基于混合词向量深度学习模型的DGA域名检测方法
2020-02-19丁世飞
杜 鹏 丁世飞
(中国矿业大学计算机科学与技术学院 江苏徐州 221116) (矿山数字化教育部工程研究中心(中国矿业大学) 江苏徐州 221116)
僵尸网络指的是被攻击者使用恶意代码感染的终端组成的网络,而这些感染僵尸程序的终端称为僵尸主机(bot).攻击者通过利用软件漏洞等方式,使受害主机感染恶意僵尸程序,并通过一对多的命令控制(command and control, C&C)信道,控制僵尸主机完成指定的攻击行为[1].僵尸网络是危害网络安全的主要威胁之一[2].僵尸网络已有较长的历史,第1个具有恶意攻击行为的僵尸网络是于1999年6月发现的PrettyPark[3].攻击者可通过部署并控制僵尸网络进行多种网络攻击,例如分布式拒绝服务攻击(DDoS)、窃取个人信息数据、发送垃圾邮件、加密勒索等[4].随着僵尸网络的发展,攻击者设计出了多种类型的命令控制信道,大多数僵尸网络依赖于命令控制服务器(C&C server)完成攻击者与僵尸主机之间的通信[5].僵尸网络的检测有多种方法[6-10],针对僵尸网络依赖的命令控制服务器,一旦发现僵尸网络依赖的命令控制服务器对应的域名,通过使用黑名单、Sinkhole或夺取命令控制服务器的方式,使僵尸网络失效[11-12].采用固定IP或域名的僵尸网络,其命令控制服务器容易被发现然后被关闭.为了对抗安全研究者,僵尸网络会采用域名生成算法(domain generation algorithm, DGA)随机生成大量的命令控制服务器域名,这使得发现僵尸网络的命令控制服务器变得更加困难[13].于是DGA域名的检测成为了防范僵尸网络的重要研究课题之一.
僵尸网络利用DGA域名的原理是,僵尸网络作者在僵尸程序中编入设计好的DGA算法,僵尸程序根据该DGA算法生成大量的DGA域名并周期性产生一个域名列表.僵尸网络作者会注册某些域名作为这个僵尸网络的命令控制服务器.之后,僵尸程序会根据该列表依次与表中的域名进行连接,如果一个域名解析成功,而且僵尸程序收到所属的僵尸网络协议的回复,这时僵尸主机便与命令控制服务器通信成功,即可完成攻击者的指令.一旦该域名被网络安全研究者发现后被运营商屏蔽,此时攻击者可注册DGA域名列表的下一个域名,这样攻击者可以保证命令控制服务器对应的域名仍能解析成功,保持命令控制服务器与僵尸主机的通信,从而增强僵尸网络的隐蔽性.这种技术被研究者称作domain flux[14].由于domain flux的良好特性,使用DGA域名的domain flux在僵尸网络中十分流行.常见的DGA算法通常结合时间、字典和硬编码的常量来生成域名[15],例如基于HTTP协议的僵尸网络Torpig[14],会根据时间通过预先定义的计算方式生成字符串,然后在该字符串后连接若干种顶级域名,完成一个DGA域名的生成.直到今天,仍有多种僵尸网络利用DGA域名来提高自身的隐蔽性[16].
因此DGA域名检测是发现僵尸网络的重要途径之一.在面对海量的域名解析请求中发现DGA域名,机器学习技术成为DGA域名检测的关键技术环节.目前僵尸网络DGA域名检测方法取得了不错的进展,早期的使用域名字符串特征的检测方法主要采用人工定义的特征为基础的机器学习技术,机器学习技术使从海量域名服务请求数据中自动发现僵尸网络DGA域名成为可能.
近年来深度学习取得了飞速发展,在计算机视觉[17-18]、自然语言处理[19]、智能体决策[20]等多项任务中不断刷新性能表现记录,并应用到具体的工业场景中.基于深度学习的DGA域名检测方法也得到了安全研究者的重视.深度学习的一大优势就是可以自动发现有效的特征并做出分类,判断一个域名是否是DGA域名,完成DGA域名的检测工作.此外,不同的僵尸网络家族生成的DGA域名可按照所属家族进行多分类.深度学习方法可以适用于DGA域名的多分类问题,监督信息为DGA域名的家族,经过训练具备识别生成该DGA域名的僵尸网络家族的能力.
目前使用域名字符串特征的检测方法仍存在一些难点.DGA域名的训练数据来源于真实的网络环境,由于被发现的不同僵尸网络家族的DGA域名数量差距较大,因此DGA域名数据存在不平衡问题.这会影响到基于深度学习的DGA域名检测方法在多分类问题上的性能表现.小样本的僵尸网络家族在多种性能度量指标上较低.
针对上述问题,本文设计一种基于混合词向量的深度学习模型,应用到DGA域名检测与分类这一具有现实意义的网络安全场景中.该方法首次结合了DGA域名的字符级词向量与双字母组(bigram,2-Gram)级词向量,令深度学习架构可以同时利用不同尺度的词向量表示信息来提取特征.同时本文设计了一种适用于DGA域名检测任务的深度学习模型,该模型使用了混合词向量的并行深度学习架构.实验表明,本文提出的方法可以提高在DGA域名多分类问题上的性能.
1 相关工作
DGA域名检测在针对僵尸网络的防御中扮演十分重要的角色,因此DGA域名检测是网络安全的一个研究重点,其研究成果多次出现在信息安全的顶级会议中.在2010年,Antonakakis等人[21]提出域名声望系统Notos,通过分析被动域名系统(passive domain name system, PDNS)数据,建立多种手工特征,通过2个层次的聚类来发现与已知的恶意域名和IP地址之间的联系,最后计算域名的声望分数,刻画该域名为DGA域名的可能性.Notos依赖于大量的恶意域名历史数据,无法对单一域名做到实时检测.
Bilge等人[22]提出了另一个使用PDNS数据发现DGA域名的系统EXPOSURE.该系统使用了与域名系统(domain name system, DNS)协议相关的特征,例如基于时间的特征、基于DNS响应的特征、基于域名的特征等.其中基于域名的特征是直接与域名字符串本身相关的特征,由手工定义的2个特征组成,数字字符占总字符数的比例与有意义的最长子串占总字符数的比例.该系统使用的分类器是决策树,使用上述手工特征进行监督学习.
除了上述2种经典的结合DNS数据检测DGA域名外,大量研究工作只使用域名字符串的特征进行DGA域名检测.Yadav等人[23-24]同时使用域名簇的1-Gram与2-Gram的统计特征,计算DGA域名集合与非DGA域名集合的1-Gram与2-Gram的分布,分布之间的差异使用KL距离度量,聚类结果与标签集合的差异使用Jaccard距离度量.
Antonakakis等人[25]通过观察DGA技术的特点发现,僵尸网络在使用DGA域名技术时会查询大量不存在的域名(non-existent domain, NXDomain),而且相同的僵尸网络会查询相似的不存在的域名.手工定义不存在的域名的统计特征,通过聚类发现潜在的DGA域名簇,之后将不同的域名簇使用隐马尔可夫模型(hidden Markov model, HMM)进行分类.同样地,这项工作也针对包含大量域名的域名簇进行分类,无法对单一域名做到实时检测.
这些经典方法全部采用手工定义的特征.随着深度学习的发展,直到2016年,Woodbridge等人[26]首次将深度学习应用到DGA域名的检测中.特别是在只使用域名字符串特征的DGA域名检测任务中,深度学习能够自动提取特征的优势凸显出来,DGA域名检测取得了相当程度的进步.Woodbridge等人[26]使用长短期记忆网络(long short-term memory, LSTM),将域名字符串作为输入,经过词向量层生成字符级词向量,之后由LSTM层提取时序特征,送入逻辑回归层完成分类.使用深度学习可以实现单一域名的实时检测.这项工作在DGA域名的二分类任务中取得了很好的效果,但在识别DGA域名家族的多分类任务中,由于数据不平衡性,其结果仍有提升空间.
