智能人脸伪造与检测综述
2020-02-25曹玉红尚志华胡梓珩朱佳琪李宏亮
曹玉红,尚志华,胡梓珩,朱佳琪,李宏亮
工程科学与技术
智能人脸伪造与检测综述
曹玉红1,尚志华2,胡梓珩2,朱佳琪2,李宏亮3
(1. 中国电子学会,北京 100036;2. 中国科学技术大学 信息科学技术学院,合肥 230026;3. 中国科学院大学 工程科学学院,北京 100049)
近年来,智能人脸伪造技术取得了长足的进步,同时也为维护社会安定和保障个人权益带来了巨大的挑战。一个普通人不需要任何专业知识也可以生成逼真的人脸伪造图像和视频,甚至可以随意制作关于公众人物的虚假新闻。为了消除人脸伪造图像和视频产生的社会安全隐患,人脸伪造检测成为了一个备受关注的新兴领域。详细梳理了智能人脸伪造方法和伪造检测方法。智能人脸伪造方法主要基于自编码器和生成对抗网络。根据篡改程度分别介绍了全脸合成、面部身份交换、面部属性修改、面部表情修改这四类人脸伪造方法,并介绍了相应的人脸伪造检测数据集。然后,分别从图像级和视频级两方面介绍了人脸伪造检测方法。为了提高检测精度,主流的人脸伪造检测方法大多基于深度学习并结合生物信息和频域信息等先验知识。之后,汇总并分析了人脸伪造检测方法的效果。最后,结合实际应用讨论了当前方法存在的不足,并对人脸伪造检测的未来发展趋势进行了展望。
人脸篡改;伪造检测;媒体取证;生成对抗网络;自编码器
引言
智能人脸伪造是一类受到广泛关注的技术,此类技术可以轻松地生成一张完整逼真的虚假人脸或修改图像和视频中的人脸图像,可以广泛应用于包括电影制作、电子游戏和虚拟现实等许多领域。然而,智能人脸伪造也带来了许多问题。一些不法分子将该技术应用于色情视频、伪造新闻、金融欺诈等以牟取不法利益。这种现象严重影响了公众权益,威胁了社会安全与稳定[1, 2]。因此,越来越多的研究正致力于有效地检测出伪造的人脸图像和视频。最近发表在国际会议中的工作[3-5]和一些大型竞赛,如媒体取证挑战赛(MFC2018)和深度伪造检测挑战赛(DFDC),展现了社会对于深度伪造检测领域的关注。
事实上,图像篡改检测一直是数字安全领域中一个重要的任务。但是过去生成面部图像的效率和真实性往往受限于编辑工具的缺乏和专业性的要求[6, 7]。如今,随着自编码器(AutoEncoder,AE)和生成对抗网络(Generative Adversarial Networks,GAN)的蓬勃发展,以及海量人脸数据的出现,自动生成一个不存在的人脸或修改一个人的脸部图像变得越来越容易。因此,许多开源软件如Deepfakes[8]、FaceSwap[9],和移动端应用如ZAO[10]、FaceApp[11]应运而生。这些软件使一个没有任何相关领域知识的人也能轻松地生成逼真的伪造人脸图像。这些软件的易用性导致社会稳定和个人权益受到了严重的威胁。基于这些人脸伪造方法,普通人也可以轻松地制作伪造视频,比如某个领导人在从事非法活动的视频或者关于某个公众人物的色情视频等。根据对原始图像修改的程度,主流的人脸伪造方法可以分为以下四类:(1)全脸合成,(2)面部身份交换,(3)面部属性修改,(4)面部表情修改。这些方法最近几年受到了大量关注,被进行了深入的研究。
为了应对日益增多的伪造图像和视频所带来的挑战,许多研究者致力于设计有效的检测伪造图像和视频的方法。传统的伪造检测方法大多基于图像数字指纹。数字指纹主要来自于两方面:(1)在拍摄过程中,拍摄设备的硬件和软件,如镜头[12]、色彩滤镜矩阵(color filter array,CFA)[13]、插值算法[14]和压缩算法[15]等,会引入独特的数字指纹;(2)图像编辑过程,如复制、移动图像中的某些元素、降低帧率等,也会引入额外的数字指纹。然而,传统方法往往针对特定的应用场景,应用于其他场景时效果并不令人满意。这一点对于实际应用是极为重要的,因为当前伪造图像和视频主要存在于社交平台这样一个数据多样性极强的应用场景上。
相比于一般的伪造图像检测,人脸伪造检测聚焦于对合成或篡改的人脸图像进行检测。对于包含人脸的图像或视频,人脸伪造检测方法希望能判断这些人脸是否被人篡改,以此来确保其内容的真实性和安全性。人脸伪造检测任务存在以下难点。1)类内差异大,类间差异小。针对不同人物进行篡改,存在很大差异。此外,同一个人的脸部图像可能是真实的也可能是伪造的,两者差异较小,难以区分。2)伪造方法复杂多样。不同的伪造方法具有其独特的特征。这一特点给人脸伪造检测器的泛化能力带来了巨大的挑战。
为了提高检测效果,现在的研究更多地尝试利用深度神经网络提取最有价值的特征。更具体地说,基于深度神经网络的人脸伪造检测可以分为两类:(1)图像级人脸伪造检测方法,(2)视频级人脸伪造检测方法。其中,图像级人脸伪造检测方法同样适用于伪造视频检测,即通过检测视频帧图像判断整个视频是否为伪造。而视频级人脸伪造检测方法通常利用了时序信息,并不适合检测单幅图像。除此之外,还有一些研究关注了音频与视频内容的不一致性,并以此进行伪造视频检测。
已有一些综述[16, 17]关注了深度人脸伪造与检测领域。这些综述介绍了近期人脸生成算法、主流的人脸篡改检测方法和重要的公开数据集。本文特别针对人脸篡改方法的特点,分为了图像级检测和视频级检测两大类,同时又将每一类根据设计思路细分为了神经网络的改进和特有特征的学习两部分并详细讨论。这种划分方式为读者提供了一种全新的视角来梳理相关内容。
本文首先分别介绍了四种人脸伪造方法及其相应的伪造检测数据集。之后,详细介绍了图像级人脸伪造检测方法,以及视频级人脸伪造检测方法。接下来,本文展示了各个方法取得的效果。最终,分析了现有方法的不足并指出了未来发展的趋势。
1 人脸伪造方法与公开数据集
研究人脸伪造检测方法,首先需要分析人脸伪造的相关技术。4种常见的人脸伪造方法如图1所示,篡改程度从高到低分别为:(1)全脸合成,(2)面部身份交换,(3)面部属性修改,(4)面部表情修改。下文将针对每种伪造类型,提供相关操纵技术,并介绍公开数据集。
1.1 全脸合成
人脸合成一般通过生成对抗网络(Generative Adversarial Networks,GAN)[18]来生成整张不存在的人脸图像,这类方法自GAN被首次提出后便获得了相关研究人员的大量关注[19, 20]。2015年,文献[21]将卷积神经网络(Convolutional Neural Networks,CNN)与GAN结合,提出DCGAN,能够生成房间和人脸图像,为图像生成领域之后的研究打下基础。

图1 人脸伪造图像
目前生成对抗网络在人脸伪造检测中应用较多的是文献[22]中提出的PG-GAN方法。该方法在改进生成器和鉴别器的基础上引入一种新的过程化训练方法,首先训练低分辨率图像生成,再逐步过渡到更高分辨率,最终能够稳定地生成高分辨率人脸。
当前比较流行的全脸合成技术StyleGAN[20]是基于PG-GAN的改进版本。与PG-GAN不同,StyleGAN引入了风格迁移中自适应实例归一化[23]的方法,进行自动学习,将潜在编码进行解耦,从而控制发型、眼睛颜色、雀斑等属性的随机变化。
