考虑边信息的多层贝叶斯需求预测模型
2020-02-13邱萍萍黄晓宇曾青松
邱萍萍,黄晓宇+,曾青松
(1.华南理工大学 经济与贸易学院,广东 广州 510006; 2.广州番禺职业技术学院 信息工程学院,广东 广州 511483)
0 引言
需求预测在促进企业经营策略制定及供应链上各个环节间的协调中发挥着重要的作用[1]。在现实的供应链场景中,对提前期内的客户需求进行预测是企业制定采购策略、生产计划、库存等供应链运作策略的基础[2]。特别的,近年随着工业互联网经济的发展,消费品供应链中生产者和消费者的关系正在被重塑,需求的不确定性日趋增大,对企业供应链的敏捷性提出了更高的要求[3]。因此,在制造业与互联网不断融合的发展进程中,如何满足客户日益个性化的需求,并对各种新的需求做出及时、科学的响应,是企业打造智能制造供应链所需解决的关键问题。同时,Yavuz等[4]指出需求的不确定性对供应链的绩效产生了最大的负面影响,所以如何对供应链中的客户需求实现更为准确的预测,以更好地优化与规避需求的不确定性,对于供应链管理策略的优化及工业制造智能化水平的提高具有重要的现实意义。
在此背景下,如何降低供应链中的需求不确定性已成为许多企业关注的核心问题。为提高供应链系统应对需求不确定性的能力,许多不同的预测方法与技术相继被提出,如:指数平滑[5]、自回归[6]等。总体而言,这些模型在对竞争对手的商品购买需求进行分析,以及在信息不共享的情境下对供应链下游企业的商品订购进行预测等外部预测中具有较好的适用性。然而,它们都仅考虑了客户对商品的需求数量这一单一信息,而在现实生活中,客户对商品的实际需求还受其他的“边信息”的影响,如商品的销售价格、促销活动、产品生命周期、节假日、消费者价格指数等。因此,在构建需求预测模型时,将这些边信息纳入考虑,是非常必要的。
近年来,已有学者提出了若干带边信息的需求预测模型,如支持向量机[7]以及将传统时间序列方法与启发式算法结合的预测方法[8]等,这些研究结果显示,将边信息纳入模型的构建有助于提高需求预测的准确度。但值得注意的是,在现实应用中,客户对商品的需求曲线往往是非平滑的,如受日益频繁的网络促销日的影响,我国需求曲线具有显著的暴起暴落的特征,而现有的模型[7-8]均为光滑模型,对于现实场景中的应用具有一定的局限性。
针对以上问题,在工业互联网的背景下,本文从改善供应链需求管理的角度出发,主要研究在有边信息条件下,如何预测客户在未来一段时间内对该商品的需求数量,着力于提升企业对客户购买需求的预测精度。基于此,本文构建了一个将边信息纳入考虑的多层贝叶斯需求预测模型(hierarchical Bayesian Demand Forecasting model with Side Information, DFSI)。