最近的研究工作中,Yu等人[27-28]和Vinayakumar等人[29]分别对多种深度学习架构在DGA域名检测任务中进行了实验对比,比较了多种典型的卷积神经网络(convolutional neural network, CNN)与循环神经网络(recurrent neural network, RNN).DGA域名检测可以看作一类特殊的短文本分类任务,在这些实验中,基于深度学习架构的方法普遍优于基于手工特征的分类方法.但同样地,这些方法在DGA域名家族多分类任务中仍有提高空间.
本文提出的基于混合词向量的方法,有效地提高了域名字符串的信息利用程度.通过结合字符级词向量和双字母组词向量,很大程度上保留了数据在2种粒度上的特征.该方法设计了一种使用窗口特征序列的结合CNN与LSTM的深度学习架构,较好地发现2种粒度上的局部特征与长期依赖特征.
2 混合词向量
DGA域名检测工作中,针对每一个域名X,判断属于DGA域名或是正常域名,这是二分类问题;判断属于正常域名或是DGA域名的具体家族,这是多分类问题.
非DGA的正常域名,就是我们日常访问互联网时提供正常各项互联网服务的域名,如baidu.com,google.com等.正常域名通常是由具有意义的单词或单词片段组成,而正如上面的例子,DGA域名通常是由杂乱无意义的字符组成,例如chaqsxphhmr.org.直观上看,DGA域名与正常域名在字符分布上应存在差异,考虑到自然语言中的英文单词或中文拼音,其元音与辅音字母的分布存在一定的规律性,存在着多种元音字母与元音字母,辅音字母与辅音字母的固定组合方式.而在使用DGA算法生成的域名字符串中,这样的字母分布特点并不明显.于是考虑使用深度学习模型进行DGA域名的检测与分类,深度学习模型可以发现字符之间隐含的分布特征.
2.1 字符级词向量
深度学习模型只能处理经过数值化的张量,而不能直接处理字符形式的数据.因此在自然语言处理中,常用的处理方式是采用词向量的技术.首先我们将字符串中的单词量化,使用one-hot编码将单词编为长度为V的向量.其中V为字典集的大小,通常来说是语料中出现的所有单词的个数.经过one-hot编码后,每个单词用的向量(o1,o2,…,oV)来表示,V个元素中只有一个元素是1,其余元素为0.one-hot编码的维度是字典集大小V.但如果直接使用one-hot编码送入深度学习模型中学习,那么将会导致模型参数数量巨大且非常稀疏的问题,同时one-hot编码忽略了单词与单词之间存在的语义关系.这将导致较差的训练效果.
因此在将one-hot编码后的域名字符串直接送入深度学习模型进行训练之前,首先需要经过词嵌入层生成每个单词的词向量.词向量是每个单词映射到维度比V低得多的实数域上的向量,不同的维度包含了不同的语义信息.在常见的自然语言处理任务中,常使用Word2Vec[30]等方法生成词向量.这是一种使用了迁移学习思想的预训练方法,Word2Vec的词嵌入层由一层线性的隐含层组成.将互联网上的大量网页作为无监督学习的语料,进行语言模型的任务,根据当前词预测上下文中可能出现的词最大化训练数据上下文中的词出现概率,这样可以学习自然语言中包含语义信息的词向量.
但在DGA域名检测问题中,由于大量DGA域名是由看似无规律的杂乱的字符组成,其域名大多并不是一个自然语言中存在的单词,因此直接使用Word2Vec等预训练方法是难以进行的.在DGA域名检测任务中,将域名中的每个字符看作一个独立的“词”,也就是针对每个字符生成一个字符级词向量.一个完整的域名记为X,为了方便使用神经网络进行学习,我们规定每个域名字符串的长度为数据集的最大域名长度L1,对于长度不足L1的域名字符串,从字符串头补全0向量.为了与后面双字母组级词向量进行区分,这些常量的下标为1,双字母组级词向量中的常量下标为2.那么域名X由L1个字符xi组成,即
X=(x1,x2,…,xL1),
(1)
之后对每个字符xi量化表示.我们设定输入的字符种类数为V1,即包含了域名字符串中所有可能出现的字符的字典大小为V1.这样就可以建立一个字符到one-hot编码的映射,每个字符使用一个V1维的one-hot向量表示.其中只有第i个元素是1,其余都是0.
xi=(o1,o2,…,oV1)T,
(2)
这样每个域名X经过one-hot编码后的维度为(V1,L1).
之后我们将域名字符串的one-hot编码送入词嵌入层,我们的词嵌入层与Word2Vec采用的词嵌入层类似,是一个矩阵W1∈RV1×N1,W1的每一行是每个字符对应的N1维词向量vi.
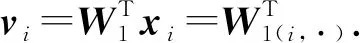
(3)
具体而言,给定一个字符xi的one-hot向量中,oi=1,oi′=0,i≠i′,该字符对应的词向量即为矩阵W1的第i行,vi∈RN1.每个域名X通过词嵌入层得到的字符级词向量为E1∈RN1×L1.与Word2Vec的语言模型训练词向量的方式不同,在DGA域名检测任务中,我们根据域名对应的标签进行具体任务的监督学习得到词向量,学习的参数W1即为词向量表.
2.2 双字母组级词向量
Yadav等人[23-24]所做工作中表明,双字母组的统计特征可以用于DGA域名检测,同时通过观察DGA域名与非DGA正常域名的字符分布的特点,2个不同的字符组合会包含更多的语义信息.我们提出结合使用字符级词向量与双字母组级词向量的混合词向量DGA域名检测深度学习模型.双字母组级词向量与字符级词向量的词嵌入层结构相似,与字符级词向量不同的是,双字母组指的是2个相邻字符作为一个基本词语单位,完成one-hot编码并送入词嵌入层中.例如baidu.com的双字母组序列为ba,ai,id,du,u.,.c,co,om.同样地,根据数据集中的最大域名长度指定每个域名的最大双字母组长度为L2,对长度不足L2的字符串补0,域名X由L2个双字母组序列xi组成.由于2个相邻字符的组合方式更加多样,因此双字母组字典大小将大于字符级字典大小.我们将双字母组字典大小记为V2,建立包含2个字符的双字母组的V2维one-hot向量,得到每个域名X的双字母组序列的维度为(V2,L2).之后送入双字母组词嵌入层中进行训练,W2∈RV2×N2,产生双字母组词向量.那么该域名的双字母组词向量为E2∈RN2×L2.经过2个不同的词嵌入层,我们分别得到字符级词向量E1和双字母组级词向量E2.这2组词向量分别包含了字符粒度上的隐含语义信息,以及在2相邻字符粒度上的隐含语义信息,这将更有利于深度学习模型完成域名的分类任务.
3 模型结构
为了自动发现域名字符串的隐含特征,我们使用深度学习模型来提取特征并进行分类任务.卷积神经网络和循环神经网络作为2种应用广泛的深度学习模型,在多项任务中取得了非常好的效果.总体而言卷积神经网络善于发现局部特征,但不易发现序列特征,而循环神经网络善于发现序列特征,能够发现数据的长期依赖关系[31].因此我们考虑结合卷积神经网络与循环神经网络的特点设计我们的深度学习模型,我们的深度学习模型如图1所示.该深度学习模型由基于字符级词向量的网络与基于双字母组词向量的网络并联而成,域名输入依次经过词嵌入层、卷积神经网络层、循环神经网络层、全连接层和稠密层,最终输出域名的分类结果.其中循环神经网络层采用长短期记忆网络[32],各层网络的细节如下所述.
