基于大数据的机动车环污检测系统的研究与应用
2020-02-03李剑曹文雅
李剑 曹文雅
(河北云联网络科技有限公司 河北省石家庄市 050000)
1 引言
随着经济社会发展和国家环保工作的纵深推进,机动车排气污染排放占大气污染物排放比重越来越大,导致空气中各种污染物的数量和浓度呈逐年上升趋势,严重危及人类的健康。虽然各市、省都在建立机动车污染大气防止系统,但由于各类系统数据较为分散,无法形成统一的数据格式,并且随着时间的推移,数据量呈现爆炸式增长,这也大大的为管理人员造成了数据准确性、及时性的困扰。本文从机动车环污检测系统出发,在原有数据收集基础上建立以Hadoop 为集群的大数据集群,在数据收集时进行数据处理,并直接将数据灌入大数据集群中,在短时间内将大量数据进行预计算,最终为领导层提供全省机动车现状及污染物排放数据支撑。
2 相关工作
2.1 Hadoop平台简介
Hadoop 由HDFS、MapReduce、YARN、Common 四个模块组成,HDFS:高吞吐量的分布式文件系统;MapReduce:分布式的离线并行计算框架;YARN:任务调度与资源管理;Common:为其它模块提供基础设施。如图1所示。
2.2 Hadoop核心设计
Hadoop 核心设计如图2所示。
2.2.1 HDFS
是Hadoop 中数据存储管理的基础,是一个高度容错的系统,能检测和应对硬件故障。它以流式访问模式访问应用程序的数据,这大大提高了整个系统的数据吞吐量,因而非常适合用于具有超大数据集的应用程序中。
HDFS 架构采用主从架构(master/slave)。一个典型的HDFS集群包含一个NameNode 节点和多个DataNode 节点。HDFS 通过NameNode、DataNode 和Client 来进行文件系统的管理,NameNode 是分布式文件系统中的管理者,主要负责文件系统中的命名空间、集群配置信息和存储块的复制等;DataNode 是文件存储的基本单元,它将文件块存储在本地文件系统中,并且周期性地将所有存在的文件块信息发送给NameNode;Client 是需要获取分布式系统文件的应用程序。
MapReduce 是一个高性能的分布式计算框架,用于对海量数据进行并行分析和处理。与传统的数据仓库和分析技术相比,MapReduce 更适合处理结构化、半结构化和非结构化数据。MapReduce 任务运行在多个服务器上,指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。把一堆杂乱无章的数据按照某种特征归纳起来,然后处理并得到最后的结果。Map 面对的是杂乱无章的互不相关的数据,它解析每个数据,从中提取出数据的特征(Key 和Value)。经过MapReduce的Shuffle 阶段之后,在Reduce 阶段看到的都是已经归纳好的数据。
2.3 ETL工具Kettle简介
Kettle 是一个组件化的集成系统,包括如下几个主要部分:
(1)Spoon:图形化界面工具(GUI 方式),Spoon 允许你通过图形界面来设计Job 和Transformation,可以保存为文件或者保存在数据库中。也可以直接在Spoon 图形化界面中运行Job 和Transformation。
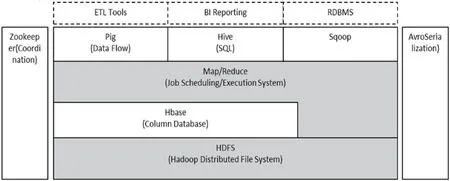
图1
(2)Pan:Transformation 执行器(命令行方式),Pan 用于在终端执行Transformation,没有图形界面。
(3)Kitchen:Job 执行器(命令行方式),Kitchen 用于在终端执行Job,没有图形界面。
(4)Carte:嵌入式Web 服务,用于远程执行Job 或Transformation,Kettle 通过Carte 建立集群。
(5)Encr:Kettle 用于字符串加密的命令行工具,如:对在Job 或Transformation 中定义的数据库连接参数进行加密。

图2
3 研究概况
