深度学习在文本生成中的应用研究
2020-02-14郭腾州孙宝山
郭腾州,孙宝山
(天津工业大学 计算机科学与技术学院,天津 300387)
早期的文本生成技术,由于受到技术的限制没能得到充分发展。文本生成就是以图像、文本、数据等作为输入,通过特定的处理、输出得到人们想要的文本的过程[1]。文本生成技术近几年发展迅速,为人们的生活提供很多便利[2]。
1 深度学习概述
1.1 深度学习介绍
深度学习是机器学习研究领域的一个新的研究方向,它被引入机器学习使其更接近最初的目标——人工智能[3]。深度学习是学习样本数据的内在规律和表示层次,这些通过学习获得的信息对解释数据有很大帮助,例如文字、图像和声音。其目标是让机器能够无限接近于人的分析学习能力[4]。目前,深度学习在语音和图像识别方面已取得显著成就[5]。
1.2 卷积神经网络(CNN)
卷积神经网络(CNN)是一种前馈神经网络,具有卷积计算和深度结构。卷积神经网络可以将特征显现出来,能将输入信息进行分类且不改变其阶层结构[6]。卷积神经网络对于图片处理具有良好的性能,其构建机制就是通过对生物的视觉模仿[7]。卷积神经网络在计算机视觉领域具有显著地位,在许多自然语言处理领域的很多任务中也起着至关重要的作用。但卷积神经网络并不是完美的,它有两个危险的缺陷就是平移不变性和池化层。
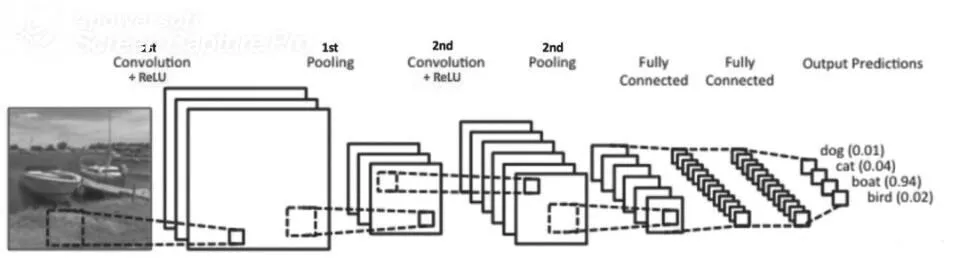
图1 卷积神经网络流程图Fig.1 Convolutional neural network flowchart
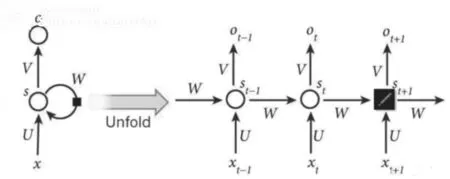
图2 递归神经网络Fig.2 Recurrent neural network
1.3 循环神经网络(RNN)
循环神经网络(RNN)是将列数据作为输入,顺着序列的传播方向进行链式递归的递归神经网络[8]。长短式记忆网络(LSTM)和双向循环神经网络(Bi-RNN)是常见的循环神经网络,循环神经网络具有记忆性、参数共享并且图灵完备。因此,在对序列的非线性特征进行学习时具有一定优势[9]。自然语言数据是典型的序列数据,所以对序列数据学习有一定优势的循环神经网络在NLP 问题中得以应用。
由于现实中的许多任务需要之前输入的计算信息,例如,文本生成中根据某关键字来预测整个文本的意思,最好知道之前有哪些词或者句子出现过。递归神经网络(见图2)主要用于预测序列模型,可以多方位、深层次地对整个文本加以理解,有助于人们更好地研究。递归神经网络是循环神经网络(见图3)的推广。
2 文本生成相关任务
2.1 词性标注
词性标注(Parts-Of-Speech,POS)是文本生成诸多任务中的其中一个,它被定义为将特定的词性标记分配给句中每个单词的过程。词性标记可以识别一个单词是否为名词、动词、还是形容词等。词性标注在各种问题上都会有所应用,例如信息检索、机器翻译、NER、语言分析等。
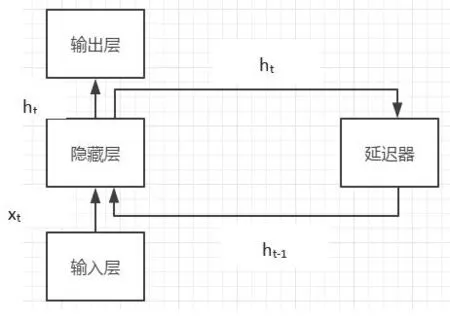
图3 循环神经网络Fig.3 Recurrent neural network
2.2 语法解析
语法解析(也被称作句法分析),是文本生成中的任务之一。其被定义为:一个检查用自然语言书写的字符序列是否合乎正式语法中所定义的规则的过程。它是一个将句子分解为单词或短语序列,并为其提供特定的成分类别的过程。
2.3 语义分析
语义分析是文本生成中的任务之一,它被定义为确定字符或单词序列的意义的过程,可以用于执行语义消歧任务。在分析一个给定的句子时,如果已经构建了句子的句法结构,那么这个句子的语义分析就算完成了。
2.4 情感分析
情感分析是文本生成中的众多任务之一,它被定义为确定一个字符序列背后所隐含的情感信息的过程。情感分析可用于确定表达文本思想的演讲者或者人们的心情是愉快还是悲伤的,或仅代表一次中性的表达。2017 年提出中文情感分类的概念,主要是基于卷积控制块概念。他用的方法就是将句子看作一个个体单位,基于卷积控制块的模型,对比各种时期上下文的依赖性进行情感分类,将单一句子的分词放置5 层卷积控制块中进行试验,最终得到92.58%的准确率。
3 文本生成
3.1 数据获取
