基于双曲正切函数的修正线性单元
2020-02-14刘坤华钟佩思徐东方
刘坤华,钟佩思,徐东方,夏 强,刘 梅
(山东科技大学 先进制造技术研究中心,山东 青岛 266590)
0 引言
近年来深度学习理论[1]在图像识别[2-3]、图像检测[4]、语音识别[5-7]、唇语识别[8-9]等方面均取得了丰硕的研究成果,提高了人工智能水平。深度学习理论之所以取得瞩目的成绩,其部分原因在于:深度学习网络架构的改进[3-4,11]、计算机硬件的改进、激活函数的改进[12-14]、优化算法的改进[15-17]等。其中,激活函数的改进是深度学习理论取得瞩目成绩的一个重要原因。激活函数起源于逻辑回归,为了将线性的净输入量转变成一个拥有良好特性的非线性方程,定义净输入量z通过一个非线性逻辑S型函数,从而得到条件概率P(y=1|x),该非线性函数称为激活函数。激活函数的数学定义来源于2016年加拿大蒙特利尔大学的Bengio教授[12]:激活函数是映射h:R→R,且几乎处处可导。
最早出现的激活函数为Sigmoid函数(式(1))和tanh(tangent)函数(式(2)):
(1)
(2)
Sigmoid函数可以被表示作概率,或用于输入的归一化,且求导容易。但是Sigmoid函数具有软饱和性[13],在其反向传导过程中,一旦落入软饱和区,其倒数将接近于0,梯度下降减小,最终造成梯度消失。Glorot等[14]表明5层的神经网络就会出现梯度消失的情况。此外,Sigmoid函数会出现偏移现象,即其输出均大于零,而不是零的均值。这将导致其下一层神经元得到的输入不是零均值信号,从而造成信号丢失。
tanh函数如式(2)所示,同时其也可以用Sigmoid函数进行表示:tanh(x)=2sigmod(2x)-1。其值域在[-1,1]区间内,也具有软饱和性。相比于Sigmoid函数,其优点在于收敛速度更快[18-19],输出为0均值;缺点在于由于软饱和性的存在,仍存在梯度消失现象。同时,tanh函数只能训练较浅的神经网络[13]。
