基于主成分分析与多元线性回归模型的铁路货运需求预测
2020-02-03孟祥爱宋欣悦
孟祥爱 宋欣悦
(北京交通大学计算机与信息技术学院 北京市 100044)
我国铁路发展起步很早,铁路网相对完善,铁路货运历史也很悠长。据中国国家铁路集团有限公司统计,2019年全国铁路固定资产投资完成8029 亿元,超额完成年初确定的8000 亿元任务,创下了近4年的最高值。同时2019年全国铁路投产铁路新线8489 公里。截至2019年底,全国铁路营业里程达到13.9 万公里以上。随着铁路交通的不断发展,铁路货运在我国货运体系中逐步占据关键地位。2019年,国家铁路完成货物发送量34.4 亿吨,创历史新高,同比增长7.8%。根据中铁总的《三年行动方案》,到2020年,国家铁路货运量预期达到37.18 亿吨。这意味着,2020年国家铁路货运量比2019年将增加8.1%。未来铁路交通将进一步发展,铁路货运需求也将会继续保持增长趋势。
在铁路货运需求态势持续增长的情况下,铁路货运需求预测变得尤为重要,一方面,相对准确的预测结果对铁路相关部门的决策可以提供一定的依据,对全国铁路固定资产投资具有指导作用,另一方面,我国铁路市场环境复杂,铁路货运量影响因素在持续变化,科学准确的预测方法更加必要。
对铁路货运需求进行预测,首先应当对铁路货运的影响因素进行分析,如宏观经济指标、大宗货物产量、其他运输方式之间的联系等。文献[1]将铁路货运需求预测方法分为以下几类[1]:时间序列法、影响因素法、组合预测法、四阶段法、机器学习法共五类,本文使用的方法为组合预测法,即通过灰色关联分析法和主成分分析法对已有的数据进行学习,找到数据间的依赖关系,使用多元线性回归模型对未知的数据进行预测,观察拟合值,计算相对误差,得到模型精度。
1 铁路货运量影响因素及其关联度分析
1.1 影响因素
