基于语谱图和深度置信网络的方言自动辨识与说话人识别
2020-02-03张明键张悦
张明键 张悦
(湖南警察学院信息技术系 湖南省长沙市 410138)
1 引言
说话人识别是指通过提取说话人语音信号中的特征,并根据特征辨认说话人是谁,也被称为声纹识别[1-4]。相对于其他生物特征识别技术,说话人识别有以下几方面优势:语音信号采集是非接触式的,被采集对象接受度高;在手机语音通话等应用场景中,语音特征是唯一能采集到的说话人生物特征[1];语音信号中还包含说话人的性别、情感、健康状况等信息[5]。说话人识别在电子商务、安保、反恐等需要进行身份验证的领域有着广泛的应用[6-8]。20 世纪后期,隐马尔科夫模型、高斯混合模型等机器学习算法被成功应用于说话人识别领域[6]。
方言辨识是语音信号处理领域的一个分支。早期的方言辨识研究采用人工辨识方法,辨识过程基于音韵学知识。20 世纪90 年代以后,方言自动辨识作为模式识别和人工智能领域的一种崭新应用开始受到研究人员的重视。前述用于说话人识别的机器学习方法也可以在方言自动辨识中加以应用。当说话人所讲语言是方言时,两步法是一个可行的方法:即,先用方言自动辨识技术对方言语种进行辨识,然后再利用说话人识别技术确定说话人的身份。顾明亮等[9-11]在方言自动辨识和方言声学特征方面取得了一系列研究成果。
本世纪以来,深度学习(Deep Learning)技术的理论和应用研究取得了重大突破,在模式识别和人工智能领域取得了巨大成功。曾春艳等[2]从特征表达、后端建模、端到端联合优化等几个方面对基于深度学习框架的说话人识别进展进行了综述。张学祥等[3]以基音周期为特征,提出了基于深度神经网络的说话人识别新算法。贾艳洁等[4]提出了一种基于特征语谱图和自适应聚类SOM 的快速说话人识别算法。
2 语音信号预处理
语音信号中低频部分能量占主体,为了让频谱中高频部分的幅度得到提升,对语音信号做后续处理之前,通常需要用一个一阶高通滤波器对语音信号进行预加重[6][12][13]。本文研究基于孤立词的方言自动辨识和说话人识别,为了将整段语音信号分割成一个个孤立词,需要利用端点检测技术确定每个孤立词语音的起始位置和终止位置[6][7]。双门限判决法是一种常用的语音信号端点检测方法[6][7],王满洪等提出了一种改进的双门限算法[14]。
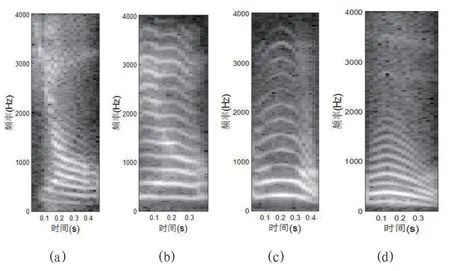
图1