近年来,深度学习网络中经常使用的函数为修正线性单元(Rectified Linear Unit, ReLU)函数:
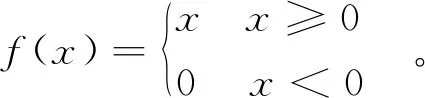
(3)
ReLU函数由Nair等[20]于2010年为限制的玻尔兹曼机提出,2011年被Glorot等[21]首次应用到了深度学习神经网络。ReLU函数提供了稀疏表达能力,其正半轴不存在梯度消失现象。文献[2]表明,ReLU比起tanh在随机梯度下降法(Stochastic Gradient Descent, SGD)中具有更快的收敛性,更快地到达了错误率0.25处。但是在x<0时,ReLU函数硬饱和(切掉了输入信号的所有具有负数的特征),会造成权重无法更新,从而出现神经元死亡现象。
为了缓和ReLU函数在x<0时出现的神经元死亡现象,学者们在ReLU函数的基础上进行了许多改进。2013年,Mass等[22]提出了泄露修正线性单元(Leaky Rectified Linear Unit, LReLU)函数,2015年He等[4]提出了参数化修正线性单元(Parametric Rectified Linear Unit, PReLU)。LReLU函数与PReLU函数的公式如式(4)所示:
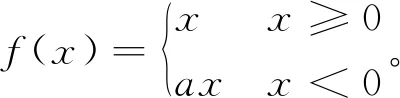
(4)
LReLU函数与ReLU函数相比,设计斜率a增加了负半轴特性,减少了神经元死亡现象,但是在训练时需要多次训练选择合适的斜率a来获得良好的性能。与LReLU函数相比,PReLU函数的斜率a不需要人为设置,而是通过神经网络学习得到,使得PReLU函数更具有柔性。2013年,Goodfellow等[23]提出了Maxout函数:
(5)
