结合自注意力的对抗性领域适应图像分类方法*
2020-03-04郭卫斌李庆瑜
陈 诚,郭卫斌,李庆瑜
(1.华东理工大学信息科学与工程学院,上海 200237;2.上海网达软件股份有限公司,上海 201206)
1 引言
深度神经网络擅长从大量已标注样本中学习,近年来在计算机视觉、自然语言处理和语音识别等领域取得了令人瞩目的成就。但是,在将已训练模型推广到新的数据集或应用领域时,却会因为数据集之间存在的方差偏移(Covariate Shift)[1]使结果不够理想。同时,获取足够数量的已标注样本通常需要耗费大量的时间和人力成本,有时甚至是无法实现的。如何有效地解决标注样本获取的困难以及使模型能够更好地适应数据集之间的偏移已成为一项富有挑战性的工作。
领域适应[2,3]使用来自目标域的未标注数据提供的辅助训练信息来处理数据集间的偏差。领域适应的目的是使用来自源数据集的知识来适应目标数据集的训练,并将训练得到的模型用于目标域的预测[4]。当源域和目标域的数据集存在偏差或需要将源域训练得到的模型迁移至目标域时,通常的有监督领域适应方法是先对目标域的数据进行标注,然后通过标注后的目标域数据重新训练模型,完成目标域图像到类别标签的映射,但通过领域适应则可以实现跨域映射图像,而不需要目标域图像的类别信息。所以,领域适应是解决数据集间偏差及标注数据获取困难的有效途径,并在近年来得到了迅速发展。基于特征的无监督域自适应方法UDA(Unsupervised Domain Adaptation)[5]不依赖任何已标注的目标样本,通过在源域和目标域之间对齐从网络提取的特征来实现领域适应[6],即在UDA中,只有源域中的数据有类别标签,而目标域的数据是无标签的,因此无法直接通过有监督学习训练目标域的数据,而只能通过无监督领域适应来将源域中的知识迁移到目标域中。而随着神经网络层数的加深,并引入生成对抗网络GAN(Generative Adversarial Nets)[7]中的对抗性思想后,领域适应算法在共享特征的提取和分类精度上更有优势。
传统的图像分类算法通过训练实现图像特征与图像类别标签间的映射,但在UDA中,由于目标域的图像是没有类别标签的,所以无法直接通过图像特征与类别标签的映射完成对图像的分类。为实现UDA中的跨域图像映射,需要分成2个步骤:(1)训练源域图像分类。因为源域图像具有类别标注,所以源域图像分类训练过程和传统图像分类训练相同;(2)完成源域和目标域间的图像适应。第(2)步在不同算法中处理方法各不相同,本文将在第2节继续展开对领域间图像适应的具体理论分析[8]。总体来说,区别于传统图像分类,UDA图像分类的目的在于寻找一种算法能够在提高分类精度的同时又能很好地完成域间的适应,该问题等同于为领域间差异提供一种理论描述,从而能够使用优化算法来实现分类精度和域间差异之间的平衡[9]。从图像分类角度解释,即通过训练使得领域间的差异对于模型而言越来越小时,提高模型的源域图像分类精度的同时也能使得模型更好地分类目标域图像,这也符合直觉上的逻辑[10]。
然而,图像分类中经常采用的卷积神经网络虽然擅长学习具有很少结构特征的图像类,但无法学习到在某些类别中一致出现的几何或结构特征,即由于卷积运算的局部感受域的原因,卷积网络偏向于提取图像局部的纹理特征,但很难学习到图像整体的结构特征。此类问题同样存在于领域适应的特征提取阶段中,使得适应效果局限于局部特征映射之间的转换而不够理想。