由于铁路货运需求量是一个复杂的变量,为了更准确地对铁路货运量进行预测,应当综合全面地考虑铁路货运量的影响因素,但由于铁路货运量影响因素众多[2],部分影响因素的关联度相对较小,全部考虑则成本较大,因此本文选择文献[3]中灰色关联分析和ARDL 模型实证分析出的主要影响因素:国内生产总值、工业增加值、第二产业增加值、公路货运量、进出口总额、铁路营业里程、工业增加值占国内生产总值比重、第二产业增加值占国内生产总值比重共七个影响因素[3],通过下节介绍的灰色关联分析定量分析,得到各个影响因素与铁路货运量之间的关联度数据,进而得到与铁路货运量关联最大的影响因素。如表1所示。
其中公路货运量与铁路货运量是平行维度,国内生产总值、工业增加值、第二产业增加值属于宏观因素,此外货运量还应合理考虑各个影响因素对铁路货运量需求的影响,比如哪些是正影响,哪些是负影响,这些都在一定程度上对最终拟合效果的准确性有指导决定作用。
1.2 灰色关联分析
灰色关联分析法被广泛应用于铁路货运量预测当中,因此在介绍主成分分析法之前,首先介绍灰色关联分析方法,将灰色关联分析得到的关联度较高的影响因素应用到主成分分析法中,得到相应的主成分,最终将其得到的主成分替换多元线性回归分析中的各个影响因素,观察拟合值与相对误差。
灰色关联分析的基本思想是在建立确定反映系统行为特征的参考序列和影响系统行为的比较序列的基础上,计算比较序列相对于参考序列曲线几何形状的关联度,由此判断自变量与因变量之间的关系[4]。
灰色关联分析的具体计算步骤如下:
第一步:确定分析数列。对于本文来讲及确定哪些是影响因素(自变量),又称为比较数列,哪个是铁路货运需求量(因变量),又称为参考数列。
第二步,变量的无量纲化。在进行灰色关联度分析时,需要对数据进行无量纲化处理[5],防止因为影响因素的不便于比较的问题而难以得出正确的结论。