具体的,考虑到顾客需求的波动随机性,本文首先假设不同时刻的顾客需求y之间相互独立,进而引入隐状态η刻画顾客需求在时序上的联系,并将边信息引入到需求预测模型的构建中。在此基础上,得到了一个新的预测顾客需求的方法。在模型的推断求解上,应用贝叶斯推断理论推导出其约束优化模型,并提出一种基于最大化后验概率思想的模型求解方法。本文将所提出的模型应用于某制造企业及京东商城的线上渠道销售的商品的需求预测中,并将星期因子、促销时间节点以及节假日等边信息在实例验证中纳入考虑,结果显示,与常用的模型相比,所提出的DFSI具有更好的预测效果。
1 文献回顾
目前,关于需求预测的研究可以归结为无边信息条件下的预测模型和有边信息条件下的预测模型两类。其中,无边信息条件下的预测模型中最为经典的是线性时间序列预测法[9-11],这类模型由于用法简单、解释性强,在实际中得到了广泛的应用。但由于受到自身线性假设的制约,这类方法的预测得到的是一个序列的长期均值,即对于长期预测而言,很难取得令人满意的结果,且易于出现误差积累的问题。为了克服线性时间序列模型的弊端,众多学者对此进行了非线性扩展。其中,Villegas等[12]从参数化模型的角度进行扩展,并提出一种基于卡尔曼滤波模型的需求预测方法,该模型采用递归算法进行状态空间模型的模型状态及协方差的最优估计,从而进行预测策略的制定;Chapados[13]则进行了非参数模型的扩展,在假设需求分布的形式为负二项分布基础上,运用近似贝叶斯推断方式进行模型的参数估计。实践表明,上述工作均在现实数据上取得了很好的预测成效。但值得注意的是,这些方法由于仅依据历史需求数据进行建模,在现实中的应用具有一定的限制性。
于是,基于边信息条件下的需求预测策略的制定受到了许多学者的关注与研究[14-19]。在从模型驱动的视角进行预测模型的构建方面,许多学者将时间序列方法与计算智能方法相结合进行需求预测策略的制定。其中,Andrawis等[14]将边信息纳入考虑,提出将一种计算智能方法与线性时间序列相结合的组合预测法。Khashei等[15]将商品购买的季节性及趋势性等边信息纳入考虑,并构建了一个将季节性自回归移动平均模型与人工神经网络及模糊模型相结合的预测方法;Bao等[16]对传统的迭代预测的支持向量机模型进行改进,提出一种直接进行多步预测的改进支持向量机模型。实验结果显示,这类模型均取得了较好的成效,但此类模型从本质上来说都是参数化模型,缺乏灵活性,难以解决复杂的非线性问题。相比之下,以贝叶斯推断模型为代表的非参数模型,可以通过对参数引入先验分布实现参数的自动化学习,对于非线性的复杂问题的处理具有显著的优势。目前,已有相关学者探索在考虑边信息的条件下,基于贝叶斯推断理论进行需求模型的构建。Seeger等[17]假设需求分布的形式为多阶段泊松分布、Dahlin等[18]假设需求的分布为非线性状态空间模型、Rasmussen等[19]假设需求的分布服从高斯过程。上述工作均在真实的数据集上取得了较高的预测精度,显示了非参数模型在需求预测领域具有良好的应用前景。