Maxout函数是ReLU函数和LReLU函数的另一种变形形式,其具有很强大的拟合能力,能够近似任意连续函数。因此。Maxout函数具有ReLU函数和LReLU函数的优点:计算简单,不会出现饱和,减少了神经元死亡现象,但是其缺点为加倍了参数,增大了计算量。Goodfellow等[23]将Maxout函数和dropout结合后,在MNIST、CIFAR-10、CIFAR-100和SVHN,4个数据上都取得了前所未有的识别率。
带泄露随机修正线性单元(Randomized Leaky ReLU,RReLU)的公式与PReLU函数和LReLU函数一样,即式(4),其最早应用于Kaggle NDSB(National Data Science Bowl)竞赛,在数据集训练过程中,随机设置斜率,在验证过程中,则固定斜率的数值。该赛事表明:随机设置斜率可以降低过拟合现象。Xu等[24]在CIFAR-10、CIFAR-100和NDSB数据集中验证了ReLU函数、LReLU函数、PReLU函数和RReLU函数,结果表明RReLU函数的错误率最低。
Clevert等[25]于2016年提出ELU函数:
(6)
ELU函数和ReLU、LReLU、PReLU一样可以减少梯度,但同时ELU函数增加了学习功能[25]。Li等[26]的试验表明基于CIFAR-10数据集,ELU函数的损失降低速度更快;在基于ImageNet数据集,批量归一化操作30层以上的神经网络时,ReLU函数会无法收敛,PReLU函数在MSRA的Fan-in(在Caffe框架上训练的模型)初始化下会发散,而ELU函数在Fan-in/Fan-out下都能收敛。
2017年,Li等[26]提出了多参数指数线性单位(Multiple Parametric Exponential Linear Unit,MPELU)函数:
(7)
