复杂环境下车牌识别算法研究
2020-03-01龙思颖兰良梁杏
龙思颖 兰良 梁杏


摘要:目前市场上已有较多应用成熟、稳定的车牌识别算法,但是大部分需要在单一背景环境下,否则识别效果不佳,所以存在复杂环境下(如光照不均、大角度、多车牌、亮度低等)车牌定位与识别准确率低的问题。文章提出一种复杂环境下多车牌识别算法来应对此问题,采取了SVM模型定位车牌、外部轮廓和外接矩形法分隔字符、BP神经网络法识别字符。其中,对非连续性字符(如中文字符)分隔提出改进算法,取得良好的效果。
关键词:多车牌;车牌识别;倾斜矫正;SVM;神经网络
0 引言
随着生活质量的提高和科技的发展,智能交通应用越来越广泛,车牌识别系统的意义也越来越重要,是智慧交通、智慧城市必不可少的部分。虽然很多成熟的车牌识别算法准确率高达98%以上,应用广泛,但是在低像素图像或复杂环境中识别准确率达不到正常使用的要求。
在许多实际情况中,监控环境比较复杂(比如高速公路、城市道路的监视图像会出现多辆汽车,背景有树木、房屋等),导致现有的单一背景车牌识别算法无法直接应用。因此,本文提出一种复杂环境下多车牌识别算法来应对此问题,其包括车牌定位、字符分割与识别三个主要过程[1]。
1 车牌定位
车牌识别首先需要快速精准地进行车牌定位,从而准确找到车牌所在图像中的具体像素坐标。文中车牌定位首先经过车牌粗定位获取大致像素坐标,再通过车牌精细定位获取准确像素坐标。
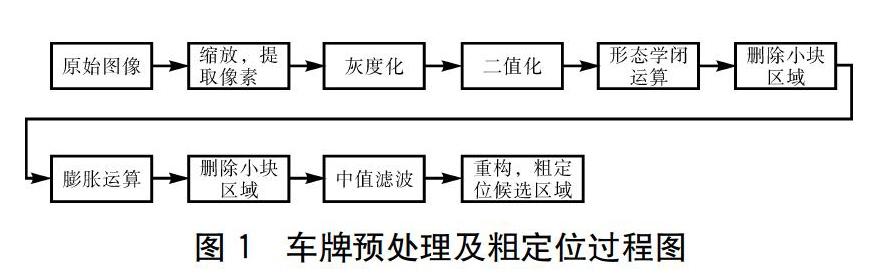
1.1 车牌粗定位
传统的车牌粗定位算法有基于RGB图像颜色处理方法和基于灰度域的纹理特征方法。前者算法对于图像边缘信息、色差不明显情况下定位不准确,同时处理R、G、B三维矩阵运算量大,导致定位运行效率低;而后者算法复杂度高[2][3]。本文提出的车牌定位算法无需每一帧像素参与运算,降低了运算量,提高识别效率,具体过程如图1所示。
[TS)]
(1)获取原始图像(如图2所示),将原始图像缩放成原来的1/3,根据色彩特征提取可能含有车牌的像素点,然后灰度化车牌像素图像,降低存储空间,加快运算速度。(2)将灰度图像二值化,通过形态学闭运算降低噪点,同时删除像素点<2的连通区域,采用矩形算子膨胀运算,并删除像素点<200的连通区域。(3)使用中值滤波降低噪声,将滤波降噪后的图像和原始缩放图像相乘还原车牌RGB图像,获取闭合区域的中心像素坐标,并根据中心像素坐标和车牌宽高比例抠出车牌图像区域,即为粗定位后的输出(如图3所示)。
1.2 车牌精细定位
由于粗定位得到的候选车牌区域可能会有很多,车牌精细定位则是为了突出候选车牌边框,使精细定位后的车牌区域与实际车牌边框一致[4]。选择支持向量机(SupportVectorMachine,SVM)模型算法将粗定位后输出图像依次进行SVM训练,根据训练结果判断候选车牌的正确性,剔除伪车牌,并且生成一个不确定样本提供给SVM模型。SVM模型训练过程如图4所示。
对图3中粗定位的候选车牌依次进行SVM模型训练后获取到精细定位的车牌,如图5所示。可见,图3中的假车牌(d)已经被识别剔除。
2 字符分割
车牌分隔是将精细定位后输出图像中的汉字、字母、数字按原有顺序切割分隔成单个的字符块。中国内地车牌每张分隔成7个字符块[5][6],理想情况下车牌区域经过二值化后按垂直方向投影可准确分割出7个块区域,但实际中车牌会出现不清晰、有污渍、存在断裂字符等,影响垂直投影的准确度。因此文中提出一种改进方法(取外部轮廓+外接矩形)。过程如图6所示。
2.1 倾斜矫正
由于拍摄位置、道路弯道、坡度影响,可能造成车牌水平、垂直、水平垂直倾斜,因此车牌分割预处理中要先进行倾斜矫正。
2.1.1 水平矫正
水平矫正法是使用Sobel算子检测车牌横向边框,再进行Hough变换检测出水平坡度θ,利用极坐标系方程如式(1)[7],把原图像变换到参数空间完成水平矫正。
2.1.2 垂直矫正
由于垂直方向边框长度较短,使用Hough变换进行矫正获取的倾斜角度誤差较大,准确度低,因此使用投影法对垂直方向拉伸矫正。投影法先把车牌图像左边框每一行的首像素投影到垂直方向上,然后按顺序左移剩余像素,将垂直倾斜的平行四边形拉伸变换成矩形。同时投影拉伸变换不会改变车牌原有的字符特征,矫正效果明显。水平、垂直矫正后获取图像如图7所示。
2.2 灰度化及二值化