此次研究数据来源主要包含:车辆定期检验数据、车辆遥感抓拍数据、车辆路检路查数据、车辆黑烟车抓拍数据、车辆OBD 远程在线监控车辆数据。此次研究采用以上五类数据进行数据融合,采用Hadoop 集群对数据进行ETL 数据清洗、转换、归类,形成统一的数据资源池,供系统进行数据调取及展示,通过一系列数据处理后,查看系统在保证数据一致性、完整性、实时性的基础上进行数据调取时性能指标是否满足日常需求,为领导层提供决策支撑。
心怡说:“我们的爷爷奶奶,外公外婆,他们是50后或60后,他们剩下的日子不是很多了,我的外公外婆身体也不好了,我很难受。”这时,教室里一片沉默。
4 详细描述
此次研究涉及到的五类数据量级依次为:定期检验数据、遥感抓拍数据、路检路查数据、黑烟车抓拍数据采取2018年-2019年两年(4TB)的全省数据进行研究;OBD 远程在线监控车辆数据采用2019年1-6月份(10TB)的数据进行研究。
此次研究搭建的系统采用Hadoop 分布式系统的基础架构;采用Hbase 对数据进行分布式存储;采用Hive 数据仓库工具对数据进行提取、转化、加载、查询、分析等;采用sqoop 在Hive 与传统数据库之间进行数据传递,采用zookeeper 为整个分布式应用提供一致性服务,包含配置维护、分布式同步等。集群采用1 主节点5 从节点及1 主节点10 从节点的两种方式进行。
依次将五类数据灌入到Hadoop 集群中,车辆信息以定期检验数据为准,建立基于一车一档的车辆基本信息,将定期检验、遥感抓拍、路检路查、黑烟车抓拍数据中的超标数据建立超标数据资源库,按照汽油、柴油对车辆进行分类,柴油车中按照车辆总质量进行详细分类,对于重型柴油车筛选出高排放车辆并建立高排放车辆资源池,进行重点监控。将OBD 远程在线监控车辆进行车辆信息匹配,获取各个车辆的排放阶段以及上传的实时数据,以国标为依据进行超标数据筛选,对OBD 远程在线监控车辆进行ETL 数据提取、转化、加载后存入至正式资源库中,并对数据进行预计算,供数据匹配及查询分析。将高排放车辆匹配OBD 远程在线监控车辆,进行车辆运行轨迹数据筛选,并耦合至地图中,根据排放因子对高排放车辆污染物计算,在地图中标注出污染较为严重的主要国道、省道、高速、乡道等。以黑烟车数据抓拍为基础,匹配定期检验、遥感抓拍、路检路查数据,进行匹配溯源,以车辆品牌、车辆型号、发动机型号等为粒度,进行数据分类展示。
在进行OBD 远程在线监控车辆时,系统首次引用了污染管控及环境参数,在天气晴朗及重污染天气下,分别对某地区环境污染物浓度进行监测。同一环境参数下,过往车辆对于此地区的环境污染物浓度影响较大。
在系统满足以上所有指标的基础上,生成以上五类数据,数据总量为1TB,作为系统实时性性能指标测试的基础,在以上14TB数据处理后,对系统进行查看,是否满足目前应用与管理的要求,并对系统进行优化测试。将1TB 实时数据灌入集群中,查看集群负载及运行状况,在系统中查看数据实时展示效果,是否满足需求。
5 预期结果
5 节点集群对于上述15TB 数据处理上能基本满足应用需要,但在实时性上无法保证是否满足系统性能要求;10 节点集群则能完全满足上述15TB 数据处理,并且在实时性上可以满足系统性能要求,对于节点数量的不同,主要差别在于数据容量及数据处理能力上,经过大量实验后,实验表明在以上数据量级的基础上,1 主节点10 从节点完全满足管理部门日常需要并且在数据容量扩展上也基本满足数据存储要求,数据完整性、一致性、实时性上能做到快速处理并呈现的要求。
6 总结
通过Hadoop 集群对15TB 的数据进行处理及展示,发现系统在性能要求上,10 节点的集群相较于5 节点的集群,数据处理能力上有很大的提升,数据实时性上面,最大延迟在90 秒之内,符合目前应用与管理的要求。溯源的超标数据及高排放数据,经过应用系统及视频监控系统确认后,均为可利用的超标数据,此类数据进行分类归档,为后续业务检查及执法提供数据来源及执法依据。
在进行OBD 远程在线监控车辆时,对某地区进行环境污染物浓度监测,发现在同一环境参数下,过往车辆对于地区的环境污染物浓度影响较大,系统在这一基础上,即会采取重污染天气应急污染管控措施,对重污染区域采用限行,工业企业减排等手段。对于发现高排放车辆连续使用排放超标的情况,可进行设置道路卡口的方式对此类车辆进行拦截,并指定维修点进行维修,为防治大气污染提供有力的数据支撑。