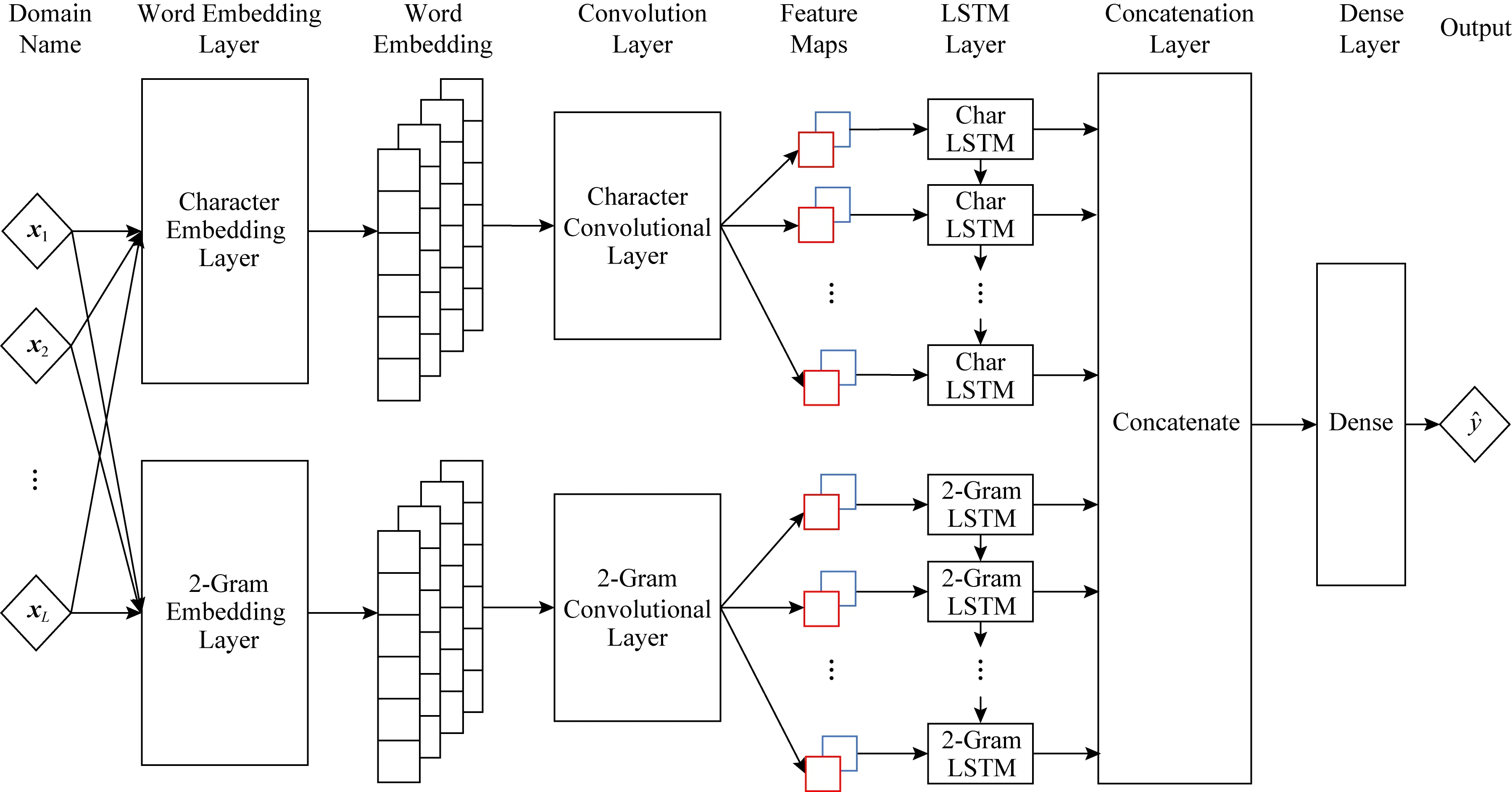
Fig. 1 The overall architecture of the model for DGA domain name detection based on deep learning models with mixed word embedding图1 基于混合词向量深度学习模型的DGA域名检测模型总体架构图
3.1 词嵌入层
我们使用的词嵌入层如图1所示,包含2个并行的词向量层,分别是字符级词向量层和双字母组级词向量层.首先对域名字符串进行预处理,生成域名的字符序列和双字母组序列,并补0至各序列的最大长度.根据我们使用的数据集的统计信息,最大域名长度为49个字符,因此域名字符序列最大长度L1=49,域名双字母组序列最大长度L2=48.域名字符序列字典大小直接取ASCII字符种类数,即V1=256.域名双字母组序列字典大小V2=2 000.词向量维度皆取n=128.之后字符序列送入字符级词向量层,双字母组序列送入双字母组词向量层,得到2个粒度的词向量:
E1=W1TXL1,
(4)
E2=W2TXL2.
(5)
3.2 卷积神经网络层
域名字符串是一维的文本序列,对应地,我们采用一维卷积神经网络.一维卷积窗口在词向量序列上滑动,检测不同位置上的特征,来自动发现不同的域名中含有的隐含模式.
设域名字符串包含L个词向量,每个词向量记作ei.由于字符级词向量与双字母组级词向量在结构上是类似的,这里不再分开讨论.ei∈Rn,是域名中第i个字符或双字母组对应的词向量,E∈RL×n为长度为L的域名的词向量序列.设一维卷积核的长度为k,那么卷积核表示为m∈Rk×d.为了获得域名的局部特征,对于域名的每一个字符或双字母组的位置j,建立一个窗口向量wj.窗口向量的长度与卷积核长度相同,也就是由连续的k个词向量组成,记为
wj=(ej,ej+1,…,ej+k-1),
(6)
窗口向量wj∈Rk×n.之后对每个窗口向量使用卷积核m进行卷积运算,那么每个窗口向量产生一个窗口特征图aj,
(7)
aj的计算过程中,b是偏置项,f是非线性激活函数,通常使用tanh或RELU,⊙是元素乘法.按行连接域名的每个窗口向量进行卷积运算产生的每个窗口特征图,得到该域名的一个维度的特征图A,A∈Rl-k+1.
A=(a1,a2,…,al-k+1).
(8)
卷积神经网络中经常同时使用多个卷积核,这里我们记卷积核数目为nc.这样每一个卷积核产生一个维度的特征图,nc个卷积核将产生nc个维度的特征图,将它们按列连接,最终得到域名特征图FM:
FM=[A1;A2;…;Anc].
(9)
按列连接使用;表示,FM∈R(l-k+1)×nc.在我们的模型中,窗口大小取k=3,卷积层同时使用64个卷积核.字符级卷积神经网络中,字符序列长度L1=49,那么字符级窗口特征图FM∈R47×64;双字母组卷积神经网络中,双字母组序列长度为L2=48,那么双字母组级窗口特征图FM∈R46×64.卷积神经网络层卷积窗口原理如图2所示:
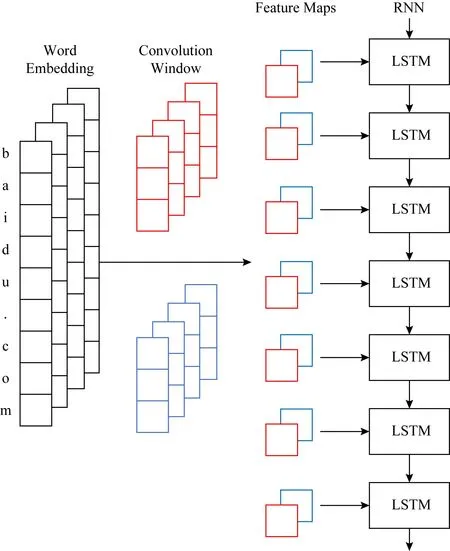
Fig. 2 The convolution windows in the convolution layer图2 卷积神经网络层卷积窗口原理示意图
卷积神经网络通常使用最大池化层或均值池化层对特征图进行处理,使得卷积神经网络提取的特征更显著,但在我们的模型中,没有采用池化层,考虑到之后采用循环神经网络的主要目的是发现域名的序列之间的时序依赖关系,池化层离散地选取特征图将破坏特征图之间的时序依赖关系.因此我们的模型中没有使用池化层.