本文以UDA的图像分类为例,比较分析GAN中对抗性思想和领域适应的关系,并在算法理论层面类比GAN的改进算法,尝试通过引入自注意力模块对领域适应算法中存在的无法建模长距离依赖的缺陷做出改进,从而进一步优化迁移和图像分类性能。此外,考虑到两者在任务上的差异,尝试通过在自注意力模块中引入新的学习参数来进行完善。实验基于常用的UDA数据集,在无监督适应的图像分类任务上的效果较优,证实了本文方法的可行性和有效性。
2 相关工作
2.1 生成对抗网络
Goodfellow等[7]受博弈论中的二人零和博弈的启发,提出了GAN。GAN中,通过输入的随机噪声z(其中z~pz(z),pz(z)为噪声所属的概率分布),生成器G不断逼近真实数据x的概率分布pdata,判别器D对来自G生成的虚拟数据和来自pdata的真实数据不断辨别数据是否真实,生成器和判别器通过最小最大化游戏达到最终的纳什均衡:
Ez~pz(z)[log(1-D(G(z)))]
(1)
通过第1节中对于UDA图像分类的阐述可以得知,UDA图像分类的本质是如何实现分类精度和域间差异的平衡。而UDA图像分类中的目标域图像映射不断逼近类别标签的目的正好和GAN中的对抗性思想吻合。2.2节正是通过引入对抗性思想来解决UDA的图像分类问题的,这也证实了前文的理论分析。
2.2 对抗性领域适应算法
在领域适应任务中,源域中训练得到的分类器适应目标域数据的分类任务和GAN中生成虚拟数据逼近真实数据分布的概念相吻合。对应地,领域适应中带有参数θf的共享特征提取器为生成器G,判别器D则通过不断更新参数θd来判别数据的来源,结合带有参数θy的分类器C,融合对抗性思想的领域适应算法DANN(Domain-Adversarial Training of Neural Networks)[11]如下所示:
(2)
其中,


其中,xi表示输入样本,yi表示类别标签;di表示领域标签,如果属于源域则为0,如果属于目标域则为1;n和n′分别代表源域和目标域中的样本数;n+n′=N,N为总样本数;λ为权重参数。文献[11]证明,当源域数据与目标域数据之间的分类误差和经验散度达到平衡时,DANN最优。因此,DANN通过迭代不断交替更新:
(3)
(4)


Figure 1 Structure of self-attention module图1 自注意力模块结构图
2.3 自注意力模块
文献[12]指出,由于卷积运算具有局部感受域,浅层卷积模型无法提取长距离的依赖特征,而多个卷积层虽然能够建立图像区域间的长距离依赖特征,但其计算效率很低,并且参数的增加也会降低模型的健壮性。所以,GAN在建立不同图像区域间的长距离依赖时不够理想。另一方面,自注意力[13]在建立远程依赖关系和计算效率之间表现出良好的平衡能力。同时,自注意力模块计算得到所有特征的加权组合,其中的权重参数或称自注意力向量仅增加了较小的计算成本。因此,文献[12]提出了结合自注意力的生成对抗网络SAGAN(Self-Attention Generative Adversarial Networks)来更好地提取包括局部和整体特征映射的混合特征映射。从图像角度解释,即SAGAN通过引入自注意力模块来提取能够反映图像整体空间关系的几何及空间特征映射,同时结合原始的局部特征映射来生成更为真实的图像。经验证,相较于增加卷积核的大小,自注意力模块能够以更低的计算量提取图像的几何特征关系。
文献[12]结合自注意力的思想,构建了自注意力模块,其结构如图1所示。其中,x′表示经过卷积层提取得到的图像特征,f(x′i),g(x′j),h(x′i),v(x′i)表示图像特征经过1×1卷积形成的映射函数,⊗表示矩阵乘法,Softmax运算在每1行上进行,o为自注意力模块最终的输出,N为总样本数。
自注意力模块的表达式如下所示:
(5)
(6)
sij=f(x′i)Tg(x′j)
(7)
