多图模型及其在宏观经济指标相关分析中的应用
2020-02-07崔婉琪邓笑笑
高 伟,崔婉琪,邓笑笑
(西安财经大学 统计学院,陕西 西安 710100)
一、引 言
多变量之间的相关关系是统计学研究的一个基础问题,多变量之间不仅存在直接相互作用,还存在以中间变量为桥梁的间接相互作用,传统的相关性分析方法难以处理间接关系。高斯图模型是变量服从多维正态分布的图模型,用结点表示随机变量,结点之间的无向边表示变量之间的条件相依关系,可以区别和处理间接关系,分析高维数据间复杂的相依结构,为建模分析和预测提供了全面准确的信息,在统计学、计算机科学、生物技术、社会学等方面得到广泛应用[1-5]。
目前关于高斯图模型的研究主要集中在单个图模型的结构学习和应用方面。然而在许多应用领域中随机变量的观测数据是具有分组特征的多源数据,来自于不同的又有一定联系的系统,将随机变量间的相依结构用图模型表示,这些图模型同时具有共同特征和各自独有的结构。例如不同经济发展水平的地区,表示其宏观经济变量间相互联系的图模型,除各自独有的联系外,还存在相同的条件相关和条件独立联系。如果分别估计单个图模型,会忽视共同的结构信息。联合估计方法通过对组间差异施加约束同时估计具有共性和个性特征的多个图模型,如连接单个图模型的分层惩罚方法[6-7],通过广义融合Lasso或组Lasso约束类间差异的联合图Lasso方法等[8-10]。Guo等通过分层惩罚处理多个图模型精度矩阵中共同的零元素,但只考虑了图模型中无边相连的结点,没有考虑有联系的结点[6]。张凌洁和张海提出了一种连接单个图模型的分层惩罚方法对多图模型进行估计[7]。Danaher等提出联合图Lasso方法,通过广义融合Lasso或组Lasso约束类间差异,估计多个高斯图模型[8]。Zhu等对精度矩阵之间的每个差异引入1惩罚,解决联合估计问题[9]。Yang等提出了融合多类图Lasso模型,该模型通过融合Lasso 惩罚激励相邻图之间的共性,并提出了可分解为子图进行估计的高维图筛选准则[10]。上述方法在联合估计多个图模型结构时,并没有用到多源数据结构已知的信息。Ma和 Michailidis在模型结构间存在先验信息的条件下,联合估计多个高斯图模型,并证明了提出方法的相容性,但假设已知每对变量间的相关关系在不同类间的差异,在实际应用中过于严格[11]。
本文假设数据来自于多个同时具有相同结构和各自独有联系的图模型,发展了多图联合估计方法,用数值模拟验证了方法的有效性。最后将方法应用于不同经济发展水平省份宏观经济变量间的相关特征分析,揭示其经济发展的共性和差异,为制定经济发展政策提供依据。
二、多图模型及其联合估计方法
(一)多图模型
多源数据的异构性使得数据出现分类的情况,按照一定的标准把结构相似的数据归为一组,每组的相依结构用一个图模型表示。 由于组间结构的差异,图模型的边集不一定相同,但由于其表示的是同一组随机变量之间的联系,又会存在某些共同特征。如果对每类数据分别使用图模型方法建模,将忽视共同的结构,而把数据集融合,建立同一个图模型,则导致差异信息损失。联合估计方法通过对不同图模型的结构差异施加约束,同时学习多个图模型,考虑到各类间的共同信息,保持共同结构的同时允许不同类间存在差异。本文主要研究如下定义的多图模型。
定义1:设p维随机变量X=(X1,X2,…,Xp)T,K组观测值分别来自于M(M≤K)个正态分布N(0p,Σm)。M个高斯图模型Gm=(V,Em),m=1,2,…,M,其中结点集V={1,2,…,p},Em表示结点对应的随机变量间相依结构。 即K组观测值中,k1个来自于图模型G1,…,kM个来自于图模型GM,k1+k2+…+kM=K。
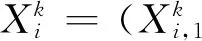
(二)联合估计方法