MPELU函数结合了PReLU函数和ELU函数。设置α可学习能够提高性能,引入参数β能够进一步控制ELU的函数形状。当α,β固定为1时,MPELU退化为ELU;β固定为很小的值时,MPELU近似为PReLU;当α=0,MPELU等价于ReLU,
MPELU=max(ReLU,PReLU,ELU)。
(8)
由以上分析可知,Sigmoid函数和tanh函数在神经网络中得到正确率较低,不适用于深层的神经网络架构。ReLU函数模拟人类神经元功能,可以提高神经网络的性能;其正半轴不存在梯度消失现象,但是负半轴存在神经元死亡现象。除Sigmoid函数和tanh函数外,大部分激活函数均由ReLU函数发展而来,解决目标均为减轻ReLU函数的神经元死亡现象。
1 基于tanh函数的修正线性单元(ThLU函数)定义
为减轻ReLU函数的神经元死亡现象,本文基于ReLU函数的正半轴不存在梯度消失现象和tanh函数的负半轴可以减轻神经元死亡现象,提出了一个新的激活函数:基于tanh函数的修正线性单元(Tangent-Based Rectified Linear Unit, ThLU),其定义如式(9)所示:
(9)
ThLU函数的负半轴来源于tanh函数的负半轴,正半轴来源于ReLU函数的正半轴。
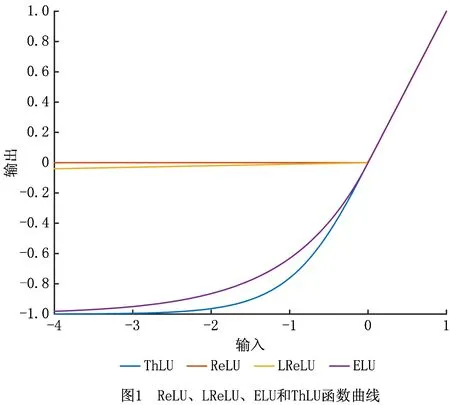
ReLU函数、LReLU函数和指数线性单元(Exponential Linear Unit,ELU)函数是卷积神经网络中常用的激活函数。为了更直观地分析ThLU函数,本文对ReLU函数、LReLU函数(α=0.01)、ELU函数(α=0.25)和ThLU函数进行了比较分析。以上各函数的图像如图1所示。由图1可以看出,当x≥0时,ThLU函数的正半轴输出与ReLU函数、LReLU函数、ELU函数的输出一样,均等于输入的值。当x<0时,在同样输入的情况下,ReLU函数、LReLU函数、ELU函数和ThLU函数的输出均小于零;且ThLU函数的输出小于ELU函数的输出,小于LReLU函数的输出,小于ReLU函数的输出。因此,从整体输出上分析,ThLU函数的输出优于ReLU函数,LReLU函数和ELU函数,更接近0均值。