综上所述,非参数模型相较于参数化模型在需求预测的准确度方面具有显著的优势。进一步的,基于前述研究可知,将边信息纳入考虑能够实现预测质量的有效改善。在此背景下,本文提出一个考虑边信息的非参数需求预测模型DFSI,以期对现有的需求预测理论实现进一步的拓展,进而为现实的企业供应链运作策略的制定提供决策参考。
2 考虑边信息的需求预测模型构建
本章将介绍所提出的考虑边信息的需求预测模型DFSI的概率图描述以及相关的统计假设。
2.1 需求预测模型构建
根据线上供应链的实际运作模式及自身的购物经历,顾客在做出购买决策时往往会参考各种已知的边信息,因此本文在需求预测模型的构建中引入边信息向量F=(f1,f2,…,fn)T,并且考虑到各个边信息在不同的时刻对需求的影响程度存在差异。假设边信息在某一具体时刻t对需求的影响为Ft=(f1(t),f2(t),…,fn(t))T,用以刻画不同的边信息对于顾客需求所产生的作用,以更加细化地分析各种边信息对顾客需求的影响,从而提升模型在实际中的适用性。
因此,在给定商品的历史需求数据y=(y1,y2,…,yT)及边信息F=(F1,F2,…,FT)的条件下,为实现顾客在未来一段时间内对该商品的需求数量的预测,本文考虑如图1所示的概率图模型。
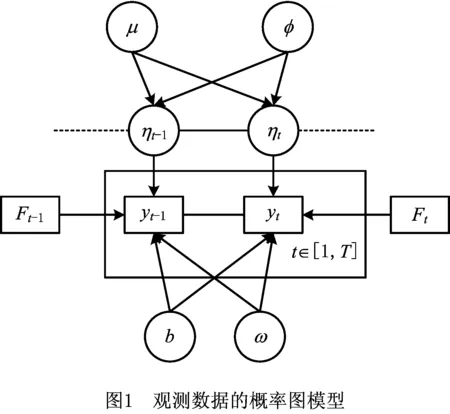
具体的,假设图1的各变量之间具有以下关系:
(1)需求数据y=(y1,y2,…,yT)在不同时间节点上的分布相互独立。在此基础上,本文假设对于任一时刻t而言,需求yt具有如下的分布:
(1)
式中:隐状态ηt表示顾客在时刻t对该商品的平稳需求特征;ω表示影响顾客购买行为发生的因子,如:商品的使用频率或寿命等可能诱发购买行为的因素等;向量b=(b1,b2,…,bn)T表示影响边信息F的各个分量的权重因子。从而可以得到任一时刻的需求yt由ωηt组成的系统性需求加上由bTFt组成的非平稳性需求构成。
(2)考虑隐状态η的先验分布的选择。由于在上述需求分布的假设中,认定任一时刻的终端顾客需求yt服从均值为ωηt+bTFt的高斯分布,而隐状态η被用于表征顾客的平稳需求。因此本文希望在隐状态η的分布的选取中体现出顾客需求的时序关联性。假设任一时刻的隐状态ηt仅受到其上一刻的隐状态ηt-1的影响,即隐状态η具有一阶马尔可夫性[20]。基于此,本文给出隐状态η=(η1,η2,…,ηT)的分布如下:
