坝面临着数量多、时间长、设备老旧、气候变化、建设条件复杂等多重因素带来的风险,其安全问题日益突出。如何准确、全面地进行大坝安全监测和预报,对大坝安全运行和辅助决策具有重要的意义[2]。
大坝工程正在步入数字大坝和智慧大坝阶段,尽管现代网络技术使得工程师能够在大坝全生命周期内展开实时、在线、全天候的管理与分析[3- 4],但由于早期大坝建设中存在的信息化建设不系统、不全面、不统一以及老旧水坝的设施落后甚至缺乏现代监测设备等问题,使得大坝安全监测普遍面临数据缺失和数据碎片化的挑战[5]。基于传统数学模型的数值拟合方法难以对残缺的大坝安全数据进行有效的补全与预测。
随着人工智能领域的快速发展,很多研究者开始采用这一方法解决大坝安全监测和预测问题。赵斌等人应用人工神经网络进行大坝安全数据的预报[6],樊琨基于人工神经网络方法建立非线性力学反分析模型解决岩土工程中的复杂非线性问题[7],蒋利娟基于线性回归模型利用降水量预测水位数据[8],姜成科提出的GA-LMBP算法提高大坝安全监测人工神经网络模型的拟合效果和预测精度[9]。本文采用广泛应用于深度学习的高斯过程回归(Gaussian Process Regression, GPR)[10]、LightGBM(Light Gradient Boosting Machine)[11]、长短期记忆神经风络(Long Short-term Memory,LSTM)[12]等模型进行大坝监测参数的预测与补全,并与传统方法做对比[13]。
机器学习方法所表现出的自组织性、自适应性、模糊推理能力和自学习能力等优势非常适合解决大坝安全数据补全与预测这一复杂的非线性问题[14]。本文提出的大坝安全数据的时序预测与补全模型是针对采集的海量数据进行深度、有效分析的前提。基于本文提出的方法所获得的高质量大坝安全数据有利于构建智慧大坝安全评估体系,是智能监控、智能诊断、智能决策的基础,有助于切实提升大坝安全智能管理能力。同时,将专家知识与海量的大坝安全数据通过人工智能技术相结合,是对大坝不同维度物理量之间的深度融合,是实现可感知、可分析、可控制的智能化大坝建设有效途径[15-18]。
1 研究方法
1.1 基于高斯过程回归的数据插补预处理
高斯过程回归(Gaussian Process Regression, GPR)模型是机器学习领域的一个经典模型。GPR以其良好的泛用性和可解释性,在时间序列分析、自动化控制、图像处理等诸多领域都有广泛应用[19-20]。
由于传感器故障或人工操作的失误,水坝数据中往往存在个别缺失值,此外,由于工况和环境的复杂性,原始数据中还会存在一些随机噪声或粗差。这些不利因素都会影响大坝安全数据补全以及预测工作的正常开展。因此,大坝安全数据补全以及预测的第一步是对原始数据做插值和平滑处理等预处理。
1.2 采用的机器学习算法
1.2.1长短期记忆神经网络
神经网络能够通过学习来近似拟合输入和输出变量之间的非线性函数关系。它的基本运算单位是神经元,神经元对输出的影响由神经元之前的权重来表现,这个权重会随着网络的训练不断调整。在网络中,每个神经元的输出都通过非线性函数计算得到,而非线性函数的输入是其他神经元输出的代数和。
常规神经网络由于只能构建单一的映射关系,对于时间序列问题的预测效果并不理想[21]。长短期记忆神经网络(LSTM)不仅能够利用当前的特征信息,还能够利用先前计算产生的中间结果,实现了无效信息的遗忘和有效信息的加强。因此,LSTM是解决如位移、渗流等大坝安全数据序列问题的最自然且最合适的理想工具。
1.2.2LightGBM模型
