红外与可见光图像融合的空间碎片识别方法
2020-02-18曹云峰庄丽葵
陶 江,曹云峰,庄丽葵,丁 萌
(1.南京航空航天大学航天学院,南京 210016;2.南京航空航天大学民航学院,南京 211106)
0 引言
空间碎片是在轨航天器安全运行的主要威胁。空间碎片是指处于地球轨道或再入大气层中无法正常工作的人造物及其碎片[1],如失效航天器、运载火箭发射阶段产生的火箭残骸、失效航天器碰撞或爆炸产生的碎片均属于空间碎片。上述空间碎片的持续碰撞会进一步加剧其数量增长,从而导致在轨航天器与碎片发生碰撞的概率进一步加大。因此,空间碎片监视对于规避碰撞风险以确保航天器的安全至关重要,而其中的关键在于在轨航天器对空间碎片的精确识别。识别结果又能为下一步对空间碎片的精确跟踪、威胁度评估、碎片清除等技术提供重要依据[2]。因此,关于空间碎片的识别方法研究意义重大。
由于可见光传感器具有成本低、体积小、分辨率高等特点,被广泛应用于天基空间目标监视系统中,如美国天基可见光(Space-Based Visible, SBV)项目[3]、美国天基空间监视(Space-Based Space Surveillance,SBSS)系统[4]、加拿大空间监视系统(Canadian Space Surveillance System,CSSS)[5]等。然而,由于天基监视系统和太阳以及空间碎片之间存在相对运动,导致可见光相机在对空间碎片成像过程中,空间碎片的光照区域呈现出非均匀特性[3],即空间碎片的可见区域会随着光源入射角的变化而变化,从而造成图像源细节部分丢失,这对基于图像的空间碎片识别性能带来巨大挑战。而红外图像对光源入射角度不如可见光图像敏感,并可以记录物体非可见光部分的热辐射信息[7],但其所包含目标的频谱信息和反射特性却不如可见光图像源丰富,如可见光图像中包含丰富的边缘、纹理等细节。因此,将目标的红外图像源和可见光图像源进行深度融合,得到相较于单一图像源细节更加丰富的图像,将更有利于目标识别[8]。
由于可见光和红外图像融合所带来的优势,融合技术被广泛应用于军事侦查、农业自动化、空间探测等领域。根据不同的应用对象和应用背景,各种红外和可见光图像融合方法也相继被提出。总体上,融合方法主要分为两大类:空间域方法,变换域方法。近年来,随着深度学习技术的迅猛发展,基于深度学习的红外和可见光融合方法也取得一定的进展。相较于传统的图像融合方法,基于深度学习的图像融合方法在特征表达和映射方面呈现出巨大优势[10]。例如基于卷积稀疏表示的异源图像融合方法不仅具有较强的细节保留能力,还对异源图像的误匹配具有较强的鲁棒性[11]。这对本文的空间碎片的红外和可见光图像融合具有重要参考价值。
在过去几十年中,空间碎片识别方法也得到了广泛研究,而大多数方法是基于传统的人工特征来训练分类器,如K近邻(k-Nearest Neighbor,KNN)分类器[12]、支持向量机(Support Vector Machine,SVM)[13]等。这些方法的性能严重受限于人工特征设计,且人工特征存在对目标描述不够本质的问题。基于深度学习的空间碎片识别方法研究较少,目前只有西北工业大学提出了基于LeNet-5网络的空间碎片深度学习识别模型[14],然而其验证所用空间碎片图像并未考虑光照因素。本文提出了一种新的基于深度学习的空间碎片识别框架,并采取基于卷积稀疏表示的图像融合方法提高空间碎片识别性能。通过实验对比结果表明,本文的基于卷积稀疏表示的识别模型性能优于基于单一可见光图像的识别方法。
1 空间碎片识别数据库
空间碎片数据库的建立在天基空间目标监视系统研制开发过程中起着重要作用,为载荷参数优化确定以及相关关键技术验证提供了必要的模拟数据源。本文以Apollo-11号探测器作为空间目标模拟失效航天器这一类空间碎片。首先利用三维动画软件3DMAX建立失效卫星的三维几何模型,然后添加光源,设置相机参数,最后利用VRay渲染器对几何模型进行渲染,得到不同光源入射角下的空间碎片可见光图像数据库。空间碎片可见光图像仿真流程如图1所示。
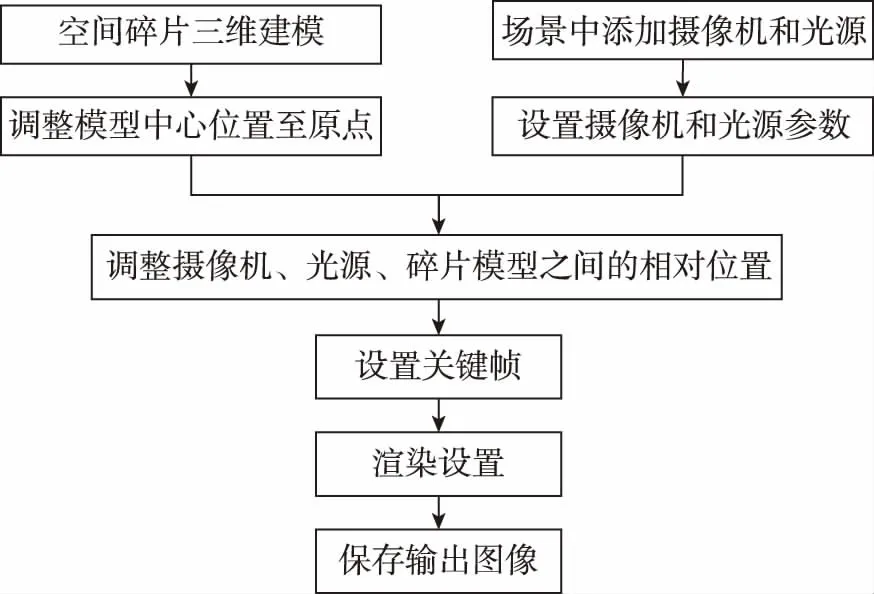
图1 空间碎片可将光图像仿真流程Fig.1 Simulation process of visible image of space debris
空间碎片相应的红外图像数据库由Vega Prime软件仿真模拟得到。在仿真红外图像时,将空间碎片三维模型在Vega Prime软件中调整到和3DMAX同一位置和视角下,则不需经过配准即可通过图像融合得到空间碎片的融合图像。本文融合图像数据库包含100幅融合图像,图像大小为640×480。图2所示为空间碎片在不同光源入射角下的部分融合图像样本。

