基于聚类分析和Apriori算法的个性化推荐研究
2020-02-03刘玥波刘田
刘玥波 刘田
(1.吉林建筑科技学院 吉林省长春市 130114 2.启明信息技术股份有限公司 吉林省长春市 130122)
消费购物一直是人类生活中不可避免的一项活动,随着计算机技术与互联网技术的飞速发展,越来越多的人习惯于网上购物,尤其是面对特殊情况,无法实现线下购物时,网上购物为人们的生活带来了更大的便利。面对网上海量的商品信息,用户通常感觉无从选择,同时虚拟的网络无法让用户直观地检查产品的外观和质量。在这种情况下,用户迫切地希望网上购物系统能够提供一种类似购物助手的功能,可以根据用户自身的兴趣爱好推荐他们可能感兴趣而且满意的产品[1]。另一方面,海量数据、各类推荐算法与数据挖掘技术的发展,为个性化推荐提供了技术支持[2]。
1 聚类分析
聚类分析是数据挖掘的主要方法之一[3],聚类算法分析主要是将对象的集合划分为多个聚簇,以“物以类聚”为原理,对本身没有类别的样本集根据样本之间的相似性程度分类,彼此相似的样本被归为一类。聚类是在事先不知道样本类别的基础上分类,属于无监督的学习,这一点与分类有本质的区别,分类是用已知类别的样本集来设计分类器,属于有监督的学习。聚类分析的目的是使同一个簇的样本之间彼此相似,而不同簇的样本之间足够不相似。
1.1 K-means 聚类算法思想
1967年Mac Queen首次提出了K均值聚类算法(K-means算法),该算法已广泛地应用于科学研究和计算机网络。聚类分析作为一种非监督学习方法,是机器学习领域中的一个非常重要的研究方向[4]。
该算法首先随机选取K 个点,作为初始聚类中心,这也是该算法一个关键输入,通过确定K 值的典型方法是依据某些先验知识可通过测试不同的K 值进行探查聚簇的类型信息,从而最终选定适合的K 值。然后计算各个对象到所有聚类中心的距离,以欧式距离作为鉴定相似程度的标准,将对象归入到离它最近的那个聚类中心所在的类,目标函数如下所示:
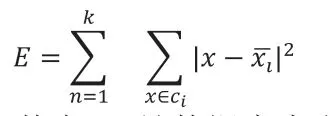
其中,E 是数据库中所有对象的平方误差总和,x 是空间中的点,表示给定的数据对象,是簇ci的平均值[5]。
1.2 k-means算法描述
输入:数据集D,聚族数k
输出:聚簇代表集合C,聚簇成员向量m
(1)从数据集D 中随机挑选k 个数据点。
(2)使用k 个数据点构成初始聚簇代表集合C。
(3)将D 中的每个数据点重新分配至与之最近的聚簇均值。
(4)更新聚簇均值,即计算每个对象簇中的对象均值。
(5)计算目标函数。
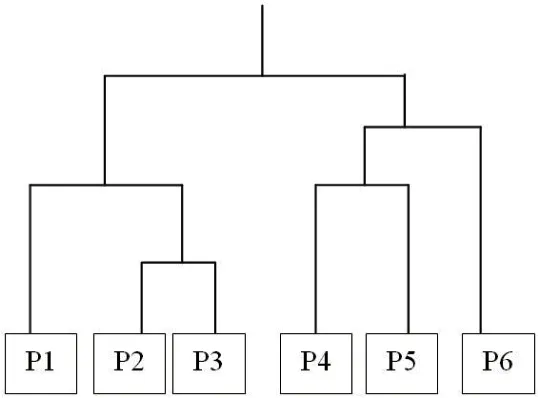
图1:层次聚类结果
(6)重复(3)(4)(5),直到目标函数收敛。
1.3 K-means 算法存在的问题
K-means 十分容易理解,也很容易实现,但同时也存在以下不足之处。对于离群点和孤立点敏感; k 值选择无法确定,必须首先给出k(要生成的簇的数目),而事先并不知道给定的数据应该被分成什么类别才是最优的; 初始聚类中心的选择,一旦初始值选择的不好,可能无法得到有效的聚类结果;只能发现球状簇。
2 关联规则
关联规则是数据挖掘中一个比较重要的挖掘方法,关联规则挖掘用于寻找给定数据集中数据项之间有趣的关联或相关联系。关联规则揭示了数据项间未知、隐含的依赖关系。根据挖掘出的关联关系,可以从一个数据对象的信息,来推断另一个数据对象的信息。
2.1 关联规则概念
若X、Y 均为项集,且X⊂I,Y⊂I,并且X ∩Y=∅,则形如X →Y 的蕴涵式即为关联规则。其中,X 和Y 分别被称为关联规则的先导(前件)和后继(后件)。
对于项集X,设定count(X)为交易集D 中包含X 的交易的数量,count(D)为事务总数,则项集X 的支持度为:
关联 规则X →Y 的支 持度 为项 集X⋃Y 的 支持 度:
最小支持度是项集的最小支持阈值,记为minsup。支持度不小于minsup 的项集称为频繁项集,否则称为非频繁项集,长度为k的频繁集称为k-频繁集。
规则X →Y 的置信度表示D 中包含X 的事务中有多少可能性也包含Y,即表示规则确定性的强度,记作confidence(X →Y)
最小置信度是由用户定义衡量置信度的一个阈值,记为minconf。
2.2 Apriori 算法
由 Rakesh Agrawal 和 Ramakrishnan Skrikant 提出的Apriori 算法是关联规则算法中最经典、最基础、研究最广泛的算法之一[6]。算法在挖掘的过程中,通过不断迭代地扫描事务数据库,扫描整个数据集,得到所有出现过的数据,作为候选1 项集C1,然后通过连接和剪枝步骤计算支持度Support(Ck),当Support(Ck)≥minsup 时,得到所有频繁k 项集Lk。最后通过用户给定的minconf,在每个最大频繁项集中,寻找Confidence(X →Y)≥minconf 的关系规则,即找出强关联规则。