第三步,计算关联系数
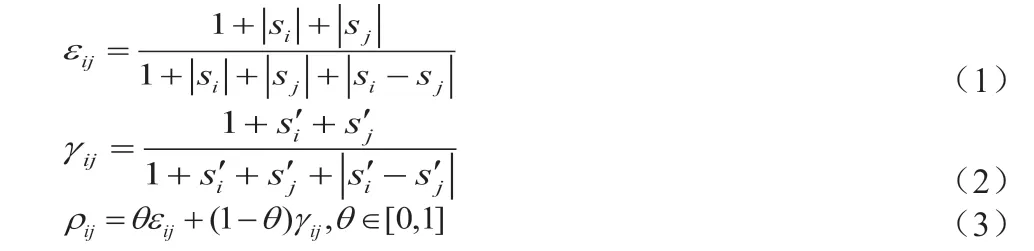
其中ρ即为相对关联系数,其中θ∈(0,∞),称为合成系数。θ越小,分辨力越大,一般θ 的取值区间为(0,1),具体取值可视情况而定。当θ ≤0.5463 时,分辨力最好,通常取θ=0.5。
第四步,计算关联度。因为关联系数是比较数列(自变量)与参考数列(因变量)在各个时刻(即曲线中的各点)的关联程度值,因此得到的数据很多,而信息过于分散不便于进行整体性比较。因此有必要将各个时刻(即曲线中的各点)的关联系数集中为一个值,即求其平均值,作为比较数列与参考数列间关联程度的数量表示,关联度记为ri[6]。
第五步,关联度排序。关联度按大小排序,如果r1<r2,则参考数列y 与比较数列x2 更相似。关联度越接近1,则说明该影响因素与铁路货运需求量之间的关系越亲密,及自变量对因变量的影响最大。在算出Xi(k)序列与Y(k)序列的关联系数后,计算各类关联系数的平均值,平均值ri 就称为Y(k)与Xi(k)的关联度。
根据灰色关联分析,得到各个影响因素的关联度如表2,并进行排序,可以看到各个影响因素与铁路货运量的关联度都达到了0.5以上,其中公路货运量对铁路货运量的影响是几个影响因素中最大的,其次是铁路营业里程和工业增加值,而第二产业增加值占国内生产总值比重和工业增加值占国内生产总值比重的影响则最小,这也为今后的决策制定提供了方向。
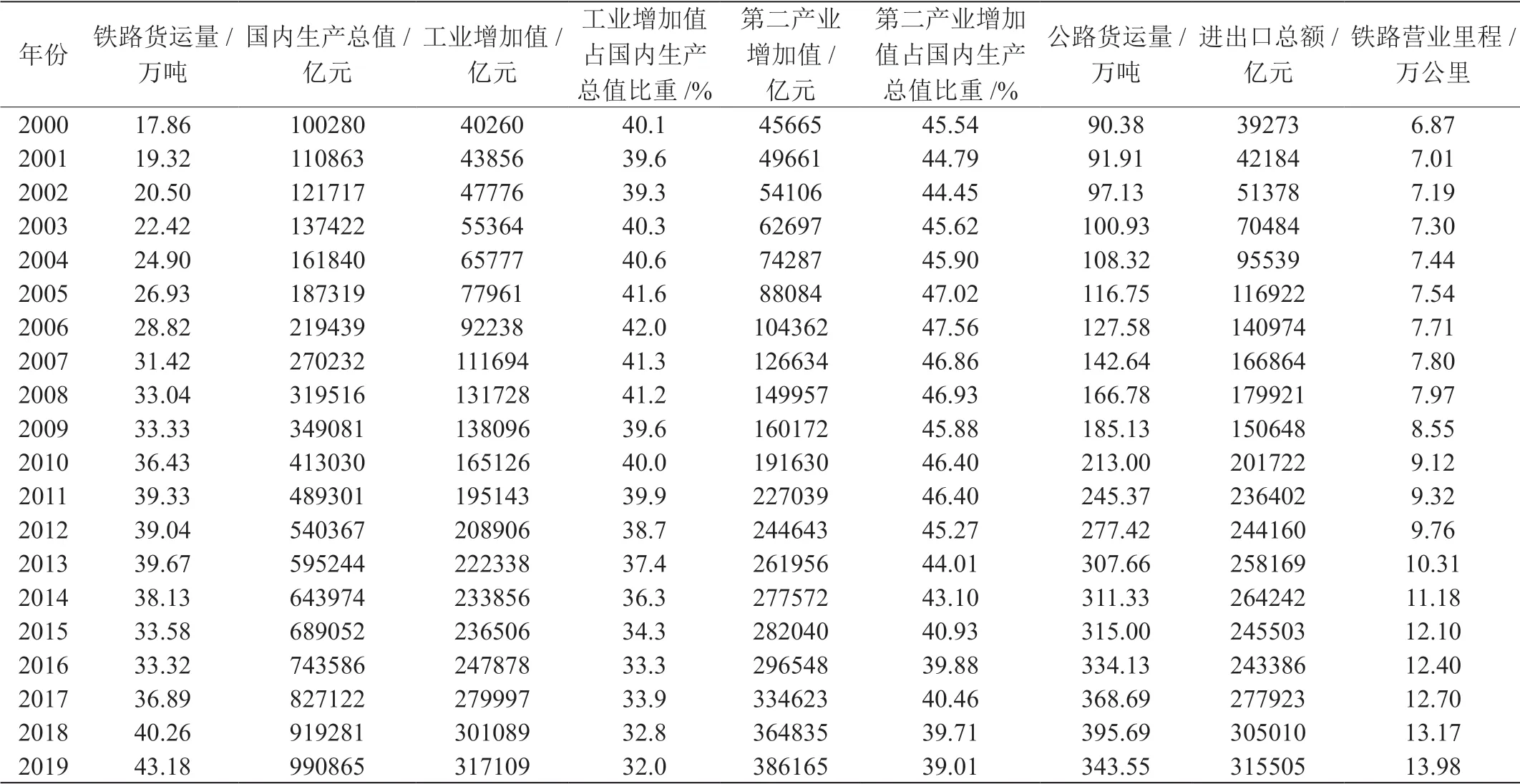
表1:2000~2019年我国宏观经济与综合交通运输体系各指标的年度数据

表2:2000~2019年铁路货运量与各变量的灰色关联分析结果
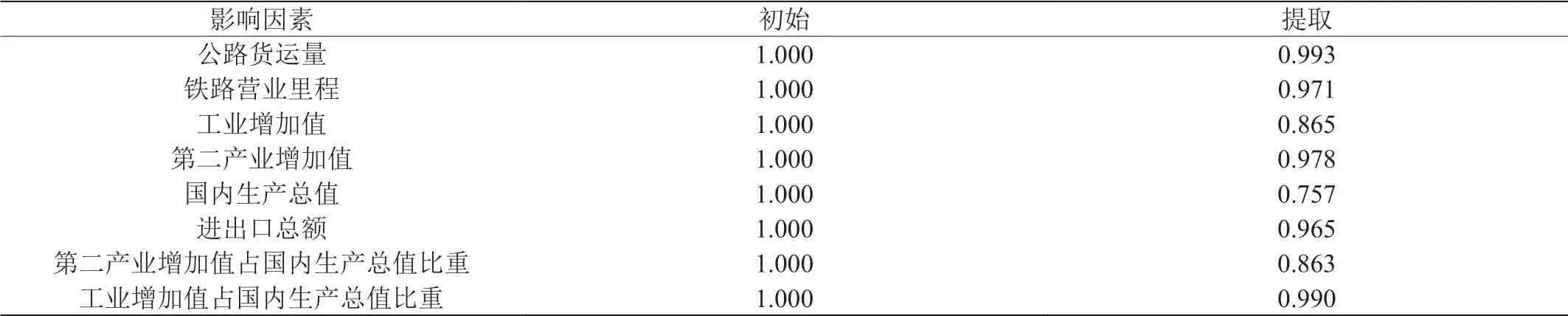