2 试验分析
为验证ThLU函数的性能,本文基于VggNet-16神经网络架构,在CIFAR-10数据集和CIFAR-100数据集上对tanh、ReLU、LReLU、ELU和ThLU函数分别进行了试验。CIFAR-10数据集[27]是Alex Krizhevsky、Vinod Nair和Geoffrey Hinton于2009年收集的一个数据集,是学术界用来训练验证神经神经网络架构的一个重要数据集。CIFAR-10数据集包含10类共60 000个32×32的彩色图像。CIFAR-100数据集[27]由CIFAR-10数据集上发展而来,具有20个大类物品,其中20个大类又分为100个小类。每小类包含600个图像,包含500个训练图像和100个验证图像。
由于CIFAR-10数据集和CIFAR-100数据集的图像大小均为32×32,因此,设置试验1和试验2具有相同的神经网络参数(表1)。神经网络均选择随机梯度下降法(SGD)作为优化算法。试验平台为OS X EI Capitan系统,Intel Core i5主板,8 G内存,TensorFlow为1.2.1CPU版本。
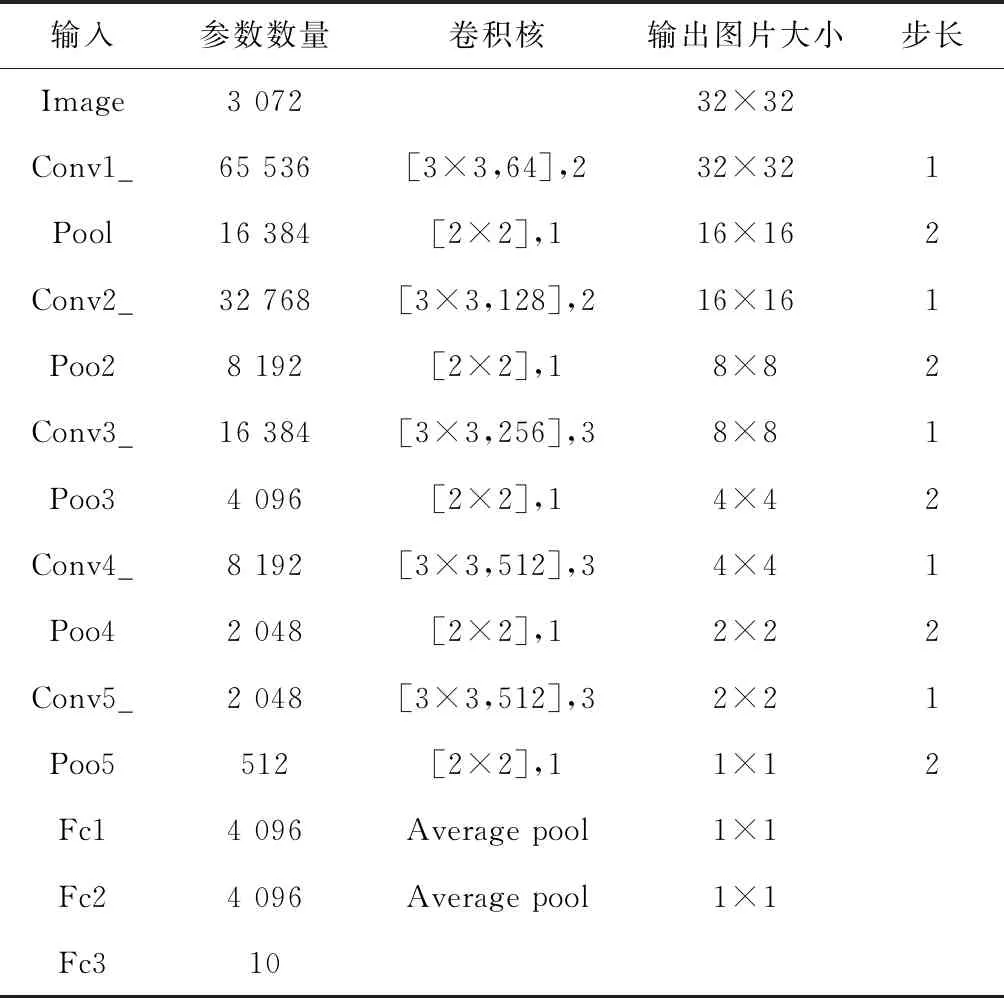
表1 参数设置
试验1基于VggNet-16神经网络架构和CIFAR-10数据集的试验。
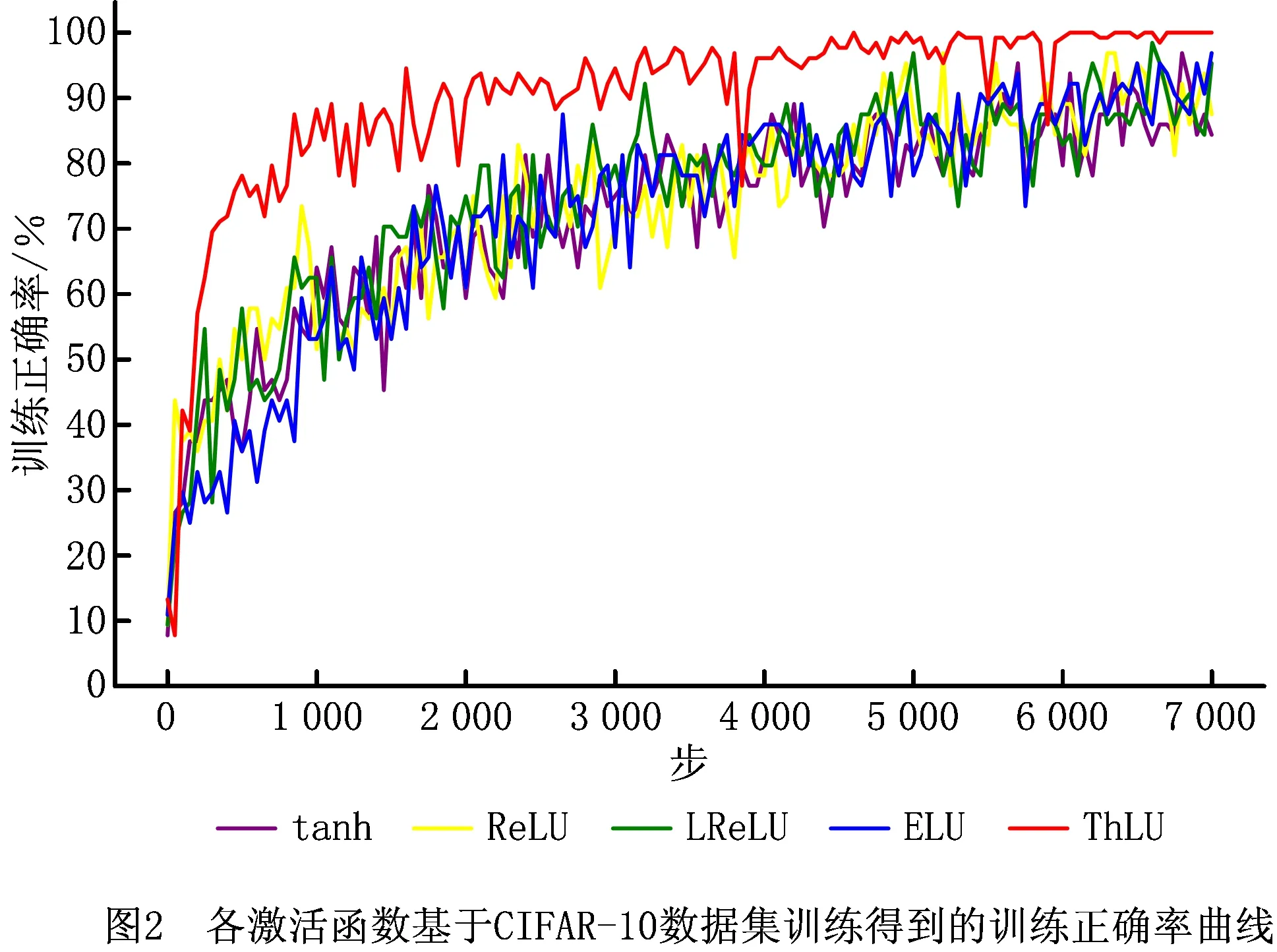
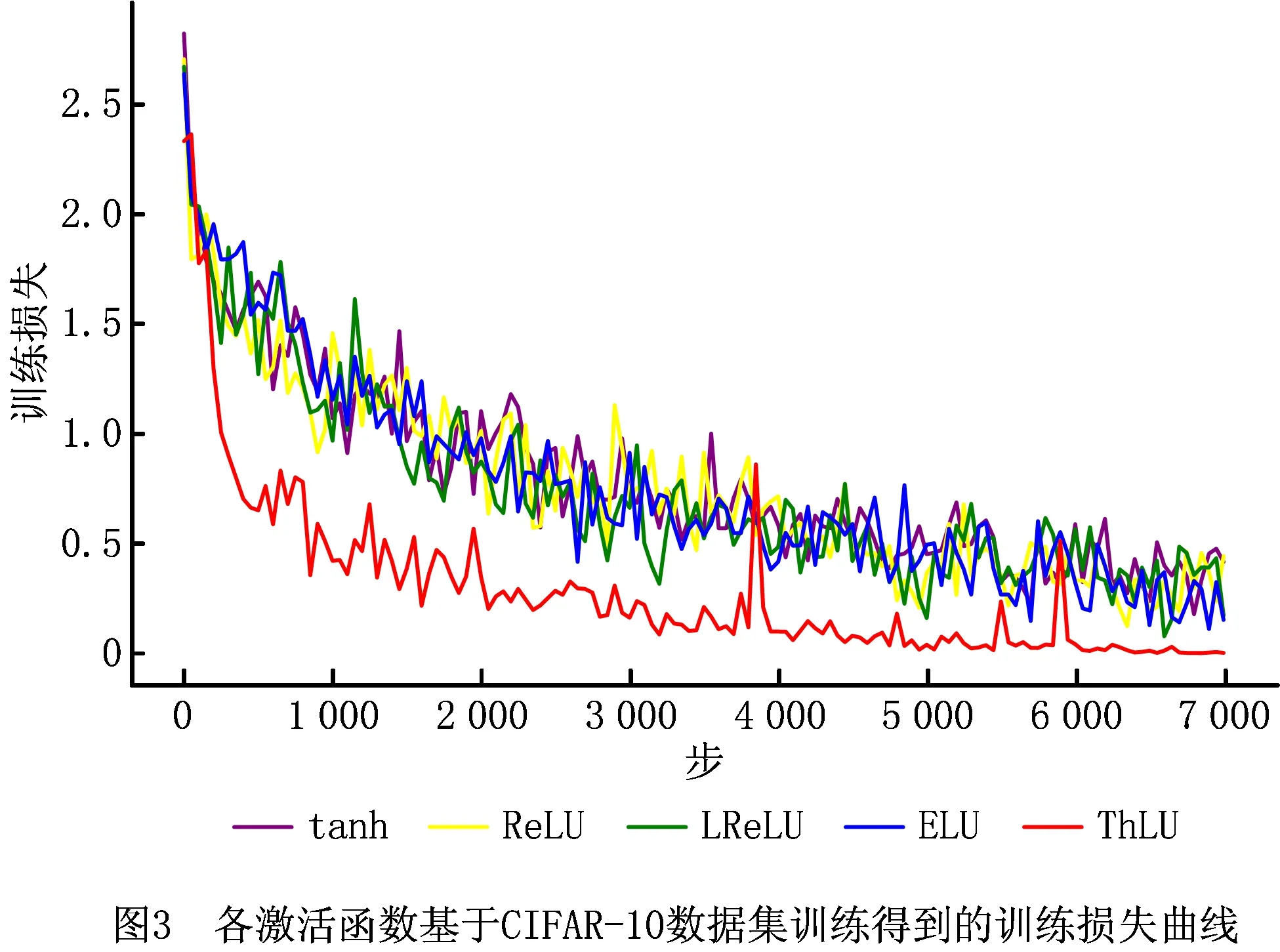
