多源遥感数据特征优选的大兴安岭沿麓不同农作物提取
2020-02-05于利峰乌兰吐雅李继辉于伟卓敦惠霞
于利峰,乌兰吐雅,李继辉,于伟卓,敦惠霞
(1.内蒙古自治区农牧业科学院 农牧业经济与信息研究所,内蒙古 呼和浩特 010031;2.内蒙古自治区农业遥感工程技术研究中心,内蒙古 呼和浩特 010031;3.奈曼旗林业工作站,内蒙古 大沁他拉镇 028300)
确保粮食安全一直是我国“三农”工作的首要任务,我国是粮食生产大国也是进口大国,我国对粮食消费深刻影响着国际市场粮食品种价格。近年来,国际粮食贸易面临着保护主义和单边主义的干扰,不稳定因素增加,因此,开展农作物面积动态监测,对合理规划作物种植布局,深入实施“藏粮于地、藏粮于技”战略,实现粮食自给自足保障粮食安全都有重要意义。
确保粮食安全,首先要有精准的农作物面积调查数据。基于统计方式的农作物面积调查,缺少空间参考,且时效性较差。20 世纪70年代卫星遥感技术的应用,为多尺度的农作物面积动态监测提供了条件,特别是近年来遥感数据质量的提高和处理技术的发展,使遥感的农作物面积提取精度不断提升。国内外学者针对遥感技术在农作物面积监测中应用开展了大量的研究,研究内容大致可以概括为利用时间序列遥感数据的作物提取研究[1-4]、多源数据的作物提取研究[5-9]、单时相高分辨率数据下作物提取研究[10-13]。其中,基于时间序列的分类方法刻画了作物间的时间变化特征,用途较广,作物提取效果较好。但使用时间序列受制条件有很多,若使用MODIS、Landsat、HJ 等中高分辨率光学遥感数据提取作物,混合像元势必忽略很多地面信息,如作物的间作套种;若使用Sentinel、ZY、GF 系列等高分辨光学遥感数据提取作物,不仅数据幅宽有限,而且云雨天气会导致光学影像不确定,虽然GF-6的宽视场相机能满足幅宽和分辨率的要求,但其单景数据超过6 GB,需要进行正射校正处理,对计算机硬件要求较高。使用雷达和光学数据融合进行农作物提取能够避免云雨天气影响,但雷达数据处理周期较长,产生的数据量较大,不适合大范围提取。
Google Earth Engine(GEE) 提供了一个通过Web 端和Python 语言端的数据分析云计算平台。能够并行化计算PB级遥感数据,可为用户实现科学分析和可视化,使得遥感影像的巨大数据量不再成为研究广度和深度的限制,也为大规模遥感数据的挖掘分析提供可能。JIN 等[14]利用GEE 平台和多源遥感数据在肯尼亚和坦桑尼亚依次构建了2017年的农田分布图、玉米分布图和玉米产量10 m 分辨率图;DONG 等[15]利用GEE 平台和Landsat8 数据绘制了东亚地区的水稻分布图;李宇宸等[16]利用GEE 平台和Landsat8 数据研究了中、老、缅边界橡胶林的提取分布图;SINGHA 等[17]利用GEE 平台和Sentinel-1 数据提取了孟加拉国和印度东北部的水稻分布情况。
上述基于GEE 平台的研究内容主要集中在单一研究对象上,且提取的精度提升,在农作物动态监测应用中缺乏整体性,难以满足政府部门对地区农作物进行全方位布局规划的需求。因此,本研究基于GEE 平台,采用Sentinel-1 和Sentinel-2为主的多源遥感数据作为研究数据源,以内蒙古呼伦贝尔市为研究区,对多种作物加以提取,以期为多云多雨条件下、跨气候带区域和高寒旱作农业区大尺度农作物提取应用提供解决方案。
1 研究区与数据源
1.1 研究区概况