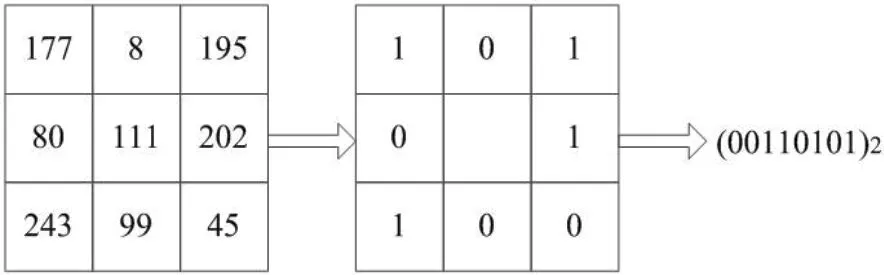
图2:3×3 矩形邻域LBP 计算过程
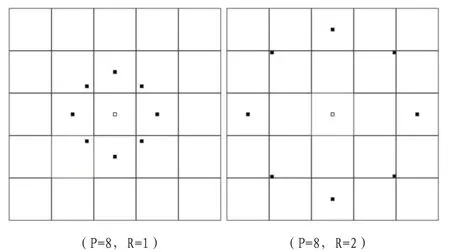
图3:两种圆形邻域LBP 算子
语音信号具有非平稳的特性,其特征是随着时间变化的。但是,在一个很小的时间片段里,语音信号可以视为平稳信号,语音的特征参数在短时间内近似看作没有变化[6-8][12][13]。也就是说,语音信号可以视为短时平稳的。为此,对语音信号进行处理时通常先将语音信号分割为一个个小的片段(帧)。语音信号以帧为单位进行处理,每帧的时间长度一般在10~30ms 范围内[6]。为了使得提取的语音特征在相邻帧之间能够平滑过渡,相邻帧之间一般设有一定量的重叠部分[6-8][12][13]。用一个窗函数与语音信号相乘可达到对语音信号分帧的目的[6],窗口的宽度即为帧的长度。加窗处理通常使用汉明窗,相对于矩形窗它的旁瓣衰减较大[6-8][12][13]。
计算每一帧语音信号的短时功率谱,再将各帧的功率谱按照时间先后顺序拼接起来,就形成了语谱图[4][7]。语谱图的横轴方向代表时间,纵轴方向代表频率,灰度值的大小表示对应频带能量的高低[4][7]。语谱图的纹理结构中反映了说话人的基音频率、共振峰、音韵学特征等信息。语谱图的实例如图1 所示。
从图1 中可以看出普通话数字‘9’和长沙话数字‘9’的语谱中的纹理具有明显的差异。同时,不同说话人所讲长沙话数字‘5’的语谱图也存在明显差异。可见,对于同一个孤立词,不同的语种发音对应的语谱图上的纹理结构不一样。相似地,对于同一个孤立词,不同说话人的发音对应的语谱图的纹理结构也不一样。因此,根据语谱图上的纹理信息,可以进行方言语种自动辨识和说话人识别。
3 LBP特征
局部二值模式(Local Binary Pattern, LBP)由Ojala 等[15]提出,它是一种描述图像局部纹理特征的算子。最初的LBP 针对图像固定的3×3 矩形邻域进行计算。该计算方式以邻域中心位置像素灰度值为阈值,邻域中像素灰度值比阈值大的映射为1,邻域中像素灰度值比阈值小的映射为0。再由邻域中8 个数字(0 或1)构成一个二进制数作为LBP 值(如图2 所示)[15]。
Ojala 等在文献[16]中进一步把LBP 特征计算方式由固定的3×3矩形邻域拓展到圆形邻域(如图3 所示),从让而LBP 具有了灰度不变性和旋转不变性[16-18]。