设置神经网络训练时批量大小为64,最大步数为7 000。各激活函数基于CIFAR-10数据集训练得到的训练正确率曲线、训练损失曲线如图2和图3所示。由图2和图3可知,在训练过程中,基于ThLU函数训练得到的训练正确率,高于基于tanh函数、ELU函数、LReLU函数和ReLU函数训练得到的训练正确率,在6 200步左右基于ThLU函数训练训练得到的正确率即可达到100%;基于ThLU函数训练得到的训练损失,低于基于tanh函数、ELU函数、LReLU函数和ReLU函数的训练损失。各激活函数经过7 000步训练后,其最高训练正确率和最低训练损失如表2所示。
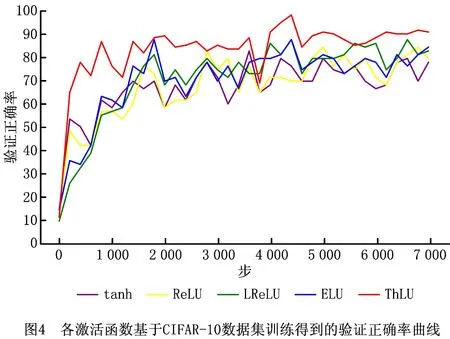
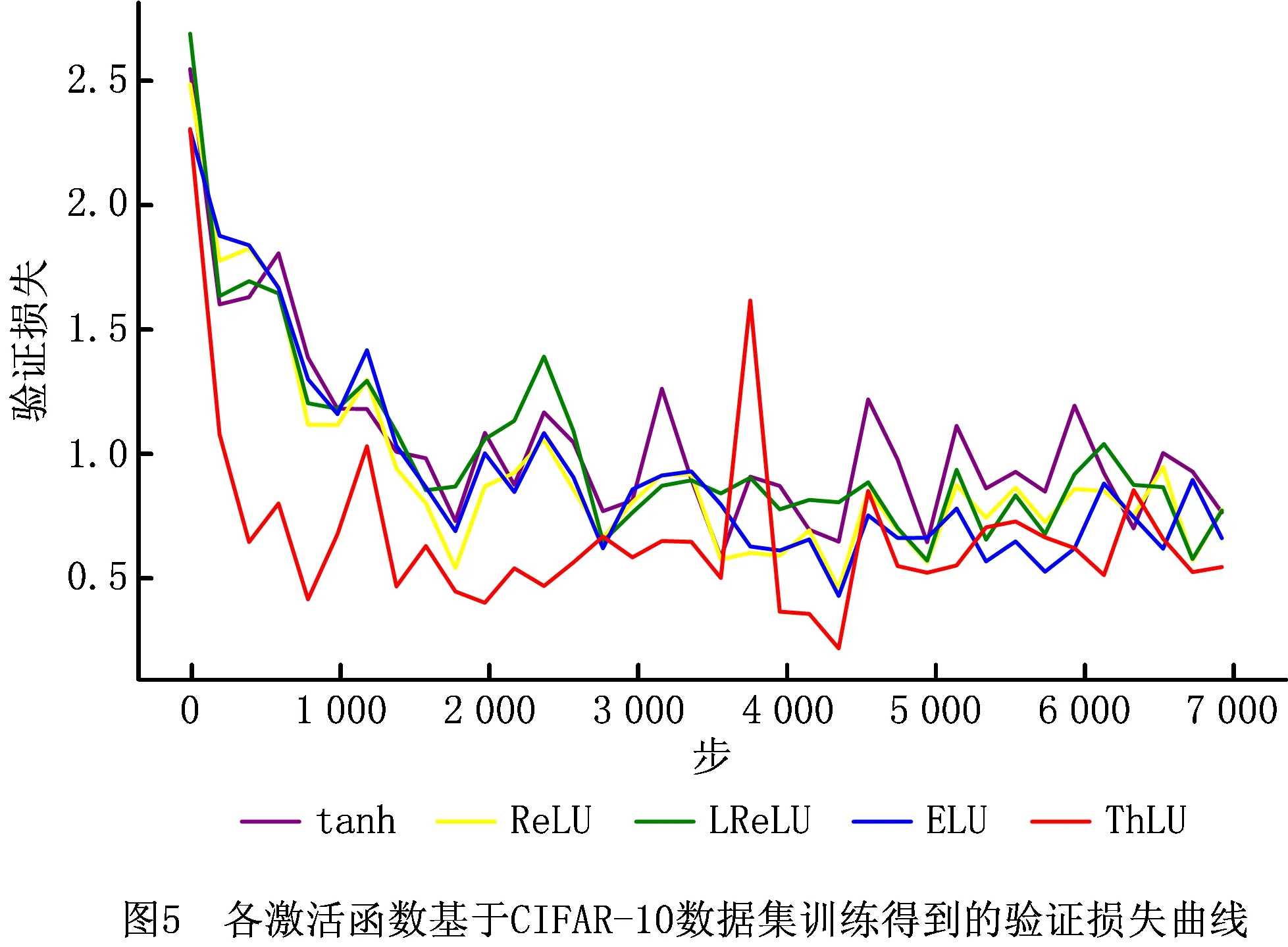
各激活函数基于CIFAR-10数据集训练得到的验证正确率曲线、验证损失曲线如图4和图5所示。由图4和图5可知,基于ThLU函数得到的验证正确率高于基于tanh函数、ELU函数、LReLU函数和ReLU函数得到的验证正确率;基于ThLU函数得到的验证损失低于基于tanh函数、ELU函数、LReLU函数和ReLU函数得到的验证损失。各激活函数经过7 000步训练后,其最高验证正确率和最低验证损失如表2所示。
本文对各激活函数基于CIFAR-10数据集训练得到的神经网络模型在9 984个数据上进行了测试,基于ThLU函数、ELU函数、LReLU函数、ReLU函数和tanh函数训练得到的神经网络模型测试正确率(表2)分别为:85.61%、78.01%、71.56%、70.26%和69.40%;测试损失分别为:0.001 8、0.264 1、0.462 8、0.632 7和0.897 1。此外,各神经网络模型的训练时间分别为:12 h 56 min、19 h 41 min、18 h 9 min、6 h 23 min和6 h 29 min。

表2 各激活函数基于CIFAR-10数据集的结果总结