精细定位后输出的车牌区域仍然是彩色图像,由于字符分割需要使用到灰度化图像,并降低运算量,因此将矫正后的车牌进行灰度化处理。同时,不同车牌颜色(如蓝底白字和黄底黑字等)使用的二值化参数不一样,所以要先判断车牌的颜色。本文选取车牌中间区域判定车牌底色,分别在选定区域查找黄色或蓝色像素点。如果黄色像素占比高于设定的颜色占比预设值,则车牌颜色判断为黄色;同理,如果蓝色像素占比高于设定的颜色占比预设值,则车牌颜色判断为蓝色;反之归为其他颜色车牌。
本文根据判定的颜色选择相应二值化参数进行处理。为了降低车牌边缘和铆钉干扰,选取中间部分区域分别使用Otsu算法、反向二值化法对蓝色车牌、黄色车牌进行处理。
2.3 提取外部轮廓及外接矩形
提取外部轮廓的方法在处理连续字符(如英文字母)时准确率较高,但在处理非连续性文字(如“京”“川”“浙”“苏”等)时会出现分割不准确的问题,因此不能直接使用提取外部轮廓法进行字符分割。本文采取对中文单独处理解决此问题。如车牌“京LZ7793”,“京”字后面的字符“L”表示城市代码,与后续的车牌号有一定的间隔,由特殊符号“·”分隔。
首先在车牌中心横坐标的1/7~2/7之间区域找到间隔字符,就能找到城市代码,提取其外接矩形,记录城市代码外接矩形宽度w与高度h,再向左偏移确定汉字“京”的外接矩形,其矩形高度与h一致,宽度为1.15w。同时,确保汉字外接矩形在车牌边缘内部。同理,从间隔字符依次向右偏移确定剩余字母或数字的外接矩形,并按次序生产7个矩形块。最后,为了避免字符识别中对字符重复性预处理,将分割后的字符图像进行双线性插值处理和归一化缩放成统一规格,并尽可能减少缩放过程中的失真。本文选定归一化后字符图像缩放规格大小为10×10。
3 字符识别
字符识别典型的算法有人工神经网络法、特征匹配法、模板匹配法等[8]。经过对比测试,本文采用BP神经网络法,对复杂环境、模糊、污渍、变形图像等效果良好,其网络结构如图9所示。输入训练集I={(x1,y1),(x2,y2),…,(xn,yn)},xi∈Im,yi∈In,即输入X=x1,x2,…,xm,输出Y=y1,y2,…,yn。
文中使用归一化后10×10字符图像有100个像素块作为特征向量,从10维纵向直方图和横向直方图取到20维特征向量,总计120维特征向量。自动识别输出的7个矩形块的内容,显然输出层需要识别字符类型为31个省份简称、24个英文字母(由于字母I、O和数字1、0具有相似性,因此一般不使用)、10个数字,总计字符类型65种。首先需要给图9中的bj选定合适的节点个数,即选定q的取值。经过无数实验仿真验证,选定bj层的节点个数为40。由于神经网络中输入层节点数目与特征向量纬度相匹配,输出层节点数目与目标识别种类相匹配,最终可以确定输入120个节点,输出65个节点,即:m=120,q=40,n=65。
4 结语
本文阐述了复杂环境中多车牌识别的过程,采取了SVM模型定位车牌、外部轮廓和外接矩形法分隔字符、BP神经网络法识别字符。其中,对非连续性字符(如中文字符)分隔提出改进算法,取得良好的效果。在实验过程中,选取了近万张车牌图像作为SVM模型训练序列,经过大量测试调优统计,文中的车牌识别算法准确率高达98.53%,并且运算简单,对系统或硬件要求不高,适用于复杂道路环境。
参考文献:
[1]郑顾平,闫勃勃,李 刚.基于机器学习的多车牌识别算法应用研究[J].计算机技术与发展,2018(6):129-132.
[2]罗 林.基于视频的车辆细节特征识别方法研究[D].成都:电子科技大学,2016.
[3]梁大宽.复杂背景下多车牌识别算法的研究与软件系统实现[D].太原:太原理工大学,2016.
[4]张变莲,唐慧君,闫旻奇.一种复杂车辆图像中的多车牌定位方法[J].光子学报,2007,36(1):184-186.
[5]HEKaiming,SUNJian,TANGXiaoou.Guidedimagefilte-ring[J].IEEETransactionsonPatternAnalysisandMachineIntelligence,2013,36(6):1397-1409.
[6]X.Yang,Y.Zhao,J.Fang,etal.ALICENSEPLATESEGMENTATIONALGORITHMBASEDONMSERANDTEMPLATEMATCHING[C].ICSP2014ProceedingsonIEEE,2014.
[7]王楠楠.車牌定位及倾斜矫正方法研究[J].工业控制计算机,2014,27(11):25-26.
[8]曾 泉,谭北海.基于SVM和BP神经网络的车牌识别系统[J].电子科技,2016,29(1):98-101.