研究区选择大兴安岭沿麓主要农业区的内蒙古自治区呼伦贝尔市,其面积相当于山东省和江苏省的总和,研究区西与蒙古国、北与俄罗斯接壤,东与黑龙江省、南与内蒙古兴安盟相邻,大兴安岭横贯中部,将大兴安岭西麓划为温带大陆性气候,大兴安岭东麓划为温带大陆性季风气候,四季分明。研究区也属于北方高寒旱作农业区,地处N47°05′~53°20′,E115°31′~126°04′(图1),统计数据显示,2018年呼伦贝尔农作物播种面积为189.425 万hm2[18],占内蒙古农作物播种面积的21.47%,研究区冬季寒冷漫长,夏季温凉短促,春季干燥风大,秋季气温骤降霜冻早;热量不足,昼夜温差大,有效积温利用率高,无霜期短,日照丰富,降水量差异大,降水期多集中在7—8月。
1.2 数据源
1.2.1 Sentinel-1 数据 Sentinel-1 数据是欧盟地球监测计划“哥白尼计划”的第一个星座,它搭载C 波段5.405 GHz的合成孔径雷达传感器,以A/B 双星的形式,提供陆地和海洋全天候、雷达成像的服务,A/B 双星对同一地理位置重访周期为6 d。GEE 平台中提供了Sentinel-1 干涉宽幅模式(IW)的地距多视产品(GRD)数据,这些数据已经通过Sentinel-1Toolbox(https://step.esa.int/main/toolboxes/sentinel-1-toolbox/)进行了热噪声消除、辐射校准和地形校正等处理,提供最高分辨率为10 m的VH、VV、HH和HV极化方式数据。由于HV 和HH 极化主要用于监视极地环境以及海冰区,本研究使用的数据为VV 和VH极化方式数据。
1.2.2 Sentinel-2 数据 Sentinel-2 卫星携带一颗多光谱的光学传感仪(MSI),可拍摄涵盖可见光、近红外线与短波红外线的13个波段影像,A/B 双星对同一地理位置重访周期为5 d。目前Sentinel-2 共有两种数据产品,分别为Level-1C 产品和Level-2A 产品,Level-1C 产品是由大气顶层(TOA)反射率观测得到,Level-2A 产品由大气底层反射率(BOA)观测得到,也可以从Level-1C级图像使用ESA 提供的专用工具箱(https://github.com/senbox-org)进行大气校正得到。2018年研究区范围内GEE 中仅提供了大气顶层(TOA)反射率,相关研究表明不进行大气校正不会影响地类的识别精度[19]。因此,本研究采用GEE提供的Sentinel-2 大气顶层(TOA)反射率数据。
1.2.3 辅助数据 在以往的研究中,大尺度区域耕地、草地、灌木和林地容易混淆,导致分类精度降低[20]。遥感辅助数据的作用是排除非耕地信息的干扰,以实现提高分类精度的目的。研究区地处大兴安岭沿麓,地形起伏复杂,开垦种植农作物往往不会在25°以上陡坡地,且海拔高度也会影响气候条件,进而影响农作物的种植结构。因此,本研究选择美国航天局航天飞机雷达地形任务(SRTM)数据集中全球数字高程模型(DEM)及其衍生数据坡度。除此,研究区还有大片林地和草原,本研究使用MODIS 土地覆盖类型产品MCD12Q1 用于区分地表信息,MCD12Q1是使用监督分类算法生成的每年土地覆盖类型(2000—2018年),空间分辨率为500 m,包含6种分类方案,已被证明是拥有较高分类精度的土地利用数据[21]。
1.2.4 样本数据 本研究中将样本分为作物样本和非作物样本。使用的作物样本数据为实地观测的2018年呼伦贝尔市作物野外样本数据,使用BDS 手持机采集,经过差分校正和影像叠加目视校正,合计1 797个;非作物样本数据使用对应年份的Google earth 高分辨率影像选取,合计311个。所有样本合计2 108个,在使用时随机选择70%样本进行分类训练,其余的30%部分进行精度验证(表1)。