其中,sij表示f(x′i)与g(x′j)相乘得到的中间结果,f(x′i),g(x′j),h(x′i),v(x′i)表达式如下所示:
f(x′i)=Wfx′i
g(x′j)=Wgx′j
h(x′i)=Whx′i
v(x′i)=Wvx′i
Wf,Wg,Wh,Wv∈RM×M
其中,M为特征的通道数。γ为可学习参数,初始值为0,意为自注意力模块初始只输出原始的上采样虚拟图像特征xi,之后在学习过程中逐渐加入自注意力图像特征的部分,组成局部和自注意力的混合图像特征,来生成更加逼真的虚拟图像。
然而文献[14]表明,GAN属于生成器一类,即GAN模型的目的是为了使生成器能够生成更加逼真的图像。而在领域适应中,模型的目的则是为了使分类器能够更好地对目标域的数据进行分类,这也是文献[14]将DANN归为判别器一类的原因,即通过判别器判断目标域的数据和源域数据越来越相似时,通过源域数据训练的分类器对目标域数据的分类也将越准确。因此,领域适应的任务和GAN的任务在本质上有所不同。
3 结合自注意力的对抗性领域适应算法
本文在总结概括先前方法的基础上,类比SAGAN对于GAN的改进,尝试通过在DANN中引入自注意力模块来改进DANN建模长距离依赖的能力,并通过改进自注意力模块来使其能够更加适用于领域适应的任务。引入改进的自注意力模块后得到的混合特征映射表达式如式(8)所示:
GF(x;θf;θs;δ;γ)=δGf(x;θf)+
γGs(Gf(x;θf);θs)=δGf(x;θf)+
(8)
为了便于说明,以下出现的(·)表示省略参数。式(8)中,δ为本文引入的新学习参数,初始值为1,其具体作用将在后文分析;θs表示自注意力层参数,即f(·),g(·),h(·),v(·)4个函数中的所有的参数;θf表示特征映射层Gf的参数;GF(·)为局部特征映射和自注意力特征映射组成的混合特征映射,因在原来的特征映射函数Gf(·)的基础上进行了扩展,所以使用GF(·)表示;Gf(·)原为上采样形成的虚拟图像特征,在这里为特征提取器F提取的特征映射;Gs(·)为自注意力函数,因为自注意力被称为Self-Attention,因此以首字母s命名为Gs(·);f(·),g(·)和h(·)的含义同原自注意力模块中的含义。由于自注意力层的引入与SAGAN有所不同,为了便于说明,GF(·)中将γ作为单独的参数。
虽然SAGAN中完全保留xi意在完全保留上采样图像特征,从而能够生成更加逼真的虚拟图像,但在领域适应的任务中局部特征映射Gf(x)不是一定有利于分类的,即对于分类任务而言不需要完全保留,而是可以以一定的权重从中挑选有利于分类的部分,而该权重可以由神经网络自动拟合。本文从自注意力层的引入着手,在原始的自注意力模块的输出层引入1个新的学习参数δ,其初始值为1。类比于SAGAN中引入的γ参数,引入δ意在初始时使用提取的局部特征映射来进行分类和判别,后续逐步使用更加完整的自注意力特征映射来取代一部分局部特征映射。这样设计的原因在于,在领域适应的分类任务中,局部特征映射虽然也有助于分类,但与自注意力特征映射混合并达成动态平衡后,可以进一步提高分类准确率。同时,参数δ的引入能够使得加入自注意力层以后,模型提取的特征数在总体上仍然保持相对稳定,以此增加整体模型的健壮性。本文希望通过引入训练参数δ,使自注意力模块能够针对分类任务,在整体特征映射和局部特征映射之间取得平衡,从而提高在领域适应任务中的准确率。而在计算成本方面,1个训练参数的引入也不会影响自注意力模块的性能。