在最近的工作中,文献[24]提出StyleGAN2对StyleGAN进行了一些修改,包括新设计的规范化、多分辨率和正则化方法。也有一些工作关注于生成特定属性的合成人脸,例如文献[25]将三维先验知识引入对抗学习中,训练网络模拟三维人脸变形和渲染过程的图像生成,同时引入对比学习,提出一种虚拟人物面部图像生成方法,具有解纠缠、精确可控的潜在表示;AFGAN[26]提出一种新的基于GAN的方法,引入双路嵌入层和自注意机制,将二值属性转化为丰富的属性特征,然后以属性为特征,生成特定属性的人脸。
此外,由于现阶段大多数GAN在使用过少的数据集训练时会过拟合,Karras等人[27]提出一种自适应鉴别器增强机制,可以在有限的数据区域内显著稳定训练。
如表1所示,全脸合成方法中有4个值得注意的公共数据集:100K-Generated-Images数据集[28]、100K-Faces数据集[29]、iFakeFaceDB数据集[30]和Diverse Fake Face Dataset(DFFD)数据集[31]。其中100K-Generated-Images数据集使用StyleGAN架构为生成方法,采用FFHQ数据集进行训练,共合成100000张人脸图像;100K-Faces数据集也使用StyleGAN网络生成数据集,但与100K-Generated-Images不同,100K-Faces使用来自69个不同模型的大约29000张图像进行训练,同时考虑了来自更受控场景的面部图像,减少了StyleGAN带来的奇怪伪像;此外,DFFD数据集使用了两种方法生成图像,该数据集共包含300000张人脸,三分之一通过PG-GAN生成,其余通过StyleGAN生成。

表1 全脸合成公开数据集
StyleGAN生成的人脸图像包含了StyleGAN产生的GAN“指纹”,容易被识别。为了降低GAN“指纹”的影响,iFakeFaceDB数据集使用自编码器从GAN原始创建的图像中删除了GAN“指纹”,同时保持图像的视觉质量,生成250000张StyleGAN合成的人脸图像和80000张PG-GAN合成的人脸图像。
1.2 面部身份交换
面部身份交换也称为人脸交换,与全脸合成不同,面部身份交换技术利用已有的视频或图像,将源人物的脸替换为目标人物的脸,从而改变目标视频中主体人物的身份。
面部身份交换方法包括基于经典计算机图形学的FaceSwap方法[9]和被称为DeepFakes的基于深度学习的方法。其中FaceSwap方法首先提取面部区域和关键点坐标,然后利用这些关键点,使用blendshapes拟合3D模板模型,并对模型进行渲染,之后将渲染的模型与图像混合,进行羽化和简单的颜色校正,得到伪造人脸。该算法是轻量级的,可以在CPU上高效运行;DeepFakes方法基于编解码结构进行换脸,有各种不同的实现,其中比较著名的是FakeApp[32]和FaceSwap- Deepfake[8]。这类方法通常先使用人脸检测器,裁剪和对齐脸部图像,进行脸部提取,然后使用经过训练的编码器和解码器进行换脸,换脸后再将替换的脸部区域融合到原图中,得到伪造视频或图像。除了简单的编解码器结构,也有工作使用GAN进行人脸交换,经典方法有FaceSwap- GAN[33],该方法引用CycleGAN[34]的生成网络,并采用多任务级联卷积网络来进行更稳定的人脸检测和对齐[35]。使用GAN的方法可以快速地进行风格转换,但也会带来许多不可控因素,例如肤色和面部特征的不一致。
表2总结了当前面部身份交换的公开数据集和相关信息。其中第一个公开数据集UADFV[36]包含49个来自YouTube的真实视频,之后使用带有后处理的DeepFake方法生成了对应的49个伪造视频。为了减轻利用相似度变换矩阵将假脸仿射到图像中带来的色差伪影,该数据集在换脸过程中生成了一个由左右眉毛和下嘴标志确定的凸多边形掩膜,在将假脸仿射到原始图像时仅保存在掩膜内。此外,为了进一步平滑换脸效果,作者还对掩码的边界应用高斯模糊。UADFV数据集中每个视频只有一个人,分辨率为294×500像素,平均时长11.14秒。
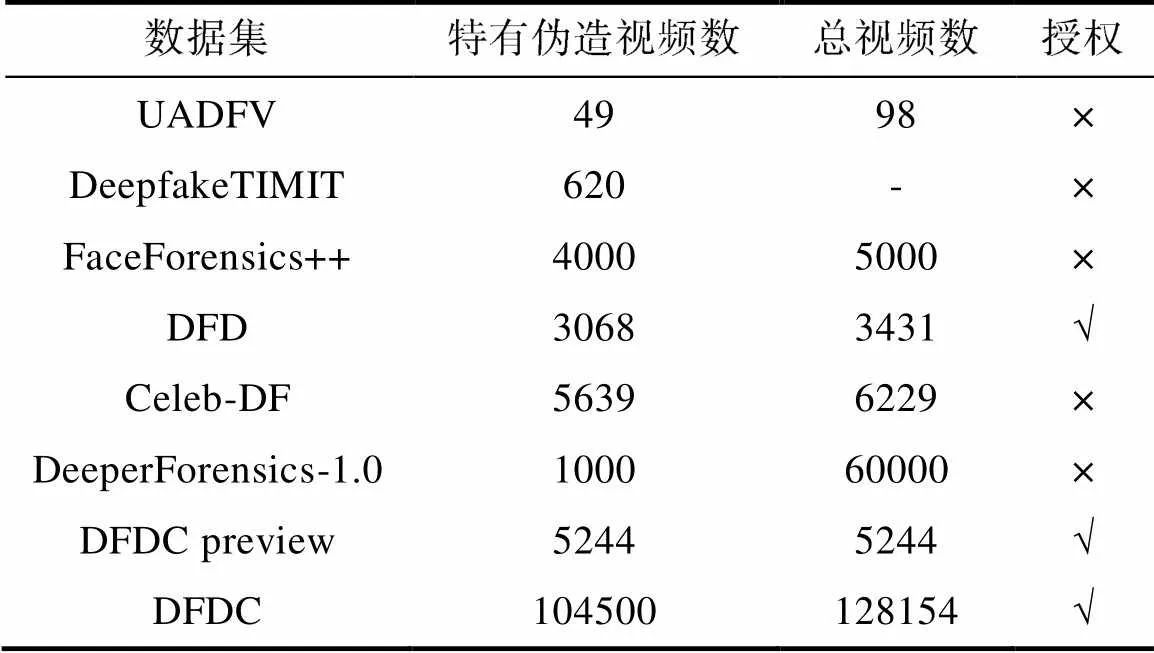
表2 面部身份交换公开数据集
第二个公开数据集是由P.Korshunov等人提出的DeepfakeTIMIT[37],数据集从VidTIMIT数据库[35, 38]中选择16对长相相似的人,通过FaceSwap-GAN方法生成了620个伪造视频,包括64×64像素图像的低质量视频(LQ)和128×128像素图像的高质量视频(HQ)。
第三个公开数据集是由A.Rossler等人于2019年在ICCV上发表的FaceForensics++数据集[39]。该数据集是对面部表情修改数据集FaceForensics[40]的拓展,包含从YouTube上提取的1000个真实视频,然后使用4种方法进行人脸伪造。其中FaceSwap方法和DeepFakes方法属于面部身份交换,各生成1000个伪造视频。在Google的支持下,DFD数据集也被录入,该数据集中包含363个真实视频和对应的3068个伪造视频,所有真实视频来自16个不同场景的28位付费演员。FaceForensics++和DFD数据集都包含了不同级别的视频质量:(1)原始质量RAW,(2)高质量HQ(恒定速率量化参数为23),(3)低质量LQ(恒定速率量化参数为40)。这一方面模拟了社交网络中常使用的视频处理技术。
第四个公开数据集Celeb-DF[41]是Y.Li等人为了提供更好视觉质量的伪造视频而提出的。目前Celeb-DF共由590个真实视频和5639个伪造视频组成,所有视频时长均为30秒。其中原始视频从YouTube公开视频中挑选,包括不同的性别、年龄和种族分布。Celeb-DF使用改进的DeepFake算法,采用更多层且增加维度的编解码器生成高分辨率人脸,同时通过训练数据的增加和后期处理,引入颜色转换算法[39, 42],减少面部颜色不一致等问题。
第五个公开数据集是DeeperForensics-1.0[43],该数据集由包括1760万帧的60000个视频组成,其中有50000个原始收集的视频和10000个经过处理的视频。为了解决以往视频质量不高的问题,数据集考虑在高保真换脸时的通用性和可扩展性,利用DF-VAE方法生成伪造视频。
在2019年12月由Facebook与微软、亚马逊和麻省理工学院等合作发起的深度伪造检测挑战赛(DFDC)中发布了一个预览数据集DFDC preview[44],包括5244个视频,由两种方法生成,所有源视频均来自66个付费演员;最近,在DFDC挑战赛结束后,Facebook发表了完整版DFDC数据集[45],这是目前该领域最大的公开数据集,使用来自3426名付费演员的真实视频,通过多种伪造方法,包括DeepFakes方法、GAN方法和非深度学习方法,生成了10万多个伪造视频。
1.3 面部属性修改
面部属性修改主要编辑面部的某些特征,例如添加眼镜、改变发型以及眼睛的颜色等,目前比较流行的FaceApp移动应用程序就是利用相关方法对人脸属性进行修改。