表3:主成分分析法成分矩阵
1.3 主成分分析法
主成分分析[7]就是用较少的变量去解释原来资料中的大部分数据,将很多相关性很高的变量转化成彼此相互独立或不相关的变量。通常是选出比原始变量个数少,能解释大部分变量的几个新变量,称为主成分,并用以解释数据变化的综合性指标。主成分分析实际上是一种降维方法,在力保数据信息丢失少的原则下,对多个变量数据进行最佳综合简化,即对高维变量空间进行降维处理[8]。
主成份分析是最经典的基于线性分类的分类系统[9]。这个分类系统的最大特点就是利用线性拟合的思路把分布在多个维度的高维数据投射到几个轴上。如果每个样本只有两个数据变量,这种拟合就是线性拟合。
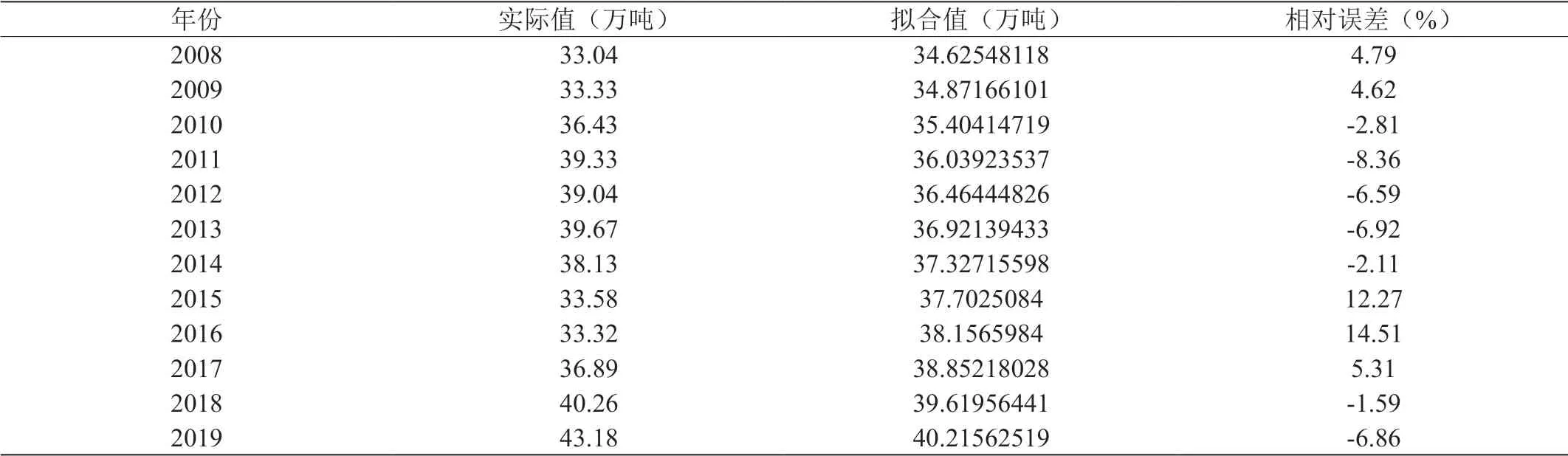
表4:一元线性回归分析模型得到的拟合值
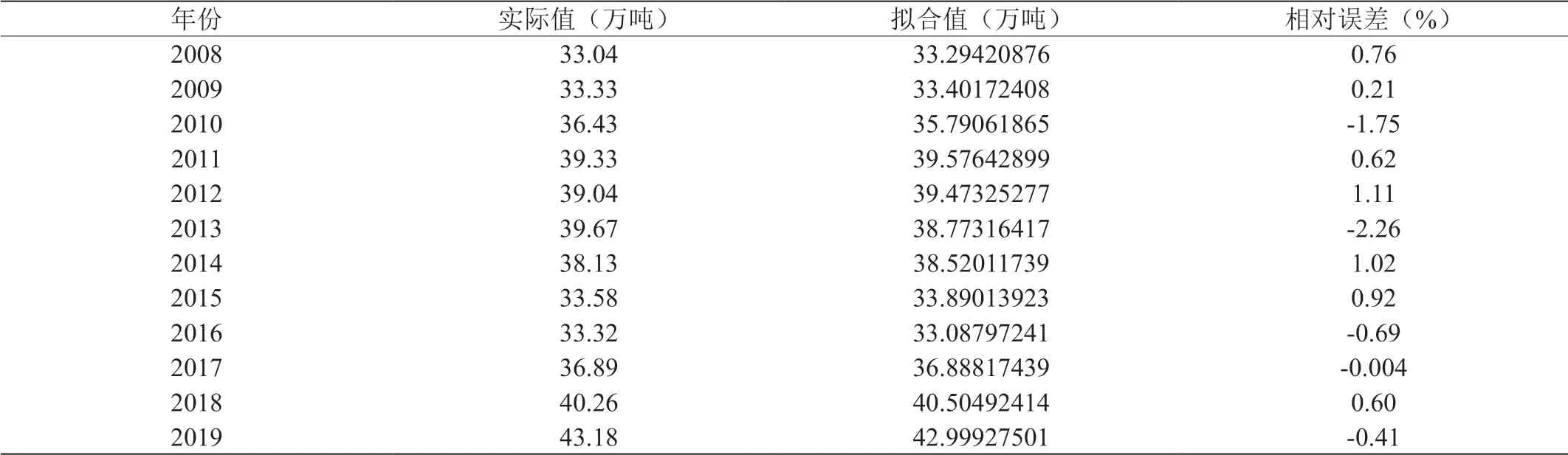
表5:多元线性回归分析模型得到的拟合值(共六个影响因素)
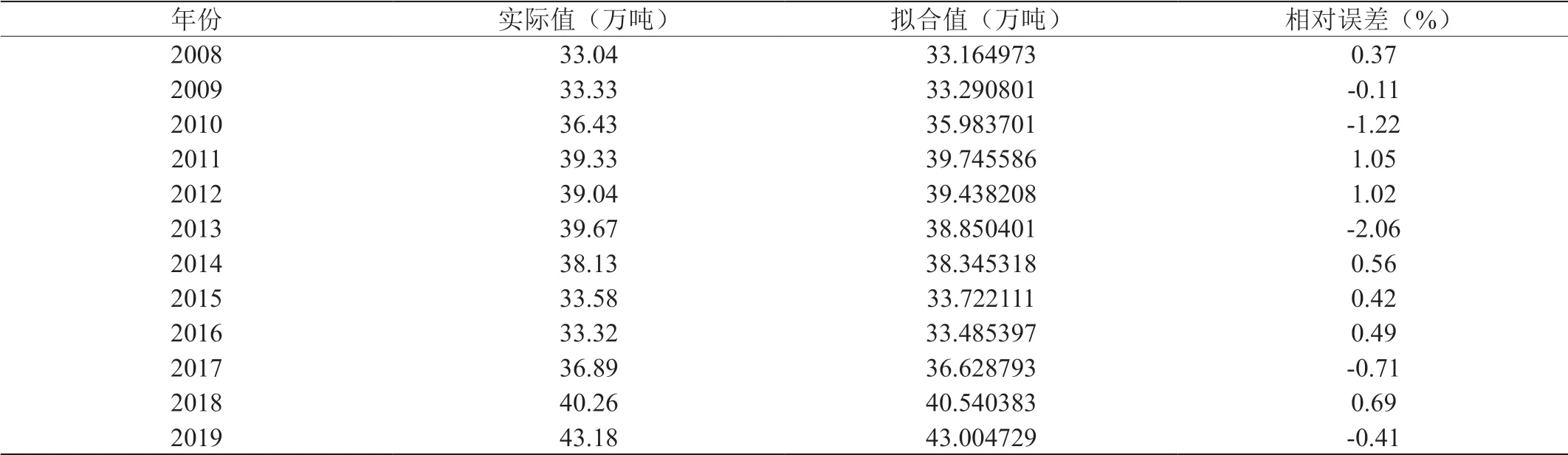
表6:基于主成分分析法与多元线性回归分析模型的拟合值
a1x1+a2x2=P 其中x1和x2分别是样本的两个变量,而a1和a2则被称为loading,计算出的P 值就被称为主成份。实际上,当一个样本只有两个变量的时候,主成份分析本质上就是做一个线性回归。公式a1x1+a2x2=P 本质上就是一条直线。如果一个样本有n 个变量,那主成份就变为:a1x1+a2x2+......+anxn=PC1,其中PC1称为第一主成份,以此类推可以得到第二主成分、第三主成分等。
将灰色关联分析得到的影响因素带入,得到主成分得分系数矩阵如表3。
2 基于多元线性回归模型进行铁路货运量需求预测
2.1 多元回归分析模型
