基于Multi-attention的文本语音多媒体情感分析
2020-02-03佟德超
佟德超
(沈阳化工大学计算机科学与技术学院 辽宁省沈阳市 110000)
1 概述
之前的情感分析大多集中在对文本数据的分析上,但如今人们表达情感的方式早已不仅仅局限于单模态的文字,而是同时包含音频信息、视频信息、和文本信息的多媒体数据,因此多媒体数据情感分析的研究正在变成一个越来越受重视的研究方向[1]。单模态的数据只需处理好模态的内部信息,但对于多模态的数据来说还需处理好模态间的交互信息,这也是多模态情感分析的关键和优势所在[2-3]。
与单模态相比,多模态的情感分析在处理好单模态信息的基础上还需要处理好不同模态之间的信息交互问题。单模态的特征信息通常使用卷积神经网络(Convolutional Neural Networks,CNN)、门控制循环单元(Gated Recurrent Unit,GRU)、或者长短期记忆网络(Long Short-Term Memory,LSTM)来获取。多模态的信息主要有早融合和晚融合两大类方式,早融合是把各个模态的信息拼接之后输入到模型中训练,早融合的一种方式是使用LSTM。晚融合是先单独训练,然后进行决策投票。情感分析任务中句子的语境也会影响句子的情感倾向[4],但传统的方法大都忽略了这一点。之前的研究中不乏对文本和音频的研究,You 等人提出了一种跨模态一致回归模型(CCR)。Porias 等利用卷积神经网络(CNN)分别提取文本和音频数据的特征之后进行多核学习来进行特征融合。Zadeh等提出了图记忆融合网络和张量融合网络来进行信息的融合。以上方法较传统的方式相比有了一定的提升,但是没能做到单模态内部信息和各个模态之间交互信息的联合学习,而且无论是单个模态的信息还是多个模态之间的交互信息都只关注了局部的特征,没有结合全局的信息,导致多模态的信息融合也不够充分。
为解决上述问题,本文提出了一种基于Multi-attention 的多媒体情感分析方法。该方法使用Multi-attention 进行多媒体数据的信息交互,让多媒体特征进行更充分的交融。最后使用softmax 对情感进行分类。
2 模型结构
图1 中展现了基于LSTM 和Multi-attention 的多模态情感分析的模型框架图,简称为MAM 模型。
模型主要分为以下几个部分:
(1)文本和语音的嵌入方式。
(2)文本和语音的单独的信息交融。
(3)文本和语音之间的信息交互。
2.1 文本和语音的嵌入方式

图1:基于注意力机制的多模态情感分析模型框架图
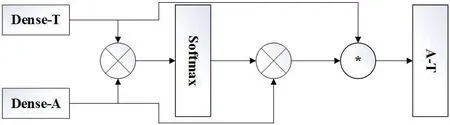
图2:模态交互注意力机制计算流程图
初始的嵌入我们使用由卡内基梅隆大学提供的多模态数据工具包(CMU-Multimodal SDK)。我们使用MOSI 语料库,该语料库中的特征是句子级别的,其中文本特征由基于词语共现矩阵的GloVe 模型获取,语音特征由Cova-Rep 语音分析框架获取。由于多个模态的数据在表达同一含义时所需的特征长度是不同的,所以需要对各个模态进行对齐。使用工具包中的P2FA 将单词和对应的音频视频数据对齐,这种对齐方式也是被应用较为广泛的,同时也是更容易被理解的一种多模态数据的对齐方式。经过以上方式对原始数据进行嵌入之后,假设该视频片段中有n 个句子,则本文的初始特征T∈Rn*100,音频特征A∈Rn*73。
2.2 单模态的信息交融
单模态的信息抽取主要依靠的是Bi-LSTM,该模型可以从前后两个方向来获取句子间的关系。单向的LSTM 模型是当前隐层状态携带了前面隐层状态的信息,但有时当前隐层状态与后面的隐层状态的信息也有很大的关联,所以需要同时考虑前后两个方向的隐层信息。Bi-LSTM 的计算公式如下:

2.3 模态间的信息交互
在2.2 节中我们分别得到了文本和声音的经过了Bi-LSTM 层和Dense 层的特征表示,在本节中我们的任务是把多个模态的信息进行交互融合,发掘出模态与模态之间的交互信息。也就是图1 中的Multi-Attention 部分,该模块实现了对两种模态的信息交互的目的,其结构如下:
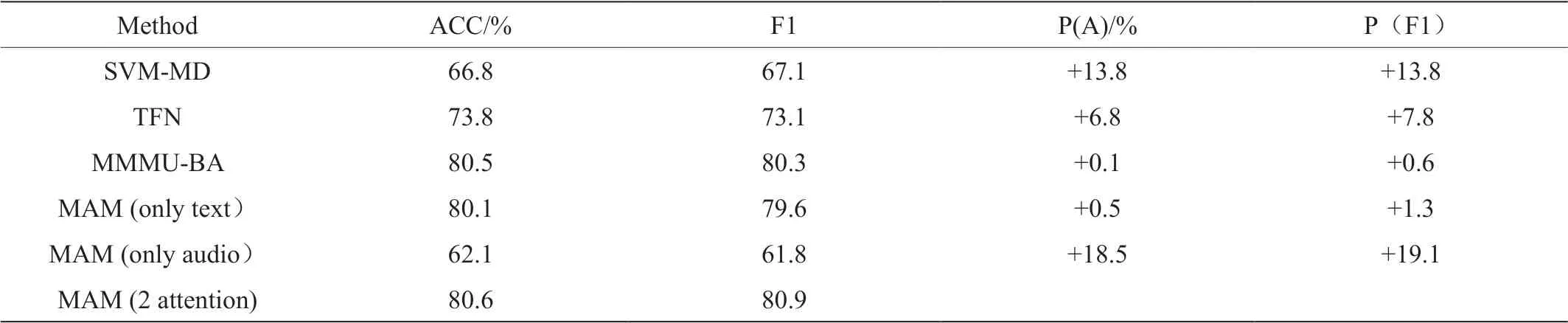
表1:不同模型实验结果
图2 中的x 表示dot 运算(矩阵乘法运算),*表示multiply运算(元素乘法运算),首先用经过了Bi-LSTM 和Dence 层的特征Dense-A 和Dense-T 进行dot 运算计算出Dense-T 特征对Dense-A 特征的相似度矩阵D。
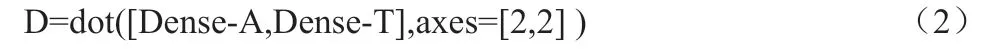
矩阵D 经过softmax 之后得到的代表着Dense-T 特征对Dense-A 特征注意力权重的矩阵N。用Dense-A 与矩阵N 进行dot运算可以得出融合了Dense-T 信息的Att-At 特征,公式如下:
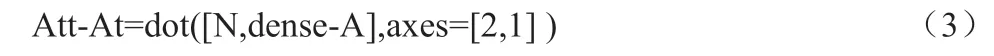
最后,在每个经过了Multi-Attention 特征融合表示之后的单独模态的特征与其他模态之间计算了一个乘法门控函数,这种元素矩阵乘法有助于处理多种模态和句子的重要组成部分。
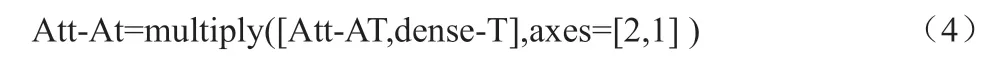
式(3)中Att-At 为语音信息融合了文本信息的特征。用同样的方式可以求出文本融合了语音的信息Att-aT,公式如下:
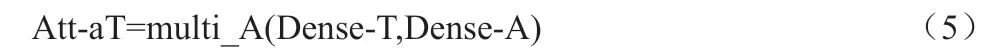
同时为了更好的考虑单个模态特征对自身特征的注意力分布,特征融合层还将两种模态分别做了自注意力机制(self-attention)操作,其计算方式与多模态attention 基本一致。可以得到特征Att-AA 与Att-TT:

最终的融合特征merged 表示为:

3 实验与结果
3.1 实验
3.1.1 实验设置
实验中Bi-LSTM 的单元个数bi_lstm_units 为300,正则化参数drop_bilstm 为0.8,Dense 层的单元个数dense_units 为100,正则化参数drop_dense 为0.8。本实验选择Accuracy 和F1-score 作为评价指标。
3.1.2 对比实验
为验证本实验模型的有效性,将本实验的模型与如下模型进行对比实验:SVM-MD,TFN,MMMU_BA,MAM,本文提出的方法,其中MAM(only text)为单文本模态,MAM(only audio)为单语音模态。
表1 中的P(A)和P(F1)分别表示论文方法BLAM(2 attention)与对比方法在ACC 和F1 指标上的差值。
3.2 实验结果分析
通过表1 中的对比实验数据结果可以看出,总体来说本文提出的多模态情感分析模型的表现优于其他的对比模型。所提方法与SVM 等传统机器学习方法对比在accuracy 指标和f1-score 指标上都有较高的提升,与近期先进的深度学习方法TFN 和MMMU-BA等对比,在两个指标上也有一定的提升,突出了充分考虑上下文语境以及attention 机制融合信息的重要性。
4 结束语
本文提出了一种基于双向长短期记忆网络和注意力机制的多模态情感分析方法。通过Bi-LSTM 和self-attention 从全局语境上更加充分的获取单个模态信息,再通过multi-attention 进行模态间的信息交互和融合,使单模态更加关注其他模态的重要组成部分,最后通过分类器完成多模态情感分析的任务。本文以MOSI 作为实验的数据集,在对比实验中本文所提的方法表现优异。但是由于现有的资源有限,只在相对小的数据集完成了实验,未来会尝试在更大的数据集去完善我们的方法。