这类生成方法大多基于自编码器结构或GAN。在文献[46]中,Upchurch等人使用预训练的VGG-19[47]网络设计一种深度特征插值方法(Deep Feature Interpolation,DFI),通过在特征空间中进行线性插值进行属性编辑;Liu等人[48]在Coupled GAN[19]的基础上提出无监督图像翻译框架UNIT,可以在属性域间进行人脸变换;Perarnau 等人[49]介绍了用于图像编辑的可逆条件GAN(IcGAN),由两个独立的编码器和一个条件GAN生成器联合组成[50];Jia等人[51]则针对现有人脸老化工作都需要进行繁琐的数据集预处理问题,在IcGAN的基础上提出没有任何数据预处理的AIGAN,使用最小绝对重构损失来优化年龄向量,进行人脸老化和去龄化。
除此之外,为了使用一个生成器和判别器来学习多个域之间的映射,Y.Choi等人在文献[52]中提出StarGAN,并利用掩码向量方法成功地学习到了数据集间的多个域图像转换。在论文中,作者通过属性分类损失和循环一致性损失训练了条件转移网络,获得了良好的视觉效果,为相关研究做出了很大贡献。
在最近的工作中,InterFaceGAN[53]提出一个新的框架,通过解释GANs学习到的潜在语义来进行人脸编辑,并设法用子空间投影解释一些纠缠语义,从而实现精确的属性控制。
由于大多数属性修改的方法代码都是公开的,在该领域的研究中,往往自己生成数据集。到目前为止,DFFD[31]是该领域仅有的公开数据集,分别通过StarGAN和FaceAPP生成了79960和18416张伪造图像。
1.4 面部表情修改
面部表情修改主要是修改源人物的面部表情。这类技术将视频中一个人的面部表情替换为另一个人的面部表情,目前最流行的有Face2Face技术[54]和NeuralTextures[55]技术。
Face2Face方法是一种基于计算机图形学的方法,它在保持源视频人物身份不变的情况下,将目标视频的表情迁移到源视频,从而伪造源人物的面部动作。Face2Face使用每个视频的前几帧来获取一个人脸的3D模型,并在剩下的帧中跟踪目标视频的表情,然后,将每一帧的目标表情参数传输到源视频,生成伪造视频。
NeuralTextures方法是Thies等人最近提出的方法,该方法利用深度学习技术学习神经纹理。与之前图像到图像翻译的方法不同,NeuralTextures结合渲染网络优化神经纹理,进行神经渲染,以重新计算生成图像,并在实现中使用了基于块的GAN损失[56],能显示出视觉质量更好的结果(尤其是在口腔区域)。
除了Face2Face和NeuralTextures方法进行表情之间的迁移之外,比较常用的还有X2Face[57],该方法通过驱动框架控制,采用密集运动场,通过图像翘曲生成输出视频,使源视频的人物同时模仿目标视频的表情和姿态;与X2Face相似,文献[58]中提出方法使源图像中的人物模仿目标视频中的表情动作,但不需要一个明确的参考姿势,优化更为简单,且生成图像的质量也比X2Face有很大提升。
目前面部表情修改的可用数据集有FaceForensics数据集和FaceForensics++数据集。FaceForensics公开数据集中使用Face2Face来生成伪造表情的视频,数据集中包含来自1004个视频的约50万张人脸。FaceForensics数据集有两个子集组成,第一个数据集包括源视频和目标视频,第二个数据集则是输入视频后由Face2Face生成的视频;FaceForensics++是FaceForensics数据集的拓展版本,对于面部表情修改方面,除了Face2Face生成的数据,还引入NeuralTextures来生成伪造视频,并公开了所有数据。
2 图像级人脸伪造检测
本文将根据各类检测方法的原理和思路对图像级人脸伪造检测进行介绍,而不是根据被检测的人脸合成方法进行分类,希望通过这种方式来展现人脸伪造检测方法中的共同之处,同时也充分展示相近方法之间的差异。图像级人脸伪造检测方法的研究可以分为2类:(1)优化神经网络模型,(2)基于伪造图像特性检测,如特定生物信息和频域信息等。
2.1 优化神经网络模型
与常规分类任务类似,优化神经网络模型可以增强模型学习能力从而提升检测效果。这类方法不依赖于特定的人脸伪造图像特性,而是将大量真实与伪造的人脸图像作为训练数据,训练神经网络模型进行人脸伪造检测。
一种直观的思路是使用在常规图像分类任务上取得不错效果的神经网络模型,即使用真实与伪造人脸图像训练一个二分类器,如文献[59]中使用了VGG19和ResNet50,文献[60]中使用了DenseNet、InceptionNet-v3和XceptionNet。还有一部分工作对神经网络模型进行了优化,如计算图像的互相关矩阵再进行特征提取与分类[61-63],在一般的分类网络外再添加一个提取统计特征并分类的双分支结构[64],提出一种全新的卷积层[65],使用迁移学习[66],使用图像局部切片分别预测最后投票得到总的结果[67]等,并最终取得了效果的提升。
Afchar等人[68]提出了两种包含若干卷积层的关注于图像中观特性的神经网络模型MesoNet:(1)一个包含4层卷积层和1层全连接层的网络(Meso-4);(2)一个包含Inception的变种模块的Meso-4的改进版本,称为MesoInception-4。该方法在一个专有数据集上测试,取得了98.4%的准确率。此外他们将训练好的模型在未见过的数据集Celeb-DF上测试,取得了一定的效果,证明该方法具有一定的鲁棒性。
Nguyen和Yamagishi等人[69]采用一种胶囊网络来检测人脸伪造图像,并提出了一种胶囊间的动态路由算法,如图2所示。实验证明伪造图像和真实图像的胶囊输出有很大不同,该方法在FaceForensic数据集上取得超过MesoNet的结果。
Zhou等人[64]提出了一种双分支网络。该方法融合了两个分支:(1)一个基于GoogLeNet的分类分支,来检测一幅人脸图像是真是假;(2)一个Triplet分支,使用三元损失函数训练学习隐写特征,使用SVM分类。起初该系统用来检测表情篡改,后来Yi等人在文献[65]中测试了它的泛化性能,结果显示该方法是Celeb-DF数据集上最鲁棒的方法之一。
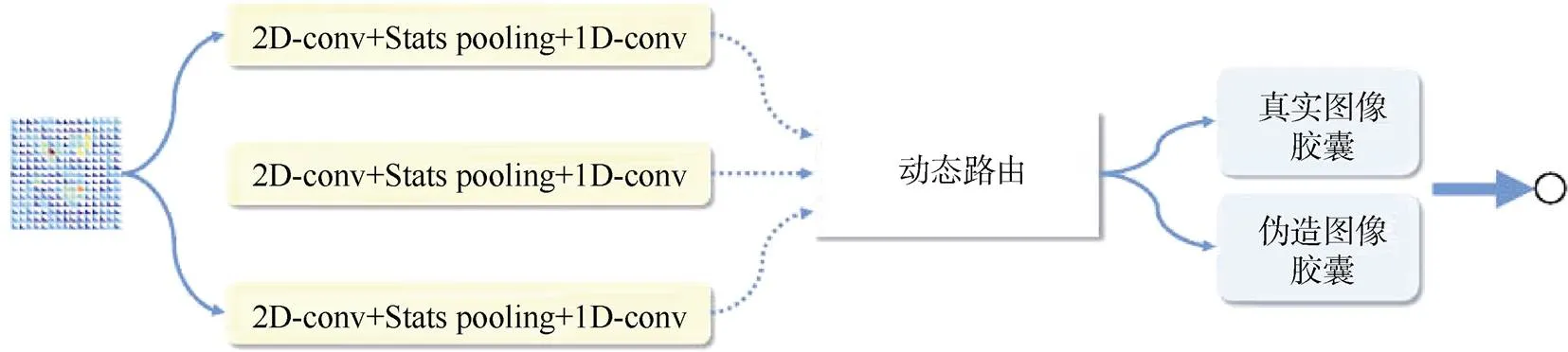
图2 文献[69]采用一种胶囊网络的结果示意图
Rossler等人[39]使用FaceForensics++数据集对不同的虚假检测方法进行了详尽的分析,测试了五种不同的检测方法:(1)一个使用手工特征训练的CNN方法[70];(2)一个带有抑制高层内容的卷积层的CNN方法[65];(3)一个带有计算四种统计量(均值、方差、最大值和最小值)的全局池化层的CNN方法[71];(4)MesoInception-4[68];(5)基于XceptionNet的方法,在ImageNet上预训练。总的来说,基于XceptionNet的方法在DeepFakes和FaceSwap类型的伪造视频上取得了最好的结果[72]。此外,为了模拟视频在社交网络中传输造成的画质下降,该文在不同视频质量上对各种检测方法进行评价。当画质下降时,所有检测系统的准确率都产生下降,这也显示出真实情景下伪造视频检测任务的挑战性。