εt~N(0,1)。
(2)
其中:μ∈R为隐状态η自回归的长期均值水平;-1<φ<1表示自回归的速率;εt表示自回归的噪声项。

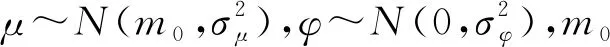
3 模型推断与求解
在上一章模型构建的基础上,本章首先对DFSI的整体结构进行分析,进而进行参数分布的推导,最终给出模型的求解策略。
3.1 模型的整体结构
基于前述模型构建,在给定T个观测到的顾客需求及边信息数据的情况下,为得到未来一段时间内顾客对该商品的需求数量的预测,依据贝叶斯定理[21],可以推断得到:
L=P(η1:T,ω,b,μ,φ|y1:T,θG,F1:T)
∝P(η1:T,ω,b,μ,φ,y1:T|θG,F1:T)
P(η1:T,ω,b,μ,φ|θl)。
(3)

从而,在最大后验角度下,为得到参数η,ω,b,μ,φ的最优估计值,相当于最大化如下目标:
F1:T)×P(η1:T,ω,b,μ,φ|θl)。
(4)
3.2 参数分布推导
本节对式(4)右端的两个概率分布进行详细推导。
(5)
对于P(η1:T,ω,b,μ,φ|θl)而言,由于ω,b,η均作用在需求数据y上,三者之间具有条件独立性。由此可得:
(6)
另外,基于式(2)的假设,可以得到隐状态η的分布服从马尔可夫随机场[20]。因此,依据马尔可夫随机场原理,可以得到:
(7)
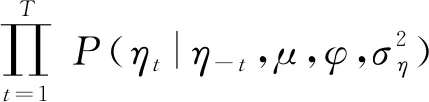
(8)
因此,最终可以得到P(η1:T,ω,b,μ,φ|θl)的分布为:
(9)
3.3 模型求解
本节讨论对DFSI的求解。假设给定的历史需求数据长度为T,令π=-log(L),可以得到本文的目标函数如下:
(10)
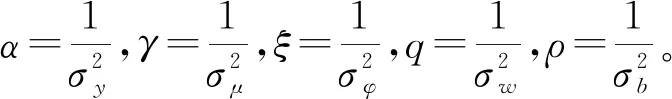
算法1DFSI模型的参数拟合。
输入:历史需求数据y={y1,y2,…,yT}及边信息F={F1,F2,…,FT};
1.设置梯度下降速率为δ;
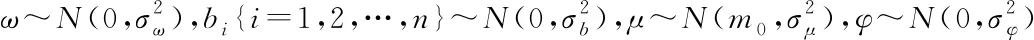
3.在t=1,2,…,T内,运用式(2)生成的ηt的初值;
4.令K=[ω,b,μ,φ,η];
5.while目标函数π未收敛do


8.计算函数π;
9.endwhile
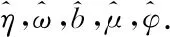
上述算法的核心步骤在于目标函数对各参数的梯度计算。
对于ω,有:
(11)
对于bi{i=1,2,…,n},有:
(12)
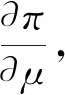
(φ-1)]+γ(μ-m0);
(13)

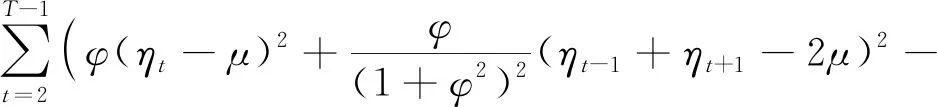
