基于表情识别的情绪影集剪辑系统
2020-02-03潘哲琦付晓峰陈旭坤
潘哲琦 付晓峰 陈旭坤
(杭州电子科技大学计算机学院 浙江省杭州市 310018)
1 引言
表情是一种非语言动作,但可以跟语言发挥类似的作用,传达一定的信息和情绪。人工智能的发展使得对表情的感知不仅局限于人与人之间,机器也可以识别人脸表情。人脸表情识别技术日趋成熟,但是相关应用的市场占有率还很小。人脸表情识别在人机交互、医疗[1]、通信等方面具有较大的商业价值,是学术界和工业界研究的热点。近年来,深度学习以及智能设备的发展为表情识别技术的产生奠定了基础,而人脸检测精度[2]提高更是加快了人脸表情识别的进度。目前的人脸表情识别方法有
(1)非对称性局部二值模式人脸表情识别,该方法通过对表情图像光照补偿预处理及分割出表情的关键区域,并加权融合局部与整体特征,大大提高了特征的鉴别能力[3];
(2)基于特征融合的人脸表情识别研究,高阶自相关特征能反映图像内容固有的边缘信息和细节信息,提高了算法识别率[4]等。这些方法存在一些缺陷,如所用数据集较小,没有对实时检测进行实验。而本文采用卷积神经网络[5],搭建网络结构,使用Fer2013据集在较短时间内训练出验证准确率高达90%的人脸表情识别模型。同时,以表情识别为核心算法构建了一个情绪影集剪辑系统,拥有良好的用户界面和交互性。将该系统应用于婚宴场景的表情抓拍,并取得良好的结果。
2 基于视频监控的表情识别系统设计
2.1 系统功能目标
(1)实时性是本系统所追求的重要目标。要想对视频进行实时处理,对表情识别的速度要求很高。视频传输的时间是固定的,要让表情识别对每一帧视频图像检测时间更少,需要提高算法识别速度。
(2)应用兼容性是应用型系统的重要目标。本系统运行的软件和硬件环境均为当前主流配置,所以兼容性较强。
(3)系统必须达到的目标是高准确率,能够精确检测人脸并识别出表情种类