基于深度学习的文本生成技术中,由于深度学习需要大量的数据,所以数据获取是文本生成的一个重要的环节。其中,数据的形式也在随着时间的推移不断改变,从结构化数据变为半结构化数据。同样地,也有许多对于非结构化的研究[10]。各个研究领域都会有自己体系的数据获取方法。目前的文本生成技术中,由于语料库的规范问题导致构建比较困难,所以到现在为止还没有固定的文本语料库。
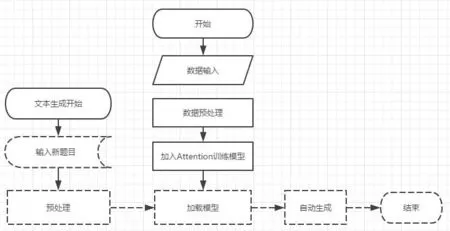
图4 文本生成流程图Fig.4 Text generation flowchart
3.2 数据预处理
在文本生成过程中,将给定的语句分解为词向量或者句子向量,为方便生成模型识别和计算。其中,中文语料需要将其进行分词。之前的one-hot 词向量对于表示语法和语义效果不足,所以现在大多数人都采用词分布式表示,它可以更好地表示词到向量空间的逻辑关系。
3.3 注意力机制
简单地说,就是将注意力放在重要的地方,将其他次重要或不重要的因素忽略。Attention 分为空间注意力和时间注意力,空间注意力用在图像处理,时间注意力则是使用在自然语言处理问题中。由于在Seq2seq 模型中,encode过程产生的保存原来语义信息的中间向量C 是固定长度的,所以当输入原序列的长度比较长时,向量C 无法将全部的信息保存下来,很大程度上限制了上下文语义信息,也使模型的理解能力下降[11,12]。因此,使用Attention 机制来打破这种原始编解码模型对固定向量的限制。
3.4 文本生成流程图(见图4)
4 文本生成测评
文本生成需要一个标准来规范,所以文本生成的测评是文本生成不可缺少的重要组成部分。一个高质量的文本生成机制,必定会有一个优秀的文本生成测评。有两个因素可以影响文本生成质量——变化的输入和输出的未知。文献阐述了文本生成的测评内容,其主要分为内部测评和外部测评。
4.1 内部测评
内部测评主要是对系统内部进行测评,严格来讲就是对生成的文本质量的测评。例如,生成的文本是否具有统一性、完整性等,大致分为主观测评和客观测评。主观测评是指生成的文本遵循语言原则,且可读性和准确性强;客观测评是指生成的文本通过数据库,使用机器来客观测评。到目前为止,人们还没有研发出来一个充分适合文本生成的内部测评算法。在机器翻译中有BLEU(Bilingual Evaluation Understudy),ROUGE(Recall-Oriented Understudy for Gisting Evaluation ),NIST(National Institute of Standards and Technology)等算法。
4.2 外部测评
外部测评是基于用户实用性考虑的一种测评方式,即最大程度上满足用户要求的一种主观测评。但采用外部测评往往比较耗时耗力,不容易达到预期的效果,所以外部测评在实际应用中相对较少。
综上所述,外部测评和内部测评各有利弊。但内部测评结合多种技术,应用广泛,易于人们接受。今后的研究,可以考虑将多个测评方法结合,提高测评的精准度和科学性。未来,文本生成测评机制一定会成为一个研究热潮。
5 未来方向和潜在问题
虽然近些年文本生成技术已经有了显著进步,但对现有的技术来说仍不能满足人们的需要。文本生成技术还存在一些问题需要解决:
1)数据集不足。可以拿来充当数据集的数据非常少,只有仅有的几个领域,构造数据集需要人工收集,所以公开的数据集明显不足且种类单一。
2)可以用作自动生成的语料短而简。自动生成的文本短而简,这就使得一些好的模型不能充分发挥它的作用,从而不能达到预估的期望。
3)没有一个客观规律的评价手段。评价手段除了人工评价外,缺少一种机器自动评价体系可以体现出文本内容的统一性、相关性、结构特征等方面。
4)不能充分具体地供应人们使用。虽然小部分可以使用,但由于技术的不成熟,还没有被人们广泛地使用和推广。
6 结语
采用神经网络模型来实现文本生成是目前的主流趋势。虽采用RNN 实现文本生成居多,但还没有一种专门的机器评测体系用来规范文本生成,相信将来会研究出来的。
现如今,人们对人工智能的应用越来越关注。文本的自动生成也变得尤为重要,机器代替人力的例子也不那么罕见,尤其是国内外的机器翻译、新闻撰写等行业更是不断地探索求学。文本生成的进步,需要各行业共同努力,需要软硬件技术的不断更新推动,文本生成技术才会融入人们的生活,帮助人们分担一些工作。