图2 空间碎片图像数据库部分样本Fig.2 Part of fused image samples of space debris
2 空间碎片识别
本文提出的空间碎片识别框架如图3所示。首先采用基于卷积稀疏表示的方法对空间碎片的可见光和红外图像进行融合得到融合图像;然后基于空间碎片融合图像训练样本通过深度神经网络模型训练得到空间碎片识别模型;最后将空间碎片的融合图像输入识别模型便可得到识别结果。

图3 空间碎片识别框架Fig.3 Scheme of space debris recognition
2.1 基于卷积稀疏表示的图像融合方法
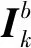
(1)
其中:gx=[-1 1]和gy=[-1 1]T分别为水平方向和竖直方向的梯度算子。η为正则化参数,本文取其经验值5。细节层可通过求解式(2)得到
(2)

(3)
假设Ck,1∶M(x,y)表示稀疏系数图Ck,m在位置(x,y)上的值,则稀疏向量Ck,1∶M(x,y)在每个像素位置上的l1范数作为源图像的活跃度测量。活跃度Ak(x,y)由式(4)得到
(4)
为使图像融合过程对误匹配有较强的鲁棒性,采取对活跃度Ak(x,y)取局部窗口平均值的策略重新计算活跃度,如式(5)所示
(5)
其中,r表示窗口尺寸。对于红外可见光图像融合,需要考虑尺寸较小的细节(如边缘、纹理等),因此r取较小的值更有利,本文取经验值3。采取选择最大策略计算融合系数图
Cf,1∶M(x,y)=Ck*,1∶M(x,y),k*
(6)
然后将所有源图像分解的细节层通过式(7)进行融合重建
(7)
采取平均值策略对各个基础层进行融合重建,以减小各个源图像在同一位置上的灰度值的不一致性问题。则所有源图像分解的基础层按式(8)进行融合重建
(8)
(9)
图4所示为空间碎片的红外和可见光图像融合结果。左图为空间碎片的可见光图像,可以看出空间碎片右边未被光线照射的部分基本没有纹理等细节被反射;中图为空间碎片的红外图像,可以看出其基本不受光照影响,非可见光部分的辐射信息也得到较好呈现;右图为空间碎片的融合图像,可以看出相较于可见光图像,将右半部分的不可见部分的纹理保留下来,左边可见光部分相较于红外图像,细节纹理也更加丰富。