结合了改进的自注意力模块的DANN的结构如图2所示。图2中,X代表样本集,Y代表类别标签集,DA代表领域标签集。⊗为矩阵乘法,x为输入图像,y为图像标签,d为域标签。F层在原GAN中为生成器,在本文中为特征提取器,S为改进的自注意力模块,C和D含义同DANN中一样,分别为分类器和判别器。因为该模型需要作为推广使用,所以对F,S,C,D4个部分进行了抽象,而不限制具体的实现。引入参数δ之后,S层和F层的输出共同构成了提取的混合特征映射。

Figure 2 DANN structure combined with improved self-attention module图2 结合改进的自注意力模块的DANN结构图
本文算法表达式如下所示:
(9)
(10)

4 数值实验
为了验证和比较算法的可行性和有效性,本文使用公开的数据集进行测试和分析。按照无监督领域适应的要求,所有目标域将均由未标注样本组成,若无特别说明,均使用全部训练集。出于横向比较的考虑,本文采用了多种常用的UDA图像分类数据集,包括数字数据集(MNIST、USPS、SVHN、Synthetic Numbers)、交通标志数据集(Synthetic Signs、GTSRB)以及常见物体数据集(CIFAR-10、STL-10)。其中,数字数据集都为0~9共10个数字。交通标志数据集中则是交通法规中规定的总共43种常用交通标志,如弯道、限速等。最后的常见物体数据集中则是例如飞机、鸟类等共9种常见的交通工具和动物。参照文献[14]对数据集的处理,以颜色通道数为划分依据,将适应任务分为2组,分别为单通道(Gray)和三通道(RGB)适应,共计6个任务:MNIST→USPS,USPS→MNIST,SVHN→MNIST,Synthetic Numbers→SVHN,CIFAR-10→STL-10以及Synthetic Signs→GTSRB,其中前3个为单通道适应任务,其余为三通道适应任务。以下为各数据集具体介绍:
(1)MNIST:领域适应测试中最常用的手写数字数据集,训练集共包含60 000幅图像。在与USPS的适应任务中,按照文献[11]中的训练方法,从训练集中随机抽取20 000幅用作训练,而MNIST与SVHN的领域适应学习任务中则使用全部的训练集。
(2)USPS:与MNIST类似的数字数据集,训练集共包含20 000幅图像。
(3)SVHN:从真实场景中收集并经过简单裁剪处理得到的32×32像素的数字数据集,分类难度较大。训练集中共包含73 257幅图像。
(4)Synthetic Numbers:数字数据集。由于一般训练模型使用的是合成数据,推广到真实场景时不够理想,为了解决这一问题,仿照SVHN创建了该人工数据集。
(5)Synthetic Signs:共包含43个交通标志类别的数据集。与Synthetic Numbers类似,该数据集也是为了推广模型而人工创建的,领域适应的难度较大。
(6)GTSRB:常用于分类的43种大型交通标志数据集,训练集共包含35 000幅像素在15×15~250×250的图像。
(7)CIFAR-10:9种常见交通工具和动物数据集。为进行领域适应任务,参照文献[15]的数据集处理方法,将其中的‘frog’类的样本去除,使其与STL-10[16]近似。
(8)STL-10[16]:与CIFAR-10数据集类似的9种常见交通工具和动物数据集,同CIFAR-10的处理方法,将其中‘monkey’类的样本去除,并按照CIFAR-10中的类标签对STL-10中的样本进行重新标注。
4.1 参数设置