3.3 循环神经网络层
在我们的模型中,循环神经网络层采用长短期记忆网络,即LSTM.一个LSTM单元由输入门it、输出门和遗忘门ft构成.重复的LSTM单元可记录每一个时刻的状态,在本问题中,每一个时刻就是域名的每一个字符或双字母组位置.输入门控制新的输入值流入单元的程度,遗忘门控制值在单元中保留的程度,输出门控制决定哪些值用于输出激活LSTM单元.每个单元由前一个隐藏状态ht-1和当前时刻的输入xt决定,xt包含了it和ft,它们共同计算得到当前记忆单元ct和当前隐藏状态ht.LSTM单元内函数定义如下:
it=σ(Wi(ht-1,xt)+bi),
(10)
ft=σ(Wf(ht-1,xt)+bf),
(11)
qt=tanh(Wq(ht-1,xt)+bq),
(12)
ot=σ(Wo(ht-1,xt)+bo),
(13)
ct=ft⊙ct-1+it⊙qt,
(14)
ht=ot⊙tanh(ct),
(15)
σ表示sigmoid函数,tanh是双曲正切函数,⊙表示元素乘法.在LSTM网络中,所有单元中的向量都具有相同的维度,在我们的模型中,LSTM单元中的向量维度和卷积神经网络输出的窗口特征图的维度相同,都为nc=64.LSTM层的输入的特征向量为式(9)所示的域名特征图FM,在字符级网络结构中,LSTM层输入的特征向量的维度是(47,64);在双字母组级网络结构中,LSTM层输入的特征向量的维度是(46,64).
LSTM层通过如下步骤进行反向传播更新权值:
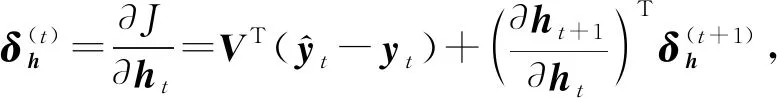
(16)
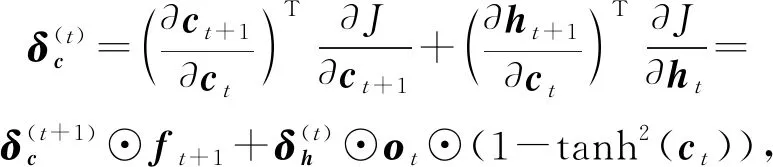
(17)
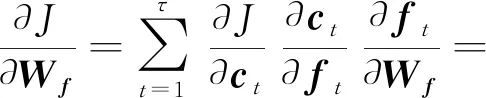
(18)
LSTM单元中使用多种门的设计是为了存储长距离序列的状态,可以缓解梯度消失的问题.LSTM为时序数据学习长期依赖而设计,因此选用LSTM来学习卷积层提取的高层特征的时序依赖关系.
为了防止过拟合,我们在LSTM层后使用Drop -out. Dropout在训练时随机移除网络中LSTM层和特征融合层之间的边,也就是忽略一定比例的LSTM单元,从而实现网络的正则化.在我们的模型中,Dropout的比例为0.1.
3.4 特征融合层
在特征融合层,我们采用向量连接操作,将字符级LSTM和双字母组级LSTM提取的特征连接起来,进行特征融合,使最后的稠密层分类器可以同时使用不同粒度的特征.设字符级LSTM的输出向量为(Schar1,Schar2,…,Scharnc),双字母级LSTM的输出向量为(Sbigram1,Sbigram2,…,Sbigramnc),在特征融合层,得到特征融合向量:
feature=(schar1,schar2,…,scharnc,sbigram1,sbigram2,…,sbigramnc).
(19)
其中nc=64,特征融合向量的维度为 R128.
3.5 稠密层
稠密层基于融合的特征完成最终的分类功能.根据任务的不同,稠密层也略有不同.在DGA域名检测的二分类任务中,稠密层仅由一个节点构成.在域名的DGA家族多分类任务中,稠密层节点数为域名的家族种类数,也就是多分类问题的标签类别数.由那么稠密层的神经元表示如下:
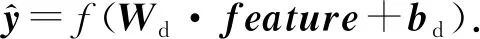
(20)
其中f是一个非线性激活函数,在DGA域名检测的二分类任务中,激活函数为sigmoid;在域名的DGA家族多分类任务中,激活函数为softmax,公式为
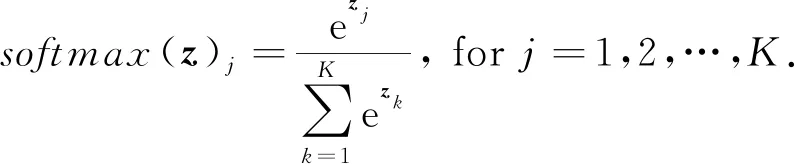
(21)
损失函数为交叉熵损失,通过Adam优化算法完成反向传播训练模型:
(22)
4 实验与结果
本节介绍本文模型在DGA域名检测问题上的实验,使用Keras和TensorFlow实现.Keras是一个高层次的深度学习编程框架,集成了多种神经网络的实现.Keras基于Python编程语言和TensorFlow后端,支持在GPU上加速训练模型.
4.1 数据集介绍
实验采用2个数据集,使用360 Netlab DGA开放数据[33](以下简称360数据集)为DGA样本数据,使用Alexa访问量全球排名前100万的网站域名数据集[34](以下简称Alexa数据集)作为非DGA样本数据.
截至2018年9月,360数据集包含了42个DGA域名家族,每条域名数据包含家族、域名和验证时间.由于部分家族的域名数量过少,我们采用与文献[26]相同的实验设置,除去数量最少的10个域名家族中的所有域名数据,只选取32个域名家族的域名数据用于训练与验证.360数据集中的所有域名在DGA域名识别的二分类问题中,被认作DGA阳性,即输出标签为1.
另一方面,考虑到每日庞大的访问量,Alexa数据集中的域名在各种DGA域名识别的研究中均被视为非DGA的正常域名,因此在DGA域名识别的二分类问题中,被认作DGA阴性,即输出标签为0.
在域名家族的多分类问题中,Alexa数据集域名作为单独一类,与360数据集中的32类域名,共同组成具有33个类别的多分类监督数据.同时,这2个数据集中的所有域名包含的字母都已转换为小写字母,这是因为DNS协议中域名对大小写不敏感,因此字母的大小写不在特征的考虑范围内.2个数据集中的最大域名长度为49 B.
4.2 实验步骤
在本节中,我们在Alexa数据集和360数据集上设计实验验证基于混合词向量的深度学习方法,包括基于混合词向量的LSTM模型、基于混合词向量的CNN模型和基于混合词向量的CNN-LSTM模型.进行2组实验来验证我们提出的基于混合词向量深度学习模型有效性:第1组实验是DGA域名检测的二分类实验.第2组实验是域名家族的多分类实验.通过本模型与对比模型在相同数据集上进行训练与测试,依照评价指标验证混合词向量带来的性能提升.
首先我们对数据进行预处理,从数据集中剔除无关字段,360数据集只保留家族字段与域名字段,Alexa数据集中只保留域名字段.之后在二分类任务中,整合2个数据集的域名数据,作为深度学习模型的输入数据,给360数据集中的域名标签为1,Alexa数据集的域名标签为0.在多分类任务中,深度学习模型的输入数据也是域名数据,Alexa数据集中的所有域名的标签为Alexa家族,360数据集中的域名标签为对应的DGA家族字段,将这些家族名称用1~33的整型数字唯一标识,作为多分类任务的标签.之后我们生成域名数据的字符序列和双字母组序列,补零至各序列的最大长度.并把字符和双字母组看作语言的基本单位“单词”,生成字符字典和双字母组字典,并把所有的“单词”唯一映射到one-hot向量.此时完成数据的预处理.
数据预处理完成后,划分训练集和测试集,测试集占总数据集的20%,按照所有类别随机生成训练集和测试集.我们将字符序列的one-hot向量输入到对比模型中,将字符序列和双字母组序列的one-hot向量输入到本文提出的模型中,进行训练与测试.
我们使用Adam方法优化目标函数,超参选择如下:学习率为0.001,β1=0.9,β2=0.999,ε=10-8,decay=0.0.
4.3 评价指标
DGA域名检测的二分类任务中,我们采用精确率(precision)、召回率(recall)、F1值和ROC曲线下面积(AUC)进行对模型的评价.其中二分类任务中的精确率、召回率和F1值为微平均(micro average).