图4 空间碎片红外和可见光图像融合结果Fig.4 Visible and infrared image fusion result of space debris
2.2 基于深度卷积神经网络的空间碎片识别方法
本文提出的深度神经网络架构(Deep Convolutional Neural Networks,DCNN)基于AlexNet[15]模型。DCNN模型由8个带权重参数的层构成,包含5个卷积层和3个全连接层。第1个卷积层由96个11×11×3的卷积核构成,步长为4,输入图像大小为224×224×3;第2个卷积层由256个大小为5×5×48的卷积核构成;第3个卷积层由384个大小为3×3×256的卷积核构成;第4个卷积层由384个大小为3×3×192的卷积核构成;第5个卷积层由256个大小为3×3×192的卷积核构成。3个全连接层每层都由4096个神经元构成。最后的全连接层输出到一个二分类函数softmax中,最终输出每幅图像被分类为某种目标的概率。采取修正线性单元(Rectified Linear Units,ReLUs)作为每个卷积层和全连接层的激活函数。ReLUs的表达式如下
f(x)=max(0,x)
(10)
其中,x和f(x)分别表示某个神经元的输入和输出。第1个卷积层和第2个卷积层后分别添加一个响应归一化层。响应归一化的活跃度由式(11)表示
(11)

由于本文建立的空间碎片图像数据库只有1000幅图像,在训练过程中可能存在训练数据不足导致的过拟合问题。为此,首先对空间碎片图像数据库采取标签保留转换[16]方式进行数据增强。包括对图像进行水平翻转和垂直翻转。此外,本文还考虑对图像添加亮度变化以增强数据。由于在不同光源入射角照射下,空间碎片目标本身的可见区域也随之变化,从而导致图像本身的亮度也会随之变化。因此,添加亮度变化对于防止本文光照不均匀环境下识别模型的过拟合有利。此外,由于空间碎片具有翻滚特性,其姿态也不断变化,因此,通过对空间碎片图像进行旋转来增强数据。首先对原始100幅空间碎片图像进行水平和垂直翻转得到200幅图像;然后对原始图像数据集每幅图像每隔36°旋转1次,共旋转10次,得到1000幅图像;通过Gamma矫正的方式实现图像亮度变化,取gamma值由0.1间隔0.1变化到1得到1000幅图像。图5所示分别为gamma=0.3和0.8时的图像。最终通过数据增强得到2200幅图像,将其中的1500幅图像作为训练样本,700幅作为测试样本。

(a) gamma=0.8

(b) gamma=0.3图5 空间碎片图像亮度变化Fig.5 Image brightness changes of space debris
3 仿真验证
首先对基于卷积稀疏表示的图像融合方法进行仿真验证,并与基于稀疏表示(Sparse Representation,SR)的融合方法进行对比。本文对空间碎片图像数据库的100幅源图像进行融合对比实验,采取主观评价方法和客观评价方法两种方式对融合效果进行评估。主观评价方法是指目视评估法,即直接通过肉眼对融合图像的质量进行评估。CSR和SR两种融合方法的部分结果如图6所示。从图6中可以看出,CSR融合方法比SR方法能从源图像中提取出更多的细节。