(4)系统界面设计应站在用户的角度进行,清晰、准确、简洁的实现用户和软件之间的交互。界面舒适,色彩柔和。按钮设计合理,便于用户使用。系统交互性设计让用户拥有良好的体验。
2.2 系统总体设计
系统总体设计如图1 所示,系统总体功能分为四个模块:读取视频流模块、人脸检测模块、表情识别模块、情绪影集生成模块。整个系统,对输入的视频流进行处理,读取一帧图片,对图片预处理后进行人脸检测,然后进行表情识别并显示结果。根据表情分类选择合适的表情生成情绪影集。
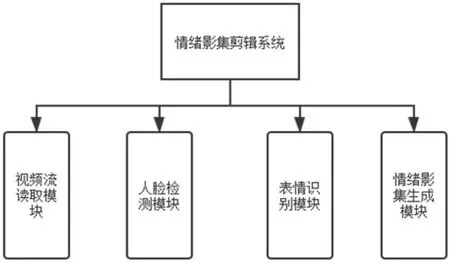
图1:系统总体设计
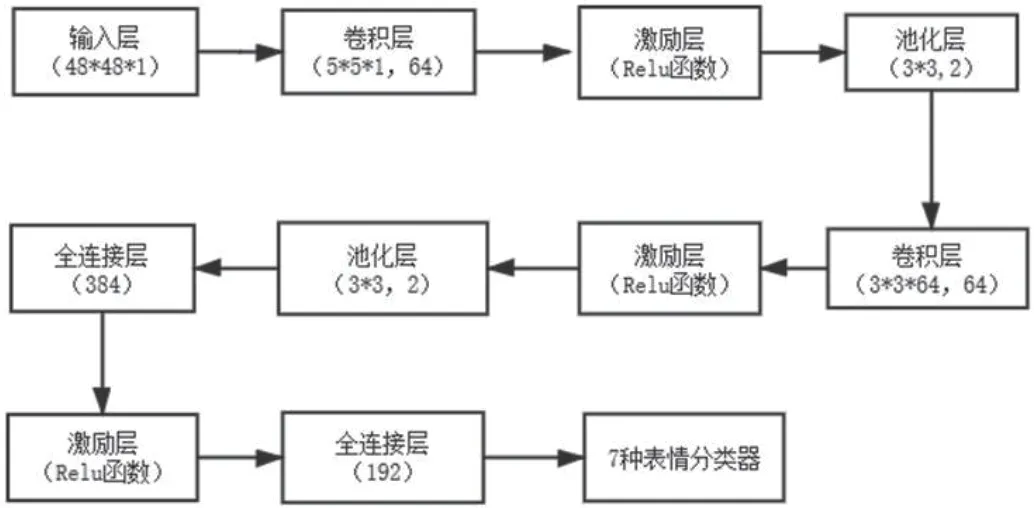
图2:网络结构

图3:实时视频中人脸表情识别流程图
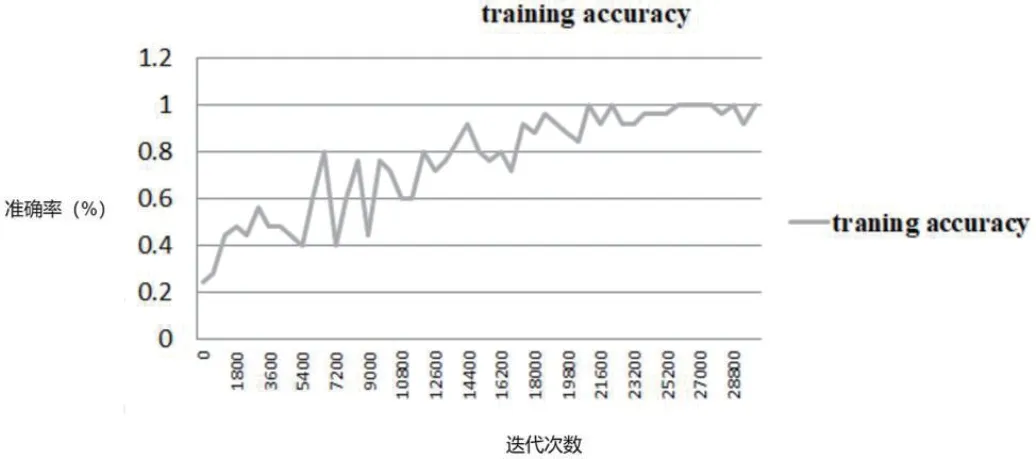
图4:训练集准确率随迭代次数的变化
系统组成模块如下所示:
2.2.1 视频流读取模块
该模块接收来自外界(如摄像头、本地视频)的视频流,对每一帧图像进行预处理。

表1:本文算法和其他算法识别率比较

表2:本文算法和其他算法识别速度比较
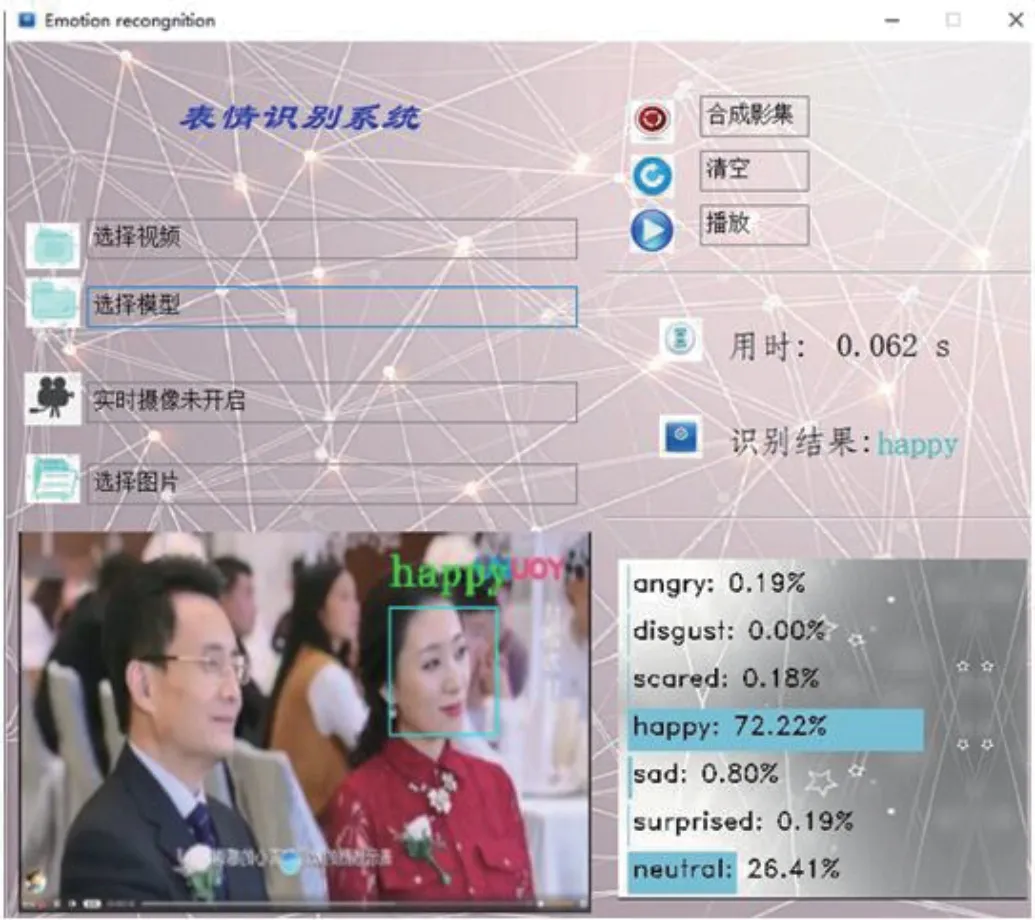
图5:查看实时摄像视频

图6:表情选择界面
2.2.2 人脸检测模块
该模块对图片进行人脸检测,检测出图片中人脸位置并裁剪出精确的人脸。
2.2.3 表情识别模块
这是系统中最重要的模块。对裁剪出的人脸进行表情识别,并记录结果。同时将图片识别结果存储在不同文件夹里。
2.2.4 情绪影集生成模块
该模块对于已经存储的各类表情进行选择,之后合成情绪影集。
3 表情识别算法设计
3.1 数据预处理
Fer2013 是本文使用的数据集。该数据集包括35886 张图片,分为七种表情,分别是:中性、惊讶、伤心、开心、恐惧、厌恶、生气。首先从Fer2013.csv 中获取人脸数据,将其变为48*48 像素图片。再进行灰度处理,灰度处理可以减少之后的计算量,同时又不会失去图像的形态特征。