在之后的研究中,注意力机制被用来进一步提升伪造图像的检测能力。Dang等人[31]对不同的人脸篡改进行了详尽的分析。该文提出了一种实现简单并可嵌入现有主干网络中的注意力机制,来改进分类模型的特征图。该方法在DFD数据集上测试取得了99.43%的AUC和3.1%的EER。
Marra等人[73]进行了一项有趣的研究来检测未见类型的伪造视频:一个多任务渐进学习检测方法用于检测和分类新类型的GAN合成图像,同时保持对已训练类型的检测能力不会下降。该文提出了两种基于iCaRL算法但分类器不同的方案:(1)多任务多分类器(MultiTask- MultiClassifiers,MT-MC);(2 )多任务单分类器(MultiTask-SingleClassifier,MT-SC)。对于实验数据,该文使用了五种不同的GAN结构(CycleGAN,PG-GAN,Glow,StarGAN和StyleGAN)。该文采用基于XceptionNet的模型,取得了很好的效果,能够正确检测不同类型的GAN生成的伪造图像。
上述方法将人脸伪造检测看作是一个二分类问题,只输出一个分类结果。此外,一些研究希望对伪造区域进行定位[74]。
Li等人[5]观察到人脸伪造图像制作过程中普遍存在将脸部区域融合到原图的步骤,而融合边界的两侧存在不一致性,因此提出了一种全新的图像表示方法Face X-ray。该方法创新地提出融合两幅真实图像来生成伪造图像作为额外训练数据并训练模型预测伪造图像中的融合边界。该方法在FaceForensic++数据集上取得了优异的结果,并且对于不在训练集中的伪造方法有很强的泛化能力。但是该方法依赖于融合步骤的存在,对于没有脸部融合操作的整张伪造图像,该方法就会失效。
Songsri-in和Zafeiriou[75]提出了一个既能分类、又能定位的DCNN模型。该模型包含一个编码器,将输入图像映射到隐藏特征空间。输出部分为两个分支:类别预测分支和掩膜预测分支,分别输出图像的分类和伪造区域的分割定位。
Nguyen和Fang等人[76]也提出了分类并同时定位伪造区域的方法。如图3所示,与常规自编码器结构不同的是,该方法的解码器为Y型,包含两个输出分支。编码器的输出特征用来分类,解码器的一个分支用来分割伪造区域,另一分支用来重建输入图像。为了提升模型的泛化性能,该方法采用半监督学习方法。

图3 文献[76]提出的多任务检测器的示意图
Cozzolino等人[77]提出了ForensicTransfer,采用域适应的方法提升泛化性能。该方法采用一种全新的自编码器结构,在训练时使原域中的真实和伪造图像在隐藏表达空间中进一步分开,然后使用少量目标域中的样本使模型适应目标域。
Du等人[78]提出了一种结合局部性学习和局部性增强的统一的局部自编码器框架(locality- aware autoencoder,LAE)。LAE的核心思想是模型应该关注正确的区域并利用合理的证据,而不是捕捉数据集中的偏差来进行预测。由于纯数据驱动的训练模式,一般的自编码器不能保证集中在伪造区域进行预测。LAE通过增加模型的局部可解释性和在额外的监督下正则化解释,使模型依赖伪造区域来进行检测预测。此外,该文还设计了一个主动学习框架来选择有挑战性的候选者进行归一化学习。
2.2 基于伪造图像特性检测
区别于常规的分类任务,人脸伪造图像检测有其独特的特点:类别间视觉内容高度相似。因此,许多工作关注人脸伪造图像的一些特性作为检测依据。第一类特性是生物信息特性。人脸伪造图像中往往会破坏一些真实人脸图像中所包含生物信息,如头部姿态不一致等。第二类特性是频域信息。真实图像和伪造图像都包含其独特的高频信息。这些特殊的高频信息一般来自于真实图像的处理过程或者伪造图像的合成过程。除了这两类之外,人脸伪造图像还有一些其他特性,如图像颜色、神经网络的响应等。
2.2.1 基于生物信息的伪造检测
Matern等人[79]提出了基于相对简单的视觉痕迹(如眼睛的颜色,缺少反射,眼部与牙齿缺少细节等)的伪造检测系统。该系统分别尝试了两种分类器:(1)logistic回归模型;(2)多层感知机模型。该方法在一个专有数据集上测试,其中多层感知机模型取得了85.1% AUC的最佳结果。
Yang等人[80]提出了一种基于面部表情和头部运动的检测系统。他们观察到伪造视频是由伪造的脸部区域融合到原视频帧中生成的,这种操作导致了伪造视频中人物头部姿态与真实不同,可以使用三维头部姿态估计来发现。因此,他们采用DLIB提取的人脸全部68个关键点进行头部姿态估计的研究,来区分伪造与真实视频。在提取到这些特征并均值和标准差归一化之后,使用支持向量机(Support Vector Machine,SVM)进行最后的分类。该方法最初使用UADFV数据集进行评价,取得了89.0%的Area Under Curve(AUC)。但是,在UADFV上训练好的模型,在其他数据集上的泛化性不是很好。
2.2.2 基于频域信息的伪造检测
Rathgeb等人[81]提出了一种基于光响应非均匀性(Photo Response Non-Uniformity,PRNU)的检测系统。具体地说,该系统融合从跨图像细胞PRNU模式提取的空间特征和频谱特征分析得到的分数。该方法在一个专有数据集上进行了测试,该数据集包含使用5种不同的程序创建的伪造图像,取得了平均13.7%的等错误率(Equal Error Rate,EER)。
Zhang等人[82]提出了一种基于频域提取的特征而不是原始图像像素的检测系统。给定一幅图像作为输入,该系统对每个RGB通道进行二维离散傅里叶变换(Discrete Fourier Transform,DFT),每个通道得到一个频率图像。在分类器方面,他们提出了AutoGAN,这是一种GAN模拟器,可以在不需要访问任何预训练GAN模型的情况下合成GAN伪造图像。作者使用未见过的GAN模型测试了他们提出的方法的泛化能力。该文在测试中考虑了StarGAN[52]和GauGAN[56]两种伪造方法。对于StarGAN方法,该系统可以获得良好的检测结果(100%)。然而,对于GauGAN方法,该系统的性能会产生一个很大的退化,只有50%的准确率。这是由于GauGAN的生成器与用于训练的CycleGAN有很大不同。
Qian等人[4]认为频率提供了一个互补的视角,能够描述细微的伪造痕迹或压缩错误。如图4所示,该文提出了一种全新的利用频域的人脸篡改检测网络,名为F3-Net。该方法利用两种不同但互为补充的频域信息,采用离散余弦变换(Discrete Cosine Transform, DCT)进行频域变换。该方法在FaceForensic++数据集上取得了最先进的效果,尤其是在低画质视频上取得巨大提升。
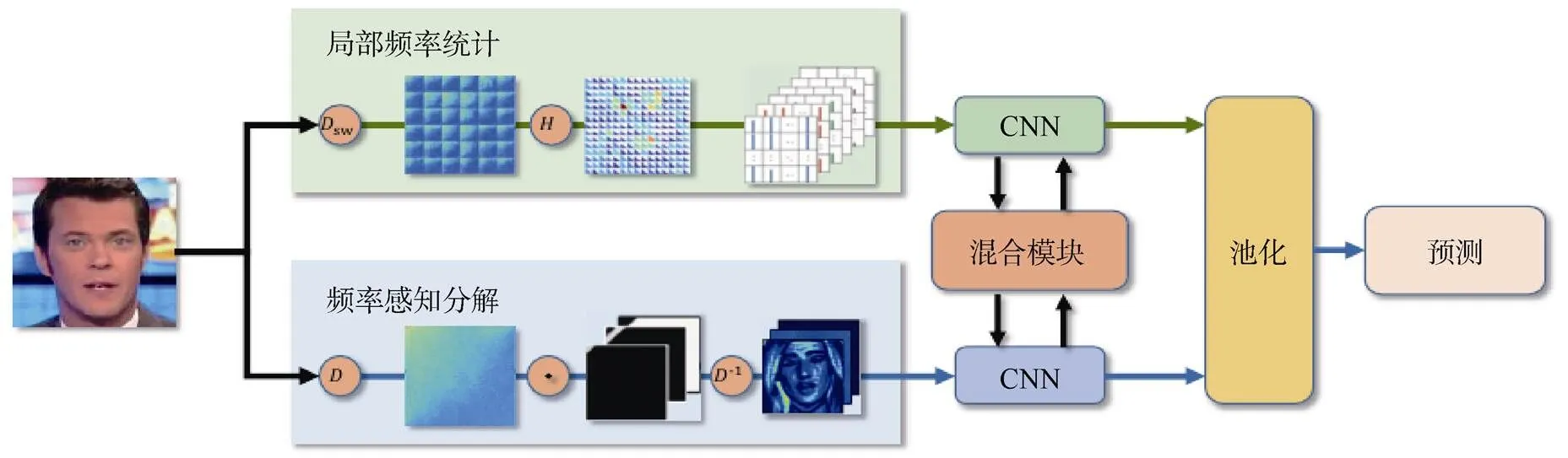
图4 文献[4]提出的利用频域信息的检测方法示意图
Chen和Yang[83]提出了一种频域与空间域结合的伪造人脸检测器。该方法认为篡改图像在频域中具有比真实图像更多的高频分量,在基频的各个边缘具有额外的频带。基于此,该方法对人脸图像进行离散傅里叶变换,得到频域特征,将输入图像划分为背景、脸部、眼部、嘴部、鼻子五部分。此外,设计了一种注意力层,对原图、五个划分区域以及频域特征分别处理,最后分别送入预训练好的VGG-19网络中进行分类,对七个结果进行融合得到最终分类。