域名的DGA家族多分类任务中,我们采用精确率、召回率和F1值分别在微平均(micro average)和宏平均(macro average)下的值进行评价,如表1所示:

Table 1 Evaluation Metrics in the Experiments表1 实验采用的评价指标
Note:Crepresents the total number of classes.
4.4 对比模型
在2个实验中,我们采用相同的对比模型.我们选用文献[26]提出的LSTM模型和文献[29]提出的较新的CNN模型.在自然语言处理领域的研究中,LSTM模型在文本分类、机器翻译、文本生成等多项任务中取得了很好的表现,已成为多种任务中的基准测试模型.直到2016年,Woodbridge等人[26]首次将LSTM应用到DGA域名分类中,并取得了优于当时所有的非深度学习方法.在2015年,Zhang等人[35]通过实验发现字符级一维卷积神经网络在自然语言处理的多项任务中优于LSTM方法.文献[29]选取CNN用于DGA域名检测任务,实验表明取得了很好效果.
此外,文献[29]的实验结果表明,在DGA域名检测的二分类实验与多分类实验中,基于手工特征的非深度学习方法的分类性能都不如LSTM模型.这些机器学习模型包括逻辑回归、随机森林、决策树和朴素贝叶斯.因此我们选取性能更好的LSTM模型以及CNN模型作为本实验的对比模型.
具体来说,LSTM模型的词向量维度为128维,送入128维的LSTM层中,最后送到稠密层输出预测值.CNN模型中,词向量维度为128维,1维卷积大小为3,步长为1,没有填充,激活函数为RELU,后跟最大化池化层,大小为2,送入激活函数为RELU的稠密层,最后送入sigmoid或softmax层进行分类.在CNN-LSTM模型中,我们使用的模型的超参数选择已经在第3节中提及,重复部分不再赘述.其中,基于字符级词向量的LSTM模型记为LSTM,基于混合词向量的LSTM模型记为LSTM-MWE;基于字符级词向量的CNN模型记为CNN,基于混合词向量的CNN模型记为CNN-MWE;基于字符级词向量的LSTM-CNN模型记为LSTM-CNN,基于混合词向量的LSTM-CNN模型记为LSTM-CNN-MWE.