(a) SR

(b) CSR图6 空间碎片图像融合方法性能对比Fig.6 Comparison of different image fusion method
此外,选取了四种常用的图像融合客观评价指标对空间碎片的可见光和红外图像融合算法性能进行评估分析。这四种指标分别为:熵EN(Entropy),表征图像包含的信息量和纹理丰富程度,值越大,信息量越多;标准差(Standard Deviation,STD),表征图像亮度,值越大,图像对比度越大,即灰度级越分散;平均梯度(Average Gradient,AG),表征图像锐度,值越大,表明图像信息量越丰富;空间频率(Spatial Frequency,SF),表征图像清晰度,值越大,表明图像纹理和边缘细节越丰富。对比结果如表1所示。从表1中可以看出,CSR融合方法的图像的细节丰富程度均优于SR融合方法。
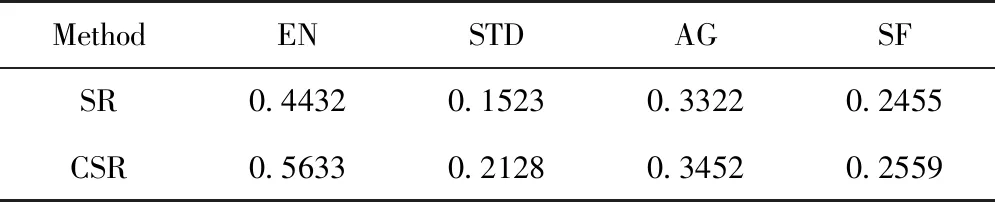
表1 图像融合客观评价指标对比Tab.1 Objective metrics comparison for image fusion methods
经试验,在小数据集上随机梯度下降法(Stochastic Gradient Descent,SGD)收敛速度比Adam慢但收敛性能更好,本文的深度神经网络采用SGD进行迭代优化。考虑到计算机内存等性能因素,选取小批量训练样本,将batch size设为64。为加快收敛速度并减小SGD震荡,设置动量(momentum)为0.9。考虑本文的网络深度,将权重衰减(weight decay)为0.0005即可。学习率设为0.001,迭代训练50次后停止训练。由于本文训练集不大,采用dropout正则化来减轻过拟合,具有较好的效果,将隐藏层的采样概率设为经验值0.5。训练过程如图7所示,当迭代至20次左右时,训练精度和训练损失均已收敛。收敛较快的原因有三方面:1)空间碎片本身目标特性(如纹理、颜色、形状、大小等)明显,对深度特征的学习与提取比较有利;2)空间碎片图像背景相对简单,没有其他天体和杂波干扰,这对于分类器的区分度量也较为有利;3)训练样本相对较少,图像数据为单通道图像且分辨率不高,也减少了训练时间。对可见光图像数据和融合图像数据分别进行训练得到2个深度学习模型进行对比,二者训练超参数设置相同。此外,本文的深度学习模型还与文献[14]提出的LeNet-5模型以及文献[13]提出的基于SVM的方法进行了对比,对比实验结果如表2所示。从表2中可以看出,本文提出的深度学习模型对空间碎片的识别性能优于LeNet-5模型和基于SVM的方法,识别正确率可达99.93%。此外,融合图像训练得到的识别模型性能均优于单一可见光图像训练得到的识别模型。

图7 深度卷积神经网络训练过程Fig.7 Training process of different deep convolutional neural network

表2 空间碎片识别方法对比实验结果Tab.2 Experiment results comparison of space debris recognition methods
4 结论
本文针对暗弱空间环境中的空间碎片识别问题,提出了一种基于深度卷积神经网络的空间碎片识别框架。算法分析与实验结果表明:
1)通过对空间碎片图像数据集进行数据增强,可减轻训练过程中的过拟合现象。本文针对空间碎片光照区域不均匀这一特点,通过对原始图像数据集调节亮度来增强数据集,可提高对光照不均匀条件下的空间碎片识别性能。
2)在暗弱空间环境中,通过对空间碎片的红外和可见光图像进行融合,然后再进行识别的方案,相较于基于单一可见光图像的识别方案识别性能更好。这是因为融合图像不仅包含了红外图像中的热辐射特征,也包含了可见光图像高分辨率的细节特性,相较于单一图像源所含信息量更丰富,这对于基于深度学习的识别模型是有利的。
3)在实际空间环境中,空间碎片图像背景可能包含太阳、行星、地球等其他天体,以及噪声干扰。而本文图像数据库图像背景为纯色背景,在实际应用过程中可能会存在识别性能下降问题。因此需要进一步完善图像数据库,添加典型背景噪声干扰,使其更具通用性。