将单个图模型结构估计的Lasso方法推广到多图模型,联合估计M个图模型。 Meinshausen等将求解精度矩阵的问题转换为回归系数估计问题,提出高斯图模型结构学习的Lasso方法[12]。Yuan等将Lasso方法推广到分组数据上,提出了组Lasso方法,约束来自于同一组的变量其系数同时都为零或都不为零[13]。本文将高斯图模型结构学习的Lasso方法推广到分组结构上,得到联合估计多个图模型的组Lasso方法,即求解如下的分组优化问题:
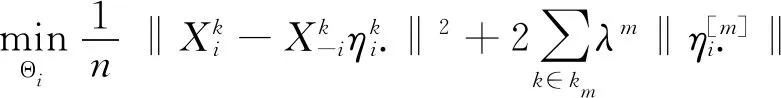
(1)
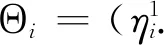
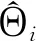
(2)
进一步,在式(2)得到的图模型基础上,用图Lasso方法再次进行边集选择,得到更精确的图模型[14]:
(3)
m=1,2,…,M
联合估计方法将构建多图联合模型的问题转化为K个回归方程在1范数和分组约束下的求解问题,避免了直接估计精度矩阵Θ。通过分组惩罚使M个类别之间的精度矩阵具有相似性。由于求解是按照不同变量独立进行的,有可能导致模型给出的结果具有不对称性,即出现和结果不对称情况。可以考虑和中任意一个非0,就认为图中结点i与j有边相连。优化问题(1)中涉及到惩罚参数的选择,本文用贝叶斯信息准则(BIC)平衡模型拟合优度及其复杂性,
BIC(λ)=
(4)
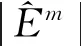
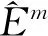
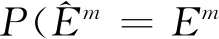
三、数值模拟
本文通过模拟数据验证多图模型联合估计方法的有效性。由推论1可以发现,多图模型联合估计的收敛速度和变量个数、样本量以及协方差结构等有关。我们考虑了不同图结构、变量个数和样本量对多图联合估计方法的影响,并与单独估计的图lasso方法进行对比分析。
图模型结构估计的有效性用精确率(Precision)、召回率(Recall)和F1得分来评价,即:
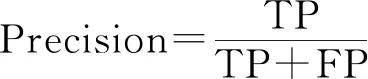
其中,TP表示正确辨识的边数,FP表示误判为存在但实际不存在的边数,FN表示误判为不存在但实际存在的边数。精确率为正确辨识的边数占辨识的总边数比例,召回率为正确辨识的边数占实际总边数的比例。惩罚参数值较大时,辨识的边数较少,精确率大而召回率小;惩罚参数值较小时,辨识的边数较多,精确率小而召回率大。F1得分是精确率和召回率的调和均值,只有当两者都大时,才能得到高的F1得分值。
给定高斯图模型个数M和变量个数p,每类生成一组模拟数据。首先生成边集,对共同结构E0,设边数为|E0|,|E0|组不同的边(i,j),i、j=1,2,…,p,i≠j。每个高斯图模型的独立结构边数设为φ|E0|,φ(φ>0)表示图模型独有的边数与共有的边数之间的比值。分别随机抽取φ|E0|组不同于E0的边作为每个图模型各自的边,结合共同结构E0,组成多图模型的边集Em,m=1,2,…,M。然后生成精度矩阵,精度矩阵的非对角线非零元素位置对应于边集Em,从区间[-1,-0.5]∪[0.5,1]中产生随机数为其取值,对角线元素取值设为相同,且保证矩阵的正定性。本节模拟用精度矩阵直接求逆的方法得到协方差矩阵,当变量维数较高时,建议采用优化方法计算协方差矩阵Σm。最后分别产生n个多维正态分布N(0p,Σm)的随机数作为样本。
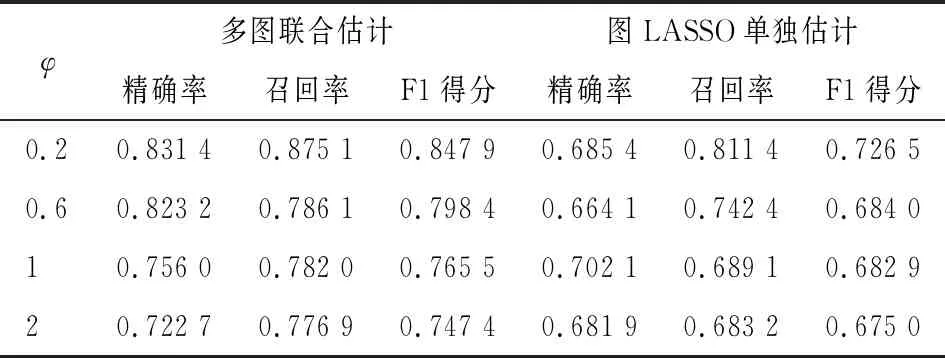
表1 p=20,不同φ|E0|两种方法结果比较
接下来设M=5,变量个数p和公共边数都分别取10,20和50,独有的边数为0.3|E0|,样本量分别取n=50和n=100,模拟进行100次。表2的结果表明,样本量一定,随着变量维数的增加,两种方法的F1得分都减少,联合估计方法减小幅度小于单独估计方法;维数一定,F1得分随样本量增加而提高,联合估计方法增加的幅度大于单独估计方法。各种情况下,联合估计方法都优于单独估计方法,并且随着变量个数和样本量的增加,差距显著增加,进一步验证了联合估计方法的一致性和在高维变量上的优势。