4.5 结果分析
DGA域名检测的二分类结果如表2所示.可以看出,我们的模型和3种对比模型在二分类任务的4个评价指标上都取得了相当好的结果,说明深度学习模型在DGA域名检测任务中具有非常优秀的性能.这4种模型在二分类任务中的性能差距不明显.
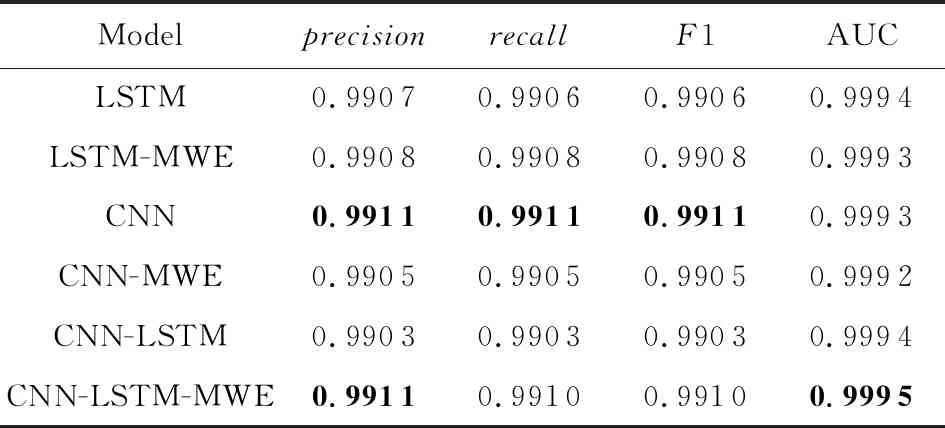
Table 2 Test Results for Binary Classification 表2 二分类实验测试结果
Notes: The best results for each metric are shown in boldface.
在第2组实验中,全部33个域名家族的在3种评价指标上的结果如表3~5所示.根据实验结果可以发现,通过使用本文提出的混合词向量方法,本文实验中选取的3种深度学习模型都有性能提升,特别是在宏平均精确率、宏平均召回率和宏平均F1值上有较明显的提升.说明混合词向量可有效提升在不平衡数据集中小样本类别的分类性能.考虑到类别不平衡的数据集上,分类器的分类性能主要受限于小样本类别,采用混合词向量可有效增加样本数据的信息利用度,从而缓解由于训练数据量不足带来的影响.在实际应用中,可选择采用混合词向量设计分类器模型,来提高分类性能表现.
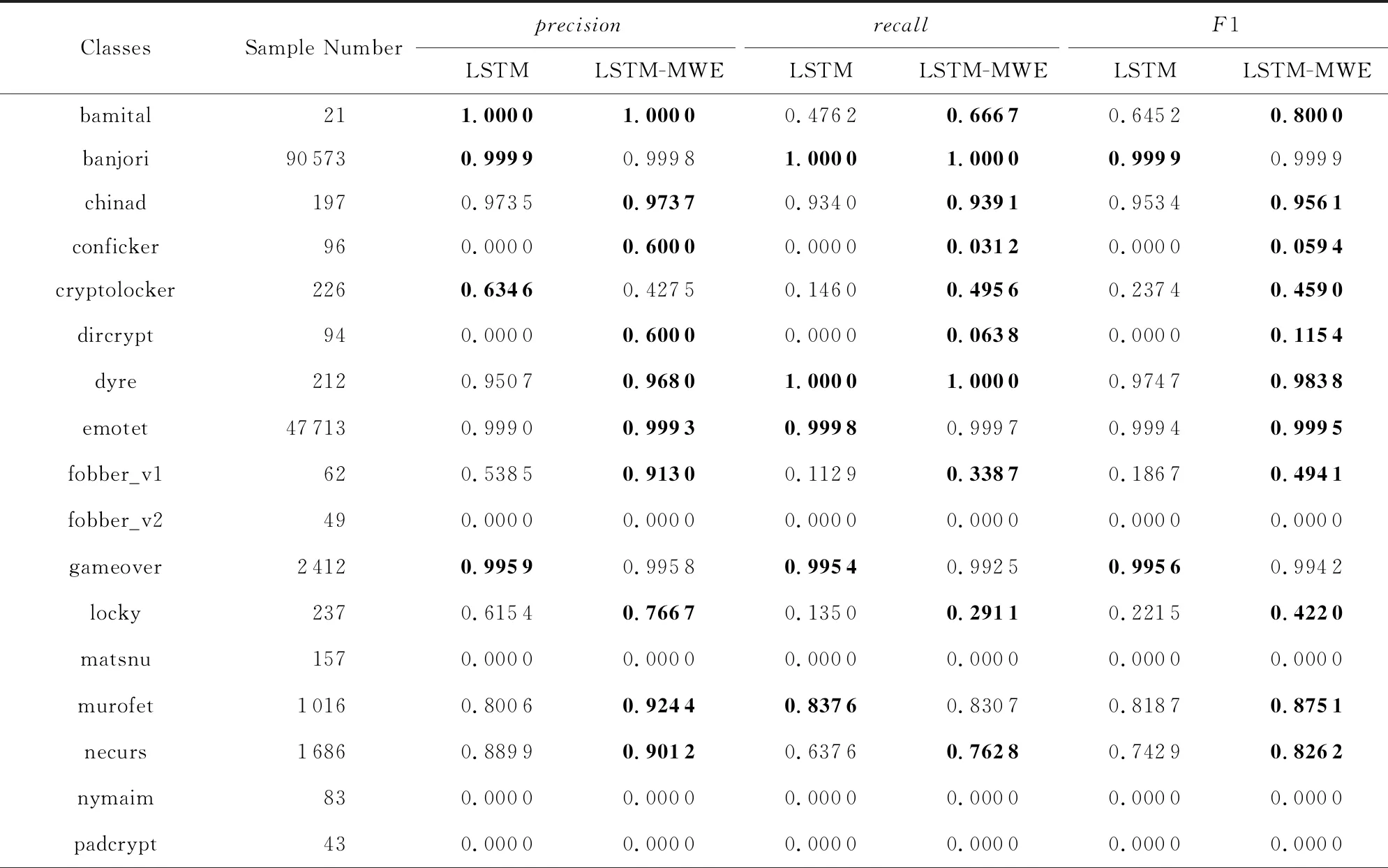
Table 3 Test Results of LSTM and LSTM-MWE for Multi-Class Classification 表3 LSTM模型与LSTM-MWE模型的多分类实验测试结果
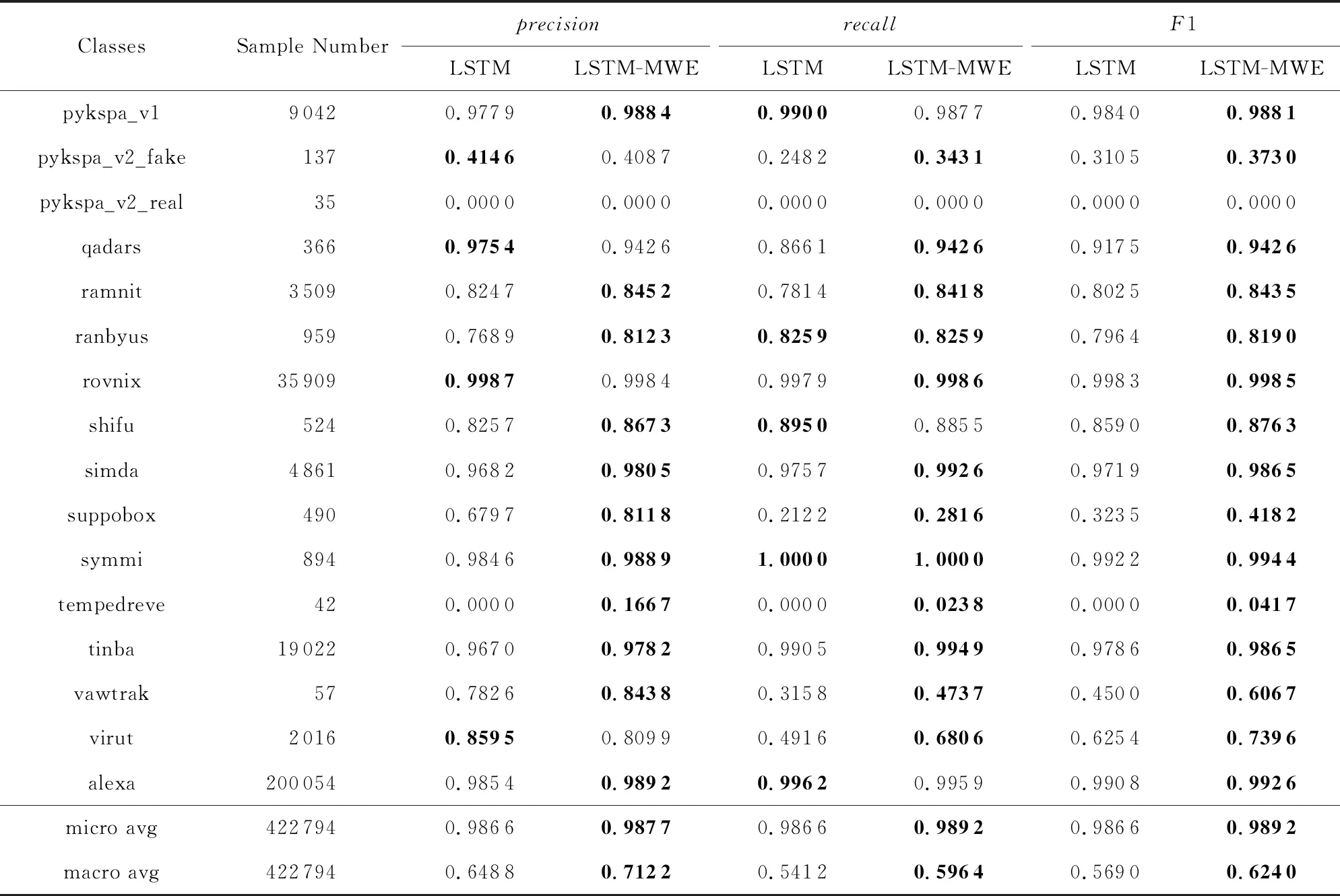
Continued (Table 3)
Notes: The best results for each metric are shown in boldface.
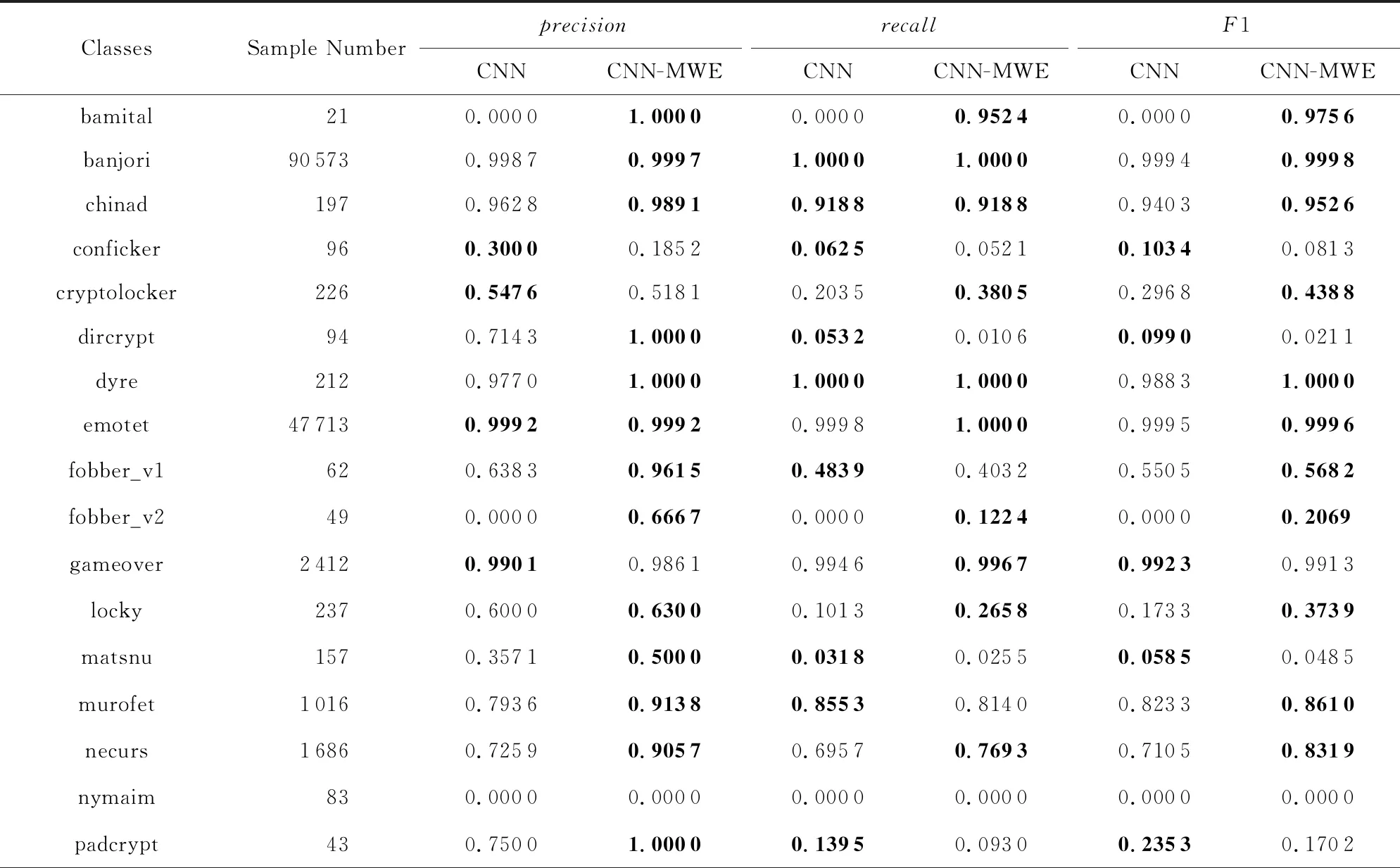
Table 4 Test Results of CNN and CNN-MWE for Multi-Class Classification表4 CNN模型与CNN-MWE模型的多分类实验测试结果