3.2 人脸检测
本文使用Opencv 自带的Haar-Adaboost 算法。该算法先针对同一个训练集训练出不同的分类器,再把这些分类器集合起来构成一个更强的最终分类器。该算法可以检测出一张图片有无人脸,并标出人脸位置。
3.3 表情识别神经网络结构
通过构建卷积神经网络来训练数据集,本次使用的网络结构如图2 所示。其中有两个卷积层,卷积核分别是5*5*1、3*3*6。参数基于以往科学家的实验然后针对本实验不断调整得出。激励层使用Relu 函数作为激励函数,而且效果一般不错,之后实验证明也是如此。本文使用每个块大小为3*3、步长为2 的最大池化层,用于数据降维。全连接层用于表情分类其中参数384、192 代表输出神经元个数。
3.4 实时视频中人脸表情识别
如图3 所示,取出实时视频中每一帧图像,进行人脸表情识别,并返回结果。一秒可以检测98 张图片。而视频流一秒有25 张图片,完全可以满足实际应用。鉴于视频读取和输出的时间消耗,会有一点点延迟,但可以忽略。
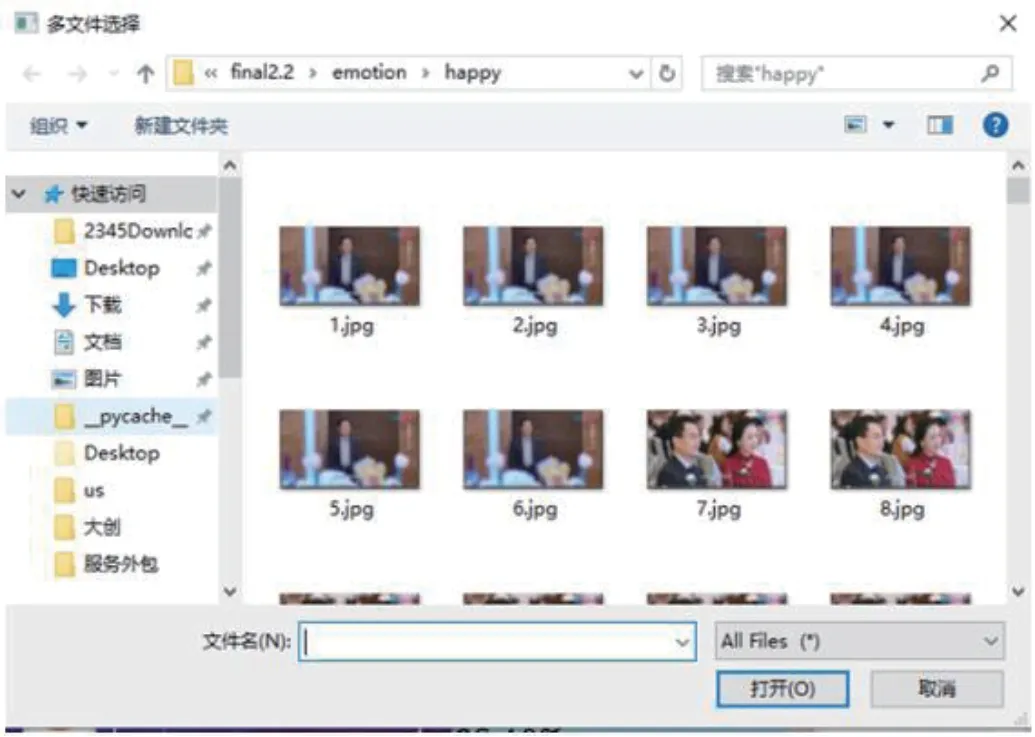
图7:选择要合成的表情和图片
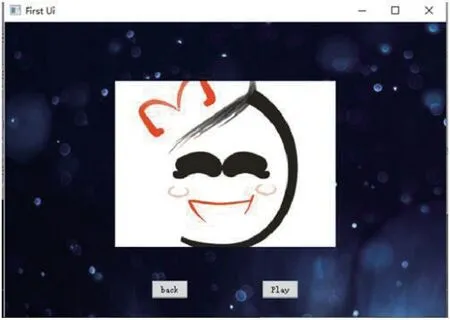
图8:播放合成影集
4 表情识别验证及准确率
如图4 所示,随着迭代次数的增加,总的训练准确率呈上升趋势。但不是一直递增,有时也会下降。Step20000 之后趋于平稳。最后训练集准确率达到96%。总的训练时长大约3 小时,总体训练时间较少。另外平均检测一张图片的时间只需0.04 秒,可以对视频流进行实时检测。
如表1 所示,将本文算法和其他算法的识别率进行比较,在Fer2013 数据集上,本文算法具有一定的优势,具有较高的识别率。本文算法采用数据集数量大,采用卷积神经网络提取特征,最后使得识别率高。