LBP 值的计算公式为[16]:

其中,P 表示以gc为中心的圆形邻域上的像素点数,gp表示邻域点,R 是圆的半径。s(·)是符号函数,定义为:

邻域点gp与中心点gc的横坐标和纵坐标差值分别是-Rsin(2πp/P)和Rcos(2πp/P)[16]。当邻域点没有正好落在像素中心位置时,其灰度值通过插值进行计算。通过以中心像素为阈值的操作,局部邻域转化成了一种二值模式[16]。近年来,LBP 特征在木材缺陷自动检测分类[19]、人脸识别[20]、纹理图像识别[21]、工件图像识别[22]等机器视觉领域得到了广泛应用。
4 深度置信网络
深度置信网络(Deep Belief Network, DBN)由“深度学习之父”Hinton 与合作者在2006 年最先提出[23],它是由多个受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)接续而成的深度学习模型[24-26]。一个RBM 包含一个隐含层和一个可见层,隐含层和可见层之间的节点之间是双向全连接的,隐含层和可见层内部的节点之间没有连接的关系(如图4 所示)[24-26]。
图5 是一个由3 个RBM 叠加而成的深度置信网络。RBM1 的隐含层作为RBM2 的可见层,RBM2 的隐含层作为RBM3 的可见层,RM3 的隐含层是分类器的输入层[24-27]。DBN 模型的训练包含以下两个阶段。
第一个阶段是无监督预训练过程,即分别以无监督的方式单独训练每一层RBM 网络[24][25]。利用对比散度(Contrastive Divergence,CD)算法[25][26][28]训练RBM1,训练完成以后固定RBM1 的参数。再将RBM1 的隐含层的输出作为RBM2 可见层的输入,同样利用对比散度算法对RBM2 进行训练。该过程一直持续,直到每一层RBM 都训练完成[24-26]。
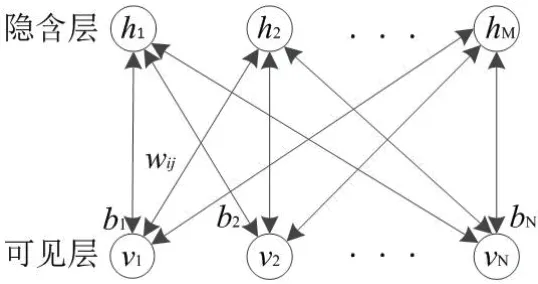
图4:RBM 的结构
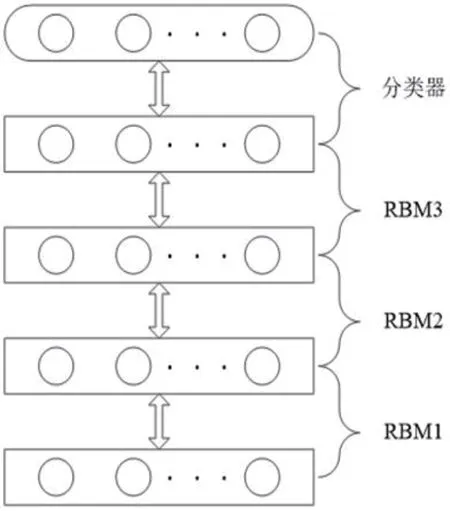
图5:DBN 的结构
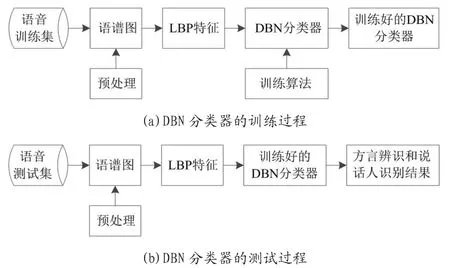
图6
第二个阶段对DBN 网络参数进行微调。在预训练的基础上,利用反向传播算法,对整个DBN 网络的参数进行优化调整[24-28]。这个阶段是一个有监督的训练过程,以网络最顶层的实际输出与预期输出(标签值)之间的误差最小为准则,利用梯度下降法自顶向下迭代调整RBM 的参数[24-28]。