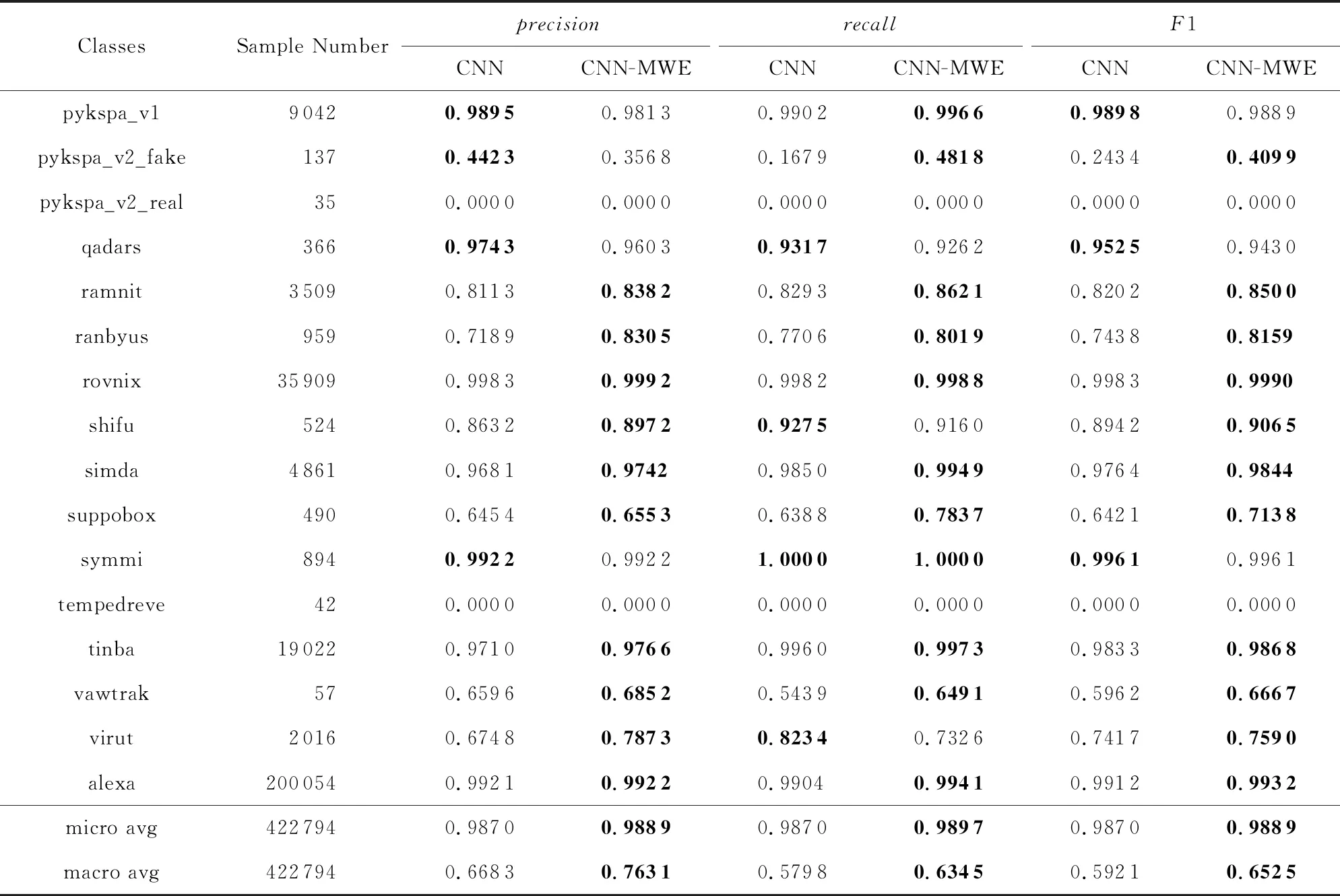
Continued (Table 4)
Notes: The best results for each metric are shown in boldface.
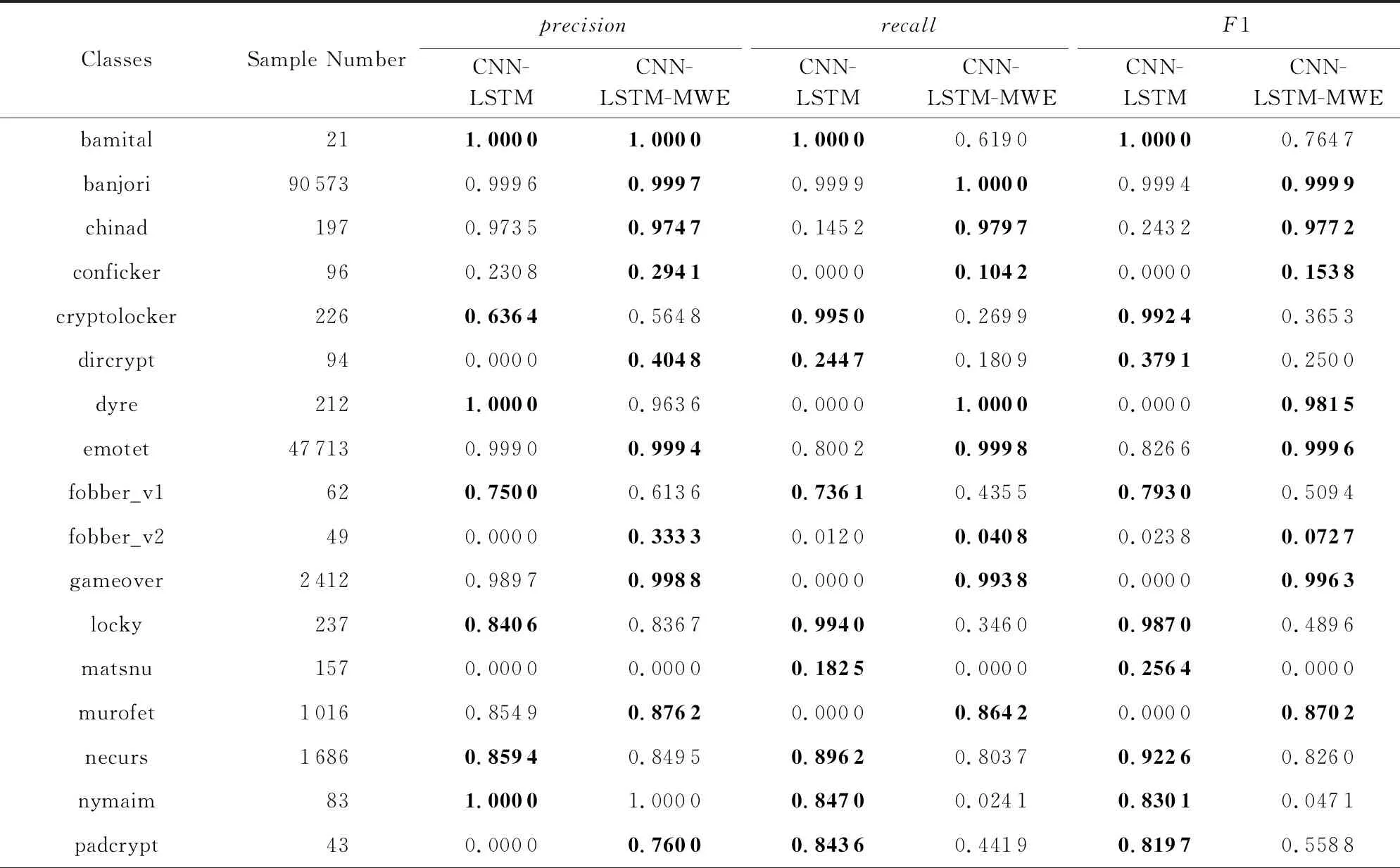
Table 5 Test Results of CNN-LSTM and CNN-LSTM-MWE for Multi-Class Classification表5 CNN-LSTM模型与CNN-LSTM-MWE模型的多分类实验测试结果
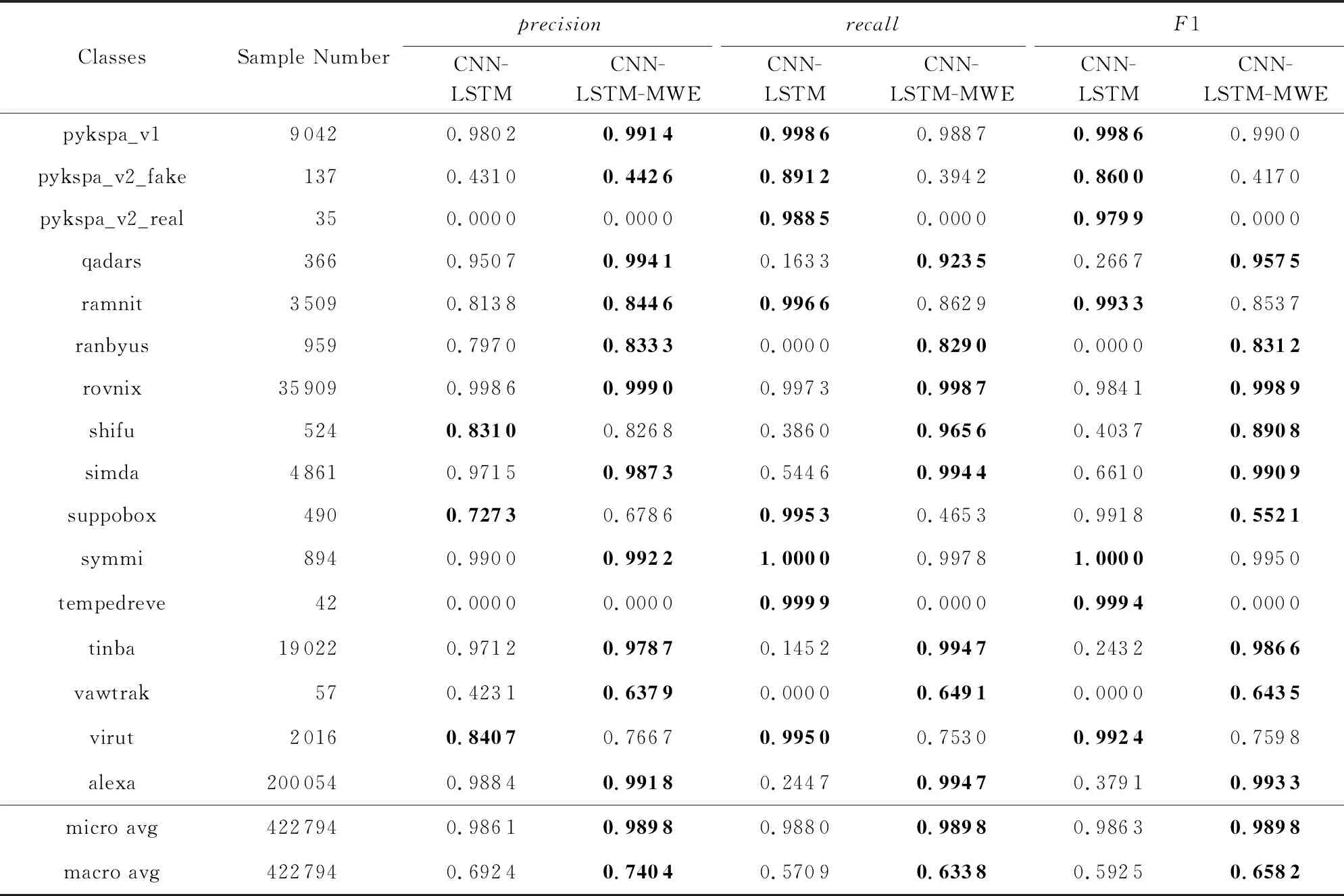
Continued (Table 5)
Notes: The best results for each metric are shown in boldface.
通过实验我们发现,本文使用的CNN-LSTM模型在只使用字符级词向量的实验中,性能表现优于文献[26]提出的LSTM方法,也优于文献[29]提出的CNN方法.在使用混合词向量后,本文使用的CNN-LSTM模型在6种方法中(LSTM,LSTM-MWE,CNN,CNN-MWE,CNN-LSTM,CNN-LSTM-MWE),精确率、召回率和F1值这3种评价指标的微平均和宏平均皆为最优,具有最好的分类性能,说明本文提出的基于混合词向量的深度学习模型是有效的.
此外,CNN和CNN-LSTM两个模型,在使用混合词向量后,零检出域名家族的数目减少.实验证明我们提出的基于混合词向量的深度学习模型有着最好的特征提取能力与分类效果,且在一定程度上缓解了数据不平衡性带来的负面影响.
通过观察CNN-LSTM-MWE模型零检出的3类域名家族的域名数据,我们发现,这些域名家族的数据量过少,而且这些家族的域名字符串本身也有一些特点.其中matsnu家族的域名完全由随机挑选的自然语言中的英文单词和连接线构成,如cause-walk-girlfriend.com,这类域名完全仿照真实的非DGA正常域名,具有很强的隐蔽性,因此从字符和双字母组的分布特征上看,与正常域名十分类似.