2.3 Apriori算法存在的问题
Apriori 算法中,事务数据存放在数据库中,为了获取候选集,需要多次扫描事务数据库,导致I/O 负载过大,另外由LK-1得到Ck的过程,会导致产生大量的没有实际操作意义的候选集[7]。因此该算法的改进可以从两个方面考虑,一方面是如何对事务数据库中的数据进行有效的聚类,减少数据库中的无用数据,从而提高扫描效率;另一方面是针对数据库的描述得到的大量候选集,如何提高验证候选集支持度计数时的I/O 效率。
3 算法改进
3.1 事务数据库聚类方法
针K-means 算法的不足,对数据库中数据进行凝聚层次聚类(AHC)[8],该算法属于无监督学习的一种聚类算法,使用自底向上的策略,将对象组织到层次结构中。凝聚层次聚类的思想是:最初将每个对象作为一个簇,然后按照相似性度量标准,按照数据相似度的高低,由高到低的依次合并数据形成簇,随着簇的合并,簇间的相似度逐渐降低,当达到给定的相似度阈值时,聚类终止。
首先将样本(p1,p2,p3,p4,p5,p6)中每个数据视为一个簇,然后根据相似性度量标准找到距离最短的两个簇p2,p3 进行合并形成P23,此时的簇集合为{p1,P23,p4,p5,p6},接着从当前簇集合中寻找距离最短的两个簇p4,p5 进行合并形成P45,从而得到新簇{p1,P23,P45,p6},如果此时达到给定的阈值4,则聚类停止。
此处采用的相似性度量标准为欧式距离法:
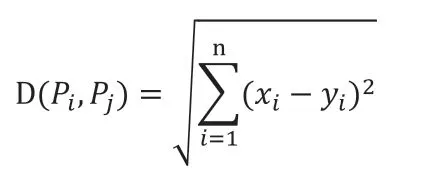
簇间距离度量采用最短距离法(最大相似度):Distmin(Ci,Cj)= min{|p-q|}(p∈Ci,q∈Cj)
该算法的整个过程是建立一个树结构,如图1 所示。
3.2 采用矩阵方式存储项集关联事务[1]
通过扫描事务数据库,获取事务数据库中的所有1 项集,利用m×n 阶矩阵,记录每个项集对应的事务信息,每一行表示一个项,每一列表示一个事务,在矩阵中分别用“1”和“0”表示项Ii是否出现在Ti中。获取候选1-项集C1的支持度记数,计算矩阵中每一行的取值为“1”的元素的个数。根据关联规则性质构造频繁K 项集LK。
4 聚类分析与Aprior在线购物系统中的应用
为数据库中的每个购物记录构造用户相关的属性,根据用户注册时输入的信息,包括用户的性别、年龄、爱好等信息,使用K-means凝聚层次聚类算法,先将数据库中的每个对象作为一个簇,然后针对每个簇根据某个邻近度量而进行合并,反复进行聚类合并过程,直到所有对象最终满足要求,达到给定的相似度阈值,对合并后的簇找出其具有代表性的数据,从而实现事务数据库的压缩。算法的执行过程如下:
(1)根据用户的注册信息,确定有用的用户的属性特征描述:用户性别、年龄、职业、爱好、学历等。
(2)对用户属性值进行正规化操作,将所有属性值映射到[0,1]区间。
(3)使用K-means 凝聚层次聚类算法,根据用户的年龄或爱好等属性,利用欧氏距离计算公式,计算距离最短的两个用户簇进行合并,然后再次从簇集合中寻找距离最短的两个簇合并,循环直到有所用户都聚类完成,形成聚类树。根据聚类树划分想要的N 个聚类,改变 cluster 数目不需要再次计算数据点的归属。
(4)从每个聚类中,根据商品出现的频次构造该聚类中的代表数据,完成事务数据库的压缩。
针对压缩后的事务数据库D,生成m×n 矩阵[1],计算矩阵中每一行中“1”的个数,即得到Ii 的支持度,将结果记录于数据字典中;然后将矩阵中小于最小支持度记数2 的项删除,得到矩阵M1以及频繁1-项集L1;将矩阵M1中的各行进行“逻辑与”运算,并计算“与”运算的项的支持度,得到候选2 项集C2,将结果记录于数据字典中;将小于最小支持度记数2 的项删除,得到频繁2-项集L2;根据频繁项集的所有非空子集都必须是频繁的,将频繁2 项集进行连接操作,同时扫描矩阵M1,当连接后的项对应的各行进行“逻辑与”运算,得到候选3 项集C3,将小于最小支持度记数2 的项删除,得到频繁3-项集L3;依此类推,最终得到所有需频繁项集,生成关联规则。
4 结论
本文利用关联规则挖掘算法Apriori 发现在线购物系统中用户购买商品的内在联系,以实现个性推荐功能,并针对Apriori 算法存在的不足,首先利用聚类算法对在线购物系统数据库进行了聚类,然后利用矩阵及字典存储事务数据库中的数据,最终完成频繁项集的挖掘与关联规则的生成,该算法可有效降低Apriori 算法反复扫描数据库导致的产生大量候选集的情况,提高了算法的执行效率。