2.2.3 其他检测方法
一些研究提出分析篡改的过程来检测真实与伪造图像间的不同痕迹。McCloskey等人假设真实拍摄的图像与伪造合成图像的颜色有明显的不同。他们提出了一个基于颜色特征的检测系统和一个SVM进行最后的分类,取得了NIST MFC2018数据集上的最佳结果(70.0% AUC)。Li等人[84]分析伪造图像和真实图像颜色分量的不同来进行检测。
Wang等人[85]观察到通过监测神经元的行为可以检测伪造脸部,因为一层接着一层的神经元激活模式也许能够反映出对篡改人脸检测重要的微小的特征。他们提出的这种方法被命名为FakeSpotter,从深度人脸识别系统(如VGG-Face、OpenFace、FaceNet)提取真实脸部和虚假脸部的神经元收敛行为作为特征,然后训练一个SVM作为分类器。作者使用CelebA-HQ和FFHQ中的真实人脸,加上InterFaceGAN和StyleGAN的伪造人脸进行测试,在FaceNet模型上取得了准确率84.7%的最佳结果。
Guarnera等人[86]提出了基于分析卷积的迹(traces)的伪造检测系统。特征由期望最大化算法提取,使用流行的分类器(KNN、SVM、LDA)进行最终的检测。该方法使用AttGAN、GDWCT、StarGAN、StyleGAN和StyleGAN2生成的伪造图像进行测试,取得了准确率99.81%的最佳结果。
Liu等人[87]认为伪造人脸图像的纹理与真实人脸非常不同并且全局的纹理统计对不同伪造类型更鲁棒。基于这两点,该文提出一个名为Gram-Net的全新检测结构,利用全局图像纹理表达来进行鲁棒的伪造图像检测。
3 视频级人脸伪造检测
尽管大多数图像级人脸伪造检测方法都可以快速地应用于人脸伪造视频的检测,但是这些方法无法有效地利用视频中的时序信息。因此一些研究进一步尝试利用时序信息进行视频级人脸伪造检测[88]。
3.1 神经网络的改进
与图像级人脸伪造检测方法类似,一些工作根据其他视频分类任务的经验,如动作识别,构建适当的网络结构提取视频特征并进行分类。
视频级人脸伪造检测方法不仅考虑了图像级的特征,也进一步考虑了视频的时序特征。Guera和Delp[85]提出了一个基于视频帧间时域关系的人脸伪造检测虚假方法。他们采用了CNN提取单帧图像中的视觉特征并使用循环神经网络(Recurrent Neural Network,RNN)融合多帧图像的视觉特征。对于CNN,作者采用了当时优秀的骨干网络InceptionNet-v3用于提取特征。CNN直接使用了在ImageNet预训练的参数而并没有额外的训练。对于RNN,作者采用一个隐藏层具有2048记忆单元的长短期记忆模型(Long Short-Term Memory,LSTM)[89]融合多帧信息并获取视频级特征。最后两层全连接层分类获取的视频级特征,给出整个视频被伪造的概率。该方法在一个专用数据集上测试取得了97.1%的分类准确度。
Sabir等人采用类似的思路[90]提出利用帧间的时域不一致性进行人脸伪造视频检测并设计了一个基于时域信息的方法(图5)。因此,他们利用了一个类似于文献[91]的RNN。该方法将帧序列输入模型之前先进行了预处理。在预处理过程中,人脸图像被定位、裁剪和对齐,以帮助模型聚焦于最重要的区域。该方法在FF++上测试,其中低画质的DeepFake和FaceSwap分别取得了96.9%和96.3%的AUC。
不同于CNN和RNN组合的结构,文献[3]为了有效利用空间和动态信息,提出了基于成熟的三维卷积神经网络(3DCNN)模型的检测方法,包括I3D[87]和3D ResNet[92],在低画质FF++上取得了不错的效果。
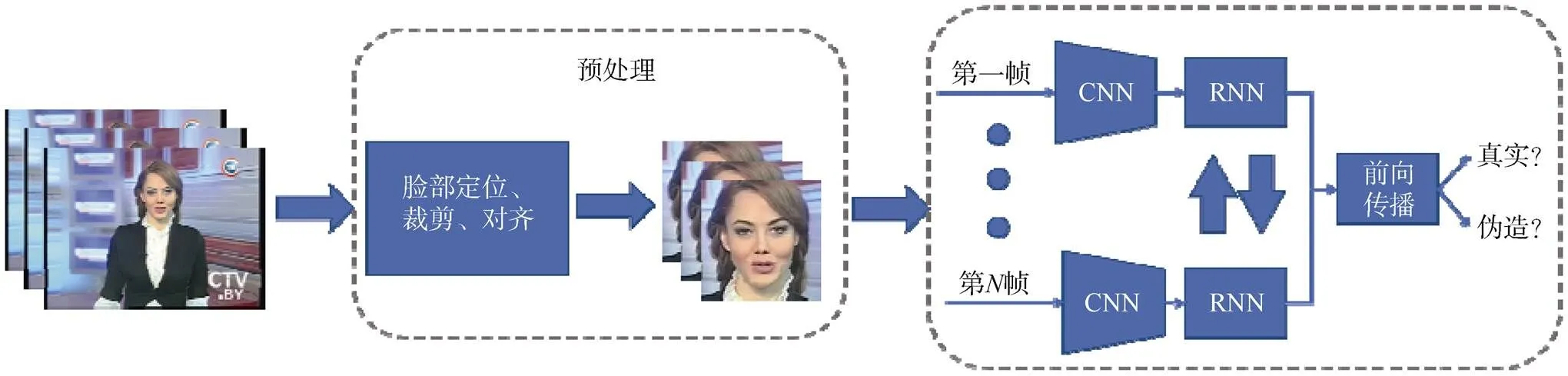
图5 文献[90]提出的基于CNN和RNN的人脸伪造视频检测方法示意图
文献[43]也在它所提出的数据集DeeperForensics-1.0上比较了多种方法在视频级人脸伪造检测上的效果[93],包括图像级方法XceptionNet[71]、视频级方法ResNet+LSTM[89, 94]、C3D[95]、TSN[96]、I3D[92]。实验结果显示视频级检测方法更有优势,但优势并不明显。
3.2 基于伪造视频特性的检测
人脸伪造视频中往往会丢失一些细节信息,尤其是人物的生理特性,如心跳、眨眼、口型等。因此一些工作尝试挖掘这些容易被忽略却十分重要的信息,作为人脸伪造检测的重要证据。
Agarwal和Farid[74]提出了一种基于面部表情和头部运动的检测系统。他们采用OpenFace2[94]工具获得与面部肌肉运动有关的18个不同面部动作单元的强度和发生率,如抬面颊、鼻子皱纹、嘴伸展等,并将此作为检测的重要特征。此外,考虑了头部运动有关的其他四个特征。最终,对于每十秒的视频片段,作者使用皮尔森相关性(Pearson correlation)来度量特征向量间的线性关系以确定一个人的运动特征,并最终得到一个190维特征向量。最后,作者采用SVM对190维的特征进行分类以检测伪造视频。在实验中,作者基于YouTube上下载的视频建立了自己的数据集。在其中大部分视频中,主角是面对摄像头的。为了生成伪造视频,作者使用faceswap-GAN[33]对每人训练一个GAN模型。在这个数据集中,该方法取得了96.3%的AUC的成绩,并且对新的篡改技术有一定鲁棒性。
视频中人物眨眼的特征也被研究用于检测伪造视频。在文献[95]中,作者提出了DeepVision算法用于眨眼模式的变化。该算法使用Fast- HyperFace[96]检测人脸并使用Eye-Aspect-Ratio[97]的获取眨眼频率。最终,该方法基于眨眼次数和周期的特征决定输入视频是真是假。该方法在一个专有数据集上取得了87.5%的分类准确率。
远程光电体积描记术(remote visual photoplethysmography, rPPG)可以监控由心跳和血液流动而产生的肤色变化规律,因此,DeepRhythm[98]算法通过观察人脸肤色变化规律检测伪造视频。作者提出运动放大时空表示(motion-magnified spatial-temporal representation,MMSTR),用于有效地描述脸部图像中肤色的变化。该算法在FF++和DFDC-preview数据集分别取得了很好的效果,并且对于图像质量衰减有一定鲁棒性。
与伪造图像检测类似,伪造视频的频域信息也是一种重要的伪造检测证据。文献[99]提出了一种双分支的网络结构用于检测伪造视频。一个分支用于传播原始的视觉信息,另一个分支使用高斯拉普拉斯算子(Laplacian of Gaussian,LoG)调整多频带信息并抑制高级视觉语义信息。之后视觉特征被输入双向长短期记忆网络(bi- directional LSTM)以利用视频时序信息。该算法在FaceForensics++、Celeb-DF和DFDC preview数据集上取得了优秀的效果。