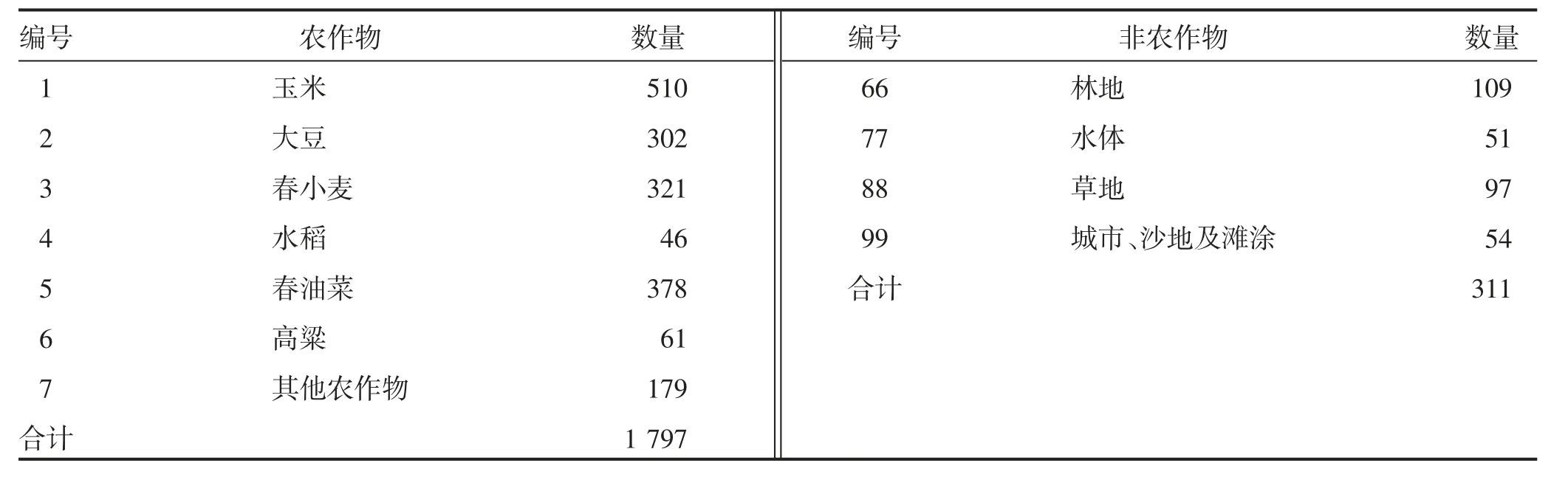
表1 样本数据
2 研究方法
研究区的农作物分布存在地区差异,大兴安岭西麓属于蒙古高原延伸地带,主要种植春小麦、春油菜、甜菜等作物;大兴安岭东麓属于东北平原的边缘,主要种植玉米、大豆、水稻等作物。其中,每年最早播种的是春小麦在4月初,最晚收获的是水稻在10月中旬。因此,本研究利用2018年Sentinel-1 数据构建VH、VV 两种极化方式的时序数据集;利用2018年Sentinel-2 构建作物生长季(4月1日—10月30日)多光谱和遥感指数数据集。
2.1 Sentinel-1 时间序列
农作物的生长发育随时间发生改变,表现在光谱反射率变化、群体结构和郁闭度变化、高度变化等信息,遥感时序数据能监测上述动态变化特征,但研究区多云多雨天气致使光学数据影像难以进行大尺度长时间序列观测,可通过构建Sentinel-1时间序列分析农作物的时间变化特征,笔者在该地区使用Sentinel-1 时间序列数据开展的局部研究试验已经取得了比较好的农作物分类结果[22]。大尺度遥感观测需要将相邻不同轨道的卫星影像拼接形成满足观测范围和内容需求的影像产品,Sentinel-1传感器的相邻轨道存在时间差,可以通过多周期合成方式实现整体数据获取,即在研究范围内利用多时相合成数据以达到数据的最佳观测窗口,本研究对研究区Sentinel-1 数据进行月均值合成构建时序数据集。
SAR 数据存在相干斑噪声,会导致分类结果产生“椒盐现象”,本研究中利用Boxcar 滤波方法对多时相双极化Sentinel-1 数据进行斑点滤波处理,Boxcar 滤波在合成孔径雷达数据处理中通过用滑动窗口内连续的像素点的平均值,代替原有连续的像素点增强雷达信号的信噪比。相关的研究表明,使用Boxcar 滤波器后的多极化雷达数据能够提高数据的计算效率并能提高分类精度[23],其公式
2.2 Sentinel-2 生长季合成
利用Google Earth Engine 对研究区2018年的Sentinel-2 影像进行云量统计,分析云的分布特征(图2)。2018年4—10月研究区范围内共有4 651幅Sentinel-2 TOA 影像,其中云量低于20%的影像有1 945幅,占41.8%,且云量低于20%的数据主要集中在4月、9月和10月,无法在该区域利用多光谱数据制作时序数据集,本研究中使用Sentinel-2 影像合成生长季数据,以云量得分最低的像元复合成为一幅最小云量合成影像。利用Sentinel-2 生长季合成数据计算NDVI、NDWI、NDBI、EVI 和GVI,5个参数用以突出植被信息,区分水体、不透水面、沙地、滩涂等非作物区域;计算NDRE 用以突出作物间的差异。
2.3 分类特征变量
为了研究不同数据组合下的农作物提取能力,实现分类精度最大化,本研究利用滤波后Sentinel-1的VV极化方式、VH极化方式及VV+VH 极化时间序列数据集,Sentinel-2 多光谱波段、遥感指数、地形数据和土地利用数据组成多源数据集38个特征变量,进行对比分析(表2)。
2.4 随机森林分类器
随机森林是机器学习算法中一种将多棵决策树组合预测的算法,将投票次数最多的类别指定为输出结果,特别是对于高维特征的输入样本,无需降维和调整参数也可以得到很好的分类结果。RF的重要参数之一是决策树的数量,相比其他决策树算法,RF 算法不存在过度拟合的问题,但会产生一定限度的泛化误差[24]。BREIMAN 提出,泛化误差总是随着树的数量的增加而收敛[25],因此,决策树的数量可以尽可能大,但超过一定点时,多余的决策树对目标预测的贡献并不大。RF 已被证明在各种应用中具有良好的效果,本研究以最常用的500 树设定为默认值,并尝试调整决策树的数量以验证不同决策树下的分类效果。