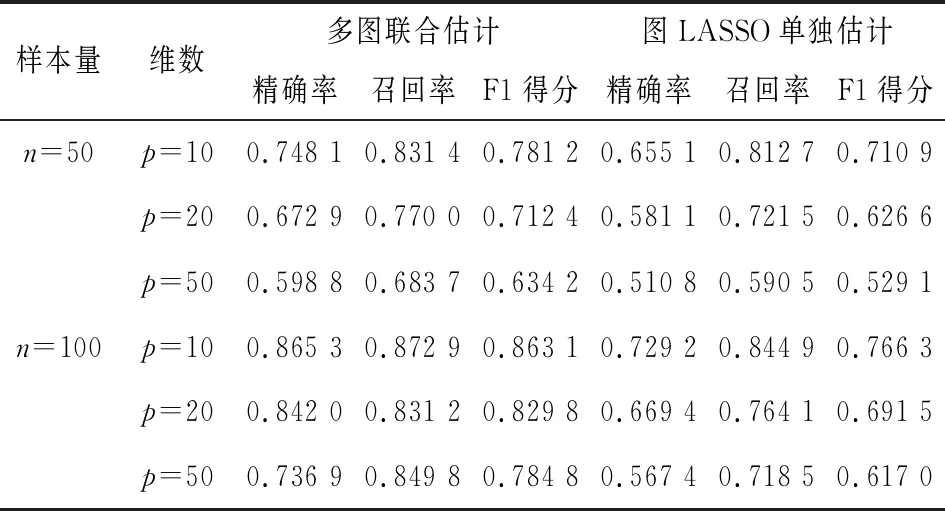
表2 φ=0.3,不同样本和变量个数下两种方法结果比较
四、实证分析
将多图模型联合估计方法应用于中国宏观经济变量,分析不同经济发展水平省份宏观经济变量间的相关联系特征。
考虑到数据收集的完整性,选取15个省份13个宏观经济变量1980—2017年共计38年的年度数据,分别为:财政预算支出X1,财政预算收入X2,城镇登记失业率X3,国际旅游外汇收入X4,居民消费价格指数X5,货运量X6,客运量X7,农业总产值X8,林业总产值X9,牧业总产值X10,渔业总产值X11,社会固定资产投资X12,社会消费品零售总额X13。数据来源于国家统计局(http://data.stats.gov.cn)。为确保多个数据源之间的兼容性和一致性,对数据进行了标准化和正态化处理。
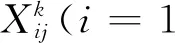
五组图模型中共同的联系有财政预算支出X1、财政预算收入X2和社会固定资产投资X12之间存在的完全子图结构;财政预算支出X1、社会固定资产投资X12和社会消费品零售总额X13之间的完全子图;农业总产值X8、林业总产值X9和牧业总产值X10之间的完全子图;农业总产值X8、林业总产值X9和渔业总产值X11之间的完全子图;社会消费品零售总额X13与居民价格消费指数X5之间的联系。这些共同联系反映了中国现阶段经济发展的特征。
每一类中与其他四类不同的联系,反映了各类随机变量间相依结构独有的特征。第一类中北京和上海是15个省份中经济发展最好的,作为直辖市,土地面积和发展规划与其他省份不同,财政预算支出X1与林业总产值X9,货运量X6与渔业总产值X11之间的联系为其独有。与其余四类相比,城镇登记失业率X3、国际旅游外汇收入X4及货运量X6与客运量X7之间均无边相连,反映出旅游业、失业率和货运量与客运量没有明显的直接联系。第二类中江苏和山东在15个省份中是仅次于北京和上海的文化与经济大省,渔业是临海地区主要产业,居民价格消费指数X5与渔业总产值X11之间存在联系,货运量X6与农业总产值X8、牧业总产值X10及社会消费品零售总额X13之间的联系,反映了农、牧业和社会消费品的生产优势。城镇登记失业率X3与国际旅游外汇收入X4之间的联系表明,它们作为临海省份,旅游业和渔业具有独特地位。与其余四类相比,林业总产值X9与社会固定资产投资X12,财政预算支出X1与货运量X6之间没有直接联系,进一步表明其在林业和货运上,对财政和交通的依赖不明显。第三类中河南和河北牧业发展较好,牧业总产值X10与城镇登记失业率X3及居民价格消费指数X5之间的独有联系反映了其经济发展特征。第四类中安徽、辽宁、广西、江西和湖南五个省份,与其余四类相比,其13个经济指标间的相依结构没有明显的特色。第五类中吉林、陕西、贵州和黑龙江处于发展期,财政预算收入X2与国际旅游外汇收入X4及农业总产值X8之间的联系,反映了农业和旅游业在其经济发展中的重要地位;城镇登记失业率X3与林业总产值X9,货运量X6与社会固定资产投资X12之间的联系是独有的。
五、结 论
多源数据同时具有共性和异质性,对其分析要在发现独有特征的同时保留共同信息。本文提出改进的多个高斯图模型的联合估计方法,首先对数据进行分组,应用组Lasso方法约束各组内联系的一致性,用联合估计方法充分利用所有样本对共同信息进行估计,再进一步用图Lasso方法优化每组的图结构。数值模拟结果表明,多图联合估计比单独估计得到更准确的图模型结构。最后将提出的方法应用于中国15个省份13个宏观经济变量数据分析中,得到反映五组省份变量间相依结构的图模型,分析其经济发展的共性,以及不同类独有的联系。结果表明,多图联合估计方法对于体系复杂的宏观经济变量数据分析更全面,在保留组间共有结构信息的基础上,揭示了不同经济发展水平省份经济发展侧重点的个性信息,指标间联系的差异反映了其经济发展政策上的特征。