除了仅仅使用视觉特征,Korshunov和Marcel[37]关注音频-视觉痕迹在伪造视频检测中的应用。他们提出了一种基于伪造视频中嘴唇运动和音频不一致性的检测方法,他们采用梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)提取音频特征和嘴部相对于基准的距离作为视觉特征,并使用主成分分析(Principal Component Analysis,PCA)减少特征块的维度,最终使用LSTM来检测伪造视频。此外,他们还评价了几种常用的基于图像的系统的几种变体。
他们发现基于唇音一致性的方法并不能很好地检测出伪造视频。相对地,他们使用图像质量度量(image quality measures)作为视觉特征。该特征使用了129中图像特征度量(如信噪比,反射特性,模糊度等)。最终,作者使用SVM分类视觉特征,并在DeepfakeTIMIT数据集的低质量和和高质量视频上分别取得了3.3%和8.9%的EER。
4 实验分析
本文在表3和表4中分别汇总了上述图像级伪造检测方法和视频级伪造检测方法的实验结果。因为伪造人脸方法多种多样并且检测方法利用的信息不同,所以许多方法的实验使用了不同的数据集。此外,不同检测方法的评价指标也有差异,如分类准确度(Acc.)、ROC曲线下与坐标轴围成的面积(AUC)、错误率(ERR)等。因此难以直接比较各方法之间的优劣。但实验结果仍然可以展现一些规律。第一,近年来,基于深度学习的人脸伪造检测方法性能相比于传统的检测方法有所提升。事实上,正如前文所说,改进网络结构是一种有效的提升检测效果的途径。因此本文认为使用拥有更强学习能力的深度网络结构可以有效地提升检测效果。第二,利用伪造图像或视频特性进行检测一直是该领域研究的重要方向。而这一研究方向在基于深度学习的方法中也得以保留并取得了优异的效果。最近的一些取得最优效果的方法中也利用了这些特性,如频域信息和生物信息。这说明先验知识对于人脸伪造检测有着重要意义。更全面深入的人脸伪造图像和视频分析并充分利用相关特性将有益于人脸伪造检测效果。第三,相对于图像级伪造检测,视频级的检测方法往往能取得更好的效果。因为视频级的检测方法不仅提取了多幅图像中的视觉信息(帧内信息),也利用了这些视觉信息的时序关系等(帧间信息)。同时,在实际应用中,伪造视频所产生的威胁也大于伪造图像的威胁,因此进一步探索视频级的检测方法十分重要。

表3 图像级别检测方法结果对比
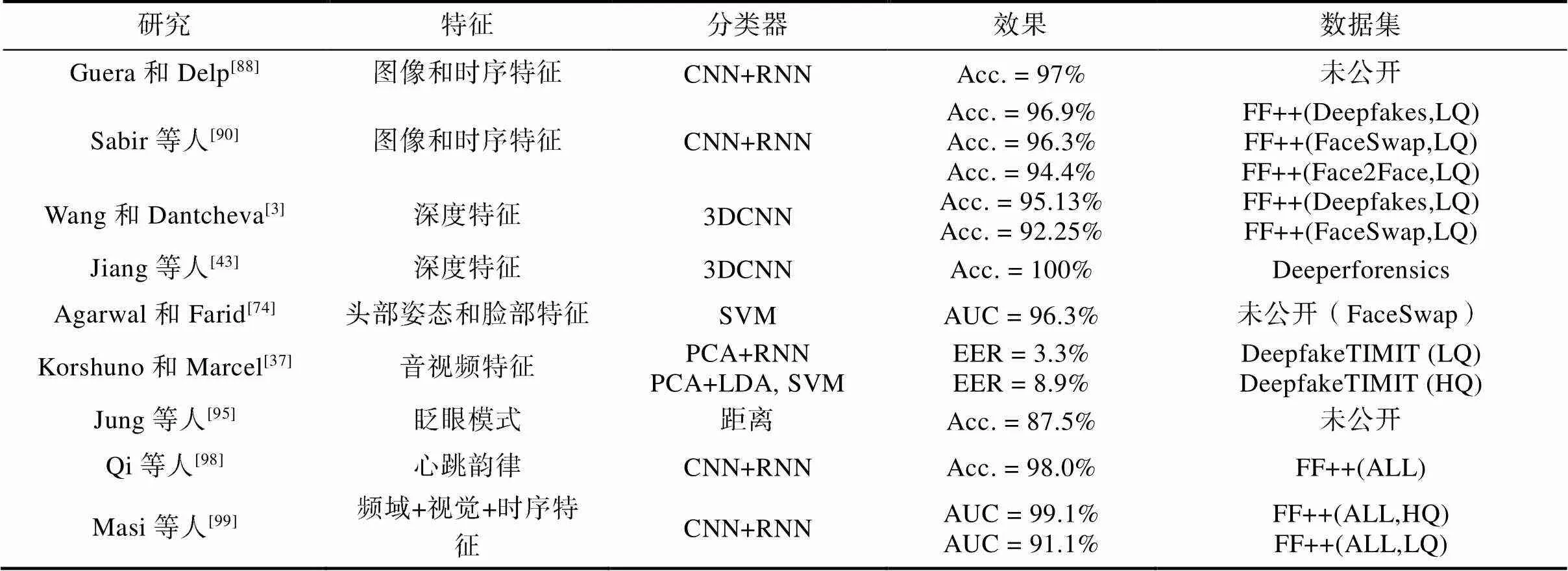
表4 视频级别检测方法结果对比
5 总结与展望
近年来,智能人脸伪造方法取得了很大进展。相应地,人脸伪造检测研究吸引了广泛关注并取得了不错的效果。本文对人脸伪造方法和人脸伪造检测方法进行了广泛的调研。根据人脸伪造方法的类型:(1)全脸合成,(2)面部身份交换,(3)面部属性修改,(4)面部表情修改,对其进行了介绍并汇总了相关人脸伪造检测数据集。同时,从图像级和视频级两个方面介绍了人脸伪造检测领域近期的主要研究方向,讨论了相关的研究成果。
区别于一般的分类任务,人脸伪造检测任务中的正负例差异较小,语义信息极为相似。一般认为人脸伪造检测方法往往依靠一些噪声级别的差异,如GAN生成图像中的数字指纹等,进行分类。因此,人类对于人脸伪造检测的一些先验知识在该领域中更为重要,包括频域信息和生物信息等。然而,存在以下两个问题。(1)人脸伪造检测的证据难以确定。不同的方法往往会利用不同伪造证据。而这些证据间的关系并没有被清楚的研究。(2)人脸伪造算法也在不断改进,基于人类的先验知识,伪造算法也可以进一步优化自身以消除伪造痕迹。此时人脸伪造检测器或许会失效。因此,如何利用这些先验知识,无论是对于人脸伪造方法还是人脸伪造检测方法,都是一个重要的课题。
此外,当前的人脸伪造检测方法主要基于视觉特征进行判断。然而一些基于更多信息的方法应该被探索以获得性能更高、更鲁棒的伪造检测器。例如文献[37]中利用了语音信息进行辅助判断,尽管效果并不是很理想但仍是一种积极的探索。另一个例子是文献[100]中,作者提出在拍摄时使用群体验证:使用多个摄像机同步地拍摄演讲者。这些尝试利用更丰富的信息来应对人脸伪造图像和视频的工作提供了很新颖的研究思路。
当应用环境中数据分布与训练数据分布相似时,人脸伪造检测器可以取得非常高的准确率,因此人脸伪造在一定程度下是受控的。然而,因为在社交媒体上,即人脸伪造视频主要存在的环境中,视频的质量,如压缩级别、分辨率和噪声等十分多样,同时人脸伪造方法也在不断改进,所以人脸伪造检测器往往需要应对从未见过的数据分布。不幸的是,如深度伪造检测挑战赛(Deepfake detection challenge, DFDC)[42]所说,缺乏泛化能力是大多数人脸伪造检测器的共同缺点。一些研究[5]已经努力提升检测器的泛化能力,然而这些方法的效果并不能满足应用的需求。因此,提升人脸检测器的泛化能力对其实际应用有着重要的意义。
[1] 刘益东. 科技重大风险与人类安全危机:前所未有的双重挑战及其治理对策[J]. 工程研究——跨学科视野中的工程. 2020, 12(4): 321-336.
[2] 王彦雨. 人工智能风险研究:一个亟待开拓的研究场域. 工程研究——跨学科视野中的工程. 2020, 12(4): 366-379.
[3] Wang Y, Dantcheva A. A video is worth more than 1000 lies[C]// Comparing 3DCNN approaches for detecting deepfakes. IEEE International Conference on Automatic Face and Gesture Recognition, Buenos Aires: IEEE, 2020.
[4] Qian Y, Yin G, Sheng L, et al. Thinking in frequency: Face forgery detection by mining frequency-aware clues[C]. Proceedings of the 16th European Conference on Computer Vision. Glasgow: Springer, 2020: 86-103.
[5] Li L, Bao J, Zhang T, et al. Face x-ray for more general face forgery detection[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 5000-5009.
[6] Heo J, Savvides M. Gender and ethnicity specific generic elastic models from a single 2D image for novel 2D pose face synthesis and recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2011, 34(12): 2341-2350.