决策树是一种常见的机器学习模型,它代表的是对象属性与对象值之间的一种映射关系[22]。决策树,本质上是针对样本的重要特征不断做出判断,根据每步的判断结果寻找合适的路径,最终得到合适的预测结果。决策树模型具有多种实现方法。LightGBM(Light Gradient Boosting Machine)[11]模型是众多方法中较为高效的之一,与其他方法相比,LightGBM具有更高的训练效率、更低的内存使用、支持并行化学习等特征,这些优秀的特征使得它在实际生产中有比较广泛的应用。
1.3 时间序列预测与补全任务
1.3.1经验模型
在经验模型中,通常都假设某一时刻的安全监测结果(如位移、渗流等)主要受水压、温度等环境量因素以及时效等因素影响,因此,安全监测结果由水压分量、温度分量和时效分量组成,即δ=δH+δT+δq。其中,δ表示位移;δH表示水压分量;δT表示温度分量;δq表示时效分量。从本质上来讲,经验模型就是一个以环境量和时效量为特征的多项式回归模型。
1.3.2时间序列预测与补全
在大坝安全数据时间序列预测这个问题上,本文尝试了不同的时间序列预测方法,包括前文提到的传统方法、经典的时间序列模型自回归滑动平均模型(Autoregressive moving average model, ARMA)[23],还有全连接神经网(Fully Connected Neuron Network,FCNN)、LSTM和LightGBM这三个机器学习模型。在三个机器学习模型中,本文用到的特征包括历史的环境量数据(温度,上下游水位,降水)和待预测安全数据的历史数据,应用历史数据的长度和具体问题有关,一般来说应用两个月以内的历史数据即可。
当大坝安全数据由于某些原因(比如传感器长时间故障等)出现大范围缺失的情况下,数据本身的规律变得难以挖掘,数据插补和时间序列预测的模型变得不再适用。为了针对大坝安全展开进一步的研究,必须对这些缺失数据有效补全。对于同一坝段,不同位置的相同类型数据可能有着相似的变化规律,我们可以根据坝段其他位置的信息,去补全坝段的当前位置数据。具体地,本文针对某个缺失数据较多的坝段,找出多个与目标坝段相近且数据较全的坝段,对它们的传感器数据进行插补、平滑等预处理操作。然后,用这些临近坝段的相对完整的数据训练模型,以便模型可以建立起不同点位数据之间的映射关系。最后,将这一模型应用于目标坝段,基于目标坝段中完整的点位数据,补全目标坝段中残缺点位的数据。其中,这个模型可以是简单的线性模型,也可以是本文前面提到的神经网络模型和LightGBM模型。
2 结果分析
2.1 高斯过程回归数据预处理结果
在数据预处理阶段,主要应用高斯过程回归(GPR)模型对数据进行平滑和插补,最终数据处理的效果如图1a(处理前的原始数据)和图1b(处理后

图1 高斯过程回归数据预处理结果
的数据)所示。平滑操作可以有效保留数据的趋势特征,并消除随机噪声与粗差的不利影响,处理后曲线更反映大坝安全数据的变化趋势。
在数据平滑的过程中,基于高斯过程回归处理的结果的置信度分布如图2所示。

图2 平滑数据的置信区间
当数据变化趋势较为稳定,预测结果的不确定性就比较小(阴影宽度降低),而当数据的趋势发生变化时,数据的不确定性会有所增加。本文模型给出的结果和专家的主观经验吻合,符合物理机理。
2.2 时间序列预测结果
对于时间序列预测问题,本文对比分析了多种模型,包括经验模型和神经网络模型(FCNN与LSTM)。本文以某水电大坝位移数据为例测试。使用MSE(Mean Square Error,均方误差,指的是参数估计值与参数真值之差平方的期望值)值描述预测值和真实值的差距,MSE越小意味着预测精度越高;同时以R2 score (R方值,决定系数,反映的是因变量的全部变异能通过回归关系被自变量解释的比例)描述预测数据的变化趋势和真实数据变化趋势的相似性,它越接近1则模型预测精度越高。根据实验结果,经验模型难以在所有坝段均取得良好的效果。而基于深度学习的FCNN模型和LSTM模型在每个坝段上都取得了明显优于经验模型的良好效果,具有较好的预测稳定性。