-(ηT-1-μ)(ηT-μ-φ(ηT-1-μ))]+ξφ。
(14)
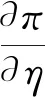
当t=1时,
(ηt+(φ-1)μ-φηt+1);
(15)
当1 (ηt-1+ηt+1-2μ))(1+φ2); (16) 当t=T时: (ηt+(φ-1)μ-φηt-1)。 (17) 本节讨论在给定历史需求数据y=(y1,y2,…,yT)及边信息F=(F1,F2,…,FT,FT+1,…,FT+m)的情况下,如何对未来一段时间的顾客需求(yT+1,yT+2,…,yT+m)进行预测。具体算法如下。 算法2DFSI模型的预测流程。 1. fori=1:mdo 4. end for 本文将所提算法应用于3个真实的线上销售数据集进行客户需求预测实验。 为验证DFSI模型的有效性及实用性,本文使用国内某制造企业的线上渠道销售数据集及京东平台上的销售数据集进行实验设计。由于在实际的销售过程中,顾客的真实需求是不可得的,本文将商品的销售数据等同于顾客对该商品的需求。其中,DS-1为京东商城上一种商品2016年1月1日~2017年12月31日共611天的销售数据(其中6月与11月两个大促月的数据集在所公开的数据集中已被剔除)。DS-2~DS-3数据集为国内某制造企业2017年10月1日~2018年10月31共396天的两种商品的线上销售数据。表1所示为3个数据集的描述统计信息。由表1可知,DS-1数据集的离散系数及标准差远小于DS-2~DS-3数据集。可以得到,DS-1数据集上的商品销售数据的波动相对较为平缓,而DS-2~DS-3则呈现出了剧烈波动的特征。故而,以这3个数据集进行仿真实验,可以更好地验证所提出的模型在不同类型的商品预测中的适用性。 表1 实验数据集的描述统计信息 图2所示为DS-1~DS-3上的3种商品的实际销售情况。从图2可以看到,在促销时间节点及节假日的顾客购买需求的波动非常明显,由此可知这两个边信息对于商品的购买需求产生了显著的影响。另外,在线上销售的实际运作中,星期内的不同天数的购买活跃度往往会有所差异[8],因此本文将商品的星期指数因子、促销时间节点以及节假日因子这3个边信息纳入考虑,以进行后续的实验设计。 本文选取两个在现实中得到广泛应用的评价指标,均方根误差RMSE[15,19]及平均绝对百分比误差MAPE[8,16,19],以定量地评估模型的性能。其中,RMSE用于衡量预测值与实际值之间的绝对误差,MAPE则体现了预测值与实际值之间的误差的相对大小。上述两个评价指标的值越小,预测的精度越高。具体计算公式为: (18) (19) 本节描述所提出的DFSI模型的参数调节过程。