[7] Garrido P, Valgaerts L, Rehmsen O, et al. Automatic face reenactment[C]. Columbus: IEEE conference on computer vision and pattern recognition. 2014: 4217-4224.
[8] Deepfakes[EB/OL]. https://github.com/deepfakes/faceswap.
[9] Faceswap[EB/OL]. https://github.com/MarekKowalski/ FaceSwap.
[10] ZAO[EB/OL]. https://apps.apple.com/cn/app/id1465199 127.
[11] Faceapp[EB/OL]. https://faceapp.com/app.
[12] Yerushalmy I, Hel-Or H. Digital image forgery detection based on lens and sensor aberration[J]. International journal of computer vision, 2011, 92(1): 71-91.
[13] Popescu A C, Farid H. Exposing digital forgeries in color filter array interpolated images[J]. IEEE Transactions on Signal Processing, 2005, 53(10): 3948-3959.
[14] Cao H, Kot A C. Accurate detection of demosaicing regularity for digital image forensics[J]. IEEE Transactions on Information Forensics and Security, 2009, 4(4): 899-910.
[15] Lin Z, He J, Tang X, et al. Fast, automatic and fine- grained tampered JPEG image detection via DCT coefficient analysis[J]. Pattern Recognition, 2009, 42(11): 2492-2501.
[16] Mirsky Y, Lee W. The Creation and Detection of Deepfakes: A Survey[J]. arXiv preprint arXiv:2004.11138, 2020.
[17] Verdoliva L. Media forensics and deepfakes: an overview[J]. arXiv preprint arXiv:2001.06564, 2020.
[18] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[J]. Advances in neural information processing systems, 2014: 2672-2680.
[19] Liu M Y and Tuzel O. Coupled generative adversarial networks[C]. Advances in neural information processing systems, 2016: 469-477.
[20] Karras T, Laine S, Aila T. A style-based generator architecture for generative adversarial networks[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2019: 4401-4410.
[21] Radford A, Metz L, Chintala S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks[R]. ICLR, 2016.
[22] Karras T, Aila T, Laine S, et al. Progressive growing of gans for improved quality, stability, and variation[EB/OL]. [2020-10-18]. https://arxiv.org/pdf/1710.10196.pdf.
[23] Huang X, Belongie S. Arbitrary style transfer in real-time with adaptive instance normalization[C]. Proceedings of the IEEE International Conference on Computer Vision. 2017: 1501-1510.
[24] Karras T, Laine S, Aittala M, et al. Analyzing and improving the image quality of stylegan[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 8110-8119.
[25] Deng Y, Yang J, Chen D, et al. Disentangled and Controllable Face Image Generation via 3D Imitative-Contrastive Learning[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 5154-5163.
[26] Yuan Z, Zhang J, Shan S, et al. 2020 25th Attributes Aware Face Generation with Generative Adversarial Networks[C]. 2020 International Conference on Pattern Recognition (ICPR).
[27] Karras T, Aittala M, Hellsten J, et al. Training generative adversarial networks with limited data[J]. Advances in Neural Information Processing Systems, 2020, 33.
[28] 100K-Generated-Images. (2018) [EB/OL]. https://github. com/NVlabs/stylegan.
[29] 100,000 Faces Generated by AI, (2018)[EB/OL]. https: //generated.photos/.
[30] Neves J C, Tolosana R, Vera-Rodriguez R, et al. Ganprintr: Improved fakes and evaluation of the state of the art in face manipulation detection[J]. IEEE Journal of Selected Topics in Signal Processing, 2020, 14(5): 1038-1048.
[31] Stehouwer J, Dang H, Liu F, et al. On the detection of digital face manipulation[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020: 5780-5789.
[32] FakeAPP [EB/OL]. https://www.malavida.com/en/soft/ fakeap/.
[33] Faceswapgan[EB/OL]. https://github.com/shaoanlu/faceswap GAN/.
[34] Zhu J Y, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]. Proceedings of the IEEE International Conference on Computer Vision, 2017: 2223-2232.
[35] Zhang K, Zhang Z, Li Z, et al. Joint face detection and alignment using multitask cascaded convolutional networks[J]. IEEE Signal Processing Letters, 2016, 23(10): 1499-1503.
[36] Li Y, Chang M C, Lyu S. In ictu oculi: Exposing ai generated fake face videos by detecting eye blinking[EB/OL]. (2018)[2020-10-18]. https://arxiv.org/pdf/1806.02877.pdf.
[37] Korshunov P, Marcel S. Deepfakes: a new threat to face recognition? assessment and detection[EB/OL]. (2018) [2020-10-18]. https://arxiv.org/pdf/1812.08685.pdf
[38] Sanderson C, Lovell B C. Multi-region probabilistic histograms for robust and scalable identity inference[C]. International conference on biometrics, 2009: 199-208.
[39] Rossler A, Cozzolino D, Verdoliva L, et al. Faceforensics++: Learning to detect manipulated facial images[C]. Proceedings of the IEEE International Conference on Computer Vision, 2019: 1-11.
[40] Rossler A, Cozzolino D, Verdoliva L, et al. Faceforensics: A large-scale video dataset for forgery detection in human faces[EB/OL]. (2018)[2020-10-18]. https://arxiv.org/pdf/ 1803.09179.pdf
[41] Li Y, Yang X, Sun P, et al. Celeb-df: A new dataset for deepfake forensics[EB/OL]. (2019)[2020-10-18]. https://arxiv.org/pdf/1909.12962.pdf
[42] Reinhard E, Adhikhmin M, Gooch B, et al. Color transfer between images[J]. IEEE Computer graphics and applications, 2001, 21(5): 34-41.
[43] Jiang L, Li R, Wu W, et al. Deeperforensics-1.0: A large-scale dataset for real-world face forgery detection[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020: 2886-2895.
[44] Dolhansky B, Howes R, Pflaum B, et al. The deepfake detection challenge (dfdc) preview dataset[EB/OL]. (2019)[2020-10-18].https://arxiv.org/pdf/1910.08854.pdf.
[45] Dolhansky B, Bitton J, Pflaum B, et al. The deepfake detection challenge dataset[EB/OL]. [2020-10-18].https:// arxiv.org/pdf/2006.07397.pdf.
[46] Upchurch P, Gardner J, Pleiss G, et al. Deep feature interpolation for image content changes[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2017: 7064-7073.
[47] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[C].3rd International Conference on Learning Representations, 2015.
[48] Liu M Y, Breuel T, Kautz J. Unsupervised image-to-image translation networks[J]. Advances in neural information processing systems, 2017: 700-708.
[49] Perarnau G, Van De Weijer J, Raducanu B, et al. Invertible conditional gans for image editing[EB/OL]. (2016) [2020-10-18]. https://arxiv.org/pdf/1611.06355.pdf.
[50] Mirza M, Osindero S. Conditional generative adversarial nets[EB/OL]. (2014)[2020-10-18]. https://arxiv.org/pdf/ 1411.1784.pdf.
[51] Jia L, Song Y, Zhang Y. Face aging with improved invertible conditional gans[C]. 2018 24th International Conference on Pattern Recognition (ICPR). IEEE, 2018: 1396-1401.
[52] Choi Y, Choi M, Kim M, et al. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2018: 8789-8797.
[53] Shen Y, Gu J, Tang X, et al. Interpreting the latent space of gans for semantic face editing[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 9243-9252.
[54] Thies J, Zollhofer M, Stamminger M, et al. Face2Face: Real-time face capture and reenactment of rgb video[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016: 2387-2395.
[55] Thies J, Zollhöfer M, Nießner M. Deferred neural rendering: Image synthesis using neural textures[J]. ACM Transactions on Graphics (TOG), 2019, 38(4): 1-12.
[56] Isola P, Zhu J Y, Zhou T, et al. Image-to-image translation with conditional adversarial networks[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2017: 1125-1134.
[57] Wiles O, Sophia Koepke A, Zisserman A. X2face: A network for controlling face generation using images, audio, and pose codes[C]. Proceedings of the European conference on computer vision (ECCV). 2018: 670-686.
[58] Siarohin A, Lathuilière S, Tulyakov S, et al. First order motion model for image animation[C]. Advances in Neural Information Processing Systems. 2019: 7137-7147.
[59] He M. Distinguish computer generated and digital images: A CNN solution[J]. Concurrency and Computation: Practice and Experience, 2019, 31(12): e4788.
[60] Marra F, Gragnaniello D, Cozzolino D, et al. Detection of gan-generated fake images over social networks[C]. IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), 2018: 384-389.
[61] Nataraj L, Mohammed T M, Manjunath B S, et al. Detecting GAN generated fake images using co-occurrence matrices[J]. Electronic Imaging, 2019, (5): 5321-5327.
[62] Barni M, Kallas K, Nowroozi E, et al. CNN Detection of GAN-Generated Face Images based on Cross-Band Co-occurrences Analysis[EB/OL]. [2020-10-18]. https://arxiv.org/pdf/2007.12909.pdf.