深度置信网络广泛应用于人体动作识别[29]、田间杂草识别[30]、数字调制信号识别[31]等模式识别领域。
5 计算机仿真实验
方言自动辨识和说话人识别的流程如图6 所示。
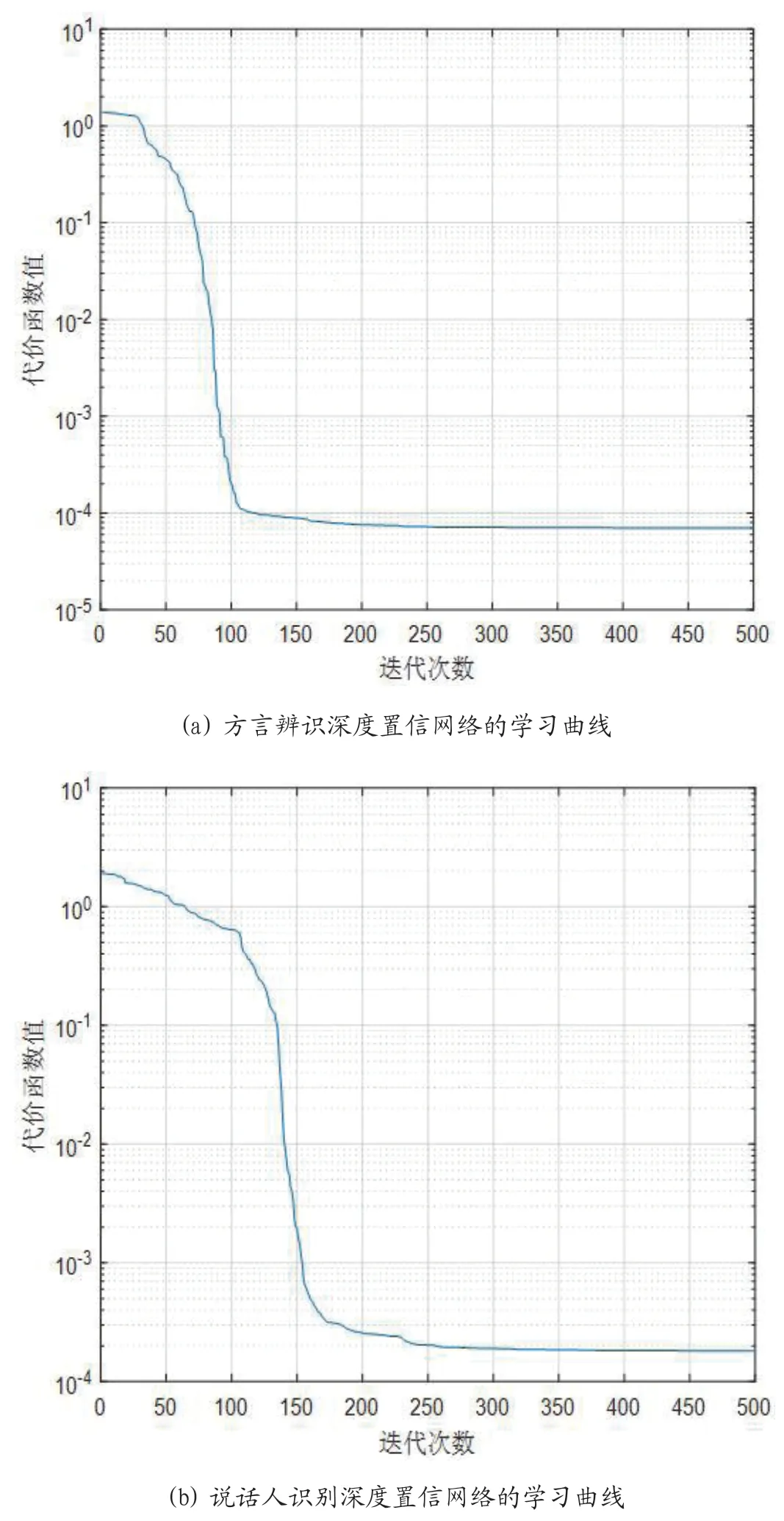
图7
计算机仿真实验使用的数据集文件共有180 个语音片段,内容是数字‘1’-‘10’。其中,普通话语音片段共有90 个,长沙话语音片段也有90 个。普通话语音的说话人共有3 人,长沙话语音的说话人也有3 人。语音信号的采样率是8kHz,每个数据样本以16bits 量化。在语种辨识仿真实验中,60 个普通话语音片段和60个长沙话语音片段用作DBN 网络的训练数据集,剩下的30 个普通话语音片段和30 个长沙话语音片段作为DBN 网络的测试数据集。在长沙话说话人识别仿真实验中,3 个说话人的共60 个语音片段作为DBN 网络的训练数据集,同样3 个说话人的剩下的30 个语音片段作为DBN 网络的测试数据集。
计算机仿真实验中构造的DBN 网络共4 层,包括1 个输入层、2 个隐含层和1 个输出层。
对一个语谱图,如果整幅图像的LBP 特征值形成一个向量会丢失掉位置信息,为此仿真实验中将图像划分为16 个子图,每个子图的尺寸一致。对每个子图计算LBP 特征值,进一步得到直方图向量,再将这些向量接续在一起形成一个特征值向量。一个子图中LBP 特征值直方图数据是1×256 维的,16 个子图的LBP 特征值拼接在一起就是1×4096 维。为了对LBP 特征值数据降维,实验中使用在文献[16]中提出的等价模式(Uniform Pattern),将256 种模式转化为59 种模式[22]。因此,在等价模式下,一个子图中LBP 特征值直方图数据是1×59 维。

表1:归一化语谱图水平方向像素点数目h 与Pd、Ps 的对应关系
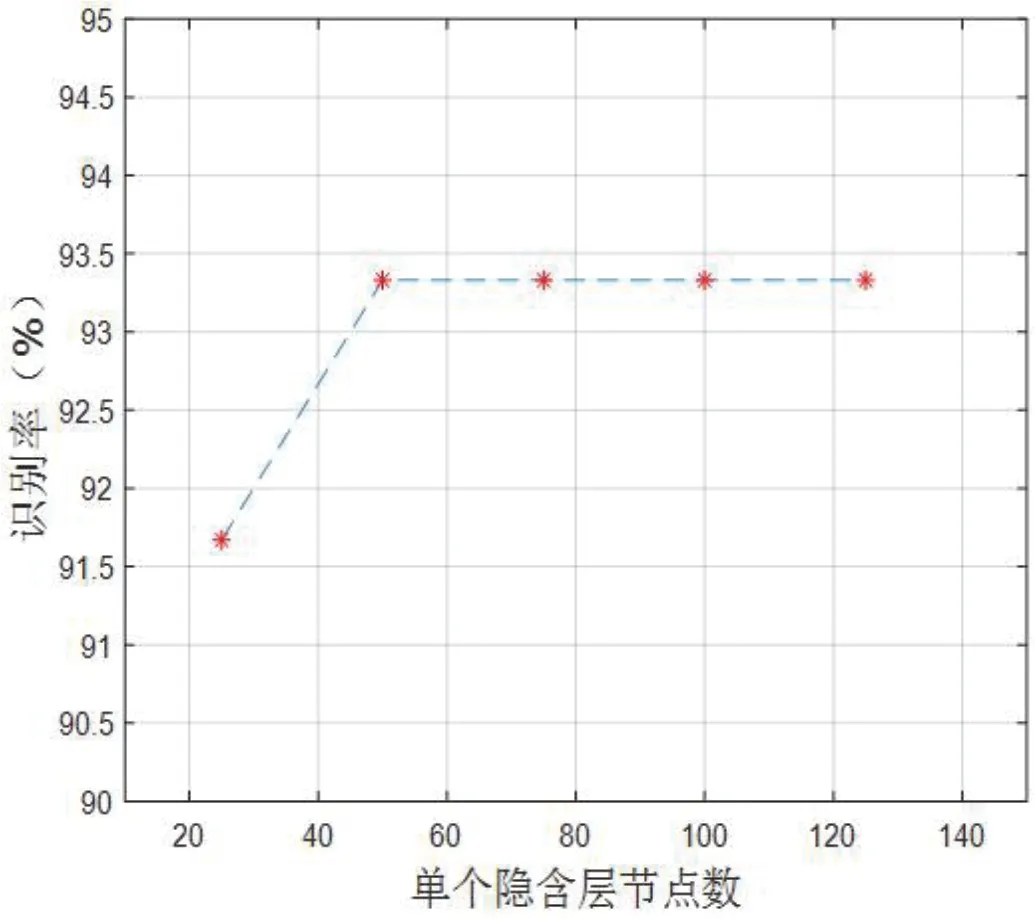
图8:DBN 的单个隐含层节点数与识别率之间的对应关系
为了计算语种辨识和说话人识别的识别率,我们定义RN×N维的混淆矩阵C,其中,N 表示测试集中加标签的子集合数目。混淆矩阵C 的第(i,j)个元素表示标签为i 的测试集中的语谱图被训练好的DBN 网络识别为标签为j 的语谱图的数目。识别率PI 定义为:

基于以上识别率的定义,我们分别用PId表示长沙话辨识的识别率,用PIs表示长沙话说话人识别的识别率。
因为每个孤立词语音信号的时间长度可能不一样,所以对应语谱图的横轴方向像素点数目也可能不一样。为此,需对测试集和训练集中的语谱图尺寸进行归一化,即让语谱图的水平方向像素点数目一致。而每个语谱图的垂直方向像素点数目是一致的,因此语谱图归一化过程中不需要对垂直方向像素点数目进行调整。表1 列出了归一化语谱图水平方向像素点数目h 取不同值时,识别率Pd和Ps的数值。该仿真实验中,2 个隐含层节点数均为100。
为了研究深度置信网络学习过程的收敛情况,本文利用归一化处理以后得到的水平方向像素点数目为28、垂直方向像素点数目为176 的语谱图进行仿真实验,2 个隐含层节点数均设置为100。仿真结果如图7 所示。图7(a)描述的是面向长沙话辨识的深度置信网络学习过程中,迭代次数与网络的代价函数数值之间的对应关系,从中可以看出算法在迭代300 次以后达到收敛。图7(b)描述的是面向长沙话说话人识别的深度置信网络学习过程中,迭代次数与网络的代价函数数值之间的对应关系,从中可以看出算法在迭代350 次以后达到收敛。
为了研究DBN 隐含层的节点数对方言辨识的识别率影响,本文利用归一化处理以后得到的水平方向像素点数目为40、垂直方向像素点数目为176 的语谱图进行仿真实验。我们改变每个隐含层的节点数(两个隐含层的节点数相同),并分别记录对应的识别率(如图8 所示)。如果隐含层节点数过少,则会影响该网络的分类性能,长沙方言辨识的识别率低。从图8 可以看出,当单个隐含层的节点数设置为25 时,长沙方言辨识的识别率为91.67%。单个隐含层节点数提高至50 以后,深度置信网络的识别率提升至93.33%。再进一步提高单个隐含层节点数,深度置信网络识别率维持在93.33%。值得注意的是,深度置信网络隐含层节点数增加了以后,网络训练过程中参数调整的计算复杂度增加,从而导致收敛速度变慢。因此,综合考虑识别率和网络参数调整的收敛速度两方面因素,每个隐含层节点数设定为50~100 之间比较合适。
6 结束语
本文实现了小样本条件下长沙方言自动辨识和说话人自动识别算法。识别算法以语音信号语谱图的局部二值模式作为特征,以1个输入层、2 个隐含层和1 个输出层构成的DBN 为分类器。仿真实验结果显示长沙方言辨识的识别率在91.67%至95%之间、长沙话说话人识别的识别率在93.33%至96.67%之间。