基于式(10)可以看到,DFSI模型有α,γ,ξ,q,τ,s,ρ共7个参数需要调节。其中,α直接作用于全局变量y上,对于需求预测的结果会产生较大的影响,而其他6个参数均作用于局部变量上。经验上而言,上述参数主要用于平滑对局部变量的拟合效果,其选取对于模型的预测结果不会产生显著的影响。因此,本节重点讨论α的调节,同时设定γ=ξ=q=τ=s=ρ=1。 在参数α的调节过程中,本文从DS-1~DS-3上分别抽取了70%的数据作为训练集,余下的30%作为测试集。将α的候选值设定为{2-1,2-2,…2-10},并选取使测试集RMSE、MAPE最小的α。 在DS-1上得到最优的α=2-5,此时MAPE=0.141 3,RMSE=3.383 1;DS-2上的为α=2-4,此时MAPE=0.085 0,RMSE=3.582 2;DS-3则为α=2-2,此时MAPE=0.102 2,RMSE=2.824 0。具体参数调节过程如图3所示。 4.4.1 边信息的作用分析 本文分别将DFSI和DFNSI应用于DS-1~DS-3进行用户需求预测,在预测性能对比的实验设计中,分别对训练集:测试集为8∶2及9∶1的顾客需求数据的预测表现进行检验。预测表现如图4所示。图4中,虚线左侧为对训练集的拟合结果,虚线右侧则表示为对测试集的预测结果。 由图4的实验结果可知,无边信息条件下的需求预测模型DFNSI对于顾客需求波动性的识别能力较弱,而基于边信息条件下的需求预测模型DFSI则对需求的波动性表现出了较强的拟合能力。因此,从拟合的曲线趋势来看,将边信息纳入考虑的DFSI的预测效果优于无边信息条件下的DFNSI。同时,将边信息纳入考虑可以显著地提高模型的预测性能。 4.4.2 预测性能比较 以Croston[9]、ARIMA[10]、SSpace[12]、H-NBSS[13]及高斯过程[19]5种算法作为基准算法,对比它们与本文提出的DFSI模型在数据集DS-1~DS-3上的预测表现。在基准算法中,Croston与ARIMA属于经典的时间序列预测模型,而SSpace基于卡尔曼滤波对传统的时间序列方法进行改进,这3类模型均属于不带边信息的参数模型,已有的实验结果显示,在对平稳的客户需求序列的预测应用中,它们都获得了很好的预测效果[9-10,12];H-NBSS属于不带边信息的非参数模型,适用于波动性较强的需求预测[13];高斯过程则属于考虑了边信息的非参数预测模型,在高斯过程的核函数的选取中,本文选用常用的指数核及Matern两种核函数进行高斯过程模型构建。5次重复试验的均值结果如表2所示,RMSE和MAPE的值越小,预测精度越高。 