为验证本文算法,将本文算法识别速度和其他算法进行比较,如表2 所示。由表2 可见,本文算法识别速度较高,完全可以适用于实际应用。
5 系统实际应用
系统开发面向实际婚宴场景应用,用于抓拍婚宴中人们的各类表情,并生成情绪影集。可以选择本地视频、摄像头或者本地图片进行识别。识别后,可以选择各类表情进行合成视频。具有识别准确率高、识别速度快的特点。
(1)如图5 所示查看实时摄像,并实时显示表情种类。左下角显示实时视频,中间偏右显示检测结果和检测每张图片所需时间,右下角显示每种表情的概率。左上方按钮功能分别为:点击“选择视频”,可以选择视频进行接入;点击“选择模型”可以选择使用的识别模型;点击“摄像头按钮”,可以开启本地摄像头;点击“选择图片”可以选择要进行识别的图片。
(2)在点击图5 的“合成影集”按钮后,跳转到表情选择界面,如图6 所示,可以看到有七种表情可以选择。
(3)点击图6 任意一个表情按钮,可以进行图片选择,如图7 所示,查看表情分类结果,并可以选择要合成的图片。
(5)点击图5 的“播放”按钮,可以跳转到播放界面,如图8 所示,点击play 按钮,进行播放合成的影集。点击back 按钮返回主界面。
6 应用发展的方向以及目前存在的问题
目前表情识别的应用在市场的占有率还很低,还有很大的发展空间。例如,可以在婚宴现场安装摄像头对欢乐的镜头进行抓拍,可以在婴儿房间里安装摄像头,以情绪影集的形式展现婴儿一天的喜怒哀乐。与此同时,在表情识别的应用上,对个人隐私的保护、识别速度和应对复杂环境的能力仍存在一定的改进空间。
7 结语
表情识别的应用在医疗、心理学研究上有巨大的商业价值,目前表情识别应用在市场的占有率还很低。基于表情识别的情绪影集剪辑系统具有识别准确率高、识别速度快的特点,而且是针对视频流进行识别,未来在市场上能有较好的应用。