3 结果与分析
3.1 农作物后向散射特征
不同地物的后向散射值会随着时间变化而产生变化,由图3可知,VVB和VHB极化方式下农作物表现出相同的变化趋势,即在120 d(4月30日)进入生长期,由于地表作物的生长,表面发生变化,由相对光滑的表面转为粗糙表面,导致后向散射系数增大,在180(6月29日)~240 d(8月28日)后向散射系数达到峰值,此时正值作物生长最旺盛的时期,随后作物的后向散射系数开始下降,主要原因是大部分作物在300 d 时成熟后向散射系数恢复120 d的水平,此时是农作物的收获期地表又恢复到裸露土壤的状态。

表2 分类特征变量
非农作物地类中,大兴安岭的林地类型主要为针叶林,四季变化不明显,林地类型在一年内没有大的起伏变化,在200(6月19日)~235 d(8月23日)后向散射系数略微升高并与农作物变化曲线相交,随后又略微下降,同理,城市、沙地及滩涂表面基本固定,因此,后向散射系数年内没有大的起伏变化。草地的曲线趋势与作物相似,100 d(4月10日),草地进入返青期,自125 d(5月5日)开始进入稳定期,变化幅度较小,250 d(9月7日)前后开始下降,此时草地进入了枯黄期。水体的VH 极化曲线表现为先下降后平稳的特征,主要原因是水体的冰融化导致。
不同的极化方式下,两种极化方式的变化趋势相似,地物的后向散射特征略有不同,主要表现在:VV极化方式的后向散射系数整体比VH极化方式高;VV 极化的相同节点上重叠度较高,不利于作物间、作物和非作物的区分,会导致分类精度下降。
3.2 农作物提取结果
3.2.1 不同分类特征集下分类结果分析 通过不同特征集的组合分类,得到了研究区农作物分类精度和Kappa 系数的分布情况(图4)。由图4可知,使用单独Boxcar 滤波后的VHB或VVB极化方式时间序列数据的分类精度都低于80%,使用Boxcar 滤波后的VHB极化方式时间序列数据的分类精度要高于VVB极化方式时间序列,验证了之前的后向散射变化曲线的分析结果,将两种极化方式时间序列进行组合后,数据间进行了优势互补,使分类精度有所提升,但分类精度仅有79.83%,上述结果说明仅使用Sentinel-1 时间序列数据进行分类仍然会存在较大的分类偏差,农作物提取能力具有一定的局限性;利用Sentinel-2 TOA 生长季合成数据及其衍生的指数特征集组合的分类结果略好于Sentinel-1 时间序列数据,引入辅助数据T(地形)和L(土地利用)后精度进一步提高为79.53%,由于研究区的作物关键生育期(7月、8月)大部多云多雨使得光学数据利用率较差,但光学数据仍有广泛应用潜力。
通过将Boxcar 滤波后的Sentinel-1 双极化雷达数据、Sentinel-2 光学数据以及辅助数据T(地形)和L(土地利用)进行组合VVB+VHB+M+I+T+L,最终得到87.41%的农作物分类精度,比单独的组合(VVB+VHB、M+I+T+L)提取结果分别提高了7.57个百分点和7.87个百分点,说明多源数据组合方式既可以利用Sentinel-1 提供作物的时间变化信息,又可以利用Sentinel-2 对农作物空间信息提取,同时辅助数据提高了分类精度。