而另外2个所有模型全部零检出的域名家族,pykspa_v2_real和tempedreve,其具体的域名数据例子如ilihen.net,sxilgdils.com,通过观察可以发现,这些域名的长度较短,能够提供的有效特征相对较少,而且字符串中含有在自然语言的单词中常见的双字母组合,这可能导致了这些域名难以被准确分类.
5 总 结
本文提出了一种基于混合词向量深度学习模型的DGA域名检测方法,该方法首次在DGA域名检测任务中使用混合词向量的并行深度学习架构.针对域名数据的字符分布特点以及不同家族域名数据存在不平衡性的特点,本文设计了字符级词向量与双字母组级词向量,这2类词向量分别可以学习字符级别与双字母组级别的语义信息.本文设计了适用于DGA域名检测的深度学习模型,主要部分由卷积神经网络和LSTM组成.将这2组不同粒度的词向量分别输入至字符级神经网络与双字母组级神经网络后进行特征融合,送入最终的分类器,在DGA域名检测二分类任务中与域名家族的多分类任务中取得了很好的分类效果.本文设计了包括CNN,LSTM,CNN-LSTM等多种深度学习模型的对比模型,通过精确率、召回率、F1值和AUC值等多种评价方法对本模型进行了充分的验证.实验结果表明,本文提出的基于混合词向量深度学习模型的DGA域名检测方法在分类精度方面优于许多已有的基于深度学习的DGA域名检测方法.因此,本文的提出的模型是可行的.
DGA域名家族的多分类任务存在数据不平衡性的问题,本文提出的模型在小样本域名家族的识别上较为明显地优于许多已有的基于深度学习的DGA域名检测方法,在一定程度上缓解了数据不平衡性带来的影响.针对DGA域名检测问题与域名家族多分类问题的研究,未来可从以下2个方面进行深入研究:1)针对DGA域名数据的不平衡性进行深入研究,改进深度学习模型,可考虑多任务学习在DGA域名检测与分类问题上的应用.2)针对DGA域名的深度语义表征方法深入研究,本文提出的方法中双字母组级词向量与经典的字符级词向量提升了模型的分类性能,通过数据学习更好的语义表征将进一步提升模型的多分类效果.提高DGA域名家族的多分类任务的性能表现将提升防御僵尸网络“看得见”的能力,可产生更有价值的威胁情报,对于有力保障网络安全有着重要的实际意义.