本文提出的结合自注意力模块的领域适应算法基于已有的算法模型DANN,在其基础上引入了自注意力模块,以改进其提取空间几何特征的能力。为了对比的有效性,在参数设置上尽量保持相同。λ仍然保持为λ=2/(1+exp(-10·p))-1,其中p的初始值为0,随着训练迭代逐步增加至1,其目的是在训练的初始阶段加快特征提取器的训练速度,超参数λ仅与模型的收敛速度有关,不影响模型的效果,也可以直接令λ=1。而自注意力模块的参数则和SAGAN的尽量保持相同,γ为学习参数,初始值为0。添加的学习参数δ,初始值为1。数据集方面,单通道的适应任务中,图像尺寸统一调整为28×28像素,并转换为单通道灰度图像。三通道适应任务中,Synthetic Signs→GTSRB的图像尺寸统一调整为40×40像素。Synthetic Numbers→SVHN的图像尺寸统一调整为32×32像素。STL-10按照CIFAR-10中的图像尺寸,调整为32×32像素。
4.2 实验结果及分析
从表1和表2中可以看出,引入了自注意力模块以后,本文方法相较于原始的DANN在分类精度上取得了较大的提升。同时,从三通道分类实验结果中也发现,如果自注意力模块不进行改进而直接引入到DANN中(简称为SA-DANN),分类的精度不是很稳定,可能会出现分类精度下降的现象。对此可能的解释为,自注意力模块加入的同时也增加了模型的参数个数和深度,在完全保留特征映射Gf(x)的情况下,叠加的自注意力映射将会增加分类器的不稳定性。不过从总体上看,自注意力模型的引入对于分类精度的提升还是有效的。这同时也证明了自注意力模型中引入新的学习参数使得局部特征映射和自注意力特征映射之间取得平衡时,分类效果更优。因此,本文对于自注意力模型的改进是可行的。
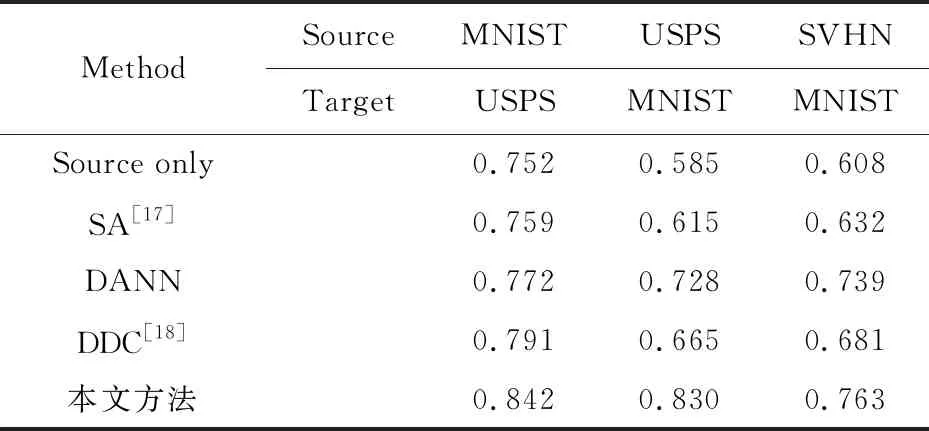
Table 1 Single channel image classification accuracy表1 单通道图像分类准确率

Table 2 Three-channel image classification accuracy表2 三通道图像分类准确率
为了更为直观地展现领域适应的效果,本文将提出的结合自注意力模块的对抗性领域适应方法构建得到的神经网络模型提取的域不变特征通过t-SNE[19]工具进行可视化处理。以USPS→MNIST 为例,从每个域随机采样少量样本。图3和图4显示了第1次领域适应迭代和完成领域适应后样本的变化,其中“+”表示源域,“-”表示目标域。从图4中可以发现,源域和目标域的样本经过领域适应后基本消除了方差偏移,表明本文方法具有优秀的提取域不变特征的能力。

Figure 3 Sample distribution after the first iteration图3 第1次迭代后的样本分布

Figure 4 Sample distribution after domain adaptation has been completed图4 已完成领域适应后的样本分布
5 结束语
本文深入分析了生成对抗网络和领域适应算法的相通性,领域适应中逼近真实数据分布的任务与生成对抗网络生成逼近真实的图像在逻辑处理上基本相同。针对原始GAN中无法建模长距离依赖的不足,本文类比GAN的改进算法,通过引入自注意力模块来对DANN中同样存在的问题进行优化。考虑到GAN算法的任务和领域适应任务虽然类似,但本质有所不同,本文对自注意力模块进行了改进,使其不完全保留提取的局部特征映射,而是在局部特征映射和自注意力特征映射之间取得平衡。改进的自注意力模块能够提高分类任务的准确率,同时不增加自注意力模块的计算成本,更加适用于领域适应任务。实验选用公开的标准领域适应数据集对本文提出的结合注意力模块的对抗性领域适应方法构建的神经网络模型进行测试和评估,通过对比其他算法和可视化提取到的共享特征,展示了方法的可行性和有效性。