2.1.1 多元回归分析模型简述所谓回归分析法,就是在掌握大量观察数据基础上,利用数理统计方法建立因变量与自变量之间的回归关系函数表达式(简称为回归方程式)。回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测值)之间的关系,这种因变量与自变量的不确定性的关系(相关性关系)。这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。
一元线性回归指的是只有两个变量x 与y,其中x 为自变量,y 为因变量。并且y 与x 成某种线性关系。这样的情况我们称其为一元线性回归问题。其基本形式为:Y=a+bx+c
其中,a、b 均为参数项。c 为随机变量,因为在两组变量之间,是无法满足严格的线性关系的。所以,此项是补齐线性关系之中误差,也称为扰动项。想要拟合线性关系,两组变量需要满足一一对应关系,相当于形成若干组键值对。但想要线性回归真实可靠还需要注意,所有的扰动项还需要保持同方差、正态分布、互相独立、零均值的情况才能保证线性回归所估计出的值是真实可靠的数值。对于自变量X 的要求则是非随机保证其为确定性变量。还需要保证自变量与扰动项之间不相关,若存在相关关系只可能是线性方程中参数估值存在误差。对于所有的扰动项分布都要遵循正态分布,如图所示。只有这样线性回归所估计出的模型才可以采信。
在对函数进行拟合之后,我们可以得到一个线性模型:y=a+bx。其中,a 与b 是参数a 和b 的拟合值。y 是y 的估计值,也称回归值。其中,我们采用的同一个总体之中的不同样本集也会得到不同的回归直线。样本集越大,样本回归直线越接近总体回归直线。所以,我们在训练线性模型的时候选取合适的样本大小可以得到一个较为精确的回归直线。
为了获取线性参数a 和b,可以选择最小二乘法,通过最小化真实值与估计值的误差平方和(MSE)来进行模型的判定。代价函数为下式:
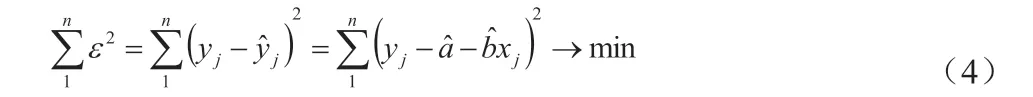
得到关于拟合参数a 与b 的函数后,要求此函数极值要对两个参数分别求偏导,并使其偏导数为0。在此情况下求出的参数即为模型的拟合参数。在一元线性回归之中,选择这样的方式是比较简便的。但在多元模型中,正规方程求解的办法就会比较消耗时间,这时我们往往会选择梯度下降法来求多元函数的极值。求解后可得:

上述结果即为通过正规方程求解法得出的,一元线性回归拟合参数值。
多元线性回归的主要特点是,自变量不再是一组数据,而是由多于一组以上的数据作为自变量。所以,多元线性回归的模型形式为:
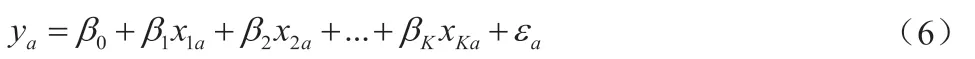
多元线性回归方程与一元线性回归方程一样,通过最小二乘法进行参数估计。所以我们可以得出下式:
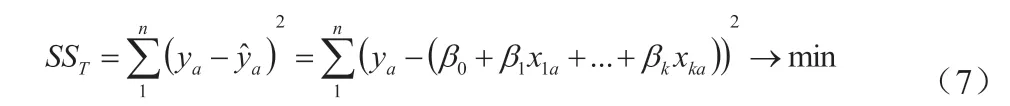
通过对此式求极值,可以得到一个针对不同参数求导的方程组,我们对这个方程组进行整理,将方程组所有的数据项进行展开,并参照矩阵乘法的方法,对所得出的式子继续化简,并得出参数矩阵b 的求解式子:

2.1.2 实验结果分析
由于2008年之前的实际值与当前实际值相差较多,且年代久远,近年来各影响因素都发生了很大的变化,因此参考意义不大,本文选用08年~19年共十二年的数据,首先构建一元线性回归模型对数据进行拟合,观察拟合值,求得相对误差如表4所示。
如表4,平均相对误差为6.40%,由此可见使用关联度最大的公路货运量为影响因素得到的一元线性回归模型拟合效果一般。
表5 为使用关联度0.55 以上的影响因素:公路货运量、铁路营业里程、工业增加值、第二产业增加值、国内生产总值、进出口总额(共六个),构建多元线性回归模型得到的拟合值与相对误差。