由以上分析可知,在基于CIFAR-10数据集和VggNet-16神经网络架构上,基于ThLU函数训练的神经网络模型比基于ELU函数、LReLU函数、ReLU函数和tanh函数训练的神经网络模型可以得到更高的正确率和更低的损失。但是,从模型的训练时间分析,基于ThLU函数的模型训练时间小于基于ELU函数和LReLU函数训练时间,却大于基于ReLU函数和tanh函数的模型训练时间。
试验2基于VggNet-16神经网络架构和CIFAR-100数据集的试验。
设置神经网络训练时批量大小为64,最大步数为10 000。各激活函数基于CIFAR-100数据集训练得到的训练正确率曲线、训练损失曲线如图6和图7所示。由图6和图7可知,在训练过程中,基于ThLU函数得到的训练正确率,高于基于ELU函数、LReLU函数、ReLU函数和tanh函数得到的训练正确率;基于ThLU函数得到的训练损失,低于基于ELU函数、LReLU函数、ReLU函数和tanh函数得到的训练损失。各激活函数经过10 000步训练后,其最高训练正确率和最低训练损失如表3所示。
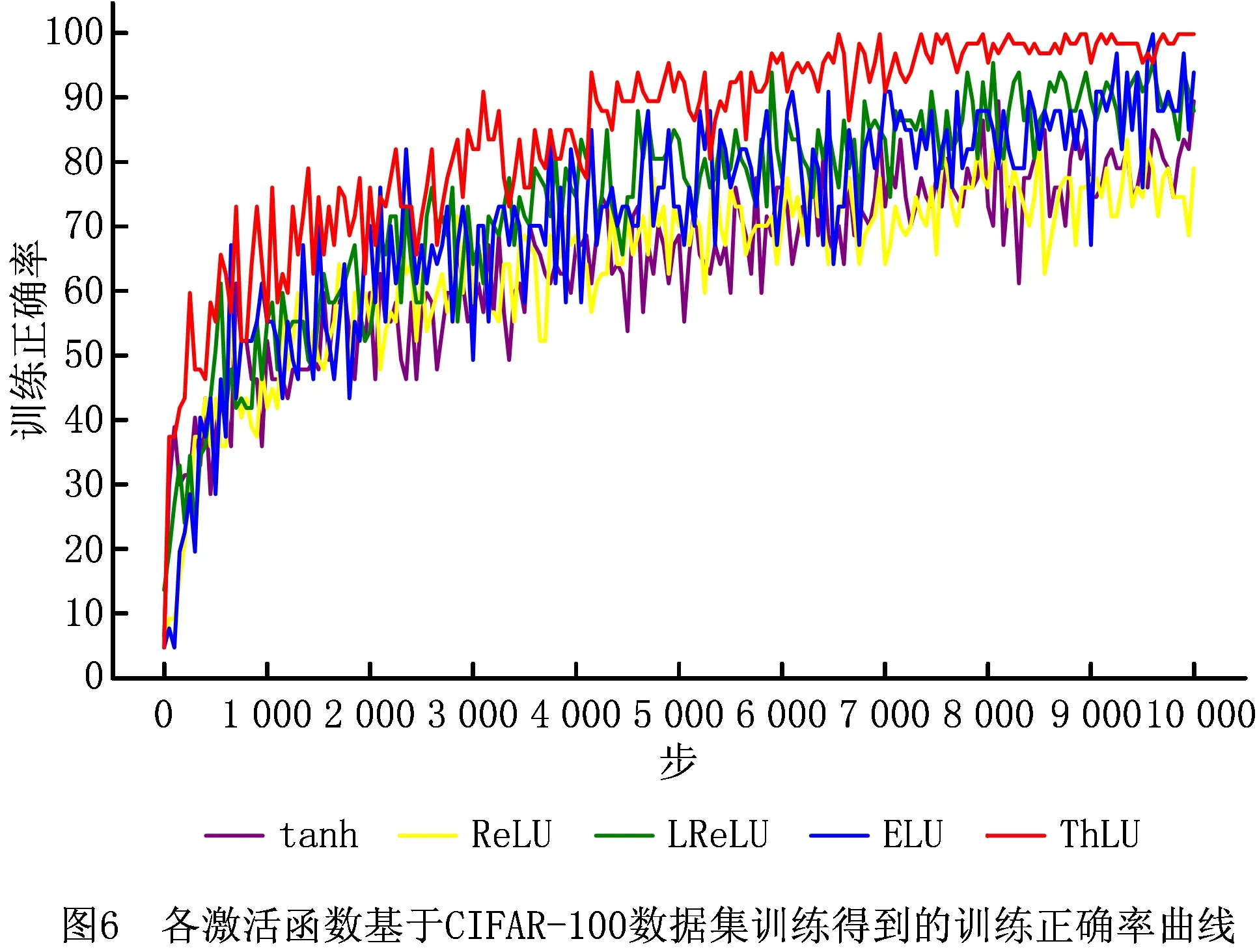

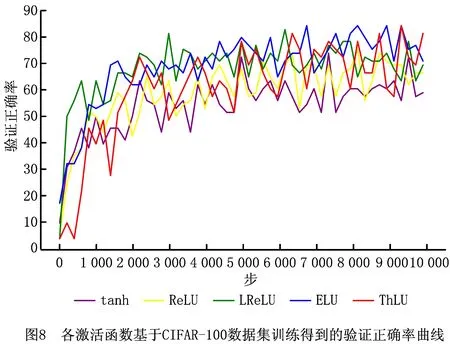
各激活函数基于CIFAR-100数据集得到的验证正确率曲线、验证损失曲线如图8和图9所示。由图8和图9可知,基于ThLU函数得到的验证正确率高于基于ELU函数、LReLU函数、ReLU函数和tanh函数得到的验证正确率;基于ThLU函数得到的验证损失低于基于ELU函数、LReLU函数、ReLU函数和tanh函数得到的验证损失。各激活函数经过10 000步训练后,其最高验证正确率和最低验证损失如表3所示。