本文对不同模型所取得的时长一年预测结果绘图展示,如图3所示。纵坐标代表位移数据。实线曲线表示真实值,实线带三角标识的曲线是预测值。对比图3可知,经验模型能够在一定程度上拟合数据的变化趋势,但是在预测时间点与已知时间点距离较远时精度较差。即随着时间推移,经验模型存在误差累积的问题。然而对于深度学习模型而言,预测结果不但很好反映了真实值的变化趋势,而且在具体数值上也预测准确,具有较好的预测效果。
2.3 时间序列补全结果
对于时间序列补全问题,本文也分析了传统经验模型、ARMAX(基于ARMA的拓展模型,加入了其他通道的数据)、神经网络(FCNN和LSTM)以及LightGBM模型的效果,实验结果如表1所示。实验使用了过去6年半的历史数据,其中,训练数据为2011年6月到2013年12月间近2年半的数据,需要补全的数据为2014年1月到2018年9月近4年的数据。其中所有数据都已经经过归一化处理。与之前的评价标准相同,在表1中,“/”左侧的数值代表的是MSE,“/”右侧的数值代表的是R2 score。
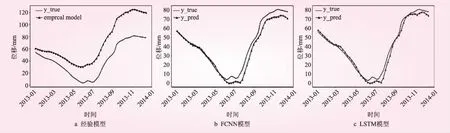
图3 不同模型时序预测结果

表1 某水电站多坝段位移时间序列补全结果
由表1可知,对于补全大范围缺失数据,经验模型并不可靠,在某些坝段上的预测出现了较大的偏差,如A19.X,A25.X。所以经验模型对于这种大范围的时间序列补全问题几乎是不可用的。ARMAX作为经典的时间序列模型,可以综合分析其他通道的数据来对待补全通道数据进行估计,在很多问题上都已经证明了它的性能。但是由于缺失数据的时间段过长,ARMAX模型给出的结果也较差。针对同一问题,以FCNN和LSTM为代表的神经网络模型取得了可以接受的效果,但是结果不如LightGBM稳定。因此,针对大范围数据补全的问题,目前效果最好且精度最高的模型是基于决策树构建的LightGBM模型,其补全效果如图4所示。图中前半部分是已知的训练数据,后半部分橘色线代表的是真实值,蓝色带三角标识的曲线代表的是预测值。实验表明,LightGBM模型可以比较准确地预测后4年数据的变化趋势。
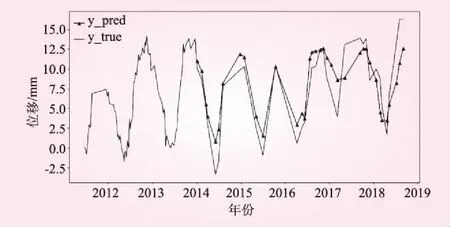
图4 LightGBM模型实验结果
3 结 论
本文采用了以神经网络和决策树为主的机器学习模型来解决水电工程中的大坝安全数据时间序列预测和时间序列补全问题,有利于提升大坝检测数据的质量与完整性,进而促进构建智慧大坝安全评估体系。为了验证模型的有效性,本文根据某水电站的真实数据进行了实验,对比分析了传统经验模型、ARMA模型、与基于机器学习的FCNN模型、LSTM模型和LightGBM模型。根据实验结果可以得出以下结论:
(1)通过FCNN和LSTM模型对大坝安全数据(位移、渗流等)进行短期的预测是可行的。FCNN和LSTM属于神经网络模型,具有较强的表达能力,可以高效学习并拟合不同类型物理量之间的映射关系。因此该模型可以基于易于获得的环境量特征(温度,上下游水位,降水)和待测安全数据本身的历史数据,对未来短期的物理量进行预测,生成可靠的结果。这一方法有助于降低运维成本并提升监测质量。
(2)通过LightGBM模型对大坝安全数据进行长期的时间序列补全是可行的。模型基于学习到的物理量之间的映射关系,结合其他坝段的相同数据作为基础,对长期的缺失数据进行补全。根据本文的实验结果,通过结合高斯过程和LightGBM模型可以取得相对较好的补全结果。
(3)通过本文的实验可知,对于大坝安全数据补全与预测这一传统的问题,采用机器学习模型可以对一些由实际工程出发得出来的经验公式进行补充和完善,获得更好的预测效果。机器学习和专家经验的结合有利于提升模型的效果,对于构建智慧大坝安全评估体系极为重要。