平均相对误差为0.86%,拟合效果较好。而采用主成分分析法与多元线性回归模型得到的结果如表6所示。
平均相对误差为0.75%,为几种方法中拟合效果最好的。
2.2 预测结果比较分析
通过对比一元线性回归模型、灰色关联分析与多元线性回归模型结合、主成分分析法与多元线性回归模型结合得到的拟合值与相对误差,可以看出基于主成分分析法与多元线性回归模型的拟合效果是最好的,一元线性回归模型拟合效果较差,这也验证了铁路货运需求量受多方影响,是一个很复杂的因变量,在预测过程中需要我们综合考虑多方面的影响因素,才能更科学准确地进行预测,只考虑一种很难得到理想的结果。基于主成分分析法与多元线性回归模型的方法综合考虑了多种影响因素,因此有较好的拟合效果。
3 结论与展望
本文采用主成分分析与多元线性回归模型结合的方法对铁路年度货运量进行预测,既可以解决影响因素的冗余的问题,又可以综合考虑影响因素的影响,不会漏掉关键影响因素。主要实验过程为首先对铁路货运需求相关的影响因素进行灰色关联分析,并按关联度大小排序,选出影响因素中关联度较大的几种,然后采用主成分分析法得到相关主成分,带入多元线性回归模型中,观察拟合值与预测值,计算相对误差。同时使用一元线性回归模型、灰色关联分析与多元线性回归模型对处理过的数据集进行分析,同样得到相应年份数据的拟合值,计算出相对误差。形成对比试验,通过比较相对误差,得出结论基于主成分分析法与多元线性回归模型的拟合效果是最好的,这种模型综合考虑了所有影响因素,又避免了信息冗余,在铁路年度货运量的预测中有较好的结果,相对误差可达0.75%。
同时本文存在一定的局限性,未能将此方法应用在月度数据,或具体某一物品的年度铁路货运量预测上,如煤炭、铁矿石等,可在今后的实验中验证此种方法是否适用于其他场景。