[63] Goebel M, Nataraj L, Nanjundaswamy T, et al. Detection, Attribution and Localization of GAN Generated Images[EB/OL]. [2020-10-18]. https://arxiv.org/pdf/2007. 10466.pdf.
[64] Zhou P, Han X, Morariu V I, et al. Two-stream neural networks for tampered face detection[C]. IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2017: 1831-1839.
[65] Bayar B, Stamm M C. A deep learning approach to universal image manipulation detection using a new convolutional layer[C]. Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security, 2016: 5-10.
[66] Ding X, Raziei Z, Larson E C, et al. Swapped face detection using deep learning and subjective assessment[J]. EURASIP Journal on Information Security, 2020: 1-12.
[67] Quan W, Wang K, Yan D M, et al. Distinguishing between natural and computer-generated images using convolutional neural networks[J]. IEEE Transactions on Information Forensics and Security, 2018, 13(11): 2772-2787.
[68] Afchar D, Nozick V, Yamagishi J, et al. Mesonet: a compact facial video forgery detection network[J]. IEEE International Workshop on Information Forensics and Security (WIFS), 2018: 1-7.
[69] Nguyen H H, Yamagishi J, Echizen I. 2019. Capsule-forensics: Using capsule networks to detect forged images and videos[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019: 2307-2311.
[70] Cozzolino D, Poggi G, Verdoliva L. Recasting residual-based local descriptors as convolutional neural networks: an application to image forgery detection[C]. Proceedings of the 5th ACM Workshop on Information Hiding and Multimedia Security, 2017: 159-164.
[71] Rahmouni N, Nozick V, Yamagishi J, et al. Distinguishing computer graphics from natural images using convolution neural networks[J]. IEEE Workshop on Information Forensics and Security (WIFS), 2017: 1-6.
[72] Yisroel Mirsky, Wenke Lee. The Creation and Detection of Deepfakes: A Survey[EB/OL]. [2020-09-13]. https://arxiv. org/pdf/2004.11138.pdf.
[73] Marra F, Saltori C, Boato G, et al. Incremental learning for the detection and classification of GAN-generated images[J]. IEEE International Workshop on Information Forensics and Security (WIFS), 2019: 1-6.
[74] Agarwal S, Farid H, Gu Y, et al. Protecting World Leaders Against Deep Fakes[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2019: 38-45.
[75] Songsri-in K, Zafeiriou S. Complement face forensic detection and localization with faciallandmarks[EB/OL]. [2020-10-18]. https://arxiv.org/pdf/1910.05455.pdf.
[76] Nguyen H H, Fang F, Yamagishi J, et al. Multi-task learning for detecting and segmenting manipulated facial images and videos[C]. International Conference on Biometrics Theory, Applications and Systems, 2019: 1-8.
[77] Cozzolino D, Thies J, Rössler A, et al. Forensictransfer: Weakly-supervised domain adaptation for forgery detection[EB/OL]. (2018)[2020-10-18]. https://arxiv.org/pdf/ 1812.02510.pdf.
[78] Du M, Pentyala S, Li Y, et al. Towards generalizable forgery detection with locality-aware autoencoder[EB/OL]. [2020-10-18]. https://arxiv.org/pdf/1909.05999.pdf.
[79] Matern F, Riess C, Stamminger M. Exploiting visual artifacts to expose deepfakes and face manipulations[J]. IEEE Winter Applications of Computer Vision Workshops (WACVW), 2019: 83-92.
[80] Yang X, Li Y, Lyu S. Exposing deep fakes using inconsistent head poses[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019: 8261-8265.
[81] Yi D, Lei Z, Liao S, et al. Learning face representation from scratch [C]. arXiv preprint arXiv:1411.7923. 2014.
[82] Zhang X, Karaman S, Chang S F. Detecting and simulating artifacts in gan fake images[J]. IEEE International Workshop on Information Forensics and Security (WIFS), 2019: 1-6.
[83] Chen Z, Yang H. Manipulated Face Detector: Joint Spatial and Frequency Domain Attention Network[EB/OL]. [2020-10-18]. https://arxiv.org/pdf/2005.02958.pdf.
[84] Li H, Li B, Tan S, et al. Detection of deep network generated images using disparities in color components[EB/OL]. [2020-10-18]. https://arxiv.org/pdf/1808.07276.pdf.
[85] Wang R, Ma L, Juefei-Xu F, et al. Fakespotter: A simple baseline for spotting ai-synthesized fake faces[EB/OL]. (2019)[2020-10-18]. https://arxiv.org/pdf/1909.06122.pdf
[86] Guarnera L, Giudice O, Battiato S. DeepFake Detection by Analyzing Convolutional Traces[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020: 666-667.
[87] Liu Z, Qi X, Torr P H S. Global texture enhancement for fake face detection in the wild[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 8060-8069.
[88] Güera D, Delp E J. Deepfake video detection using recurrent neural networks[C]. IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), 2018: 1-6.
[89] Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural computation, 1997, 9(8): 1735-1780.
[90] Sabir E, Cheng J, Jaiswal A, et al. Recurrent convolutional strategies for face manipulation detection in videos[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2019: 80-87.
[91] Cho K, Van Merriënboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[C]. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, 2014: 1724-1734.
[92] Carreira J, Zisserman A. Quo vadis, action recognition? A new model and the kinetics dataset[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6299-6308.
[93] Hara K, Kataoka H, Satoh Y. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet?[J]. Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2018: 6546-6555.
[94] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[J]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016: 770-778.
[95] Jung T, Kim S, Kim K. DeepVision: Deepfakes Detection Using Human Eye Blinking Pattern[J]. IEEE Access, 2020, 8: 83144-83154.
[96] Ranjan R, Patel V M, Chellappa R, et al. 2018. Deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, ,2018, 41(1): 121-135.
[97] Soukupova T, Cech J. 2016. Eye blink detection using facial landmarks[J]. 21st computer vision winter workshop. 2016.
[98] Qi H, Guo Q, Juefei-Xu F, et al. DeepRhythm: Exposing DeepFakes with Attentional Visual Heartbeat Rhythms[C]. Proceedings of the 28th ACM International Conference on Multimedia, 2020: 4318-4327.
[99] Masi I, Killekar A, Mascarenhas R M, et al. Two-branch Recurrent Network for Isolating Deepfakes in Videos[EB/OL]. (2020)[2020-10-18]. https://arxiv.org/pdf/ 2008.03412.pdf.
[100] Tursman E, George M, Kamara S, et al. Towards Untrusted Social Video Verification to Combat Deepfakes via Face Geometry Consistency[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020: 654-655.
Survey of Intelligent Face Forgery and Detection
Cao Yuhong1, Shang Zhihua2, Hu Ziheng2, Zhu Jiaqi2, Li Hongliang3
(1. Chinese Institute of Electronics, Beijing 100036, China;2. School of Information Science and Technology, University of Science and Technology of China, Hefei 230026, China;3. School of Engineering Sciences, University of Chinese Academy of Sciences, Beijing 100049, China.)
Face forgery technology has made considerable progress in recent years, and has several challenges in terms of maintaining social stability and protecting individual rights. Nowadays, an ordinary person can easily generate lifelike fake images and videos, including fake news related to public figures, without any professional knowledge. To eliminate the social security risks caused by fake face images and videos, face forgery detection has become an emerging field that has attracted considerable attention. This survey provides a detailed overview of face forgery and face forgery detection methods. Based on the ratio of manipulations to the original image, this paper first introduces four types of face forgery methods: i) identity swap, ii) expression swap, iii) attribute manipulation, iv) entire face synthesis, and corresponding face forgery detection datasets. We then introduce image– and video–level face forgery detection methods. To improve the manipulation detection results, most face forgery detection methods exploit prior knowledge, such as biological and frequency information, based on deep learning. Subsequently, this paper analyzes the effects of these manipulation detection methods. Finally, we discuss the shortcomings of the current methods in terms of practical applications and discuss the future development trend of face forgery detection.
face manipulation;forgery detection; media forensics; generative adversarial networks; autoencoder
2020–10–20;
2020–11–27
国家重点研发计划课题“面向互联网+的媒体内容分析技术研究”(2018YFB0804203);国家自然科学基金通用联合基金重点项目“基于深度学习的数字图像溯源分析与取证研究”(U1936210);中央高校基本科研业务费专项资金“基于显著性的压缩感知成像研究”(E0E48980)
曹玉红(1968–),女,高级工程师,研究方向为人工智能。E-mail: caoyh100@126.com
尚志华(1992–),男,博士研究生,研究方向为深度伪造人脸检测。E-mail: shangzh@mail.ustc.edu.cn
胡梓珩(1997–),男,硕士研究生,研究方向为深度伪造人脸检测。E-mail: hzh519@mail.ustc.edu.cn
朱佳琪(1997–),女,硕士研究生,研究方向为图像分类。E-mail: zhujq32@mail.ustc.edu.cn
TP391.4
A
1674-4969(2020)06-0538-18
10.3724/SP.J.1224.2020.00538