3.2.2 最佳特征组合方式下不同决策树分类结果分析 使用VVB+VHB+M+I+T+L 组合分类结果的精度最高,为充分研究随机森林分类器中决策树对分类精度的影响,通过改变决策树的数量得到如图5所示的分类结果的精度对比结果。由图5可知,分类精度会随着决策树的变化而产生变化,较少的决策树可能无法捕捉目标预测细节信息,使用10 树的分类结果精度较低为85.01%,随机森林分类器中的决策树需保持足够多的数量,本研究中使用500 树的分类精度最高为87.41%,与300 树在保留小数位数后分类精度近似,它们之间也存在着细微差异。同时可以发现,当决策树的数量超过500 树,分类精度下降,表明过多的决策树并没有提高分类器的性能。
3.2.3 特征变量优选与评价分析 随机森林分类器可以输出特征变量重要性,用来评价特征变量对目标变量预测的贡献能力。本研究利用GEE 对所用的特征向量进行相对重要性计算,如图6 中展示了本研究中特征变量相对重要性排名的分布情况。
由图6可知,在参与分类的38 特征变量中,统计不同特征变量的重要性得分发现:不同特征变量的重要性得分差异较大,VHB6(9月合成数据)特征的重要性得分最高,对分类影响相对较大,而B10、SLOPE、LC_Type1 3个特征重要性得分低于500,表明这3个特征向量对分类影响较小。
由图7可知,可将分类精度变化趋势分为3个阶段。第一阶段(排名前1~8 特征),随着参与分类的特征变量的增加,分类精度呈现急速上升的趋势,从单个特征分类精度为23.77%迅速达到81.27%,这主要因为前期特征变量的重要性评分高,特征之间相关性小和冗余特征少,从而提高了分类器的性能,对精度提高有明显影响的分别是ELEVATION(24.21%)、VHB6(23.77%)、VHB4(16.98%)、B1(6.79%)、NDVI(5.70%);第二阶段(排名前9~24 特征)分类精度提升速度大幅降低,但是仍然呈现平稳上升的趋势,分类精度从81.27%逐步达到87.76%;第三阶段(排名前25~38 特征),分类精度呈现波动下降的趋势。这是因为后期冗余特征和不相关特征增加,降低了分类器的性能,导致分类精度降低。由图7也可知,当特征变量保持在相对重要性排名前24个时,分类精度和Kappa 系数均达到最大值,分别为87.76%和0.86,将前24个特征作为最终结果参与分类。
3.2.4 分类结果图形分析 使用特征优选后的数据提取农作物分布结果见图8。对比Google Earth 可看出,耕地与非耕地区分结果较好,耕地的结构明显,界限清晰;从农作物分布情况来看,农作物沿大兴安岭山麓分布,西南方向主要分布春小麦、春油菜等作物,东北方向主要分布玉米、大豆、水稻、高粱等作物,结果与实际情况吻合;从目视效果来看,西南方向作物提取效果较好,东北方向的作物提取效果较差。玉米大豆
从细节上看,分类结果中产生了许多破碎像元,主要集中在研究区东部,根据实际调查发现,2018年研究区东部夏季多雨产生洪涝灾害,导致作物长势不均匀,产生了混合像元(图9a、图9b),西部则影响较小,地块界限比较清晰,混合像元较少(图9c、图9d)。
4 结论与讨论
本研究使用Sentinel-1、Sentinel-2 等多源遥感数据,在Google Earth Engine 平台中对数据集进行特征优选,并在此基础上提取呼伦贝尔市的农作物分布信息。通过结果分析,获得了比较理想的作物分布图,可实现常规业务化监测。但本研究也存在部分不足之处,首先,在遥感指数的选取上仅依靠经验选取了部分指数,未进行更多试验以寻求最佳指数特征;其次,在县域尺度和全国尺度对模型参数还需进一步验证。未来在本研究基础上对数据选取、处理与研究方法加以改进完善,以期提高多源遥感数据在大尺度农业资源监测中的优势。
致谢:本研究的外业数据采集工作得到了内蒙古自治区农牧厅、呼伦贝尔市农牧局及其所辖各旗县区农牧(科技)局的大力协助,在此表示感谢!