表2 预测结果统计 从表2的结果可以看出,在预测准确度方面,本文所提出的考虑边信息的DFSI模型均表现出了最佳的预测性能;虽然H-NBSS与Croston、ARIMA及SSpace均为无边信息条件下的需求预测模型,但H-NBSS的预测精度高于Croston、ARIMA及SSpace。另外,依据上述实验结果还可以看出,虽然在DS-1及DS-2数据集上高斯过程的预测结果均高于Croston等参数化模型,但在数据集DS-3上高斯过程模型的预测精度确不如Croston等参数化模型。出现这种情况的一个可能的原因是,本文采用的是普适高斯过程模型,没有针对特定的数据进行特别的核函数设计或优化,而对比的参数化模型是专门针对时序数据设计的,能更好地利用数据的领域特征。但即便如此,高斯过程模型在大部分的预测任务上,还是获得了更好的结果,显示了非参数模型的优越性。并且,随着预测天数的增加,非参数模型的预测准确度的优势越明显。由此可以得出,非参数模型在对波动日益剧烈的供应链客户需求的预测中,比参数化模型更具有适用性。 本文重点针对供应链的需求预测问题展开研究,将边信息引入到模型的构建中,建立了一个基于多层贝叶斯推断的需求预测模型。本文提出的需求预测模型为供应链中的动态需求预测提供了新思路。特别地,随着工业互联网的深入发展,提高供应链中的客户需求预测精度对于企业实现生产资源配置效率的提高具有重要的现实意义。本文所提的DFSI模型使用隐状态刻画顾客需求在时序上的联系,使用边信息刻画顾客的非平稳需求。在真实的线上销售数据集的验证中,将商品的促销策略、星期因子以及节假日因子等边信息纳入考虑,实验结果表明,与各种常用的基准算法相比,本文提出的DFSI模型具有更大的优势。 由于终端顾客需求的准确预测是制定供应链中的生产计划、库存策略、设施规划以及配送策略等的基础,如何将所提出的模型进行进一步的扩展,进而研究企业如何进行最优生产计划、库存及配送方案的制定将是未来关注的重点。3.4 模型预测策略制定
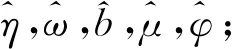
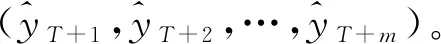
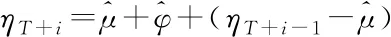

4 实验及结果分析
4.1 数据集及边信息选取

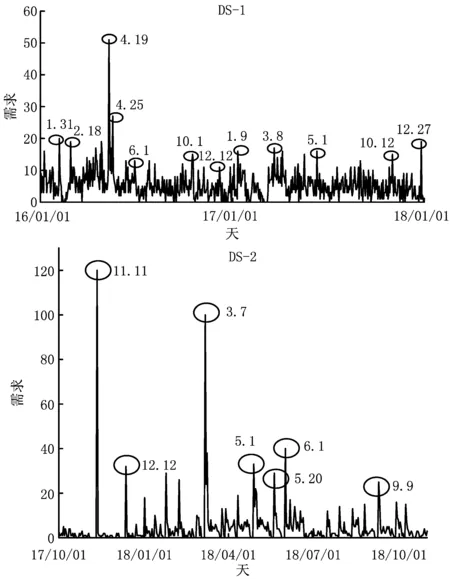
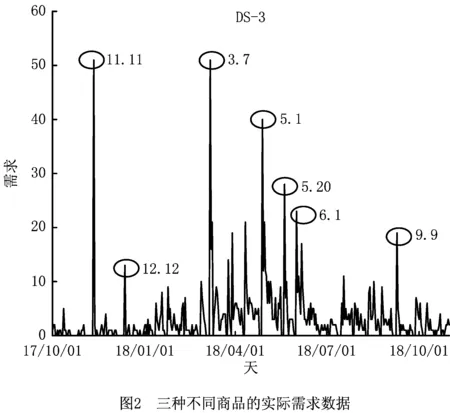
4.2 评价指标

4.3 参数调节
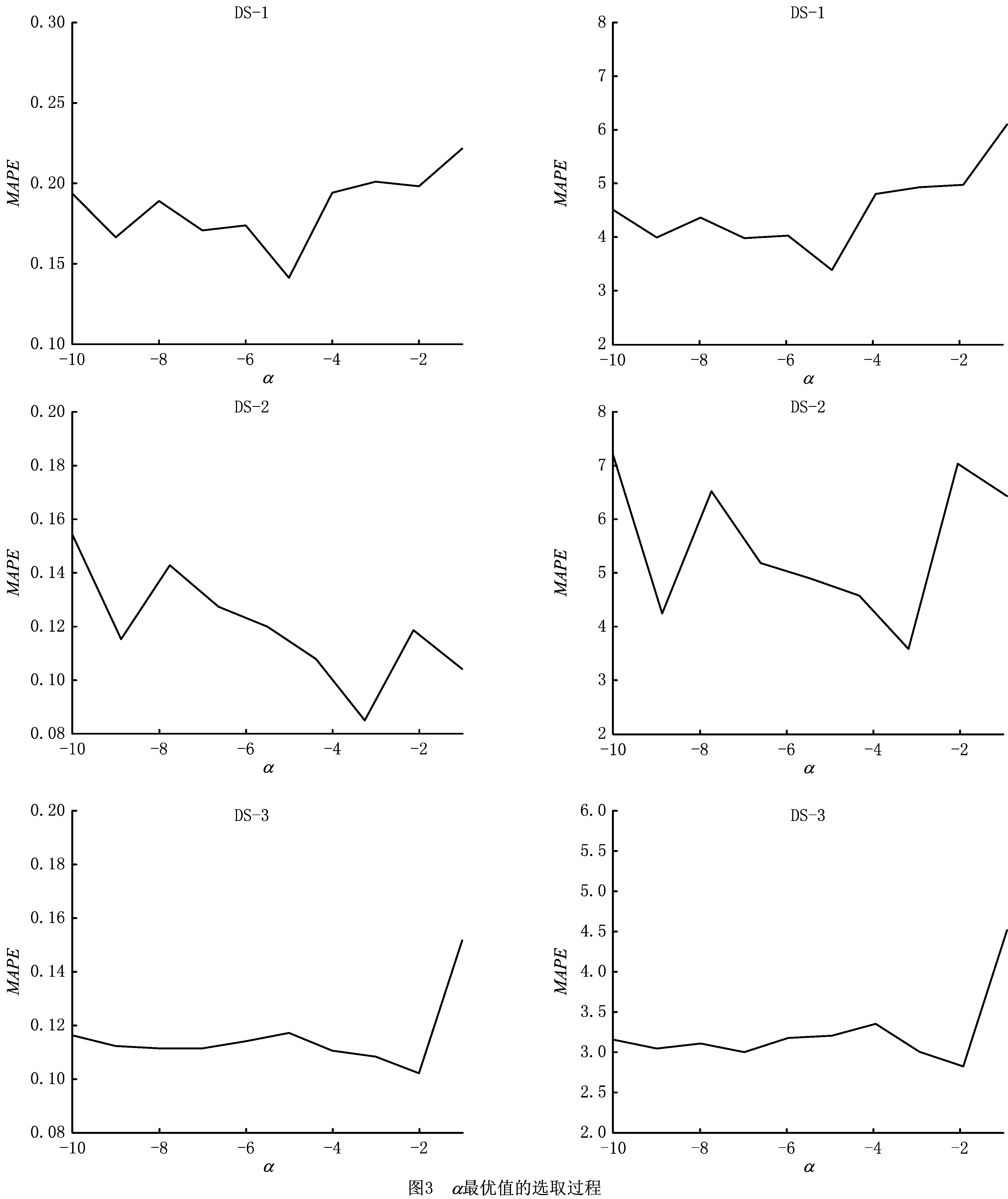
4.4 实验结果与分析
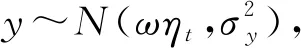

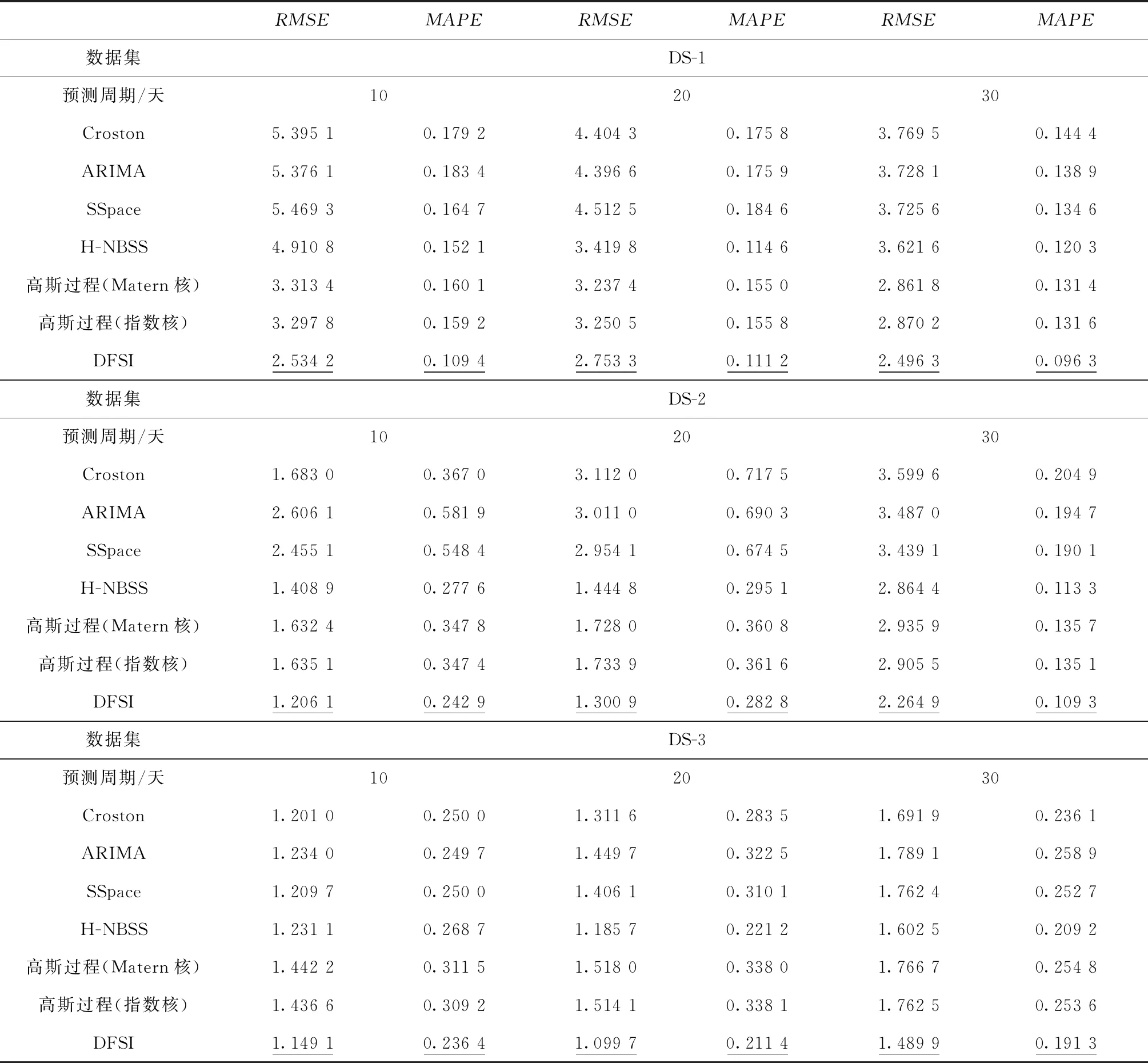
5 结束语