本文对各激活函数基于CIFAR-100数据集训练得到的神经网络模型,在9 984个数据上进行了测试。基于ThLU函数、ELU函数、LReLU函数、ReLU函数和tanh函数训练得到的神经网络模型的测试正确率(表3)分别为:79.67%、68.68%、67.69%、64.29%和57.78%;测试损失分别为:0.801 7、0.854 6、1.472 8、1.642 5和1.784 6。此外,各神经网络模型的训练时间分别为:18 h10 min、1 d 0 h 51 min、21 h 43 min、10 h 10 min和10 h 58 min。

表3 各激活函数基于CIFAR-100数据集的结果总结
通过以上两个试验表明:基于CIFAR-10数据集和CIFAR-10数据集,通过VggNet-16神经网络架构训练得到的神经网络模型,无论是从正确率、损失和训练时间上分析,ThLU函数的性能均优于ELU函数和LReLU函数;与ReLU函数和tanh函数相比较,ThLU函数在正确率、损失上得到的结果优于ReLU函数和tanh函数,但是同时其训练时间高于ReLU函数和tanh函数。
3 结束语
为了改善ReLU函数的神经元死亡现象,本文基于ReLU函数的正半轴不存在梯度消失现象和tanh函数的负半轴可以减轻神经元死亡现象,提出了一个新的激活函数:基于tanh函数的修正线性单元(ThLU函数)。为验证ThLU函数的性能,基于CIFAR-10数据集和CIFAR-100数据集,通过VggNet-16神经网络架构对tanh函数、ReLU函数、LReLU函数、ELU函数和ThLU函数分别进行了试验。结果表明基于ThLU函数训练得到的神经网络模型比基于tanh函数、ReLU函数、LReLU函数、ELU函数训练得到的神经网络模型具有更好的正确率、更低的损失,即ThLU函数可以减轻ReLU函数的神经元死亡现象,是一个高效的激活函数。在未来的研究中,期望可以发展更有效的激活函数,进一步减轻神经元死亡现象,提高模型正确率。
